LAMP架构9-mysql数据库MHA高可用的部署搭建
文章目录
- 1、MHA集群介绍
-
- 1.1 什么是MHA
- 1.2 MHA架构组成
- 1.3 MHA工作原理
- 2、MHA实现
-
- 2.1 准备
- 2.2 先搭建一主二从
- 2.3 MHA Manager部署
-
- 2.3.1首先停止之前安装的mysql路由服务:
- 2.3.2 MHA 安装准备
- 2.3.3 安装 MHA (server4)
- 3、MHA高可以切换方式
-
- 3.1 手动切换master
-
- 3.1.1 master存活状态切换
- 3.1.2 master宕机状态切换
- 3.2 自动切换master
- 3.3 通过vip手动/自动切换master
-
- 3.3.1 修改/etc/masterha/app1.cnf
- 3.3.2 修改配置文件
- 3.3.3 测试
1、MHA集群介绍
1.1 什么是MHA
传统的主从复制如果主库宕机,其余从库不会自动的代替主库继续工作,这样就不能保证业务的高可用,而MHA就是一个mysql主从复制高可用的解决方案,当主库宕机后,MHA能在1-30秒实现故障检测和故障自动转移,选择一个最优的从库作为主库,同时新的主库还继续与其他从库保持数据一致的状态。
1.2 MHA架构组成
整个MAH架构由两部分组成,即MHA Manager(管理节点),和MHA Node(数据节点),MHA Manager 可以独立部署到一台服务器上(含虚拟机)管理多个主从复制集群,也可已部署到一台主从复制从节点上或者其他应用程序上,而MHA Node 需要运行到每一台mysql服务器上 MHA Manager服务器 会定时通过主库上的MHA Node检测主库的运行状态,当主库出现故障时他可以将最优从库(可以提前指定或者由MHA判定)提升为新的主库,然后其他从库和新的主库重新保持新的复制状态。
1.3 MHA工作原理
-
主库实例挂掉但是ssh还能连接
1、监控到主库宕机,选择一个新的主,被选择的新主会取消从库的角色( reset slave)
选择标准:
一是根据其他从库的binlog日志的位置选择最新的从库作为新的主库
二是如果设置了半同步从库,直接选择半同从库作为新的主库
2、从库通过MHA自带的脚本程序,通过ssh向主库索取缺失部分的binlog
3、其他从库与新的主库从新构建主从,继续提供服务
4、如果由vip机制,将VIP从原来的主库漂移到新的主库,让应用无感知 -
主节点服务器宕机(ssh已经连接不上了)
1、监控到主机宕机后,尝试ssh连接,连接失败
2、通过上边所讲的选择标准选择新的主库
3、计算从库之间的relay-log的差异,补偿到新的其他从库
4、其他从库从新与新主构建主从关系,继续提供服务
5、如果由VIP机制,将VIP从原主漂移到新主,让应用无感知
6、如果有binlog server 机制,会继续将binlog server中缺失的事物,补偿到新的主库
2、MHA实现
2.1 准备
四台虚拟机,三台做node(一主二从),一台做manager
| IP | 主机名 | 作用 |
|---|---|---|
| 172.25.200.1 | server1 | node(主) |
| 172.25.200.2 | server2 | node(从) |
