Y86-64流水线
目录
1. 流水线通用原理
1.1 什么是流水线
1.2 计算流水线吞吐量
1.3 流水线的局限性
1.4 带反馈的流水线系统
2. Y86-64的流水线实现
2.1 SEQ+硬件结构
2.2 插入流水线寄存器
2.3 预测下一个PC
2.4 流水线冒险
3. PIPE各阶段的实现
3.1 PC选择和取指阶段
3.2 译码和写回阶段
3.3 执行阶段
3.4 访存阶段
1. 流水线通用原理
在之前我们学习了Y86-64处理器的顺序实现,将一条Y86-64指令的处理分为取指、译码、执行、访存、写回、更新PC六个阶段,本文基于《深入理解计算机系统》4.4节进行编写,介绍如何实现一个流水线化的处理器
1.1 什么是流水线
类似于工厂里工人的流水线式生产,在一个流水线化的系统中,待执行的任务将被划分为若干个不同的阶段,然后由负责相应模块的工人进行处理。例如,一位餐厅门口的接待人员负责将上一位顾客招呼好之后就可以招待下一位客人,而不必要等到上一位客人用完餐
流水线的系统中,一条指令的处理被划分为不同的阶段,由不同的组合逻辑来进行处理,在任何时刻,都会有多个对象被处理,例如下面一个三级流水线中,流水线阶段之间的指令转移是由时钟信号控制的,每隔120ps,信号从0上升为1,开始下一阶段的计算

一条指令的执行有A、B、C三个阶段
- 0~120ps, 执行指令I1的A阶段
- 120~240ps,执行指令I1的B阶段,同时执行指令I2的A阶段
- 240~360ps,执行指令I1的C阶段,执行指令I2的B阶段,同时执行指令I3的C阶段
- ...
下图给出了这样一个流水线的一个时钟周期内的操作
发现在Time=239时,指令I1刚好处于B阶段,并且其值已经到了第二个寄存器的输入(灰色部分),当time=240时,时钟信号变化,将值写进第二个寄存器中并成为寄存器的输出,其他时间段也是类似,这说明流水线是靠时钟的变化进入到下一个阶段的

1.2 计算流水线吞吐量
流水线化的一个重要特性就是提高了系统的吞吐量 ,并会轻微地增加延迟。
吞吐量是指单位时间内处理的指令的数量,其计算公式为
![]()
吞吐量=1条指令/周期(ps)*1000ps/1ns,其中周期是流水线一个阶段完成的时间,对于一个非流水线的计算硬件,每个周期为320ps,吞吐量为
![]()

我们以每千兆条指令(GIPS),也就是每秒十亿条指令,为单位来描述吞吐量
延迟是指从头到尾执行一条指令所需要的时间,因此在这个计算硬件的延迟为320ps
对于一个流水线化的计算硬件,比如下面这个流水线,被分为三个阶段,每个阶段要通过一个组合逻辑块(100ps)和一个寄存器(20ps),因此这个流水线的周期为120ps,吞吐量为
![]()

由于使用寄存器增加了流水线的阶段,每插入一个寄存器,都会导致一条指令完整的执行周期变长,因此对于流水线化的计算硬件的延迟计算公式为:
![]()
延迟 = 流水线的阶段数 × 每个阶段的周期时长,上面的流水线的延迟为3×120=360ps
可以看到,划分了流水线之后,吞吐量提高到原来的2.67倍,代价是增加了一些硬件,以及少量的延迟
1.3 流水线的局限性
局限性1 不一致的划分
然而,将流水线的每个阶段划分得时长一致是过于理想化的,实际情况是由于各个阶段处理问题额组合逻辑得功能不同,所耗费的时间也不一样
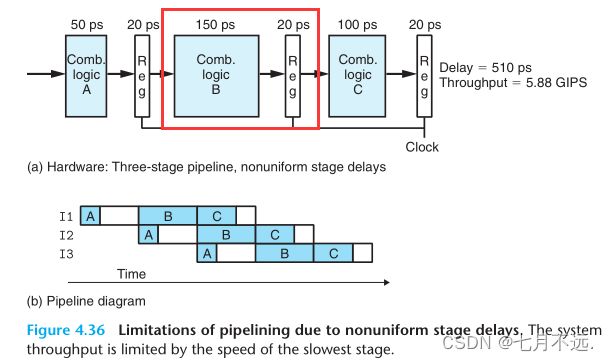
这样一个流水线每个阶段都具有不同的阶段延迟,但在实际的设计过程中,时钟周期确是相同的,因此我们只能选择延迟最长的那个阶段延迟来作为周期,上图中为170ps,因此对于的吞吐量延迟为170ps×3=510ps,吞吐量为1/170*(1000)=5.88GIPS
局限性2 流水线过深,收益下降
由于每增加一个阶段都需要引入一个寄存器,而寄存器同样存在着时间的开销,因此如果将流水线的阶数划分得过多,会引入大量寄存器,同样使得效率降低

