网络爬虫-学习记录(五)利用scrapy实现多进程爬取
目录
一、任务描述
二、任务网站描述
三、运行结果及说明
(一)单进程58同城招聘爬取
1.新建项目
2.创建爬虫
3.运行爬虫
4.爬取文件写入
5.运行文件
6.运行结果
7.将爬取的结果存入csv文件
(二)多进程爬取占星网站
1.新建项目
2.新建爬虫文件
3.爬取文件写入
4.运行文件
5.将爬取结果写入文件
6.结果展示
四、源码
1.单进程源码
2.多进程源码
一、任务描述
选取一个网站,例如新闻类、影评类、小说、股票金融类、就业类等等。
(1) 小黑框下使用scrapy创建项目进行爬取;
(2) 分析网页结构,在小黑框下运用xpath初步进行信息提取;
(3) 实现多进程爬取,爬取两个网址。
要求:
1.完成内链接提取和数据提取
2.设置合适的异常处理,保证程序正确运行
3.将提取的数据存储到文件:txt或csv或json等
二、任务网站描述
- 单进程58同城招聘爬取
请输入验证码 ws:123.56.4.112
- 多进程爬取占星网站
占星后天十二宫位简介 - 占星之门
占星十大行星简介 - 占星之门
三、运行结果及说明
(一)单进程58同城招聘爬取
1.新建项目

2.创建爬虫
创建一个名字为zhaoping,域名为sjz.58.com的爬虫

3.运行爬虫
a)初步获取

b)检查信息的获取

4.爬取文件写入
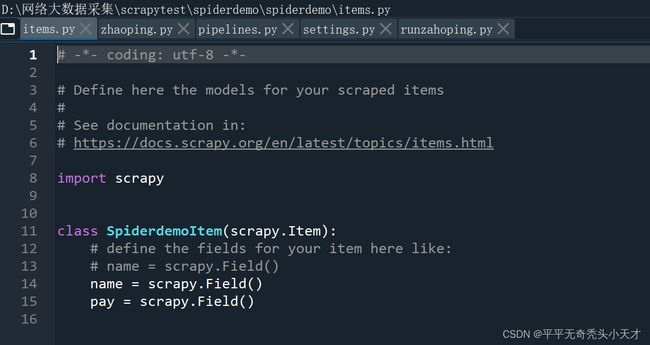
Items文件
Setting文件

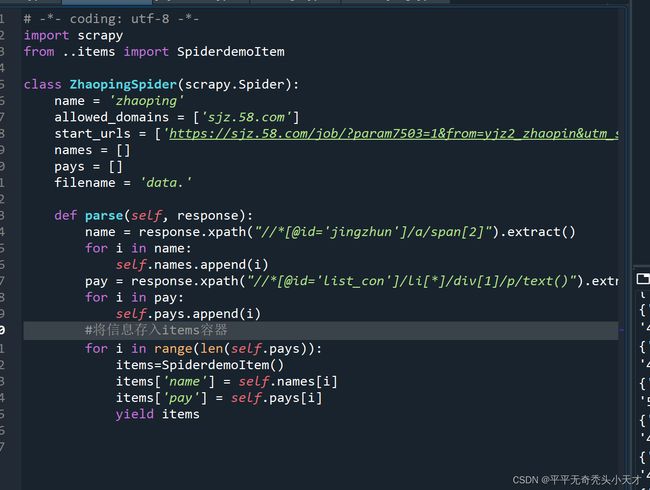
爬虫zhaoping主文件
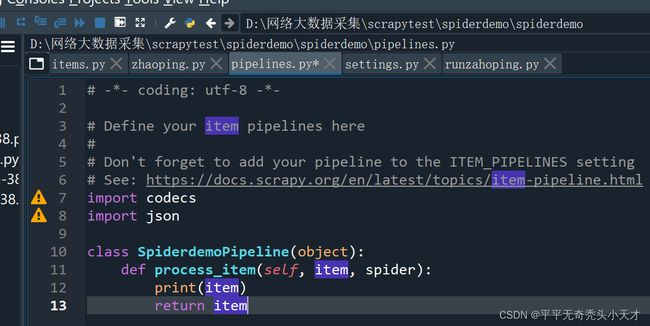
Pipelines文件
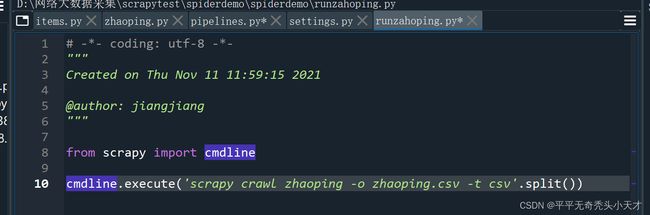
5.运行文件
6.运行结果
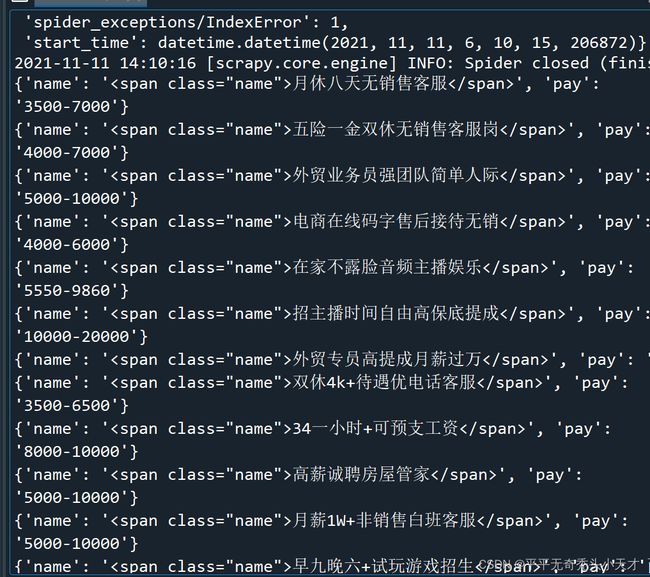
7.将爬取的结果存入csv文件

