最新 Flink 1.13 DataStream API 快速入门、详细教程
DataStream API
文章目录
- DataStream API
-
- 一、Flink 的编程模型
- 二、执行环境(Execution Environment)
-
- 1. 创建执行环境
- 2. 执行模式(Execution Mode)
- 3. 触发程序执行
- 三、源算子(Source)
-
- 1. 从集合中读取数据
- 2. 从文件读取数据
- 3. 从Socket 读取数据
- 4. 从Kafka 读取数据
- 5. 自定义 Source
- 四、Flink 支持的数据类型
-
- 1. Flink 支持的数据类型
- 2. 类型提示(Type Hints)
- 五、转换算子(Transformation)
-
- 1. 基本转换算子
- 2. 聚合算子(Aggregation)
- 3. 用户自定义函数(UDF)
- 六、物理分区(Physical Partitioning)
-
- 1. 逻辑分区(Keyby,也叫分组)
- 2. 物理分区及其分类
- 七、输出算子(Sink)
-
- 1. 输出到文件(精确一次)
- 2. 输出到Kafka
- 3. 输出到Redis
- 4. 输出到Elasticsearch
- 5. 输出到 MySQL(JDBC)
- 6. 自定义 Sink 输出
下一章: Flink 1.13 时间和窗口
一、Flink 的编程模型

-
获取执行环境(execution environment)
-
读取数据源(source)
-
定义基于数据的转换操作(transformations)
-
定义计算结果的输出位置(sink)
-
触发程序执行(execute)
二、执行环境(Execution Environment)
1. 创建执行环境
//自动识别环境,推荐
StreamExecutionEnvironment.getExecutionEnvironment();
//创建本地执行环境
StreamExecutionEnvironment.createLocalEnvironment();
//创建远程执行环境
StreamExecutionEnvironment .createRemoteEnvironment(
"host", // JobManager主机名
1234, // JobManager进程端口号
"path/to/jarFile.jar" // 提交给JobManager的JAR包
);
2. 执行模式(Execution Mode)
// 批处理环境
ExecutionEnvironment batchEnv = ExecutionEnvironment.getExecutionEnvironment();
// 流处理环境
StreamExecutionEnvironment streamEnv = StreamExecutionEnvironment.getExecutionEnvironment();
//批流处理一体模式(推荐)
//流执行环境跑批处理,只需要提交时指定批处理模式(推荐)
bin/flink run -Dexecution.runtime-mode=BATCH
//或者在代码中指定
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.BATCH);
3. 触发程序执行
env.execute();
三、源算子(Source)
1. 从集合中读取数据
DataStreamSource<Event> stream2 = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L)
);
ArrayList<Event> clicks = new ArrayList<>();
clicks.add(new Event("Mary","./home",1000L));
clicks.add(new Event("Bob","./cart",2000L));
DataStream<Event> stream = env.fromCollection(clicks);
2. 从文件读取数据
env.readTextFile("clicks.csv");
3. 从Socket 读取数据
env.socketTextStream("localhost", 7777);
4. 从Kafka 读取数据
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "hadoop102:9092");
properties.setProperty("group.id", "consumer-group");
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset", "latest");
env.addSource(new FlinkKafkaConsumer<String>("clicks",new SimpleStringSchema(),properties));
5. 自定义 Source
env.addSource(
new SourceFunction<Tuple2<String, Long>>() {
private boolean flag = true;
@Override
public void run(SourceContext<Tuple2<String, Long>> ctx) throws Exception {
String[] a = {"张", "王", "李", "赵", "吴"};
Random random = new Random();
while (flag) {
ctx.collect(Tuple2.of(a[random.nextInt(a.length)], System.currentTimeMillis()));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
flag = false;
