一、 Hadoop集群部署(2.9.2版)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 保姆级安装教程系列——Hadoop集群安装(2.9.2版)
-
- 一、安装版本
- 二、创建3台虚拟机
- 三、配置网络
-
- 1. 配置文件
- 2. 配置VMware Network Adapter VMnet8网络
- 3. 重置网络
- 4. 打开windows终端(Windows+R),查看是否可以ping通外网
- 5. 查看Centos是否可以ping通www.baidu.com
- 四、修改主机名
-
- 1. 修改主机名
- 2. 重启
- 3. 再次查看主机名是否更改
- 五、映射
-
- 1. 设置映射
- 2. 查看3台机是否相互ping通
- 六、SSH免密登录
-
- 1. 查看是否安装ssh
- 2. 配置ssh配置文件
- 4. 重启sshd服务
- 5. 使用命令ssh-keygen生成公钥和密钥(中间敲3次回车)
- 6. 复制公钥到密钥文件中
- 7. 修改密钥文件权限
- 8. 共享公钥
- 9. 当每一台机器都对每一个用户执行了共享公钥命令后,查看是否可以相互登录。
- 七、安装Java
-
- 1. 创建两个目录分别放软件安装压缩包和解压后的软件包。
- 2. 安装rz命令:yum install lrzsz
- 3. 切换到目录/opt/module在该目录下进行上传压缩包 :cd /opt/module
- 4. 输入命令:rz(选择要上传的压缩包,点击ADD并确定)
- 5. 解压软件包
- 6. 配置文件:vim /etc/profile
- 7. 重启配置文件:source /etc/profile
- 8. 验证java是否安装:java -version
- 八、安装hadoop
-
- 1. 配置文件:
- 2. 复制配置完成后的所有文件到其他两台机器上:
- 3. 关闭防火墙(永久关闭):systemctl disable firewalld.service
- 4. 重启:reboot
- 5. 查看防火墙是否关闭:systemctl status firewalld.service
- 九、启动Hadoop
-
- 1. 格式化文件系统:hdfs namenode -format
- 2. 启动Hadoop:
- 3. 验证是否成功:jps
- 4. 打开浏览器查看是否可以访问网页
保姆级安装教程系列——Hadoop集群安装(2.9.2版)
一、安装版本
jdk1.8.0_131、hadoop-2.9.2、CentOS-7-x86_64-DVD-2009.iso
二、创建3台虚拟机
1台主节点:master
2台从节点:slave1、slave2
三、配置网络
1. 配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33
** 不要设置和我的一模一样!!!**
** 不要设置和我的一模一样!!!**
** 不要设置和我的一模一样!!!**
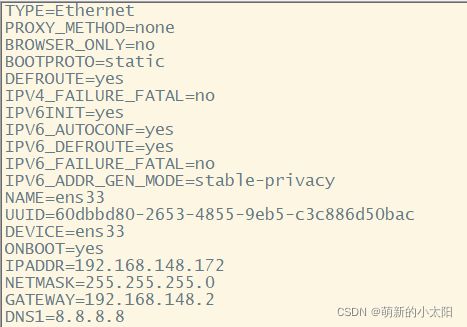
注解:
① IPADDR为IP地址
② GATEWAY为网关
2. 配置VMware Network Adapter VMnet8网络
该步骤需要在Windows系统中操作!!!
网络配置管理——VNnet8——协议4——属性
** 不要设置和我的一模一样!!!**
** 不要设置和我的一模一样!!!**
** 不要设置和我的一模一样!!!**

注解:物理机中的网段和网关须与虚拟机中的设置相同,且IP地址(最后三位数)不可相互冲突。
3. 重置网络
service network restart
4. 打开windows终端(Windows+R),查看是否可以ping通外网

