盘点近期重大技术成就及其将带给你的影响,与你我息息相关!
原文标题:Key Highlights in Data Science / Deep Learning / Machine Learning 2017 and What can we Expect in 2018?
作者:FAIZAN SHAIKH
翻译:杨金鸿
校对:丁楠雅
本文长度为6500字,建议阅读14分钟
本文列举了一些在2017年发生在数据科学行业的开创性事件。以及这些事件对数据科学专业人士的影响。还展现了在不远的将来可以看到这些技术的发展路径。
简介
对于数据科学专业人士来说,2017年是激动人心的一年。这一点在新技术的应用方面尤其显而易见,比如人脸识别技术已经彻底改变了我们在移动电话中获取信息的方式;自动驾驶汽车曾经是一个神话,但现在已经成为现实。如今,世界各地的政府都在发展自动驾驶技术。
数据科学是一个新的领域,与以往其他新兴技术相比,突破性的研究正在以更快的速度进行着。从研究到实施的时间已经大大减少了。这是由于大量的免费资源提供给每个人使用,使得普通人能够自主开展研究。例如,Andrew Ng曾经说过GitHub(一个软件开发协作平台)正在为研究想法的实现铺平道路。
个性化和自动化是当今时代的话题,越来越多的行业如金融服务,医疗保健,制药和汽车行业正在适应由机器学习/深度学习技术带来的发展。本文特别聚焦了2017年数据科学的决定性瞬间。我们按如下准则整理了一份列表:
作为一名数据科学专业人士,这些事件对你有影响吗?
这些事件会影响到你的学习或者日常工作吗?
它是创新创业公司、产品发布还是最新进展?
它是否需要产业合作,会影响数据科学的未来吗?
此外,我们也分享了我们对2018年的预测,我们相信这将是一件值得期待的事情。
2017年的有趣片段
PowerBlox开发了一种可扩展的能源设备,可以从各种输入中存储和分配电能(https://www.treehugger.com/renewable-energy/new-energy-storage-product-uses-swarm-intelligence-create-autonomous-micro-grids.html)。
标签——创业公司,可再生能源

一家年轻的公司PowerBlox正在使用算法提供电力网“群智能”。“Power-Blox 给电力网提供了自动适应电能负载的可伸缩电源”。这是一项非常重要的技术,因为我们使用的风能、太阳能和潮汐能源,每分钟是变化的,这项技术将使可再生能源变得更可用。
Neuralink:一种高带宽的安全的人机交互技术
标签——创业,创新

2017年,埃隆马斯克宣布成立了一家名为“Neuralink”的公司,该公司的目标是建立高带宽的安全的人机交互技术。埃隆想将矩阵技术带到现实生活中,学习新技能。例如驾驶直升机只需将电线插入新大脑皮质,这一切听起来像是夸张的科幻,但在埃隆心中一直认为它是真实的,比如特斯拉和SpaceX。
如果这一切都成真了,人类很快就会开发出研究和绘制大脑的技术。这对大幅改善医疗保健以及提升人类能力有着深远的影响。埃隆是认真的。该公司最近获得了2700万美元的融资,并计划通过其股票另外募集1亿美元资金。对我们普通人来说,可以打开标题链接去了解它是如何开始的,如果它成为现实将会多么伟大,足以改变人类的未来。
肯德基中国使用人脸识别支付
标签——创新,零售行业,计算机视觉

支付宝和肯德基中国允许用户通过手机人脸识别技术支付费用。这是世界上第一家使用这项新技术的零售商。
Deeplearn.js发布:在浏览器中使用机器学习
标签——产品发布,机器学习,开源软件

Deeplearn.js是一个开源加速WebGL的JavaScript库,可在浏览器中使用机器学习。
软件工程师Nikhil Thorat和Daniel Smilkov指出:“将机器学习引入浏览器的原因有很多。客户端ML库可以作为交互解释性平台,用于快速原型化和可视化,甚至用于离线计算。如果没有其他因素,浏览器将会是世界上最流行的编程平台之一”。
CatBoost的发布:自动处理分类数据的机器学习库
标签——机器学习,开源软件

在用sklearn库处理不同类型变量时,您可能已经遇到不少报错,比如“ValueError:不能将string转换为float”。使用sklearn前需要事先转换这些格式,比如进行“标签编码”、“热编码”等预处理。“CatBoost”是一个最近开源的库,由Yandex开发和贡献,看可以实现自动转换。
去年发布了许多这样的开源工具/库。这篇文章阐述了一些最流行的开源工具/库。
IBM Watson协助申报纳税系统
标签——公司协作,财务