}
})
四、Flink 支持的数据类型
为了方便地处理数据,Flink 有自己一整套类型系统。Flink 使用“类型信息”(TypeInformation)来统一表示数据类型。TypeInformation 类是 Flink 中所有类型描述符的基类。它涵盖了类型的一些基本属性,并为每个数据类型生成特定的序列化器、反序列化器和比较器。
1. Flink 支持的数据类型
简单来说,常见的 Java 和 Scala 数据类型,Flink 都是支持的。在Types工具类中找到:
- 基本类型
所有Java基本类型及其包装类,再加上Void、String、Date、BigDecimal和BigInteger。 - 数组类型
包括基本类型数组(PRIMITIVE_ARRAY)和对象数组(OBJECT_ARRAY) - 复合数据类型
- Scala 样例类及 Scala 元组:不支持空字段
- POJO:Flink 自定义的类似于 Java bean 模式的类
- Java 元组类型(TUPLE):Flink内置,Tuple0~Tuple25,不支持空字段
- 行类型(ROW):可以认为是具有任意个字段的元组,并支持空字段
- 辅助类型 Option、Either、List、Map 等
- 泛型类型(GENERIC)
Flink支持所有的Java类和Scala类。如没按照上面POJO类型的要求来定义,就会被Flink当作泛型类来处理。Flink会把泛型类型当作黑盒,无法获取它们内部的属性;不是由Flink本身序列化的,而是由 Kryo 序列化的。
元组类型和POJO类型最为灵活,因为它们支持创建复杂类型。POJO支持在键(key)的定义中直接使用字段名,这会让我们的代码可读性大大增加。在项目实践中,往往会将流处理程序中的元素类型定为 Flink 的 POJO 类型。
Flink 对 POJO 类型的要求如下:
- 类是公共的(public)和独立的(standalone,也就是说没有非静态的内部类);
- 类有一个公共的无参构造方法;
- 类中的所有字段是 public 且非 final 的;或者有一个公共的 getter 和 setter 方法,这些方法需要符合 Java bean 的命名规范。
2. 类型提示(Type Hints)
Flink 还具有一个类型提取系统,可以分析函数的输入和返回类型,自动获取类型信息,从而获得对应的序列化器和反序列化器。但是,由于 Java 中泛型擦除的存在,在某些特殊情况下(比如 Lambda 表达式中),自动提取的信息是不够精细的——只告诉 Flink 当前的元素由 “船头、船身、船尾”构成,根本无法重建出“大船”的模样;这时就需要显式地提供类型信息,才能使应用程序正常工作或提高其性能。
为了解决这类问题,Java API 提供了专门的“类型提示”(type hints)。
stream.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
五、转换算子(Transformation)
1. 基本转换算子
映射(map):“一一映射”,消费一个元素就产出一个元素
过滤(filter):对数据流执行一个过滤,通过一个布尔条件表达式设置过滤条件,对于每一个流内元素进行判断,若为 true 则元素正常输出,若为 false 则元素被过滤掉。
扁平映射(flatMap):将数据流中的整体(一般是集合类型)拆分成一个一个的个体使用。
// MapFunction 的实现类
public static class myMapFunction implements MapFunction<String,String>{
@Override
public String map(String value) throws Exception {
return value + " java";
}
}
//数据源
DataStreamSource<String> stream = env.fromElements("hello word", "scala spark");
//---------------------------------------------------------------------------------
//传函数有多种方法,这里只以 MapFunction 为例介绍
//实现类
stream.map(new myMapFunction()).print();
//Lambda表达式
stream.map(data -> data + " java").returns(String.class).print();
//匿名类
stream.map(
new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return value + " java";
}
}
).print();
//---------------------------------------------------------------------------------
//FilterFunction 只保留 hello word
stream.filter(
new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return "hello word".equals(value);
}
}).print();
//----------------------------------------------------------------------------------
//FlatMapFunction 打散每一行单词
stream.flatMap(
new FlatMapFunction<String,String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(word);
}
}
}).print();
2. 聚合算子(Aggregation)
-
按键分区(keyBy):
