如何轻松应对偶发异常
作者:亦盏
在之前的文章中,我们已经介绍了如何通过 MSE 提供的无损上下线和全链路灰度这两个功能来消除变更态的风险,相信您已经能够在变更时得心应手。但是在应用运行过程中突然遇到流量洪峰、黑产刷单、外部依赖故障、慢 SQL 等偶发异常时,您如何能够继续轻松应对呢?
本文将通过介绍 MSE 微服务治理在三月的最新功能来告诉您答案。文章主要分为三部分,首先是 MSE 微服务治理的简介,然后是 MSE 全面消除变更态风险的回顾 ,最后是如何借助 MSE 微服务治理轻松应对线上偶发异常。
MSE 微服务治理简介
首先看一下微服架构的总览,相信读者朋友们对微服务都不陌生。在 JAVA 中比较主流的微服务框架就是 Dubbo 和 Spring Cloud,同时现在也有很多公司采用 Go、Rust 这些语言去构建自己的微服务。下图中浅绿色的这一部分都是纯开源的内容,除了微服务框架本身外,还包含了服务注册发现、服务配置中心、负载均衡等一系列的组件。
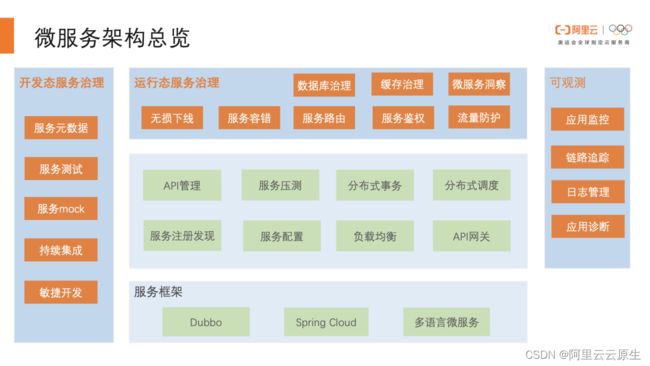
大家也发现,在微服务实施的过程中,随着微服务的增多、调用链路的复杂化,出问题和故障的可能性都在增加,问题定位的难度也成倍上升。比如说在可观测领域,需要使用到应用监控、链路追踪、日志管理等功能,才能放心地将应用部署到线上,以免出现问题无法定位。
更进一步,微服务本身更需要引入微服务治理。在开发态,需要通过服务 mock、服务测试、服务元数据等治理功能去保证微服务的快速迭代;在变更态,需要借助无损上下线和全链路灰度功能去保证发布时的稳定性,以及业务的连续性;在运行态,微服务可能遇到各式各样的偶发异常,需要借助治理功能去实现流量的自愈,保证我们的业务稳定、流畅地运行。很难想象一个线上的微服务应用没有治理是个什么场景,可以说是无 治理、不生产。
随着使用微服务架构的公司越来越多,大家也都意识到微服务治理非常重要,但是在实施微服务治理的过程中,大家还是遇到了比较多的痛点和难点。我们总结了一下,企业在实施微服务的过程中遇到的三类问题,分别是稳定、成本和安全。
- 首先是稳定的问题
-
- 微服务在发布的过程中特别容易出现问题,每次发布都得熬夜以避开业务高峰期,而且还是免不了出现业务中断。
- 当遇到难得的业务爆发式增长时,应用因为无法承载流量高峰导致整体宕机,错失了业务爆发的机会。
- 在出现一些偶发异常的时候,应用没有完善的防护和治愈手段,可能会因为偶发的小异常,不断的滚雪球,最终去拖垮我们整个集群和整个服务。
- 遇到偶发问题的无法准确定位和彻底解决,只能重启方式规避,从而使得我们微服务的隐患越积越多,风险越来越大。
- 第二是成本的问题
-
- 微服务治理功能在开源没有完善的解决方案,这个时候可能是需要去招聘大量精通微服务的人才,才能自建一套微服务治理体系,但是也无法覆盖完整的治理场景。这会使得人力成本非常高。
- 引入了微服务之后,基本都会有一些敏捷开发、快速迭代的诉求。在这个过程中,需要维护多套环境以维持一个并行开发迭代的需求,这会使得机器成本非常高。
- 传统的开发模式,当需要引入一个治理功能升级的时候,需要先升级基础组件,再对所有的应用进行代码改造,依次发布才能完成升级,改造的周期长、风险大。这会使得时间成本非常高。
- 最后是安全的问题
-
- 经常会有一些开源的框架的安全漏洞被暴露出来,这个时候需要对依赖进行升级以修复 Bug,走一次完整的发布才能实现,成本高,时效性差。
- 零信任安全的解决方案正在被越来越多的公司采用,去保障整体的业务安全。不仅是在流量入口层对业务进行安全的保障,在应用间的内部调用也需要有完整的鉴权和保障机制。
那么 MSE微服务治理是怎么去解决这三个问题的?
