Spring循环依赖、Redis
Spring循环依赖、Redis
1.Spring循环依赖
什么是循环依赖?
多个bean之间相互依赖,形成了一个闭环。比如:A依赖于B、B依赖于C、C依赖于A。
通常来说,如果问Spring容器内部如何解决循环依赖,一定是指默认的单例Bean中,属性互相引用的场景。

我们AB循环依赖问题只要A的注入方式是setter且singleton ,就不会有循环依赖问题。
Spring循环依赖纯java代码验证案例
Spring容器循环依赖报错演示BeanCurrentlylnCreationException
循环依赖现象在spring容器中注入依赖的对象,有2种情况
- 构造器方式注入依赖(不可行)
- 以set方式注入依赖(可行)
构造器方式注入依赖(不可行)
@Component
public class ServiceB{
private ServiceA serviceA;
public ServiceB(ServiceA serviceA){
this.serviceA = serviceA;
}
}
@Component
public class ServiceA{
private ServiceB serviceB;
public ServiceA(ServiceB serviceB){
this.serviceB = serviceB;
}
}
public class ClientConstructor{
public static void main(String[] args){
new ServiceA(new ServiceB(new ServiceA()));//这会抛出编译异常
}
}
以set方式注入依赖(可行)
@Component
public class ServiceBB{
private ServiceAA serviceAA;
public void setServiceAA(ServiceAA serviceAA){
this.serviceAA = serviceAA;
System.out.println("B里面设置了A");
}
}
@Component
public class ServiceAA{
private ServiceBB serviceBB;
public void setServiceBB(ServiceBB serviceBB){
this.serviceBB = serviceBB;
System.out.println("A里面设置了B");
}
}
public class ClientSet{
public static void main(String[] args){
//创建serviceAA
ServiceAA a = new ServiceAA();
//创建serviceBB
ServiceBB b = new ServiceBB();
//将serviceA入到serviceB中
b.setServiceAA(a);
//将serviceB法入到serviceA中
a.setServiceBB(b);
}
}
Spring循环依赖bug演示
public class A {
private B b;
public B getB() {
return b;
}
public void setB(B b) {
this.b = b;
System.out.println("A call setB.");
}
}
public class B {
private A a;
public A getA() {
return a;
}
public void setA(A a) {
this.a = a;
System.out.println("B call setA.");
}
}
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class ClientSpringContainer {
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext("beans.xml");
A a = context.getBean("a", A.class);
B b = context.getBean("b", B.class);
}
}
默认的单例(Singleton)的场景是支持循环依赖的,不报错
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-4.0.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-4.0.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-4.0.xsd">
<bean id="a" class="com.lun.interview.circular.A">
<property name="b" ref="b">property>
bean>
<bean id="b" class="com.lun.interview.circular.B">
<property name="a" ref="a">property>
bean>
beans>
输出结果
00:00:25.649 [main] DEBUG org.springframework.context.support.ClassPathXmlApplicationContext - Refreshing org.springframework.context.support.ClassPathXmlApplicationContext@6d86b085
00:00:25.828 [main] DEBUG org.springframework.beans.factory.xml.XmlBeanDefinitionReader - Loaded 2 bean definitions from class path resource [beans.xml]
00:00:25.859 [main] DEBUG org.springframework.beans.factory.support.DefaultListableBeanFactory - Creating shared instance of singleton bean 'a'
00:00:25.875 [main] DEBUG org.springframework.beans.factory.support.DefaultListableBeanFactory - Creating shared instance of singleton bean 'b'
B call setA.
A call setB.
原型(Prototype)的场景是不支持循环依赖的,会报错
重要结论(spring内部通过3级缓存来解决循环依赖) - DefaultSingletonBeanRegistry
只有单例的bean会通过三级缓存提前暴露来解决循环依赖的问题,而非单例的bean,每次从容器中获取都是一个新的对象,都会重新创建,所以非单例的bean是没有缓存的,不会将其放到三级缓存中。
- 第一级缓存(也叫单例池)singletonObjects:存放已经经历了完整生命周期的Bean对象。
- 第二级缓存:earlySingletonObjects,存放早期暴露出来的Bean对象,Bean的生命周期未结束,属性还未填充完。
- 第三级缓存:Map
package org.springframework.beans.factory.support;
public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry {
...