例如上面这个流水线的周期为70ps,划分为6个阶段,那么其吞吐量为1/70*(1000)=14.29GIPS,延迟为70ps×6=420ps,每个计算时钟的时间缩短了两倍,但性能只提高了14.29/8.33=1.71倍,这是由于延迟过大(占整个时钟周期的28.6%)所造成的
1.4 带反馈的流水线系统
对于像x86-64或者Y86-64这样的系统而言,指令之间并不是完全独立的,一条指令的执行很可能倚赖上一条指令的执行结果,以下面的Y86-64指令为例

- irmovq $50, %rax 表示将50这个立即数传递给%rax寄存器,这一动作的实现需要在写回阶段完成
- addq %rax, %rbx 表示将%rax里的值传递给%rbx寄存器,而读取%rax在译码阶段实现,这时上一条指令还在执行阶段,也就无法从%rax中读到准确的值
- mrmovq 100(%rbx), %rdx 表示将内存地址(%rbx)+100处的值传递给%rdx,需要在译码阶段就拿到%rbx里的值,但此时上一条指令还未将正确的值写入%rdx
因此这三条指令之间都存是在着数据相关
另一种相关是由于指令控制流造成的顺序相关,如下面这个Y86-64指令序列
1 loop:
2 subq %rdx,%rbx
3 jne targ
4 irmovq $10,%rdx
5 jmp loop
6 targ:
7 halt第三行中jne跳转要根据第二行的结果来判断下一条指令是第四行irmovq还是第七行halt,一种好的解决办法引入反馈的机制,将每条指令的结果都反馈给下一条指令,我们将在后面介绍Y86-64是如何实现这种反馈机制的
2. Y86-64的流水线实现
2.1 SEQ+硬件结构
回顾一下之前的SEQ实现

- 取指阶段,从PC中获得当前指令的地址取出指令,分为icode(指令代码)、ifun(指令功能),并由寄存器指示符字节给出可能用到的寄存器rA和rB,以及常数字段valC,并计算下一条指令地址valP
- 译码阶段,从寄存器文件中读rA和rB的值到valA和valB(也可能从%rsp中读)
- 执行阶段,ALU根据ifun来执行指定的运算,valA和valB的值分别送到ALUA和ALUB,运算得到结果valE,同时设置CC。除此之外,对于跳转指令,会根据条件码和跳转条件产生信号Cnd。ALU还会利用valC计算访存有效地址和增加减少栈指针,因此ALU的输出端口会与内存的逻辑地址单元相连
- 访存阶段,将数据写入内存或从内存中读出数据,写入的数据可以由寄存器文件提供,也可以是valP(call指令将返回地址入栈)
- 写回阶段,寄存器文件有两个写入端口M和E,ALU的计算结果valE可以通过端口E写回到寄存器文件,内存中读出的数据valM可以通过M端口写回寄存器文件
- 更新PC,要根据icode和Cnd来判断
之前所学到的SEQ的更新PC的过程是在一个周期的快要结束时完成的,为了满足流水线的需要——即我们需要在当前指令取指完成后立马进行下一条指令的取指,而不能像SEQ那样等它执行完了再进行取指。这种修改过时序的SEQ称为SEQ+
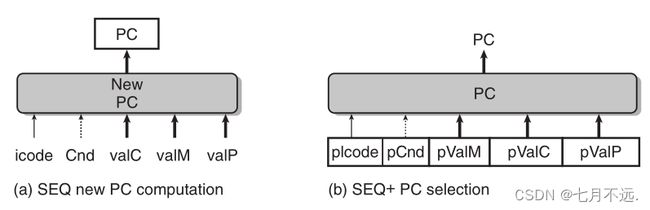
具体的方法是创建一个寄存器来保存指令执行过程中计算出来的信号,这样,当一个新的时钟周期开始时,这些信号可以像SEQ中那样,以相同的逻辑计算新的PC,使用pIcode、pCnd等来指明在任一给定的周期,它们保存的是前一个时钟周期中产生的控制信号。这样一来,我们将更新PC的操作移到了时钟周期刚开始时,但整个系统的逻辑行为并没有发生改变,这种改进称为电路重定时