MSE 的微服务治理基于开源的 OpenSergo 标准实现了无侵入的微服务治理。对于使用者来说升级成本是零,业务是完全无侵入感知的。
目前已经可以做到是五分钟接入,半小时内就学会完整的使用,保障微服务应用在变更态和运行时的稳定性。因为 OpenSergo 是全面开源标准,不会有任何的厂商绑定的问题。
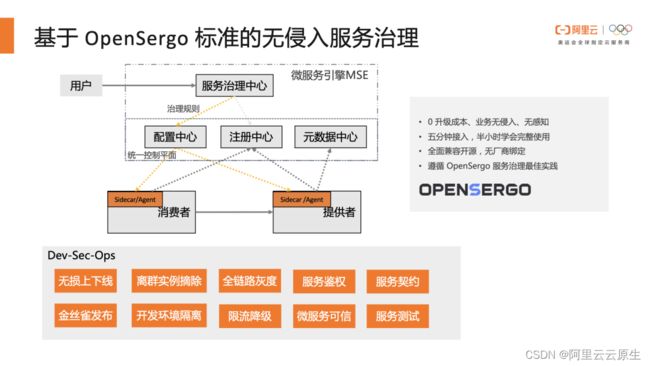
从上图中可以看出,微服务应用可以通过 Java Agent 或 Sidecar 的方式接入MSE 微服务治理。在接入治理后,可以通过 MSE 微服引擎的控制面配置治理规则的配置。应用收到规则之后会实时生效,及时地保护应用。
全面消除变更态风险的回顾
现在来回顾一下,变更态存在哪些问题,以及 MSE 是如何全面消除变更态风险的。
首先问大家一个问题,当你的代码没有问题的时候,是不是在发布的过程中就一定不会影响到业务? 答案其实是否定的,因为这个时候可能会遇到无损上下线的问题。
为什么会出现无损下线问题?第一个原因是服务消费者无法实时感知到服务提供者已经下线了,仍旧会去调用一个已经下线的地址,从而出现一个影响业务的报错。同时服务提供者也可能会在请求处理到一半的时候就直接停止了,从而导致业务报错,甚至出现数据不一致的问题。
为什么会出现无损上线的问题?一个新启动的节点,有可能在还没完全启动前就注册到注册中心了,进而导致这时候过来的流量无法被正确处理导致报错;另一种情况是,虽然应用启动完成了,但是还没有处理大流量的能力,可能直接被大流量压垮,需要先进行预热,才能处理大流量的请求。除此之外,目前 K8s 的普及率已经非常高了,如果微服务的生命周期没有与 K8s 生命周期做一个的 readiness 对齐的话,发布过程也容易出现无损上线问题。
当然更普遍的情况是,谁都不敢拍着胸脯保证我的代码没有问题。 如果没有稳定的灰度机制,对只有两个节点的应用来说,发布一台就会影响 50% 的业务。发现 bug 之后需要回顾,可怕的是回滚的速度还非常慢,甚至回滚的时候还出现了更大的问题。
那么 MSE 是如何去解决这两个问题的。首先我们看一下这个无损下线的这个问题。对于一个已经接入了MSE 微服务治理的应用,无损下线功能是默认开启的,我们可以在 MSE 的控制台中看到无损下线的完整的流程。
- 首先在无损下线开始时,sc-B 这个服务的提供者 10.0.0.242 会提前向注册中心发起注销动作。