DataStream 是没有直接进行聚合的 API 的,对海量数据做聚合肯定要进行分区并行处理,先进行分区,是通过计算 key 的哈希值(hash code),对分区数进行取模运算来实现的。// 使用Lambda表达式 KeyedStream<Event, String> keyedStream = stream.keyBy(e -> e.user); // 使用匿名类实现KeySelector KeyedStream<Event, String> keyedStream1= stream.keyBy( new KeySelector<Event, String>() { @Override public String getKey(Event e) throws Exception { return e.user; } }); //如果是元组,可以用位置表示 env.fromElements("hello","java","flink","flink") .map(word -> Tuple2.of(word,1L)) .returns(Types.TUPLE(Types.STRING,Types.LONG)) .keyBy(0) -
简单聚合
sum():在输入流上,对指定的字段做叠加求和的操作。
min():在输入流上,对指定的字段求最小值。
max():在输入流上,对指定的字段求最大值。
minBy():与 min()类似,返回包含字段最小值的整条数据。
maxBy():与 max()类似,返回包含字段最大值的整条数据。//以sum()为例,求 wordcount 的示例 env.fromElements("hello","java","flink","flink") .map(word -> Tuple2.of(word,1L)) .returns(Types.TUPLE(Types.STRING,Types.LONG)) .keyBy(0).sum(1).print(); -
归约聚合(reduce)
ReduceFunction 可以对已有的数据进行归约处理,把每一个新输入的数据和当前已经归约出来的值,再做一个聚合计算,不会改变流的元素数据类型,所以输出类型和输入类型是一样的。
public interface ReduceFunction<T> extends Function, Serializable { T reduce(T value1, T value2) throws Exception; } //示例 实现wordcount env.fromElements("hello","java","flink","flink") .map(word -> Tuple2.of(word,1L)) .returns(Types.TUPLE(Types.STRING,Types.LONG)) .keyBy(0) .reduce( new ReduceFunction<Tuple2<String, Long>>() { @Override public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception { return new Tuple2<>(value1.f0, value1.f1 + value2.f1); } } ).print();
3. 用户自定义函数(UDF)
- 函数类(Function Classes)
对于大部分操作而言,都需要传入一个用户自定义函数(UDF),实现相关操作的接口,来完成处理逻辑的定义。Flink 暴露了所有 UDF 函数的接口,具体实现方式为接口或者抽象类,例如 MapFunction、FilterFunction、ReduceFunction 等。 - 匿名函数(Lambda)
返回元组Lambda一般需要使用显式的 “.returns(…)” - 富函数类(Rich Function Classes)
“富函数类”也是 DataStream API 提供的一个函数类的接口,所有的 Flink 函数类都有其Rich版本。富函数类一般是以抽象类的形式出现的。例如:RichMapFunction、RichFilterFunction、RichReduceFunction 等。
与常规函数类的不同主要在于,富函数类可以获取运行环境的上下文getRuntimeContext(),并拥有一些生命周期方法open()、close(),所以可以实现更复杂的功能。
六、物理分区(Physical Partitioning)
1. 逻辑分区(Keyby,也叫分组)
keyBy,按照当前数据的key的hash值进行重分区;只不过这种分区操作只能保证把数据按key“分开”,至于分得均不均匀、每个key 的数据具体会分到哪一区去,这些是完全无从控制的,是一种逻辑分区(logical partitioning)操作。
- Keyby实现原理:
先对key调用一次hashCode方法获取hash值,再对当前hash值调用默默hash(MurmurHash)获取二次hash值,对默认最大并行度128取模得到键组ID(keyGroupID),然后乘以下游算子并行度,再除以默认最大并行度128。
2. 物理分区及其分类
有些时候,我们还需要手动控制数据分区分配策略。比如当发生数据倾斜的时候,系统无法自动调整,这时就需要我们重新进行负载均衡,将数据流较为平均地发送到下游任务操作分区中去。
物理分区与 keyBy 另一大区别在于,keyBy 之后得到的是一个 KeyedStream,而物理分区之后结果仍是DataStream,且流中元素数据类型保持不变。从这一点也可以看出,分区算子并不对数据进行转换处理,只是定义了数据的传输方式。
常见的物理分区策略有随机分配(Random)、轮询分配(Round-Robin)、重缩放(Rescale)和广播(Broadcast)。
-
随机分区(shuffle)
最简单的重分区方式就是直接“洗牌”。通过调用 DataStream 的.shuffle()方法,将数据随机地分配到下游算子的并行任务中去。