| 172.25.200.3 | server3 | node(从) |
| 172.25.200.4 | server4 | manager |
2.2 先搭建一主二从
node(主)的设置
[root@server1 ~]# /etc/init.d/mysqld stop
[root@server1 ~]# rm -fr /data/mysql/*
[root@server1 ~]# vim /etc/my.cnf
[mysqld]
basedir=/usr/local/mysql
datadir=/data/mysql
socket=/data/mysql/mysql.sock
server-id=1 ##实现功能的重要参数
gtid_mode=ON
enforce-gtid-consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
log_slave_updates=ON
log_bin=binlog ##实现功能的重要参数
binlog_format=ROW
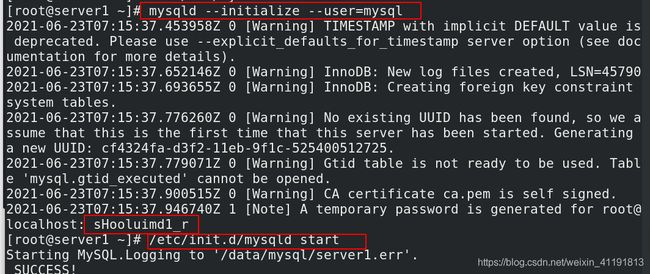
[root@server1 ~]# mysqld --initialize --user=mysql
[root@server1 ~]# /etc/init.d/mysqld start
[root@server1 ~]# mysql -p
Enter password:
mysql> alter user root@localhost identified by 'westos';
Query OK, 0 rows affected (0.01 sec)
mysql> grant replication slave on *.* to repl@'%' identified by 'westos';
Query OK, 0 rows affected, 1 warning (0.02 sec)
mysql> show master status;
mysql> quit
Bye
node(从)的设置(一模一样,这里以server2为例子)
[root@server2 ~]# /etc/init.d/mysqld stop
[root@server2 ~]# rm -fr /data/mysql/*
[root@server2 ~]# vim /etc/my.cnf
[mysqld]
basedir=/usr/local/mysql
datadir=/data/mysql
socket=/data/mysql/mysql.sock
server-id=2 ##实现功能的重要参数
gtid_mode=ON
enforce-gtid-consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
log_slave_updates=ON
log_bin=binlog ##实现功能的重要参数
binlog_format=ROW
[root@server2 ~]# mysqld --initialize --user=mysql
[root@server2 ~]# /etc/init.d/mysqld start
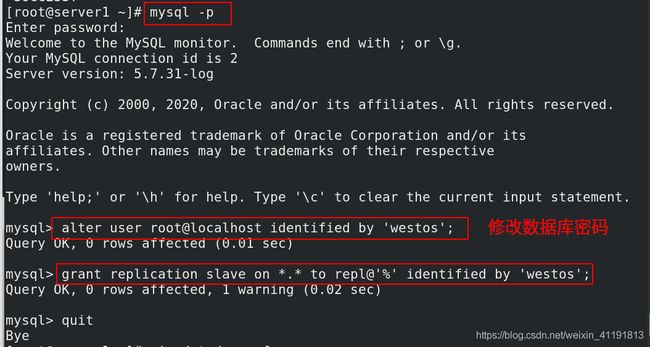
