Java面试学习笔记——HashMap源码分析
教学视频地址链接:HashMap全B站最细致源码分析课程,看完月薪最少涨5k!_哔哩哔哩_bilibili https://www.bilibili.com/video/BV1LJ411W7dP?p=8
https://www.bilibili.com/video/BV1LJ411W7dP?p=8
目录
第一部分 基础入门
1、数组的优势/劣势:
2、链表的优势/劣势:
3、有没有一种方式整合两种数据结构的优势?
4、散列表有什么特点?
5、什么是哈希?
第二部分 HashMap原理
1、HashMap的继承体系是什么样的?
2、Node数据结构分析?
3、底层存储结构介绍?
4、put数据原理分析
5、什么是Hash碰撞?
6、什么是链化?
7、jdk8为什么引入红黑树?
8、HashMap扩容原理?
第三部分 手撕源码
1、HashMap核心属性分析(threshold,loadFactory,size,modCount)
2、构造方法分析
3、HashMap put方法分析➡putVal方法分析
4、HashMap resize扩容方法分析
5、HashMap get方法分析
6、HashMap remove方法分析
7、HashMap replace方法
第一部分 基础入门
1、数组的优势/劣势:
优势:使用方便、查询效率较高、内存一般为连续的区域。
劣势:大小固定、不适合动态存储。
2、链表的优势/劣势:
优势:可以动态添加删除、大小可变。
劣势:只能通过顺次指针访问,查询效率低。
3、有没有一种方式整合两种数据结构的优势?
”散列表“:整合了数组与链表,(数组里的元素是链表)。
4、散列表有什么特点?
能通过index快速索引,又能动态扩容。
5、什么是哈希?
Hash,也称哈希、散列。
1.基本原理:把任意长度的输入,通过Hash算法变成固定长度的输出。这个映射的规则就是对应的Hash算法,而原始数据映射后的二进制串就是哈希值。
2.Hash的特点:
①从Hash值不可以反向推导出原始数据!
②输入数据的微小变化会得到完全不同的hash值,相同的数据会得到相同的哈希值。
③hash算法的执行效率要高效,长的文本也能快速的计算出哈希值。
④hash算法的冲突概率小。
由于hash的原理是将输入空间的值映射成hash空间内,而hash值的空间远小于输入的空间。根据抽屉原理,一定会存在不同的输入被映射成相同输出的情况。
第二部分 HashMap原理
1、HashMap的继承体系是什么样的?
HashMap是AbstractMap的子类,是Map的实现类,HashMap是Map接口的非同步实现类。
public class HashMap extends AbstractMap implements Map
public abstract class AbstractMap implements Map
public interface Map 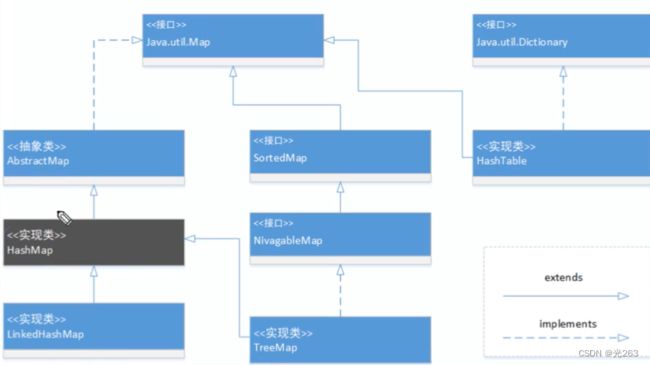
2、Node数据结构分析?
静态内部类Node
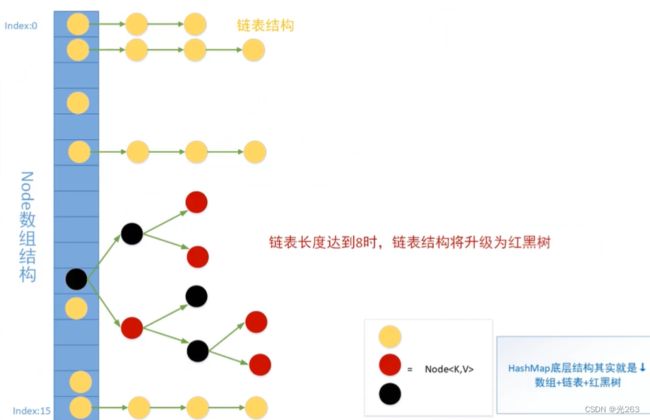
3、底层存储结构介绍?