5. 查看Centos是否可以ping通www.baidu.com
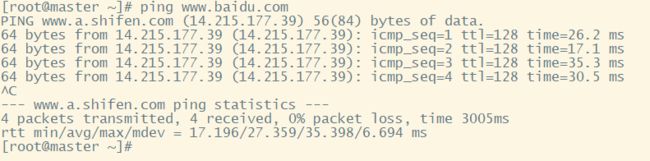
注意 :
① 如果完成以上操作后,网络依旧不能ping通,考虑查看虚拟机网络编译器,查看NAT网段是否与配置相同。
② 3台机器进行相同的操作,配置相同网段的IP地址(最后3位不同)和相同的网关。
四、修改主机名
1. 修改主机名
vim /etc/hostname

2. 重启
reboot
3. 再次查看主机名是否更改
hostname

注意 :此处主机名分别对应3台不同的机子:master、slave1、slave2,3台机子都要改主机名!否则无法完成后续的映射!
五、映射
1. 设置映射
vim /etc/hosts
添加3台机子的IP地址和主机名

注意 :3台机子进行相同操作
2. 查看3台机是否相互ping通
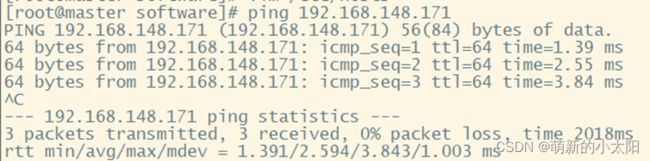
注意 :此处只贴了一张master ping slave1的图,一定要试验每一台机都能ping同其他两台,且ping通自己。
六、SSH免密登录
1. 查看是否安装ssh
rpm -qa | grep ssh
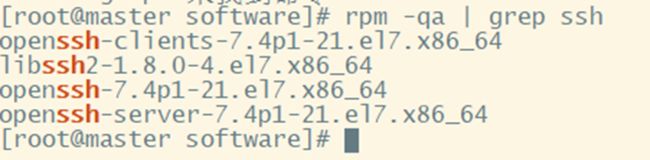
如上图:若已安装,则可直接使用;若未安装则使用命令 :
yum -y install openssh
yum -y install openssh-server
yum -y install openssh-clients
2. 配置ssh配置文件
vim /etc/ssh/sshd_config
① 修改第43行内容:去掉符号#
② 在其上面添加:RSAAuthentication yes

4. 重启sshd服务
systemctl restart sshd.service
5. 使用命令ssh-keygen生成公钥和密钥(中间敲3次回车)
6. 复制公钥到密钥文件中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_key
7. 修改密钥文件权限
chmod 0600 ~/.ssh/authorized_keys
8. 共享公钥
ssh-copy-id -i ~/.ssh/id_rsa.pub root@slave1
# 其中需要输入的密码是:root用户密码
9. 当每一台机器都对每一个用户执行了共享公钥命令后,查看是否可以相互登录。

注意 :此处只贴了一张master免密登录slave1的图,一定要试验每一台机都能免密登录同其他两台,且免密登录自己。
七、安装Java
1. 创建两个目录分别放软件安装压缩包和解压后的软件包。
mkdir /opt/module 放压缩包
mkdir /opt/software 放解压后的软件包
2. 安装rz命令:yum install lrzsz
3. 切换到目录/opt/module在该目录下进行上传压缩包 :cd /opt/module
4. 输入命令:rz(选择要上传的压缩包,点击ADD并确定)
5. 解压软件包
tar -zxvf jdk-linux-x64.tar.gz -C /opt/software/
tar -zxvf hadoop-2.9.2.tar.gz -C /opt/software/
6. 配置文件:vim /etc/profile
在文件最后一行添加:
export JAVA_HOME=/opt/software/jdk1.8.0_131
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
7. 重启配置文件:source /etc/profile
8. 验证java是否安装:java -version