[root@server2 ~]# mysql -p
Enter password:
mysql> alter user root@localhost identified by 'westos';
Query OK, 0 rows affected (0.01 sec)
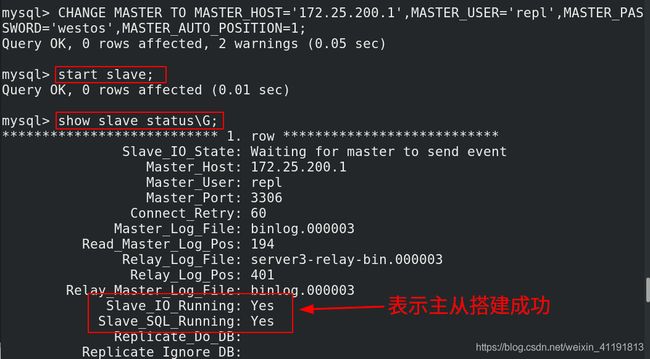
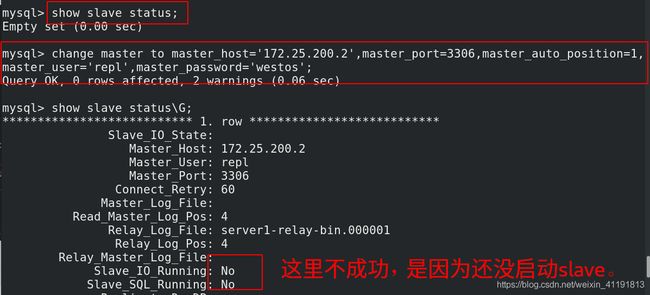
mysql> CHANGE MASTER TO MASTER_HOST='172.25.200.1',MASTER_USER='repl',MASTER_PASSWORD='westos',MASTER_AUTO_POSITION=1;
Query OK, 0 rows affected, 2 warnings (0.05 sec)
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.25.200.1
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: binlog.000003
Read_Master_Log_Pos: 194
Relay_Log_File: server3-relay-bin.000003
Relay_Log_Pos: 401
Relay_Master_Log_File: binlog.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...
...
2.3 MHA Manager部署
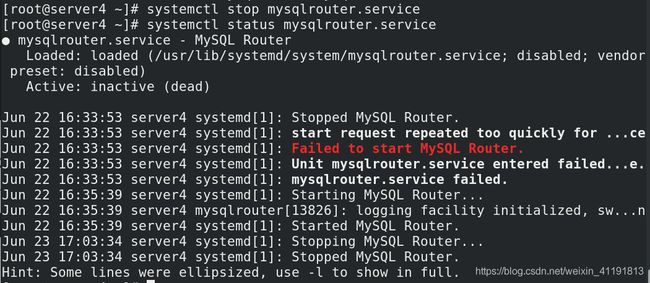
2.3.1首先停止之前安装的mysql路由服务:
[root@server4 ~]# systemctl stop mysqlrouter.service
2.3.2 MHA 安装准备
- Manager工具包主要包括以下几个工具:
masterha_check_ssh #检查MHA的SSH配置状况
masterha_check_repl #检查MySQL复制状况
masterha_manger #启动MHA
masterha_check_status #检测当前MHA运行状态
masterha_master_monitor #检测master是否宕机
masterha_master_switch #控制故障转移(自动或者手动)
masterha_conf_host #添加或删除配置的server信息
- Node工具包(由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
save_binary_logs #保存和复制master的二进制日志
apply_diff_relay_logs #识别差异的中继日志事件并将其差异的事件应用于其他的slave
filter_mysqlbinlog #去除不必要的ROLLBACK事件(MHA已不再使用这个工具)
purge_relay_logs #清除中继日志(不会阻塞SQL线程)
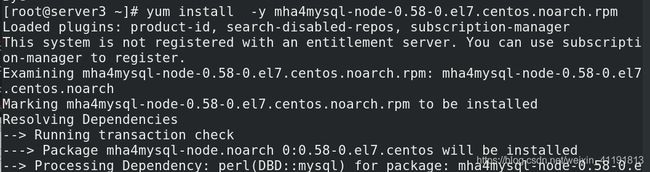
在server4上安装MHA