税务筹划公司H&R Block与IBM Watson合作,开发一个内部系统以帮助其员工申报客户税收。美国的税法长达74000页,普通人很难理解全部知识。IBM Watson的这个系统将为税务专业人员提供指导和建议,来帮助税务人员熟悉流程。在今年税收结束后,Watson将会拥有大量税收数据,可以进行数据分析。
Shelf Engine:一家用人工智能减少食物浪费的初创公司
标签——创业,食品工业
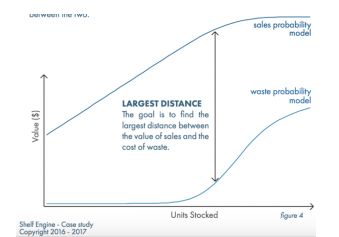
Shelf Engine是一家初创公司,设计了一个可持续发展的经营模式来帮助杂货店的品类经理搭配成百上千种产品订单。这家公司在案例研究中指出许多经理经常根据他们当前的浪费数字来制定订单——这是一种有缺陷的方法。因为“这个决定不是建立在浪费和交付的基础上”。Shelf Engine使用订单预测工具和概率模型,分析历史订单和销售数据、毛利润、货架寿命信息。客户使用系统越多,其建议就越准确。这家初创公司得到了初始资本的支持(Reddit联合创始人Alexis Ohanian是一个普通合伙人)包括,创始人的合作伙伴、Liquid 2 Ventures(Joe Montana是一个普通合伙人)和其他人。
人体实验室——一家由亚马逊收购的初创公司,从图像中获取人体的3D模型
标签——公司收购,时尚零售

人体实验室,一家计算机视觉创业公司已经开发出一种应用程序,可以通过任何输入,不论是2D照片、3D扫描还是实际的身体测量,都能预测出完整的3D视觉体型。这种外置式技术的影响是巨大的,不仅涵盖了时尚和服装领域的商业机遇,还包括健身、游戏、健康和制造业。这项技术将解决客户的试穿问题,尤其是在电子商务中由于尺寸问题而导致的巨额退货请求。人体实验室是由Michael Black、William J. O’Farrell、Eric Rachlin和Alex Weiss共同创立,他们在布朗大学和马克斯普朗克智能系统研究所进行研究。
数据科学竞赛平台“Kaggle”加入谷歌云
标签——公司收购

2017年3月谷歌收购了数据科学家的竞赛平台Kaggle。这个平台以举办数据科学和机器学习竞赛而闻名。据称,谷歌收购Kaggle旨在提高人工智能和机器学习,并利用Kaggle社区的60万名数据科学家资源。这次收购后,Kaggle将继续提供服务,但是Kaggle平台的功能比以前更加强大了。例如,在线编码环境的“内核”比以前更加平滑、提供了更多的功能、更长的运行时间。
胶囊网络——一种改进的深度学习体系结构算法
标签——研究,深度学习

Geoffrey Hinton是深度学习先驱之一,他解释了胶囊网络如何改善传统的卷积神经网络体系结构。如果将此技术应用到应用程序中,可以轻松地击败之前的基准测试技术。
实际上,这项技术以前就被发现了——但是现在已经以一种稳定的方式实现,并且被认为是更好的展现。
加拿大与人工智能研究所押注人工智能
标签——产业合作

在Geoffery Hinton的领导下,加拿大政府与谷歌、Facebook等大公司在矢量研究所投资了150亿美元,要求每年在人工智能领域培养1000名毕业生。矢量研究所通过促进和维持加拿大在深度学习和机器学习等方面的卓越成就,推动加拿大成为全球人工智能浪潮的前沿阵地。
百度训练了一名人工智能代理导航世界,就像父母教孩子一样
标签——创新、机器人技术

百度训练了一名人工智能代理使用自然语言导航二维空间,这是一种父母与婴儿之间使用的基本反馈机制。这种构建人工智能的过程可以用人类的方式进行教学。百度的下一个目标是教一个物理机器人在三维空间中进行导航,这个目标更贴近生活。这项基于强化机器学习的应用将对机器人工业产生巨大的影响。
机器学习创建地球生命地图集
标签——创业公司,食品管理

位于墨西哥的一家初创公司笛卡尔实验室利用卫星图像和人工智能来预测食品供应和危机级别。在食品短缺出现之前的几个月做出预测。让人们有足够多的时间来进行有序的人道主义响应,或者优化粮食供应网。笛卡尔实验室收集了非常深入的信息,比如能够区分单个农作物场、通过分析太阳光反射情况来确定特定区域的农作物,并使用先进的机器学习算法来处理这些图像和数据。一旦建立农作物的模型,机器学习程序就会监控该区域的生产情况。
迪斯尼了解观众的个性,更好地为他们提供服务
标签——创新,行为分析

迪斯尼研究公司Maarten Bos介绍了旗下的行为科学家团队如何进行一系列研究,使用图像来了解目标市场,并讨论了这些信息在迪斯尼和其他地方的可能应用。如果明智而勤勉地进行下去,这将彻底改变我们做品牌营销的方式。
“Entrupy”使用深度学习来识别产品的真实性
标签——创业公司,计算机视觉,深度学习