八、安装hadoop
1. 配置文件:
① vim /etc/profile
在最后一行添加:
export HADOOP_HOME=/opt/software/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
之后重启文件:source /etc/profile
② vim /etc/profile.d/hadoop.sh
此为新建文件,添加内容:
export HADOOP_HOME=/opt/software/Hadoop-2.9.2
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
之后重启文件:source /etc/profile.d/hadoop.sh
剩余配置文件需切换此路径:cd /opt/software/Hadoop-2.9.2/etc/hadoop<\font>
③ vim hadoop-env.sh
#在第25行修改
export JAVA_HOME=/opt/software/jdk1.8.0_131
#在第26行添加
export HADOOP_SSH_OPTS='-o StrictHostKeyChecking=no'
#在第113行修改
export HADOOP_PID_DIR=${HADOOP_PID_DIR}/pids
④ vim mapred-env.sh
# 在第16行修改
export JAVA_HOME=/opt/software/jdk1.8.0_131
# 在第28行修改
export HADOOP_MAPRED_PID_DIR=${HADOOP_HOME}/pids
⑤ vim yarn-env.sh
# 在第23行修改
export JAVA_HOME=/opt/software/jdk1.8.0_131
# 在最后一行添加
export YARN_PID_DIR=${HADOOP_HOME}/pids
⑥ vim core-site.xml
# 输入:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.148.170:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/software/hadoop-2.9.2/hdfsdata</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
⑦ vim hdfs-site.xml
# 输入 :
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/software/hadoop-2.9.2/hdfsdata/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/software/hadoop-2.9.2/hdfsdata/dfs/data</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:/opt/software/hadoop-2.9.2/hdfsdata/dfs/namesecondary</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>
⑧ vim mapred-site.xml
复制文件mapred-site.xml.template并命名为mapred-site.xml:
cp mapred-site.xml.template mapred-site.xml
# 输入:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>mapreduce.job.maps</name>
<value>2</value>
</property>
<property>
<name>mapreduce.job.reduces</name>
<value>1</value>
</property>
</configuration>
vim yarn-site.xml
输入:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>${hadoop.tmp.dir}/nm-local-dir</value>
</property>
</configuration>
⑨ vim slaves
# 删除localhost
# 输入:
slave1
slave2
2. 复制配置完成后的所有文件到其他两台机器上:
scp /opt/software/hadoop-2.9.2/etc/hadoop/* root@slave1:/opt/software/hadoop-2.9.2/etc/hadoop/
scp /opt/software/hadoop-2.9.2/etc/hadoop/* root@slave2:/opt/software/hadoop-2.9.2/etc/hadoop/
3. 关闭防火墙(永久关闭):systemctl disable firewalld.service
4. 重启:reboot
5. 查看防火墙是否关闭:systemctl status firewalld.service

九、启动Hadoop
1. 格式化文件系统:hdfs namenode -format
2. 启动Hadoop:
① start-dfs.sh

② start-yarn.sh
![]()
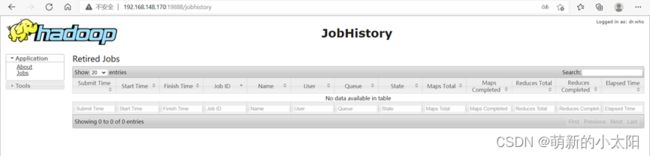
③ mr-jobhistory-daemon.sh start historyserver
![]()
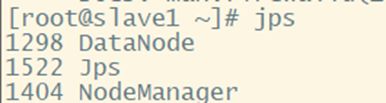
3. 验证是否成功:jps
① 主节点master:
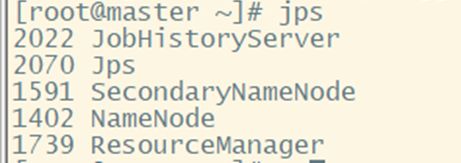
② 从节点slave1、slave2:

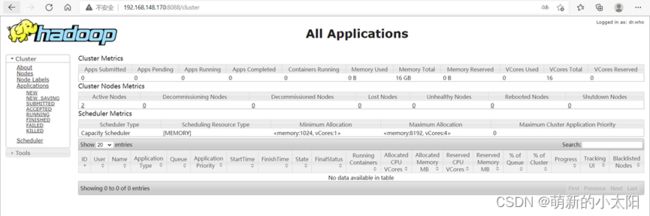
4. 打开浏览器查看是否可以访问网页
注意 :链接IP为自己设置的IP