配置免密:

将node工具包发送到server1/2/3,并安装:
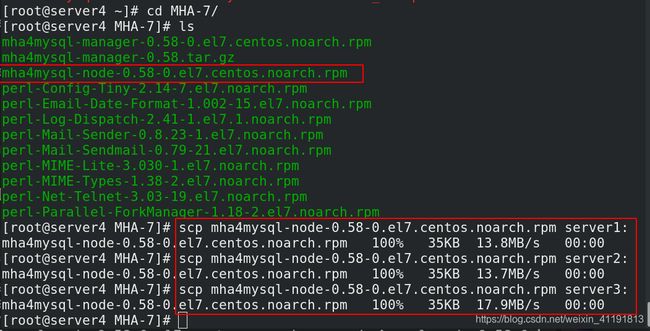


2.3.3 安装 MHA (server4)
参数模板:
- # vim /etc/masterha/app.conf
[server default]
manager_workdir=/usr/local/mha #manager工作目录
manager_log=/usr/local/mha/mha.log #manager日志文件
master_binlog_dir=/var/lib/mysql #mysql主服务器的binlog目录
#master_ip_failover_script=/usr/bin/master_ip_failover #failover自动切换脚本
#master_ip_online_change_script= /usr/local/bin/master_ip_online_change #手动切换脚本
user=root #mysql主从节点的管理员用户密码,确保可以从远程登陆
password=westos
ping_interval=3 #发送ping包的时间间隔,默认是3秒,尝试三次没有回应的时候自 动进行failover
remote_workdir=/tmp #远端mysql在发生切换时binlog的保存位置
repl_user=wxh #主从复制用户密码
repl_password=westos
#report_script=/usr/local/send_report #发生切换后发送报警的脚本
#secondary_check_script=/usr/bin/masterha_secondary_check -s 172.25.0.4 -s 172.25.0.3
#shutdown_script="" #故障发生后关闭故障主机脚本,防止脑裂
ssh_user=root #ssh用户名
[server1]
hostname=172.25.200.1
port=3306
#candidate_master=1
#check_repl_delay=0
[server2]
hostname=172.25.20.2
port=3306
candidate_master=1 #指定failover时此slave会接管master,即使数据不是最新的。
check_repl_delay=0 #默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
[server3]
hostname=172.25.200.3
port=3306
#no_master=1 #始终是slave
操作步骤:
[root@server4 MHA-7]# ls
mha4mysql-manager-0.58.tar.gz
[root@server4 MHA-7]# tar zxf mha4mysql-manager-0.58.tar.gz
[root@server4 MHA-7]# cd mha4mysql-manager-0.58/
[root@server4 mha4mysql-manager-0.58]# mkdir /etc/masterha #创建工作目录
[root@server4 mha4mysql-manager-0.58]# cd samples/conf/
[root@server4 conf]# cp app1.cnf /etc/masterha/
[root@server4 conf]# cd /etc/masterha/
[root@server4 masterha]# vim app1.cnf
[server default]
user=root
password=westos
ssh_user=root
master_binlog_dir= /data/mysql
remote_workdir=/tmp
secondary_check_script= masterha_secondary_check -s 172.25.200.1 -s 172.25.200.2
ping_interval=3
# master_ip_failover_script= /script/masterha/master_ip_failover
# shutdown_script= /script/masterha/power_manager
# report_script= /script/masterha/send_report
# master_ip_online_change_script= /script/masterha/master_ip_online_change
manager_workdir=/etc/masterha/app1
manager_log=/var/log/masterha/app1/manager.log
repl_user=repl
repl_password=westos
[server1]
hostname=172.25.200.1
[server2]
hostname=172.25.200.2
candidate_master=1
check_repl_delay=0
[server3]
hostname=172.25.200.3
[root@server4 masterha]# mkdir app1 ##创建工作目录
[root@server4 masterha]# masterha_check_ssh --conf=/etc/masterha/app1.cnf
## 测试SSH连接
保证所有节点相互免密:
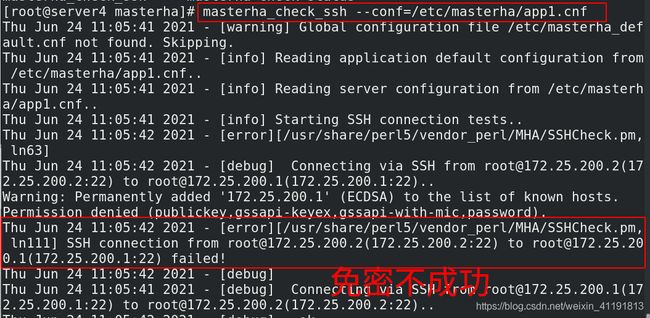
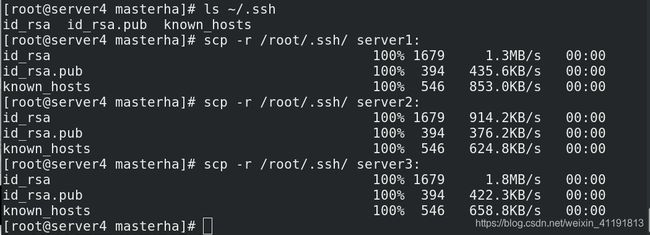
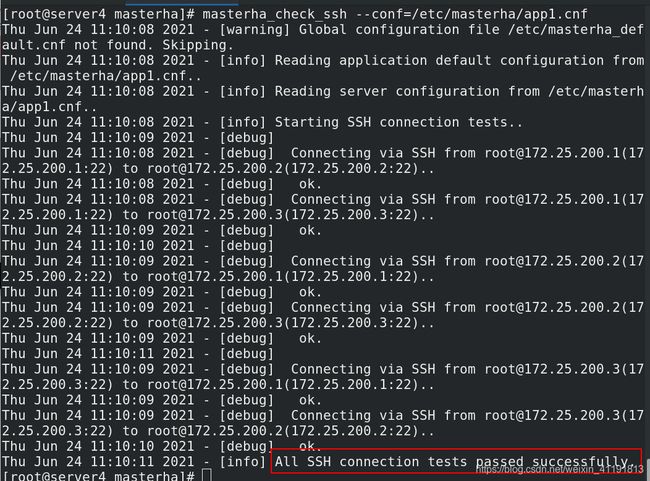