随机分区服从均匀分布(uniform distribution),所以可以把流中的数据随机打乱,均匀地传递到下游任务分区。因为是完全随机的,所以对于同样的输入数据, 每次执行得到的结果也不会相同。 -
轮询分区(Round-Robin)
简单来说就是“发牌”,按照先后顺序将数据做依次分发,通过调用 DataStream 的.rebalance()方法,就可以实现轮询重分区。 -
重缩放分区(rescale)
当调用 rescale()方法时,其实底层也是使用Round-Robin 算法进行轮询,但是只会将数据轮询发送到下游并行任务的一部分中。也就是说,“发牌人”如果有多个,那么 rebalance 的方式是每个发牌人都面向所有人发牌;而 rescale 的做法是分成小团体,发牌人只给自己团体内的所有人轮流发牌。当下游任务(数据接收方)的数量是上游任务(数据发送方)数量的整数倍时,rescale 的效率明显会更高。
由于 rebalance 是所有分区数据的“重新平衡”,当 TaskManager 数据量较多时,这种跨节点的网络传输必然影响效率;而如果我们配置的 task slot 数量合适,用 rescale 的方式进行“局部重缩放”,就可以让数据只在当前 TaskManager 的多个 slot 之间重新分配,从而避免了网络传输带来的损耗。
从底层实现上看,rebalance 和 rescale 的根本区别在于任务之间的连接机制不同。rebalance 将会针对所有上游任务(发送数据方)和所有下游任务(接收数据方)之间建立通信通道,这是一个笛卡尔积的关系;而 rescale 仅仅针对每一个任务和下游对应的部分任务之间建立通信通道,节省了很多资源。
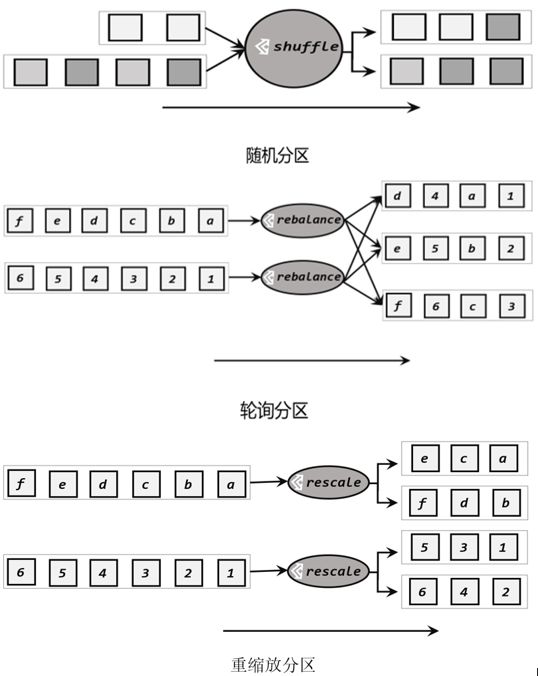
-
广播(broadcast)
这种方式其实不应该叫做“重分区”,因为经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理。可以通过调用 DataStream 的 broadcast()方法,将输入数据复制并发送到下游算子的所有并行任务中去。 -
全局分区(global)
全局分区也是一种特殊的分区方式。这种做法非常极端,通过调用.global()方法,会将所有的输入流数据都发送到下游算子的第一个并行子任务中去。这就相当于强行让下游任务并行度变成了1,所以使用这个操作需要非常谨慎,可能对程序造成很大的压力。 -
自定义分区(Custom)
当 Flink 提供的所有分区策略都不能满足用户的需求时,我们可以通过使用 partitionCustom() 方法来自定义分区策略。// 将自然数按照奇偶分区 env.fromElements(1, 2, 3, 4, 5, 6, 7, 8) .partitionCustom( new Partitioner<Integer>() { @Override public int partition(Integer key,int numPartitions){ return key % 2; } }, new KeySelector<Integer, Integer>() { @Override public Integer getKey(Integer value) throws Exception { return value; } } ).print().setParallelism(2);
七、输出算子(Sink)
在Flink 中,如果我们希望将数据写入外部系统,其实并不是一件难事。例如在 MapFunction 中,我们完全可以构建一个到 Redis 的连接,然后将当前处理的结果保存到 Redis 中。若考虑到只需建立一次连接,也可以利用RichMapFunction,在 open() 生命周期中做连接操作。
这样看起来很方便,却会带来很多问题。Flink 作为一个快速的分布式实时流处理系统,对稳定性和容错性要求极高。一旦出现故障,我们应该有能力恢复之前的状态,保障处理结果的正确性。这种性质一般被称作“状态一致性”。Flink 内部提供了一致性检查点(checkpoint)来保障我们可以回滚到正确的状态;但如果我们在处理过程中任意读写外部系统,发生故障后就很难回退到从前了。
Flink 官方提供了一部分的框架的 Sink 连接器,除 Flink 官方之外,Apache Bahir 作为给 Spark 和 Flink 提供扩展支持的项目,也实现了一些其他第三方系统与 Flink 的连接器。

1. 输出到文件(精确一次)
- 行编码:StreamingFileSink.forRowFormat(basePath,rowEncoder)。
- 批量编码:StreamingFileSink.forBulkFormat(basePath,bulkWriterFactory)。
StreamingFileSink<String> streamingFileSink = StreamingFileSink
.<String>forRowFormat(new Path("./output"),
new SimpleStringEncoder<>("UTF-8")).withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15))
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5))
.withMaxPartSize(1024 * 1024 * 1024)
.build())
.build();
// 将Event转换成String写入文件
stream.map(Event::toString).addSink(streamingFileSink);
2. 输出到Kafka
Properties properties = new Properties();
properties.put("bootstrap.servers", "hadoop102:9092");
stream.addSink(new FlinkKafkaProducer<String>("clicks",