2.2 插入流水线寄存器
将一个顺序结构改造成流水结构,只需要在SEQ+各个阶段之间插入时钟寄存器,并进行信号重新排序,就能得到一个流水结构,称为PIPE-处理器

对于上述PIPE-处理器,我们插入了F、D、E、M、W五个流水线寄存器,这五个寄存器分别有其各自的功能
- F 保存程序计数器的预测值
- D 位于取指阶段和译码阶段之间,用于保存刚刚取出的指令的信息,例如icode、ifun和寄存器指示符等等,这些信息会交给后面的译码阶段进行处理
- E 位于译码和执行阶段之间,它保存了最新译码指令的状态和从寄存器文件中读出的数值(valA和valB),这些信息会交给后面的执行阶段进行处理
- M 位于执行和访存阶段,它保存了最新执行的指令的结果(valE以及跳转指令分支条件和分支目标的信息),这些信息由访存阶段处理
- W 位于访存和反馈路径之间,访存执行的结果保存到寄存器W中,反馈路径将结果写回到寄存器文件,如果当前执行的是ret指令,它还要向PC选择逻辑提供返回地址
每个流水线寄存器都保存着上一阶段得到的值,并提供给下一阶段使用

上图就是一个典型的例子,周期1取出指令I1,然后这个指令开始通过流水线的各个阶段,直到周期5结束,将结果写回到寄存器文件;在周期2取出I2,并运行至周期6结束,写回结果,以此类推。
2.3 预测下一个PC
在流水化的体系中,每个周期都要完成一条指令,这意味着吞吐量是每个周期一条指令,所以每个周期都必须获得新的指令的地址
对于一般的指令,我们可以通过指令长度计算出下一条指令的地址valP,对于call和jmp(无条件跳转指令),下一条指令地址是valC字段,因此对于这些情况,预测下一条PC是很容易的
然而,如果取出的指令是条件分支指令,我们必须要等到执行阶段后才能根据icode和Cnd判断是否发生跳转来确定下一条指令的地址;对于ret指令,必须要等到访存阶段从内存中取出地址后才能确定下一条指令的地址
我们通常有如下几种预测新PC的方法
- 非转移指令
预测PC为valP➔永远可靠- 调用指令或无条件转移指令
▪预测PC为valC (调用的入口地址或转移目的地址) ➔永远可靠- 条件转移指令
▪ 预测PC为valC (转移目的地址,总是选择分支)
▪ 如果分支被选中则预测正确
▪ 研究表明成功率大约为60%
对于ret指令,不进行预取( 暂停处理新指令,直至ret通过写回阶段)
2.4 流水线冒险
之前我们以及讨论过,相近的几条指令之间可能会存在着某种相关,导致流水线系统出现问题。这种相关通常分为两类——数据相关和控制相关
数据相关
下一条指令会用到这一条指令计算出的结果
考虑下面的指令
# progl
0x000: irmovq $10,%rdx // 将立即数10传送到寄存器%edx,写回阶段完成
0x00a: irmovq $3,%rax // 将立即数3传送到寄存器%rax,写回阶段完成
0x014: nop
0x015: nop
0x016: nop
0x017: addq %rdx,%rax // 将寄存器%rdx和%rax中的值相加,其中译码阶段需要获得正确的值
0x019: halt
这是一个可以得到正确结果的流水线,可以看到在irmovq指令和addq指令之间插入了三个nop(nop指令在指令之间插入了一条空的指令,使得下一条指令向后推移了一个周期),这是为什么呢?
addq指令正确执行的条件是,在这条指令的取指阶段,寄存器%rdx和%rax的值已经被更新并写回寄存器
在周期7开始以后,两条irmovq指令才通过了写回阶段,此时指令addq恰好经过取指阶段才能取得更新之后的正确的值
如果只采用两条nop指令,考虑下面的情况

在周期6时,10被写入%rdx,但指令irmovq $3 %rax还处于访存阶段,%rax内的值还未更新,因此此时%rax内的值是错误的
如果只采用一条nop指令,考虑下面的情况

在周期5时,指令addq %rdx %rax进入取值阶段,而指令irmovq $10,%rdx处于写回阶段(而只有在时钟上升沿才能写入),此时10并未写入%rdx,同样指令irmovq $3,%rax处于访存阶段,%rax里也是错误的值
如果不采用nop指令,考虑下面的情况