这里MHA就实现了
3、MHA高可以切换方式
3.1 手动切换master
- MHA的故障切换过程,共包括以下的步骤:
1.配置文件检查阶段,这个阶段会检查整个集群配置文件配置
2.宕机的master处理,这个阶段包括虚拟ip摘除操作,主机关机操作
3.复制dead maste和最新slave相差的relay log,并保存到MHA Manger具体的目录下
4.识别含有最新更新的slave
5.应用从master保存的二进制日志事件(binlog events)
6.提升一个slave为新的master进行复制
7.使其他的slave连接新的master进行复制
3.1.1 master存活状态切换
masterha_master_switch --conf=/etc/masterha/app1.cnf --master_state=alive --new_master_host=172.25.200.2 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000
测试方法:直接server4(MHA)上输入命令

询问一路yes即可


3.1.2 master宕机状态切换
masterha_master_switch --master_state=dead --conf=/etc/masterha/app1.cnf --dead_master_host=172.25.200.2 --dead_master_port=3306 --new_master_host=172.25.200.1 --new_master_port=3306 --ignore_last_failover
# --ignore_last_failover 忽略最后一次的切换文件
测试方法,将server2 mysql服务关闭,到server4(MHA)上输入上面代码
[root@server2 ~]# /etc/init.d/mysqld stop
Shutting down MySQL............ SUCCESS!

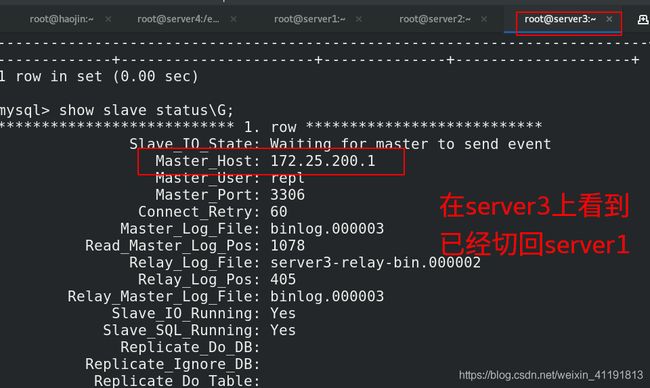
随后我们启动server2的服务,并再次将其加入

3.2 自动切换master
- MHA在线切换的大概过程:
1.检测复制设置和确定当前主服务器
2.确定新的主服务器
3.阻塞写入到当前主服务器
4.等待所有从服务器赶上复制
5.授予写入到新的主服务器
6.重新设置从服务器
- 为了保证数据完全一致性,在最快的时间内完成切换,MHA的在线切换必须满足以下条件才会切换成功,否则会切换失败。
1.所有slave的IO线程都在运行
2.所有slave的SQL线程都在运行
3.所有的show slave status的输出中Seconds_Behind_Master参数小于或者等于running_updates_limit秒,如果在切换过程中不指定running_updates_limit,那么默认情况下running_updates_limit为1秒。
4.在master端,通过show processlist输出,没有一个更新花费的时间大于running_updates_limit秒。
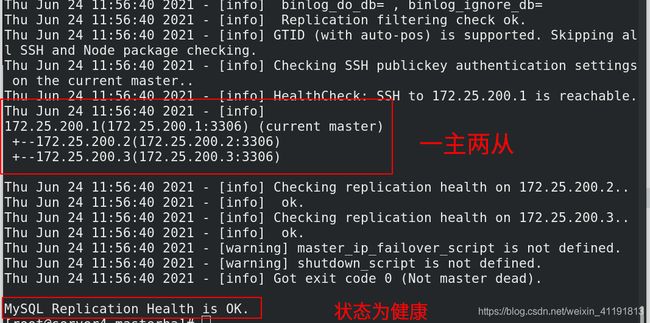
[root@server4 masterha]# masterha_manager --conf=/etc/masterha/app1.cnf &
#后台运行