- 注销之后,10.0.0.242 会去主动去通知它的服务消费者当前节点已下线。上图中的例子,服务 sc-B 的消费者 10.0.0.248 和 10.0.0.220 这两个消费者收到了下线通知。
- 10.0.0.248 和 10.0.0.220 在收到下线通知后,都会把 10.0.0.242 的地址维护在 offlineServerIp 列表中,并且找到 sc-B 对应的调用列表,在调用列表中移除 10.0.0.242 这个 IP
- 同时,10.0.0.242 在停止的过程中会做一个自适应的等待,确保所有在途请求都处理完毕才停止应用。
我们再看一下这个无损上线的这个问题。对于一个已经接入了 MSE 微服务治理的应用,可以通过控制台开启无损上线功能,开启后,我们可以在 MSE 的控制台中看到无损上线的完整的流程。
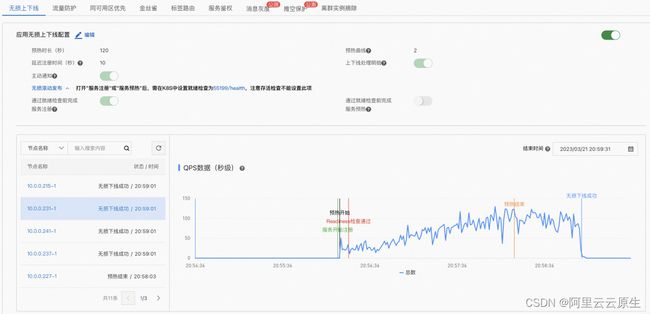
从上图中我们可以看到,应用配置的延迟注册时间是 10S,预热时间是 120S,预热曲线是拟合二次曲线。根据 QPS 数据可以看到,应用在注册完成之后才有流量进入,同时在预热开始后 120S 内,流量是一个缓慢上升的过程,直到预热结束之后,流量才开始进入平稳的状态。
看完了在代码没问题的情况下如何保证变更态的稳定性,我们在看看当代码可能存在问题的时候,如何保障变更态的稳定性。
拿一个简单的架构作为例子,微服务的整体调用链路是网关调用 A,A 调用 B ,B 再调用 C 这么一个链路。某次迭代中,有个特性的修改需要同时修改 A 和 C 这两个应用。
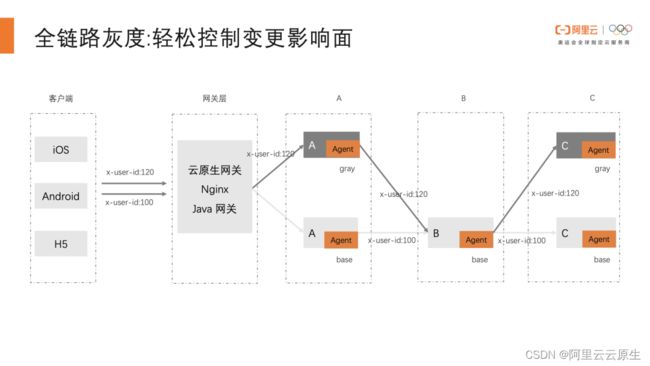
在发布的过程中,需要通过全链路灰度发布来验证 A 的新版本和 C 的新版本的正确性。假设 x-user-id 为 120 的用户是我们一个不那么重要的用户。那么我们可以配置只有 x-user-id 为 120 的这一个用户,他才会访问新版本。
在具体的调用中,网关会先访问 A 的灰度版本,A 在调用 B 的时候发现 B 没有一个灰度的版本,所以只是 fall back 到 B 的基线版本。但是 B 在调用 C 的时候,还是记住了 x-user-id 为 120 的流量属于一个灰度流量。同时又发现 C 存在灰度节点,流量还是会重新回到 C 的灰度节点。