同上面的情况一样,会得到错误的valA和valB
可以看到,由于addq指令的操作数依赖于前两条指令,因此他们之间形成了数据相关
通常有如下几种方法来避免数据冒险
1. 用暂停来避免数据冒险
暂停(stalling)是一种很常见的技术,当进行暂停时,处理器会停止流水线中的一条或多条指令,直至冒险条件不再满足。
把一条指令阻塞在译码阶段,直到它所需要的源操作数通过了写回阶段。当阻塞一条指令时,需要在这条指令的后面的阶段,也就是执行阶段插入气泡,气泡啥也不做,单纯的通过各个阶段并不会更新任何寄存器值。就像一个自动产生的nop指令一样。
通过插入气泡的方式来解决冒险问题是十分容易的,但是会带来严重的性能消耗,因为每个气泡都会减少一个时钟周期,严重的降低了性能。

2. 用转发来避免数据冒险
所谓转发,就是不等到将结果写回寄存器或者内存,直接将计算出的结果转发给后面需要用到这个结果的指令中,这种将结果值直接从一个流水线阶段传到较早阶段的技术称为数据转发

在这个例子中,周期6时,3还没写入%rax,但此时译码逻辑发现,寄存器%rax是操作数valB的源寄存器,而在写端口上还有一个对%rax的未进行的写,因此只要将W_valE信号作为操作数valB的值,无需等将3写回%rax,直接将3转发给addq指令的取指阶段就能避免暂停
转发需要额外的数据线路,所以需要稍微修改设计方式,增加一些额外的硬件。不过需要注意的是,如果指令A需要指令B更新的值,且两个指令紧挨着,那还是需要暂停一下的,因为即使是转发也必须等指令B执行到写回阶段且指令A未执行到执行阶段这两个条件才行。所以编译器进行优化时可能会错开两个相邻的指令使用同一个寄存器。
同时除了从写回阶段转发到执行阶段,也可以把值从执行阶段转发到译码阶段。
除此之外,也可以转发内存读出来的值给译码阶段。

旁路的引入使得我们的流水线完成了最终的实现,所以有五个转发源,分别是:e_valE, m_valM, M_valE, W_valM, W_valE和两个目的源:valA, valB。
转发源:
e_valE——执行阶段ALU的输出作为信号
m_valM——内存中读出来的值作为信号
M_valE——访存阶段的流水寄存器M值valE作为信号
W_valM——写回阶段寄存器文件端口M未进行的写作为信号
W_valE——写回阶段的流水线寄存器W的值valE作为信号
上图还表明,译码阶段应该确认要使用的值是来自寄存器文件还是转发过来的。通过比较目的寄存器ID与源寄存器IDsrcA和srcB来得到选择。同时为了处理多个目的寄存器ID和源寄存器ID相同的情况,需要建立优先级关系。
还可以看到。Fwd A和Fwd B用来处理转发的值。
3. 加载/使用数据冒险
有一类冒险不能通过转发解决,因为内存读在流水线中发生的比较晚,例如一条mrmovq指令要从内存某个位置读一个数到寄存器中,而下一条指令立即需要这个寄存器的值作为操作数,显然转发逻辑无法直接将这个值转发给下一条指令。
下图中0x028的指令mrmovq 0(%rdx),%rax在周期8将内存中的数读到寄存器%rax中,然而0x032: addq %ebx,%eax在周期7就需要%rax的值作为源操作数,显然无法通过转发将这个值传递给过去的时间,这就是加载/使用冒险

解决加载/使用冒险的方法是将暂停和转发结合起来,其原理是
假设一条指令B要从%rax中读,但上一条指令A要先访存后将值写入%rax,因而指令A在访存时,指令B已经到了执行阶段
我们可以将指令B暂停一个周期,这样指令A在访存时,指令B才刚到译码阶段,A可以通过m_valM将正确的值转发给B,解决加载/使用冒险
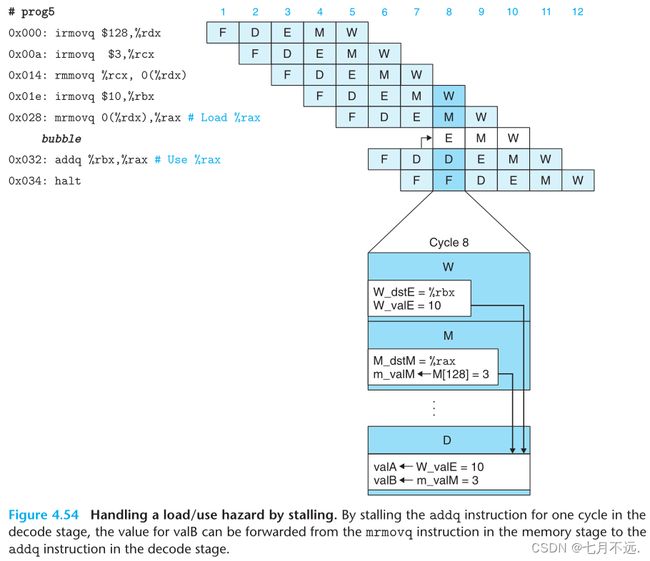
通过暂停来处理加载/使用数据冒险的方式称为加载互锁。加载互锁和转发技术可以应对所有的数据冒险类型。因为只有加载互锁才会浪费时钟周期,所以实际的流水线效率很高。
控制相关
当无法根据取指阶段的信息来确认下一条指令的地址时,就会出现控制冒险。控制冒险只会发生在ret指令和跳转指令。后一种只有在条件跳转预测错误时才会造成麻烦(默认预测跳转)
0x000: irmovq stack,%rsp # Initialize stack pointer
0x00a: call proc # Procedure call
0x013: irmovq $10,%rdx # Return point
0x01d: halt
0x020: .pos 0x20
0x020: proc: # proc:
0x020: ret # Return immediately
0x021: rrmovq %rdx,%rbx # Not executed
0x030: .pos 0x30
0x030: stack: # stack: Stack pointer对于这样一个汇编程序,下面给出了相应的处理ret指令的方法