测试:
关闭当前master,自动切换到server2。



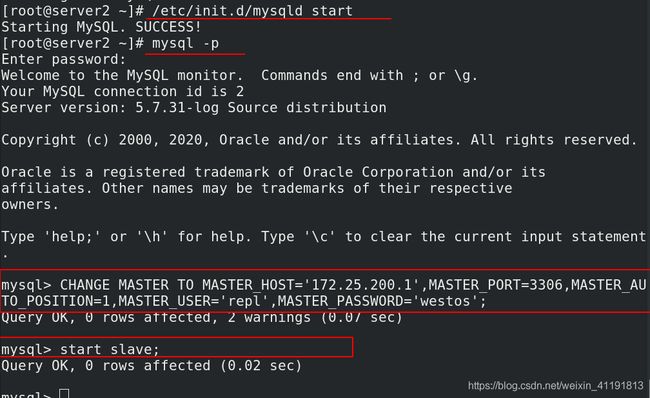
最后将server1服务启动,并再次加入主从:
[root@server1 ~]# /etc/init.d/mysqld start
Starting MySQL. SUCCESS!
[root@server1 ~]# mysql -pwestos
mysql> change master to master_host='172.25.200.2',master_port=3306,master_auto_position=1,master_user='repl',master_password='westos';
Query OK, 0 rows affected, 2 warnings (0.06 sec)
mysql> start slave;
Query OK, 0 rows affected (0.02 sec)
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.25.200.2
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: binlog.000004
Read_Master_Log_Pos: 234
Relay_Log_File: server1-relay-bin.000002
Relay_Log_Pos: 361
Relay_Master_Log_File: binlog.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes

3.3 通过vip手动/自动切换master
之前做过pacemaker的实验,需要关掉pacemaker
- pcs cluster stop
- pcs cluster disable
修改配置文件,一定要确保文件存在
文件内容如下:
master_ip_failover文件:
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
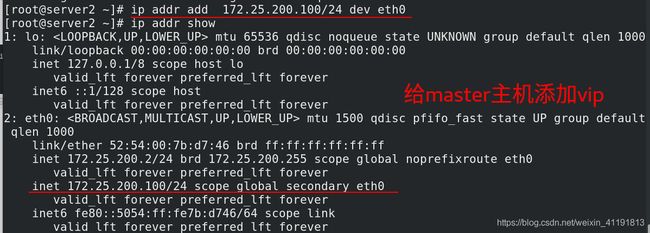
my $vip = '172.25.200.100/24';
my $ssh_start_vip = "/sbin/ip addr add $vip dev eth0";
my $ssh_stop_vip = "/sbin/ip addr del $vip dev eth0";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
sub stop_vip() {
return 0 unless ($ssh_user);
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
master_ip_online_change文件内容:
#!/usr/bin/env perl
use strict;
use warnings FATAL =>'all';
use Getopt::Long;
my $vip = '172.25.200.100/24';
my $ssh_start_vip = "/sbin/ip addr add $vip dev eth0";
my $ssh_stop_vip = "/sbin/ip addr del $vip dev eth0";
my $exit_code = 0;
my (
$command, $orig_master_is_new_slave, $orig_master_host,
$orig_master_ip, $orig_master_port, $orig_master_user,
$orig_master_password, $orig_master_ssh_user, $new_master_host,
$new_master_ip, $new_master_port, $new_master_user,
$new_master_password, $new_master_ssh_user,
);
GetOptions(
'command=s' => \$command,
'orig_master_is_new_slave' => \$orig_master_is_new_slave,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'orig_master_user=s' => \$orig_master_user,
'orig_master_password=s' => \$orig_master_password,
'orig_master_ssh_user=s' => \$orig_master_ssh_user,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
'new_master_user=s' => \$new_master_user,
'new_master_password=s' => \$new_master_password,
'new_master_ssh_user=s' => \$new_master_ssh_user,
);
exit &main();
sub main {
#print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
# $orig_master_host, $orig_master_ip, $orig_master_port are passed.
# If you manage master ip address at global catalog database,
# invalidate orig_master_ip here.
my $exit_code = 1;
eval {
print "\n\n\n***************************************************************\n";
print "Disabling the VIP - $vip on old master: $orig_master_host\n";
print "***************************************************************\n\n\n\n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
# all arguments are passed.
# If you manage master ip address at global catalog database,
# activate new_master_ip here.
# You can also grant write access (create user, set read_only=0, etc) here.
my $exit_code = 10;
eval {
print "\n\n\n***************************************************************\n";
print "Enabling the VIP - $vip on new master: $new_master_host \n";
print "***************************************************************\n\n\n\n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
`ssh $orig_master_ssh_user\@$orig_master_host \" $ssh_start_vip \"`;
exit 0;
}
else {
&usage();
exit 1;
}
}
# A simple system call that enable the VIP on the new master
sub start_vip() {
`ssh $new_master_ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIP on the old_master
sub stop_vip() {
`ssh $orig_master_ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
3.3.1 修改/etc/masterha/app1.cnf