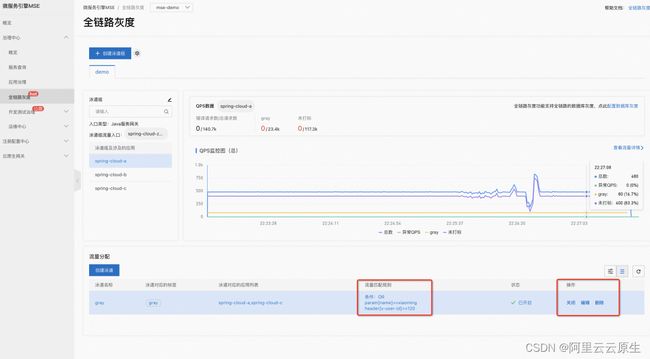
如上图所示,可以通过 MSE 全链路灰度控制新版本的影响面。将参与到全链路灰度的应用添加到泳道组后,配置如上图所示的规则,只有 x-user-id 为 120 的这个用户他才会被路由到新版本。也就是说即使这个新版本问题再大,那只是这一个用户会受到影响。同时做一个回滚的动作也是非常方便的,只需要把灰度规则关闭或者删除即可,就不会有流量被路由到新版版本。经过灰度的谨慎验证后,可以视情况继续扩大灰度的影响面,或者直接全量发布,从而实现安全的版本变更。
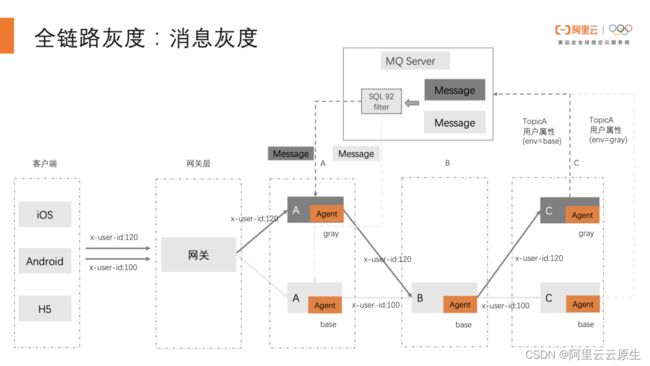
刚才我们也提到过,全链路灰度其实是一个非常复杂的过程,除了 RPC 的灰度外,还包含了前端灰度、消息灰度、异步任务灰度、数据库灰度等场景,这些场景 MSE 都做了一些探索和支持。以消息灰度为例, MSE 已经完整地支持了 RocketMQ 的灰度,实现了全链路灰度的闭环,是一个久经生产考验的全链路灰度。
以上是 MSE 全面消除变更态风险的回顾。
如何轻松应对偶发异常
在回顾了一下 MSE 是如何做到全面消除变更态风险之后。我们来看一下 MSE 微服务治理在三月份新上线的这些功能,如何帮助大家轻松应对偶发异常。
我们做了大致的总结和归类,将偶发异常的情况分为了两部分:异常流量和不稳定服务依赖。
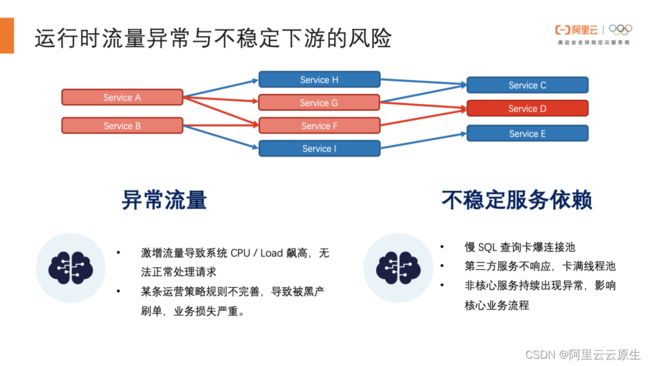
接下来我们将面向这两个大类下五个小类的场景,来阐述如何借助 MSE 微服务治理三月份发布的新功能去解决这些偶发异常的。
接口限流
首先我们看一下激增流量这一块。拿一个具体的场景来说,业务方精心准备了一个大促活动,活动非常火爆,在活动开始的一瞬间,远远超过系统承载预期的用户进来抢购秒杀,如果没有微服务治理能力,服务可能由于扛不住流量直接被打挂,甚至在重启的过程还不断被打挂。精心准备的活动由于系统宕机导致效果非常差,在遇到难得的业务爆发式增长机会时,却因为应用的宕机错失了爆发的机会。
在这个场景下,可以借助 MSE 的流控能力对关键接口配置流控规则保护应用整体的可用性。只让容量范围内的请求被处理,超出容量范围外的请求被拒绝,相当于这是一个安全气囊的作用。
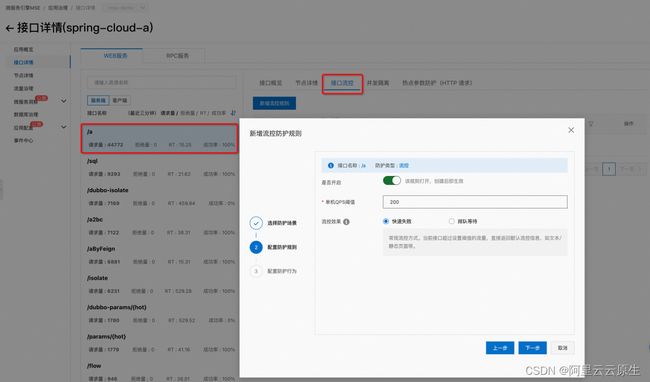