/** Cache of singleton objects: bean name to bean instance. */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name to ObjectFactory. */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name to bean instance. */
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
...
}
Spring循环依赖debug前置知识
实例化 - 内存中申请一块内存空间,如同租赁好房子,自己的家当还未搬来。
初始化属性填充 - 完成属性的各种赋值,如同装修,家具,家电进场。
3个Map和四大方法,总体相关对象
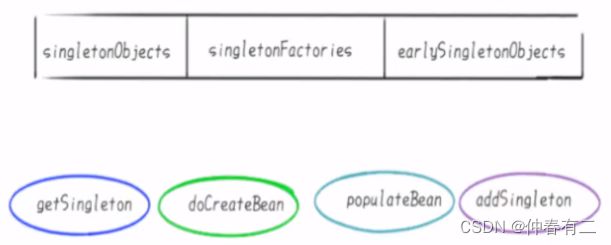
第一层singletonObjects存放的是已经初始化好了的Bean,
第二层earlySingletonObjects存放的是实例化了,但是未初始化的Bean,
第三层singletonFactories存放的是FactoryBean。假如A类实现了FactoryBean,那么依赖注入的时候不是A类,而是A类产生的Bean
A / B两对象在三级缓存中的迁移说明
- A创建过程中需要B,于是A将自己放到三级缓里面,去实例化B。
- B实例化的时候发现需要A,于是B先查一级缓存,没有,再查二级缓存,还是没有,再查三级缓存,找到了A然后把三级缓存里面的这个A放到二级缓存里面,并删除三级缓存里面的A。
- B顺利初始化完毕,将自己放到一级缓存里面(此时B里面的A依然是创建中状态),然后回来接着创建A,此时B已经创建结束,直接从一级缓存里面拿到B,然后完成创建,并将A自己放到一级缓存里面。
Spring循环依赖总结
Spring创建 bean主要分为两个步骤,创建原始bean对象,接着去填充对象属性和初始化
每次创建 bean之前,我们都会从缓存中查下有没有该bean,因为是单例,只能有一个
当我们创建 beanA的原始对象后,并把它放到三级缓存中,接下来就该填充对象属性了,这时候发现依赖了beanB,接着就又去创建beanB,同样的流程,创建完beanB填充属性时又发现它依赖了beanA又是同样的流程,
不同的是:这时候可以在三级缓存中查到刚放进去的原始对象beanA.所以不需要继续创建,用它注入 beanB,完成 beanB的创建
既然 beanB创建好了,所以 beanA就可以完成填充属性的步骤了,接着执行剩下的逻辑,闭环完成
Spring解决循环依赖依靠的是Bean的**"中间态"这个概念,而这个中间态指的是已经实例化但还没初始化的状态—>半成品。**实例化的过程又是通过构造器创建的,如果A还没创建好出来怎么可能提前曝光,所以构造器的循环依赖无法解决。”对
Spring为了解决单例的循坏依赖问题,使用了三级缓存:
- 其中一级缓存为单例池(singletonObjects)。
- 二级缓存为提前曝光对象(earlySingletonObjects)。
- 三级级存为提前曝光对象工厂(singletonFactories) 。
假设A、B循环引用,实例化A的时候就将其放入三级缓存中,接着填充属性的时候,发现依赖了B,同样的流程也是实例化后放入三级缓存,接着去填充属性时又发现自己依赖A,这时候从缓存中查找到早期暴露的A,没有AOP代理的话,直接将A的原始对象注入B,完成B的初始化后,进行属性填充和初始化,这时候B完成后,就去完成剩下的A的步骤,如果有AOP代理,就进行AOP处理获取代理后的对象A,注入B,走剩下的流程。
Spring解决循环依赖过程:
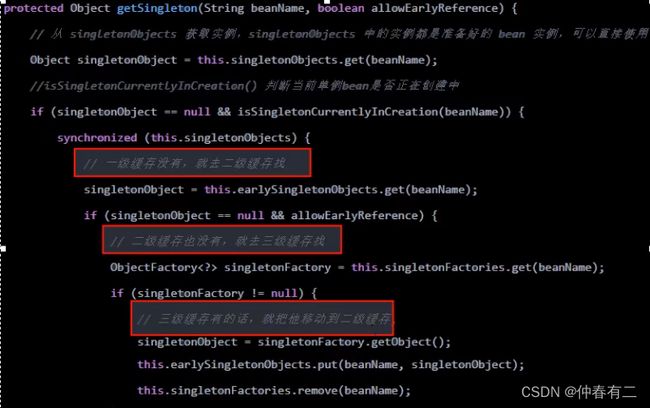
- 调用doGetBean()方法,想要获取beanA,于是调用getSingleton()方法从缓存中查找beanA
- 在getSingleton()方法中,从一级缓存中查找,没有,返回null
- doGetBean()方法中获取到的beanA为null,于是走对应的处理逻辑,调用getSingleton()的重载方法(参数为ObjectFactory的)
- 在getSingleton()方法中,先将beanA_name添加到一个集合中,用于标记该bean正在创建中。然后回调匿名内部类的creatBean方法