“Entrupy”是一家使用计算机视觉算法来检测假冒产品的初创公司。他们发明了一种便携式扫描设备,可以立即检测出仿名牌包,并通过显微照片记录材料的细节、加工、工艺、序列号和磨损。然后,它采用深度学习技术,将图像与包含顶级奢侈品牌的庞大数据库进行对比,如果该包被认为是真实的,用户就会立即获得一份真实性证书。
使用深度学习检测心脏疾病
标签——创业公司,医疗保健

与加州大学旧金山分校合作的心电图,改良了一款检测心房纤颤的Apple watch。其准确度比之前验证过的方法要高得多。他们利用深度学习技术取得了这一成就。一旦检测到疾病,该设备就会给你发送一条通知:“我们注意到你的心跳出现了异常,想和心脏病专家聊聊吗?”这可能会减少疾病发作的时间,以及从检测到治疗的时间。
Facebook减少视觉识别模型的训练时间
标签——创新,深度学习

花一分钟的时间来训练一个深度学习模式是不可能的事情,但在当今快节奏的研究世界里,这一分钟是值得的。Facebook今天早上发表了一篇论文,详细介绍了该问题的解决方法。该公司表示,它已经成功地将ResNet-50深度学习模式的训练时间从29个小时缩短到了1个小时。
IBM Watson自动形成明显的温布尔顿绕线轮
标签——创新、新闻

在过去,创建显示包和标注照片任务是人类的工作。但今年,这一工作被沃森人工智取代了。
沃森人工智可以在没有任何人工输入的情况下生成高亮显示包。它可以观看视频并识别最匹配的相关部分。可以识别玩家握手、手势庆祝、观众声音之类的简单的东西。
DeepMind发明出可以想象和提前计划的人工代理
标签——创新,强化学习
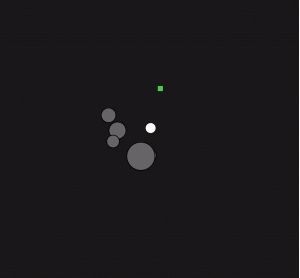
DeepMind研究人员发明了一个所谓的“想象增强剂”,即I2As,它有一个神经网络,用于从环境中提取信息,这些信息在以后的决策中起到关键作用。这个代理可以创建、评估和跟踪计划。为了构建和评估未来的计划,在决定执行哪个计划之前,I2As要“预测”行动以及结果。你也可以选择想要使用的方式,包括分别尝试不同可能的动作或者按顺序将动作连接在一起。
Replika,一个聊天机器人
标签——创新,人工智能

Replika是一个影子机器人,它可以追踪你电脑上的内容,模仿你的风格、态度和倾向,然后像你一样发送信息。举个例子,这位发明家用它来模仿一个死去的朋友的存在。
使用Twitter预测犯罪
标签——预测性分析,Twitter挖掘

弗吉尼亚大学助理教授Matthew Gerber正在利用Twitter数据预测犯罪,使警方及时关注地理犯罪热点。他通过使用一些旧的预测模型和新的tweet,预测了25种犯罪类型中的19种。这是在社交媒体上发现人们的情绪并采取紧急预防措施减少犯罪的又一种方法。
HireVue使用人工智能来分析视频面试求职者的表达能力、语气和面部动作
标签——人力资源,计算机视觉,自然语言处理

HireVue正在利用人工智能在人力资源领域进行招聘和决策。这家公司通过对面试视频进行分析,评估应聘者的面部表情、肢体语言、语调等,预测哪些应聘者将成为最优秀员工。这项技术将彻底革新人力资源行业。
E&Y使用电子邮件和日历数据来了解员工如何工作
标签——行为分析

Ernst和Young是美国最大的会计师事务所之一,它通过查看员工的日历和电子邮件数据确定要及时和谁进行接触。公司的哪些员工处于压力之下,哪些人最积极地超额完成公司目标。
卡耐基梅隆大学的“超级AI”引领德州扑克专业人士
标签——创新,游戏代理

CMU发布了一个秘密方法——打造出超人类的人工智能来打败扑克专业人员。这个方法具有重大意义,因为没有限制的德州扑克是所谓的“不完美信息游戏”,也就是说,不是所有玩家都能获得游戏中所有元素的信息。这与围棋等棋类游戏形成了鲜明对比,棋类游戏都有一个棋盘,其中包含了所有的棋子,上面的信息对于玩家来说一目了然。
深度学习模拟网络威胁
标签——创新,网络安全,深度学习

