HashTable, HashMap, ConcurrentHashMap 之间的区别?(经典面试题)

点进来你就是我的人了
博主主页:戳一戳,欢迎大佬指点!
人生格言:当你的才华撑不起你的野心的时候,你就应该静下心来学习!欢迎志同道合的朋友一起加油喔
目标梦想:进大厂,立志成为一个牛掰的Java程序猿,虽然现在还是一个嘿嘿
谢谢你这么帅气美丽还给我点赞!比个心

目录
前言
1. HashMap
2. HashTable
3. HashMap 和 Hashtable 的区别:
1. 实现方式不同
2. 初始化容量不同
3. 扩容机制不同
4. 迭代器不同
4. ConcurrentHashMap和HashTable的区别
前言
如果大家学过数据结构,想必对 HashMap 都不陌生, HashMap 的实现很简单嘛, 数组加链表嘛, 然后继续问你 HashTable 和 HashMap 的区别是什么, 我们会说一个线程安全, 然后一个线程不安全啊, HashTable 是不允许存在 NULL 值的, 但是 HashMap 中的 key 和 value 都允许为 null , 并且 key 为 null 的键值对永远放在以 table[0] 为头节点的链表中. 我们知道 HashMap 是线程不安全的,只适用于单线程下, 而在多线程环境下就是采用 concurrent 并发包下的 ConcurrentHashMap .
为啥 Hashtable 是不允许 KEY 和 VALUE 为 null, 而 HashMap 则可以呢?
因为 Hashtable 在我们 put 空值的时候会直接抛空指针异常, 但是 HashMap 却做了特殊处理.
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}而为啥 Hashtable 是不允许键或值为 null 的,但是 HashMap 的键值又都可以为 null 呢?
这是因为 Hashtable 使用的是 安全失败机制(fail-safe). 这种机制会使你此次读到的数据不一定是最新的数据. 如果你使用null值, 就会使得其无法判断对应的 key 是不存在还是为空, 因为你无法再调用一次 contain(key) 来对 key 是否存在进行判断, ConcurrentHashMap 同理。
1. HashMap
HashMap 是在 JDK1.2 引入Map的实现类.
HashMap是基于哈希表实现的, 每一个元素是一个 key-value 键值对, 其内部通过单链表解决冲突问题, 容量不足 (超过了阀值) 时, 同样会自动增长。
开始在JDK1.7的时候 底层数据结构是 数组+链表
在 JDK1.8 的时候, 底层数据结构是 数组+链表+红黑树 (看过源码的同学应该知道JDK1.8中即使用了单向链表, 也使用了双向链表, 双向链表主要是为了链表操作方便, 应该在插入, 扩容, 链表转红黑树, 红黑树转链表的过程中都要操作链表).
其次, HashMap 是非线程安全的, 只适用于单线程环境下, 多线程环境下可以采用 concurrent 并发包下的 concurrentHashMap.
HashMap 中 key 和 value 都允许为null . key 为 null 的键值对永远都放在以 table[0] 为头结点的链表中.
2. HashTable
Hashtable同样也是基于哈希表实现的,同样每个元素是一个 key-value 键值对,其内部也是通过单链表解决冲突问题,容量不足 (超过了阀值) 时,同样会自动增长.
Hashtable也是JDK1.0引入的类,是线程安全的,能用于多线程环境中.
Hashtable同样实现了Serializable接口,它支持序列化,实现了Cloneable接口,能被克隆.
也就是说,这两个东西大部分时相同的.
Hashtable 与 HashMap的不同
首先,从上面可以得出,线程安全是不同的.
HashTable只是在关键方法上加了synchronized,相当于针对HashTable本身加锁.
Hashtable 适合在多线程的情况下使用, 但是效率不高.
原因是: Hashtable 在对数据操作的时候都会上锁, 所以效率比较低
3. HashMap 和 Hashtable 的区别:
1. 实现方式不同
Hashtable 继承了 Dictionary类,而 HashMap 继承的是 AbstractMap 类.
2. 初始化容量不同
HashMap 的初始容量是 16, Hashtable 初始容量是 11, 两者的负载因子默认都是 0.75.
3. 扩容机制不同
当现有容量大于总容量 * 负载因子时,HashMap 扩容规则为当前容量翻倍,Hashtable 扩容规则为当前容量翻倍 + 1.
4. 迭代器不同
HashMap 中的 Iterator 迭代器是 fail-fast 的,而 Hashtable 的 Enumerator 不是 fail-fast 的.
快速失败(fail—fast)是java集合中的一种机制, 在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception.