3.3.2 修改配置文件
文件内容在上面给出

加可执行权限:

3.3.3 测试


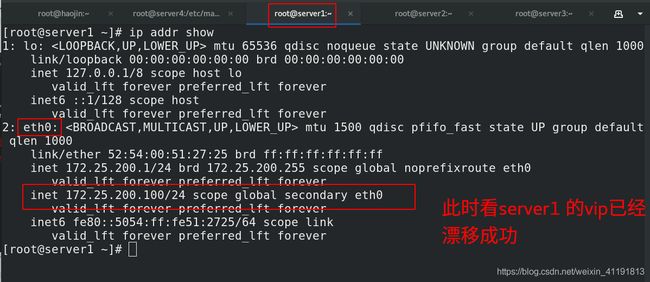
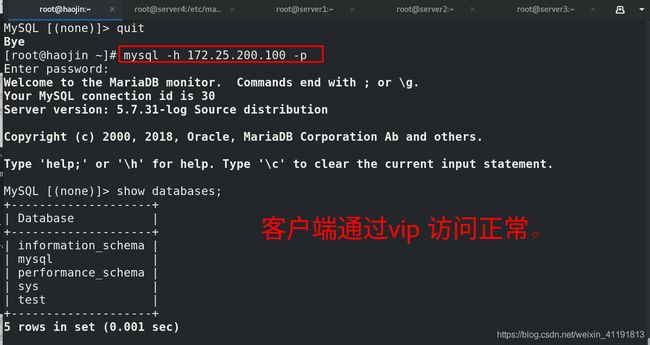
最后将server2手动加到集群中即可:
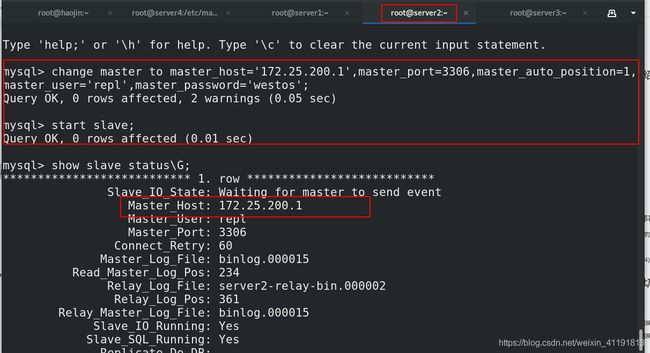
MHA 配置到这里结束