new SimpleStringSchema(), properties));
3. 输出到Redis
// 创建一个到redis连接的配置
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder()
.setHost("hadoop102").build();
public static class MyRedisMapper implements RedisMapper<Event> {
@Override
public String getKeyFromData(Event e) {
return e.user;
}
@Override
public String getValueFromData(Event e) {
return e.url;
}
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.HSET, "clicks");
}
}
stream.addSink(new RedisSink<Event>(conf, new MyRedisMapper()));
$ redis-cli hadoop102:6379>hgetall clicks
1) “Mary”
2) “./home”
3) “Bob”
4) “./cart”
4. 输出到Elasticsearch
ArrayList<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("hadoop102", 9200, "http"));
// 创建一个ElasticsearchSinkFunction
ElasticsearchSinkFunction<Event> elasticsearchSinkFunction =
new ElasticsearchSinkFunction<Event>() {
@Override
public void process(Event element, RuntimeContext ctx, RequestIndexer indexer) {
HashMap<String, String> data = new HashMap<>();
data.put(element.user, element.url);
IndexRequest request = Requests.indexRequest()
.index("clicks").type("type") //Es6必须定义 type
.source(data);
indexer.add(request);
}
};
stream.addSink(new ElasticsearchSink.Builder<Event>(httpHosts, elasticsearchSinkFunction).build());
5. 输出到 MySQL(JDBC)
stream.addSink(
JdbcSink.sink(
"INSERT INTO clicks (user, url) VALUES (?, ?)",
(statement, r) -> {
statement.setString(1, r.user);
statement.setString(2, r.url);
},
JdbcExecutionOptions.builder()
.withBatchSize(1000).withBatchIntervalMs(200)
.withMaxRetries(5).build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/userbe havior")
// 对于MySQL 5.7,用"com.mysql.jdbc.Driver"
.withDriverName("com.mysql.cj.jdbc.Driver")
.withUsername("username")
.withPassword("password")
.build()
)
);
6. 自定义 Sink 输出
stream.addSink(
new RichSinkFunction<String>() {
// 管理Hbase的配置信息,这里因为Configuration的重名问题,将类以完整路径导入
public org.apache.hadoop.conf.Configuration configuration;
public Connection connection; // 管理Hbase连接
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "hadoop102:2181");
connection =ConnectionFactory.createConnection(configuration);
}
@Override
public void invoke(String value, Context context)
throws Exception {
Table table =connection.getTable(TableName.valueOf("test"));
Put put = new Put("rowkey".getBytes(StandardCharsets.UTF_8));
put.addColumn("info".getBytes(StandardCharsets.UTF_8),
value.getBytes(StandardCharsets.UTF_8), // 写入的数据
"1".getBytes(StandardCharsets.UTF_8)); // 写入的数据
table.put(put); // 执行put操作
table.close(); // 将表关闭
}
@Override
public void close() throws Exception {
super.close();
connection.close(); // 关闭连接
}
});
下一章:Flink 1.13 时间和窗口