由于ret指令是从内存中取出下一条指令的地址的,因此想要获得正确的地址必须完成访存阶段到达写回阶段,基于此,在ret指令的译码、执行和访存阶段,流水线都不能有任何活动,只需要填充三个气泡即可
下面的汇编程序是用来解释跳转指令是如何解决控制相关的
0x000: xorq %rax,%rax
0x002: jne target # Not taken
0x00b: irmovq $1, %rax # Fall through
0x015: halt
0x016: target:
0x016: irmovq $2, %rdx # Target
0x020: irmovq $3, %rbx # Target+1
0x02a: halt我们之前总是假设发生跳转,因此下一条指令的地址总是valC,而一条预测跳转指令只有在经过执行阶段时根据条件码和指令代码才能确定是否应该发生跳转,这个时候下两条指令分别处于译码和取指阶段,如果不应该跳转,那么这两条指令就都是错误的指令,不应该执行下去
我们只需要在流水线插入气泡来进行指令取消,将错误的两条指令取消即可

3. PIPE各阶段的实现
3.1 PC选择和取指阶段

这个阶段必须选择程序计数器的当前值,并预测下一个PC。
PC选择逻辑从三个程序计数器源中进行选择:
- 当一条预测错误的分支进入访存阶段时,会从流水线寄存器M(信号M_valA)中读出预测错误的指令地址
- 当ret指令进入访存阶段,从流水线寄存器W(信号W_valM)中读出返回地址。
- 其他情况使用存放在流水线寄存器F(信号F_predPC)中的值。
HCL表达式如下:
word f_pc = [
M_icode == IJXX && !M_Cnd : M_valA;
W_icode == IRET : W_valM;
1 : F_predPC;
];当取出的指令为函数调用或跳转时,PC预测逻辑会选择valC,否则会选择valP。
word f_predPC = [
f_icode in { IJXX, ICALL } : f_valC;
1 : f_valP;
];
3.2 译码和写回阶段

寄存器写的位置是由来自写阶段的dstE和dstM信号指定的,而不是来自于译码阶段。因为它要写的是当前正在写阶段执行的指令的结果,而不是在译码阶段的指令,他们并不是同一条指令,所以不能自作聪明地更改dstE和dstM的来源。
流水线寄存器E的valA新值的HCL描述:
word d_valA = [
D_icode in { ICALL, IJXX } : D_valP;
d_srcA == e_dstE : e_valE;
d_srcA == M_dstM : m_valM;
d_srcA == M_dstE : M_valE;
d_srcA == W_dstM : W_valM;
d_srcA == W_dstE : W_valE;
1 : d_rvalA;
];上述HCL中的优先级是很重要的。如果优先级排列不准确,会造成流水线计算错误。
流水线化的实现应该总是给处于最早流水线阶段中的转发源以较高的优先级,因为它保存着程序序列中设置该寄存器的最近的指令。
还有一个就是状态寄存器,由于流水线寄存器W保存着最近已完成的指令的状态,所以很自然的要用这个值来表示整个处理器的状态。
word Stat = [
W_stat == SBUB : SAOK;
1 : W_stat;
];
3.3 执行阶段

一旦任何一条指令触发了异常,那么对于条件码的更新就会被禁止。所以可以看到,m_stat和W_stat作为信号输入Set CC模块,以此来决定是否进行更新条件码。同时可以看到,信号e_valE和e_dstE作为转发源,指向译码阶段。
3.4 访存阶段