其实就是:数组+链表+红黑树
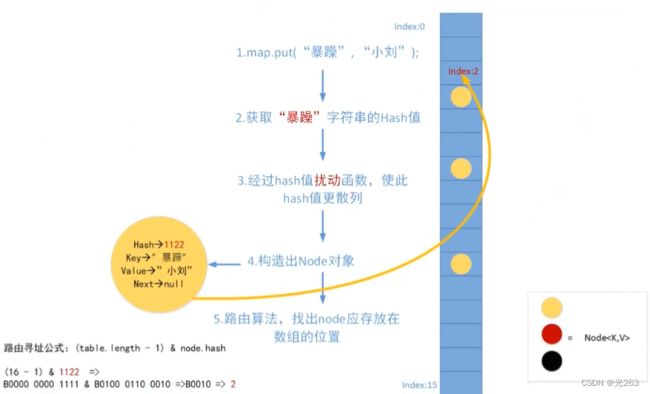
4、put数据原理分析
5、什么是Hash碰撞?
不同的数据计算出的hash值是一样的。
6、什么是链化?
扩容时,链表长度≤8、元素个数≤64时,链表化;反之树化(红黑树)。
7、jdk8为什么引入红黑树?
由于hash冲突导致链表查询非常慢,时间复杂度为O(n),引入红黑树后链表长度大于8时会自动转换为红黑树,以提高查询效率O (logn)。
8、HashMap扩容原理?
HashMap的容量,默认是16;HashMap的加载因子,默认是0.75。当HashMap中元素数超过容量*加载因子时,HashMap会进行扩容。扩容到2的n次幂,路由寻址公式:(table.length - 1) & node.hash 。
第三部分 手撕源码
1、HashMap核心属性分析(threshold,loadFactory,size,modCount)
1.几个重要常量:
①DEFAULT_INITIAL_CAPACITY "缺省table大小",=16,1<<4
②MAXIMUM_CAPACITY "table最大长度",1<<30
③DEFAULT_LOAD_FACTOR “缺省负载因子大小”,=0.75f
④TREEIFY_THRESHOLD "树化阈值",=8
⑤UNIREEIFY_THRESHOLD “树降级称为链表的阙值”,=6
⑥MIN_TREEIFY_CAPACITY "树化的另一个参数,当哈希表中元素≥这个数时,树化。",=64
2.核心属性:
①Node
②size "当前哈希表中元素个数"
③modCount "当前哈希表结构修改次数"
④threshold "扩容阙值,当你的哈希表中的元素超过阙值时,触发扩容"
⑤loadFactory "负载因子",threshold = capacity * loadFactory
2、构造方法分析
1.其实就是做了一些校验,①capacity必须是大于0,最大值也就是MAXIMUM_CAPACITY;
②loadFactory必须大于0;
③赋值loadFactory,和threshold(tablesizefor方法,返回一个≥当前值cap的一个数字,并且这个数字一定是2的次方数。(或运算 | :遇真则真,全假才假))
public HashMap(int initialCapacity,float loadFactor)
2. public HashMap(int initialCapacity)
3. public HashMap()
4. public HashMap(Map m)
3、HashMap put方法分析➡putVal方法分析
1. put方法调用putVal方法:
public V put(K key,V value){
return putVal(hash(key),key,value,false,true);
}-
hash方法:扰动函数,作用:让key的hash值高16位也参与路由运算。
异或 ^ :同0异1。
-
putVal方法:①tab:引用当前hashmap的散列表;
②p: 表示当前散列表的 元素;
③n: 表示散列表数组的 长度;
④i: 表示路由寻址 结果。
延迟初始化逻辑,第一次调用putVal时会初始化hashmap对象中的最耗费内存的散列表。 最简单的一种情况:寻址找到的桶位刚好是null时,直接将当前k-v=>node 扔进去就可以了: (e:不为null的话,找到了一个与当前要插入的key-value一致的key的元素。) 如果桶位中的该元素与要插入的key一致时,后续需要进行替换操作: 链表的情况,而且链表的头元素与要插入的key不一致,遍历: 如果迭代到最后一个元素,也没找到与要插入的key一致的node,则加到当前链表的末尾: 当前链表的长度达到树化标准时,需要进行树化操作treeifyBin(tab, hash)。 如果找到了相同的key的node元素,则进行替换操作。 e不等于null时,说明找到了一个与插入元素key完全一致的数据。 modCount:表示散列表结构被修改的次数,替换Node元素的value不计数。 插入新元素,size自增,如果自增后的值大于扩容阙值,则触发扩容。
4、HashMap resize扩容方法分析
4.1 为什么要扩容?