如上图所示, /a 这个接口是我们应用的关键接口,我们识别到单机阈值是 200 后,配置上流控防护规则,使得这个关键接口最大的通过 QPS 是 200,超出阈值的流量会直接被拒绝,从而保护应用整体的可用性。
精准限流
接下来我们再看一下精准限流,拿一个具体的场景来说,由于在配置优惠活动的时候没有配置好最大次数,或者存在规则上的漏洞。在被黑产发现后不断地进行在刷单,业务损失严重。在这个场景下,我们可以借助 MSE 的精准限流能力实现防黑产刷单。
MSE 的精准限流可以在 API 的维度基础上,基于流量的特征值来进行限流,比如根据调用端的 IP,参数中的某一个参数的值,或者说 HTTP 请求里 header 的特征等。

如上图所示,当我们识别到黑产用户的特征之后,可以根据 header 里面 key 为 user-id 的值来进行精准的业务限流,这里配置的规则为每天只能通过一次,也就意味着黑产流量被识别到之后,一天内超出一次的调用都会被拒绝,这样就能有效地防止黑产刷单保护业务。
并发隔离
第三部分是并发隔离,拿一个具体的场景来说,假设我们的应用依赖了一个第三方的支付渠道,但是因为渠道本身的原因出现了大量的慢调用,进而导致了应用全部的线程池都被调用该支付渠道的调用占满了,没有线程去处理其他正常的业务流程。而且这个第三方的支付其实只是我们其中的一个支付渠道。我们其他的支付渠道都是正常的。
MSE 可以对应用作为客户端的流量进行并发隔离,限制同时调用这个第三方支付渠道的最大并发数,从而留下充足的资源来处理正常的业务流量。
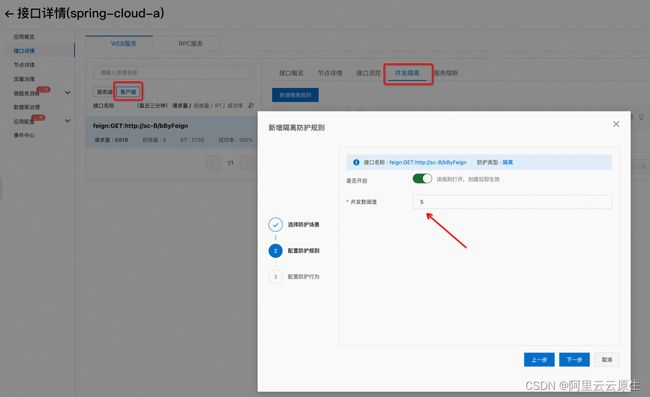
如上图所示,我们配置了并发数阈值是 5,每个应用节点最多同时存在 5个并发去调用第三方支付服务,当调用数超过了 5 的时候,请求在发起前就会直接被拒绝。通过并发隔离,把不稳定的支付渠道隔离到有限的影响面,而不会挤占其他正常支付渠道的资源,这样来保障我们一个业务的稳定性。
SQL 防护
第四部分是 SQL 防护,拿一个具体的场景来说,应用更新后出现了慢 SQL 的语句,处理的时间比较长的,这个时候需要快速定位慢 SQL ,然后防止我们这个应用去被这个慢 SQL 拖垮了。或者在项目的初期可能没有对这个 SQL 的性能做一个很好的考量,然后随着业务的发展,业务量级的增加,然后导致线上遗留老 SQL 逐渐腐化,成为了一个慢 SQL。