- 进入AbstractAutowireCapableBeanFactory#ndoCreateBean,先反射调用构造器创建出beanA的实例,然后判断:是否为单例、是否允许提前暴露引用(对于单例一般为true)、是否正在创建中(即是否在第四步的集合中)。判断为true则将beanA添加到【三级缓存】中
- 对beanA进行属性填充,此时检测到beanA依赖于beanB,于是开始查找beanB
- 调用doGetBean()方法,和上面beanA的过程一样,到缓存中查找beanB,没有则创建,然后给beanB填充属性
- 此时 beanB依赖于beanA,调用getSingleton()获取beanA,依次从一级、二级、三级缓存中找,此时从三级缓存中获取到beanA的创建工厂,通过创建工厂获取到singletonObject,此时这个singletonObject指向的就是上面在doCreateBean()方法中实例化的beanA
- 这样beanB就获取到了beanA的依赖,于是beanB顺利完成实例化,并将beanA从三级缓存移动到二级缓存中
- 随后beanA继续他的属性填充工作,此时也获取到了beanB,beanA也随之完成了创建,回到getsingleton()方法中继续向下执行,将beanA从二级缓存移动到一级缓存中
2.Redis
redis基本类型:
- string
- list
- set
- zset(sorted set)
- hash
其他redis的类型
- bitmap
- HyperLogLogs
- GEO
- Stream
String类型使用场景
最常用:
- SET key value
- GET key
同时设置/获取多个键值:
- MSET key value [key value…]
- MGET key [key…]
数值增减
- 递增数字 INCR key(可以不用预先设置key的数值。如果预先设置key但值不是数字,则会报错)
- 增加指定的整数 INCRBY key increment
- 递减数值 DECR key
- 减少指定的整数 DECRBY key decrement
获取字符串长度:STRLEN key
分布式锁:
- SETNX key value
- SET key value [EX seconds] [PX milliseconds] [NX|XX]
- EX:key在多少秒之后过期
- PX:key在多少毫秒之后过期
- NX:当key不存在的时候,才创建key,效果等同于setnx
- XX:当key存在的时候,覆盖key
应用场景:
- 商品编号、订单号采用INCR命令生成
- 是否喜欢的文章
hash类型使用场景
Redis的Hash类型相当于Java中Map
一次设置一个字段值: HSET key field value
一次获取一个字段值: HGET key field
一次设置多个字段值: HMSET key field value [field value …]
一次获取多个字段值: HMGET key field [field …]
获取所有字段值: HGETALL key
获取某个key内的全部数量: HLEN
删除一个key: HDEL
应用场景 - 购物车早期,当前小中厂可用
- 新增商品 hset shopcar:uid1024 334488 1
- 新增商品 hset shopcar:uid1024 334477 1
- 增加商品数量 hincrby shopcar:uid1024 334477 1
- 商品总数 hlen shopcar:uid1024
- 全部选择 hgetall shopcar:uid1024
list类型使用场景
向列表左边添加元素: LPUSH key value [value …]
向列表右边添加元素: RPUSH key value [value …]
查看列表: LRANGE key start stop
获取列表中元素的个数 LLEN key
应用场景 - 微信文章订阅公众号
- 大V作者李永乐老师和ICSDN发布了文章分别是11和22
- 阳哥关注了他们两个,只要他们发布了新文章,就会安装进我的List
- lpush likearticle:阳哥id1122
- 查看阳哥自己的号订阅的全部文章,类似分页,下面0~10就是一次显示10条
- lrange likearticle:阳哥id 0 10
set类型使用场景
添加元素: SADD key member [member …]