科学家借助人工智能(AI)的力量开发了一个应用程序,结合现有的解密工具,计算出密码。Thomas Ristenpart说,他可以帮助普通用户和公司衡量密码的强度。Thomas Ristenpart是一名计算机科学家,在纽约康奈尔科技大学学习计算机安全,但是他没有参与这个项目。这项新技术可能被用于密码的解密,来帮助检测计算机入侵。
Mozilla发布语音识别模型和语音数据集两款产品
标签——产品发布,语音识别,深度学习

为了加快音频领域的发展,Mozilla发布了世界上第二大开放的语音数据集,同时还开放了语音识别的前沿技术。该产品的发布势必会影响语音识别技术的发展。
课程内容快速获得:AI“编程人员最前沿深度学习——第2部分”
标签——深度学习

“编程人员最前沿的深度学习,第2部分”课程,现在已经面向大众开放了。对于那些没有机会看到课程第1部分的人来说,这门课程将以实用的方式向你介绍深度学习的基础知识。第2部分课程让你了解深度学习的细节并向你介绍业内正在进行的前沿探索。
中国将允许自动驾驶汽车在公共道路上进行测试
标签——自动驾驶汽车,交通工具

中国正在向自动驾驶汽车开放道路。北京市交通委员会发表声明称,在某些特定的道路上,某些情况下,在中国注册的公司将能够测试他们的自动驾驶汽车。
自动机器学习技术
标签——自动化机器学习

自动化机器学习是一项新技术。它完成了数据科学生命周期所需的繁重工作。这是一个非常好的想法;虽然我们以前担心调优参数和超参数,但是自动化机器学习系统可以通过多种不同的方法来优化这些参数。
在2018年我们还有哪些期待呢?
科技行业里变化如此之大,以至于很难跟上当前的趋势。它将会继续发展,直到尖端研究转化为普通人使用的技术。举个例子,你可以看到深度学习研究对计算机视觉的影响,像人脸识别,自动驾驶汽车这样的应用。在未来,你将看到应用程序的蓬勃发展,这些应用程序由深度学习技术驱动。
下面列出了我特别期待的几件事:
Will Hinton的胶囊网络会是深度学习领域的下一个风口吗?
数据科学的研究将越来越多地受到社区的影响。
使用工具将变得更加简单,大多数手动操作细节都将自动化。
在交通运输方面。将道德规范和规章制度落实到位。
硬件将更便宜,更高效——会倾向于使用人工智能芯片。
随着开放课程的增加,学习的重点将转向自我学习。
自动化机器学习将会变得有价值。
GANs功能将会变得更强,工业将开始使用GANs了。
深度强化学习是所有学习技术中最流行的技术,将在大多数商业应用中使用。
期待开发一个解释性的黑盒模型。
很多数据来源,如物联网设备、中央电视台、社交媒体等,这些信息将帮助我们建立更好的自动化的系统。
正如Andrej Karpathy——一位在数据科学领域杰出人物所解释的那样:
神经网络不只是另一种分类器,它代表了我们编写软件思想转变的开始。这些思想是软件2.0版本。软件2.0不会取代我们现在所知的软件。但是它将会接管越来越多的当今软件的功能。
尾注
本文列举了一些在2017年发生在数据科学行业的开创性事件。以及这些事件对数据科学专业人士的影响。还展现了在不远的将来可以看到这些技术的发展路径。
如果你知道一个有突破性的事件并且想要分享出来,请在下面写下你的评论。
原文链接:
https://www.analyticsvidhya.com/blog/2017/12/reminiscing-2017-defining-moments-and-future-of-data-science/
编辑:文婧

杨金鸿,北京护航科技有限公司员工,在业余时间喜欢翻译一些技术文档。喜欢阅读有关数据挖掘、数据库之类的书,学习java语言编程等,希望能在数据派平台上熟识更多爱好相同的伙伴,今后能在数据科学的道路上走的更远,飞的更远。
翻译组招募信息
工作内容:将选取好的外文前沿文章准确地翻译成流畅的中文。如果你是数据科学/统计学/计算机专业的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友,数据派翻译组欢迎你们加入!
你能得到:提高对于数据科学前沿的认知,提高对外文新闻来源渠道的认知,海外的朋友可以和国内技术应用发展保持联系,数据派团队产学研的背景为志愿者带来好的发展机遇。
其他福利:和来自于名企的数据科学工作者,北大清华以及海外等名校学生共同合作、交流。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THUID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
为保证发文质量、树立口碑,数据派现设立“错别字基金”,鼓励读者积极纠错。
若您在阅读文章过程中发现任何错误,请在文末留言,或到后台反馈,经小编确认后,数据派将向检举读者发8.8元红包。
同一位读者指出同一篇文章多处错误,奖金不变。不同读者指出同一处错误,奖励第一位读者。
感谢一直以来您的关注和支持,希望您能够监督数据派产出更加高质的内容。

点击“阅读原文”加入组织~