MSE 的数据库治理功能,可以自动统计应用的 SQL语句,以及 SQL 的 QPS、平均耗时 和最大并发等数据,并针对于 SQL 进行一个防护。

如上图所示,在平均耗时中找到慢 SQL,点击右边的 SQL 防护按钮,通过配置并发隔离规则来进行保护应用不被慢 SQL 拖垮。
服务熔断
最后我们再来看一下服务熔断。拿一个具体的场景来说,在业务高峰期查询积分服务达到性能瓶颈,导致响应速度慢、报错增多。但是它并不是一个关键的服务,这时不能因为无法查询积分余额而导致整个流程都无法进行。正确的逻辑应该是积分余额暂时不显示,但是除此之外其他主流程都能正常完成。
MSE 的服务熔断功能,可以很好地解决上述的问题。MSE 支持通过慢调用的比例,或者错误数去衡量一个服务是否处于正常状态,当识别到服务已经不正常的时候就自动触发熔断。熔断后消费者不会再去调用出问题的服务了,而是直接返回 Mock 值。

如上图所示,配置当异常比例超过 80% 的时候自动触发熔断,不再去调用不正常的服务。一方面消费者不再去调用不正常的弱依赖服务,不会因为弱依赖的问题导致主流程不正常。另一方面,熔断也给了不稳定的下游一些喘息的时间,让它有机会去恢复。
我们最后再来总结一下 MSE 微服治理是如何助您轻松应对线上偶发异常的,针对我们刚才总结的这五类场景:
- 当遇到激增流量的时候,我们应该使用接口限流。
- 当我们遇到黑产刷单等问题的时候,我们应该使用精准限流。
- 当第三方服务不响应,占满线程池的时候,我们应该使用并发隔离。
- 当应用存在慢 SQL 的时候,我们应该使用 SQL 防护。
- 当应用的弱依赖出现异常,影响我们核心业务流程的时候,我们应该使用服务熔断。
通过这五个功能,MSE 微服务治理可以助您去轻松去应对上述场景的一些偶发异常,后续 MSE 也会持续不断地去探索和拓展更多场景,更全面地保障您应用的运行时的稳定性。
结语
MSE 微服务治理致力于帮用户低成本构建安全、稳定的微服务。由于篇幅原因,更多的功能就不在这里给大家详细介绍了,关于 MSE 更多的详情,读者可以通过查看 MSE 帮助文档的了解详情。
MSE 帮助文档:
https://help.aliyun.com/document_detail/126761.html
欢迎感兴趣的同学扫描下方二维码加入钉钉交流群,一起参与探讨交流。