删除元素: SREM key member [member …]
获取集合中的所有元素: SMEMBERS key
判断元素是否在集合中: SISMEMBER key member
获取集合中的元素个数: SCARD key
从集合中随机弹出一个元素,元素不删除: SRANDMEMBER key [数字]
从集合中随机弹出一个元素,出一个删一个: SPOP key[数字]
集合运算:
- 集合的差集运算A - B
- 属于A但不属于B的元素构成的集合
- SDIFF key [key …]
- 集合的交集运算A ∩ B
- 属于A同时也属于B的共同拥有的元素构成的集合
- SINTER key [key …]
- 集合的并集运算A U B
- 属于A或者属于B的元素合并后的集合
- SUNION key [key …]
应用场景:
- 微信抽奖小程序
- 用户ID,立即参与按钮
- SADD key 用户ID
- 显示已经有多少人参与了、上图23208人参加
- SCARD key
- 抽奖(从set中任意选取N个中奖人)
- SRANDMEMBER key 2(随机抽奖2个人,元素不删除)
- SPOP key 3(随机抽奖3个人,元素会删除)
- 用户ID,立即参与按钮
- 微信朋友圈点赞
- 新增点赞
- sadd pub:msglD 点赞用户ID1 点赞用户ID2
- 取消点赞
- srem pub:msglD 点赞用户ID
- 展现所有点赞过的用户
- SMEMBERS pub:msglD
- 点赞用户数统计,就是常见的点赞红色数字
- scard pub:msgID
- 判断某个朋友是否对楼主点赞过
- SISMEMBER pub:msglD用户ID
- 新增点赞
- 微博好友关注社交关系
- 共同关注:我去到局座张召忠的微博,马上获得我和局座共同关注的人
- sadd s1 1 2 3 4 5
- sadd s2 3 4 5 6 7
- SINTER s1 s2
- 我关注的人也关注他(大家爱好相同)
- 共同关注:我去到局座张召忠的微博,马上获得我和局座共同关注的人
- QQ内推可能认识的人
- sadd s1 1 2 3 4 5
- sadd s2 3 4 5 6 7
- SINTER s1 s2
- SDIFF s1 s2
- SDIFF s2 s1
zset类型使用场景
向有序集合中加入一个元素和该元素的分数
添加元素: ZADD key score member [score member …]
按照元素分数从小到大的顺序返回索引从start到stop之间的所有元素: ZRANGE key start stop [WITHSCORES]
获取元素的分数: ZSCORE key member
删除元素: ZREM key member [member …]
获取指定分数范围的元素: ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
增加某个元素的分数: ZINCRBY key increment member
获取集合中元素的数量: ZCARD key
获得指定分数范围内的元素个数: ZCOUNT key min max
按照排名范围删除元素: ZREMRANGEBYRANK key start stop
获取元素的排名:
- 从小到大 ZRANK key member
- 从大到小 ZREVRANK key member
应用场景:
- 根据商品销售对商品进行排序显示
- 定义商品销售排行榜(sorted set集合),key为goods:sellsort,分数为商品销售数量。
- 商品编号1001的销量是9,商品编号1002的销量是15 - zadd goods:sellsort 9 1001 15 1002
- 有一个客户又买了2件商品1001,商品编号1001销量加2 - zincrby goods:sellsort 2 1001
- 求商品销量前10名 - ZRANGE goods:sellsort 0 10 withscores
- 定义商品销售排行榜(sorted set集合),key为goods:sellsort,分数为商品销售数量。
- 抖音热搜
- 点击视频
- ZINCRBY hotvcr:20200919 1 八佰
- ZINCRBY hotvcr:20200919 15 八佰 2 花木兰
- 展示当日排行前10条
- ZREVRANGE hotvcr:20200919 0 9 withscores
- 点击视频