4. ConcurrentHashMap和HashTable的区别
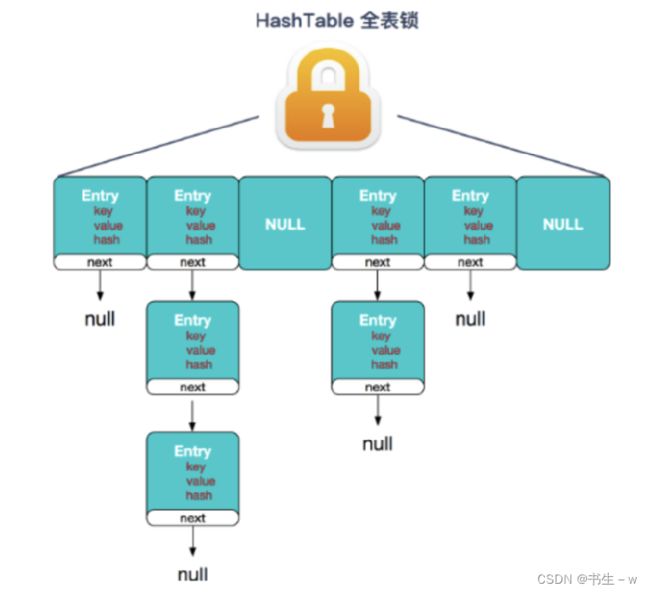
HashTable
HashTable 的键值不能为null
HashTable 虽然线程安全,但只是简单得用 synchronized 给所有方法加锁,相当于是对this加锁,也就是对整个HashTable对象进行加锁(非常无脑)
一个HashTable对象只有一把锁,如果两个线程访问同一个对象时,就会发生锁冲突
HashTable效率非常低,因为无脑加锁原因,比如一些读操作不存在线程不安全问题,所以这样的加锁方式导致效率非常低
比如 某个线程触发了扩容机制,那就会由这个线程完成整个扩容过程,如果元素特别多的情况下,效率非常低,其他线程阻塞等待的时间会特别长
HashTable 使用的数据结构是 数组 + 链表
因为HashTable无脑加锁的原因,现在Java官方已经不推荐使用HashTable了
不涉及线程安全问题时使用HashMap,如果要保证线程安全就使用ConcurrentHashMap
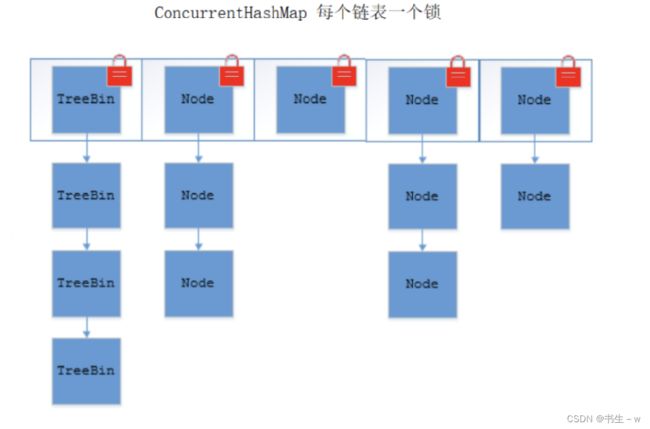
ConcurrentHashMap
ConcurrentHashMap 的键值不可以为null
ConcurrentHashMap 使用的数据结构是 数组 + 链表 + 红黑树
ConcurrentHashMap 最重要的点要说 线程安全
ConcurrentHashMap 相比比较于HashTable 有很多的优化,
最核心的思路就是:降低锁冲突的概率
(1)锁粒度的控制
ConcurrentHashMap 不是锁整个对象,而是使用多把锁,对每个哈希桶(链表)都进行加锁,只有当两个线程同时访问同一个哈希桶时,才会产生锁冲突,这样也就降低了锁冲突的概率,性能也就提高了
(2)ConcurrentHashMap 只给写操作加锁,读操作没加锁
如果两个线程同时修改,才会有锁冲突
如果两个线程同时读,就不会有锁冲突
如果一个线程读,一个线程写,也是不会有锁冲突的
(这个操作也是可能会锁冲突的,因为有可能,读的结果是一个修改了一半的数据
不过ConcurrentHashMap在设计时,就考虑到这一点,就能够保证读出来的一定时一个“完整的数据”,要么是旧版本数据,要么是新版本数据,不会是读到改了一半的数据;而且读操作中也使用到了volatile保证读到的数据是最新的)
(3)充分利用到了CAS的特性
比如更新元素个数,都是通过CAS来实现的,而不是加锁
(4)ConcurrentHashMap 对于扩容操作,进行了特殊优化
HashTable的扩容是这样:当put元素的时候,发现当前的负载因子已经超过阀值了,就触发扩容。
扩容操作时这样:申请一个更大的数组,然后把这之前旧的数据给搬运到新的数组上
但这样的操作会存在这样的问题:如果元素个数特别多,那么搬运的操作就会开销很大
执行一个put操作,正常一个put会瞬间完成O(1)
但是触发扩容的这一下put,可能就会卡很久(正常情况下服务器都没问题,但也有极小概率会发生请求超时(put卡了,导致请求超时),虽然是极小概率,但是在大量数据下,就不是小问题了)
ConcurrentHashMap 在扩容时,就不再是直接一次性完成搬运了
而是搬运一点,具体是这样的
扩容过程中,旧的和新的会同时存在一段时间,每次进行哈希表的操作,都会把旧的内存上的元素搬运一部分到新的空间上,直到最终搬运完成,就释放旧的空间
在这个过程中如果要查询元素,旧的和新的一起查询;如果要插入元素,直接在新的上插入
;如果是要删除元素,那就直接删就可以了