扩容会缓解 哈希冲突 导致的 链化 影响查询效率 的问题。
4.2 一些变量:
oldTab:引用扩容前的哈希表。
oldCap:表示扩容之前的table数组的长度。
oldThr:表示扩容之前的扩容阈值,出发本次扩容的阈值。
newCap:扩容后table数组的长度。
newThr:扩容后,下次再次触发扩容的条件。
4.3 源码分析:
(1)计算newCap和newThr:
如果oldCap > 0,说明hashMap中的散列表已经初始化过了,(正常扩容):
如果扩容之前的table数组大小已经达到了 最大阈值后,则不扩容,且设置扩容条件为int最大值。
否则,(newCap = oldCap << 1)oldCap左移一位实现数值翻倍,并且赋值给newCap,newCap小于数组最大限制 且 扩容之前的阈值 >= 16,则 下一次扩容的阈值 = 当前阈值翻倍。
如果oldCap == 0,但oldThr > 0: ①new HashMap(initCap , loadFactor); , 说明hashMap中的散列表是null。
②new HashMap(initCap);
③new HashMap(map); //并且这个map有数据。
如果oldCap == 0,且newThr == 0:new HashMap(),通过newCap和loadFactor计算出一个新的newThr。(2)扩容:
创建出一个更大、更长的数组。
如果hashMap本次扩容之前,table不为空:(e:当前node节点)
如果如果当前桶位中有数据,但是数据具体是 单个数据、还是链表、还是红黑树 并不知道。
(oldTab[j] == null),方便JVM GC 时回收内存。
一、如果当前桶位只有一个元素,从未有碰撞,则直接算出该元素应在 新数组中的位置 并扔进去。
二、如果当前节点已经树化:((TreeNode) e).split(this,newTab,j,oldCap);
三、如果当前桶位已经形成链表:
低位链表loHead:存放在扩容之后的数组下标位置,与当前数组的下标位置一致。
高位链表hiHead:存放在扩容之后的数组下标位置: 当前数组下标位置 + 扩容之前的数组长度。 5、HashMap get方法分析
核心getNode( ) 方法:
5.1 一些变量:
tab:引用当前hashMap的散列表。
first:桶位中的头元素。
e: 临时的node元素。
n: table数组长度。
5.2 源码分析:
一、如果定位出来的桶位元素 即为要get的数据。
如果当前桶位不止一个元素,可能是 链表、或 红黑树:
二、桶位升级成了红黑树。
三、桶位形成链表。6、HashMap remove方法分析
核心removeNode( )方法:
6.1 一些变量:
tab:引用当前hashMap的散列表。
p:当前node元素。
n: table数组长度。
index:表示寻址结果。
node:查找到的结果。
e:当前Node的下一个元素。
6.2 源码分析:
如果路由的桶位是有数据的,需要进行查找操作,并且删除:
一、如果当前桶位中的元素 即为 要remove删除的元素。(不用查询,直接删)
如果当前桶位要么是链表,要么是红黑树。
二、红黑树查找操作。
三、链表。
如果判断node不为空,说明按照key查找到需要删除的数据了。(先查询再删)
一、如果node是树节点,则进行树节点移除操作。
二、如果桶位元素即为查找结果,则将该元素的下一个元素放在桶位中。
三、否则(如果是链表),将当前元素p的下一个元素 设置成 要删除元素的下一个元素。7、HashMap replace方法分析
替换方法:
public boolean replace(K key,V oldValue,V newValue){}