(二)多进程爬取占星网站
1.新建项目

2.新建爬虫文件

初步获取无问题
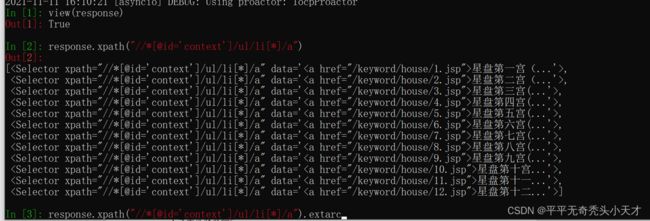
3.爬取文件写入
Items文件写入
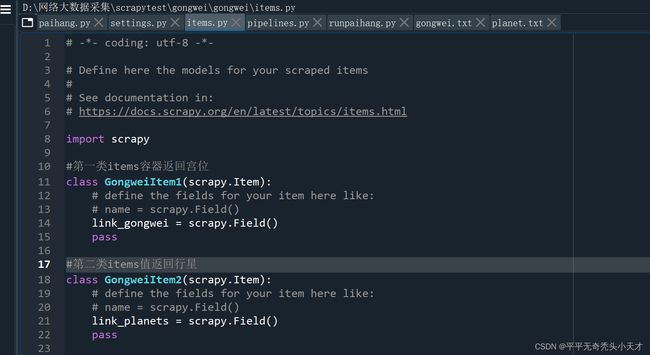
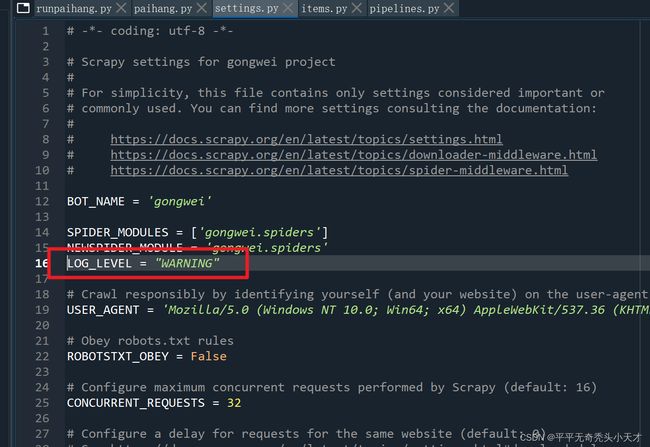
Setting文件写入
爬虫paihang主文件

Pipeline文件
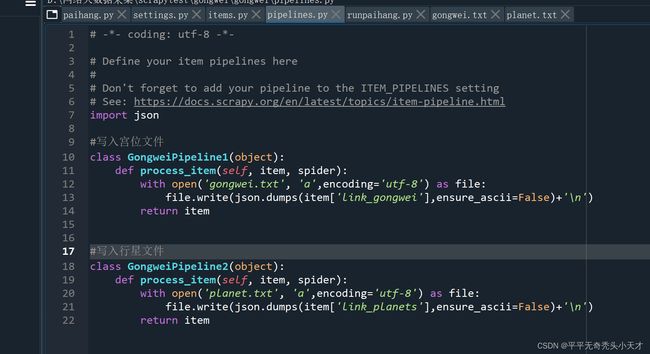
4.运行文件

5.将爬取结果写入文件
6.结果展示
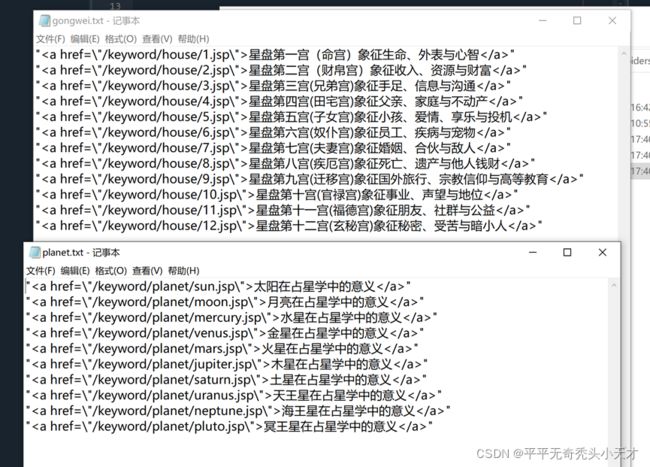
四、源码
1.单进程源码
Zhaoping.py
import scrapy
from ..items import SpiderdemoItem
class ZhaopingSpider(scrapy.Spider):
name = 'zhaoping'
allowed_domains = ['sjz.58.com']
start_urls = ['https://sjz.58.com/job/?param7503=1&from=yjz2_zhaopin&utm_source=market&spm=u-2d2yxv86y3v43nkddh1.BDPCPZ_BT&PGTID=0d202408-000f-12e9-1f36-6690b23ad3b9&ClickID=2']
names = []
pays = []
filename = 'data.'
def parse(self, response):
name = response.xpath("//*[@id='jingzhun']/a/span[2]").extract()
for i in name:
self.names.append(i)
pay = response.xpath("//*[@id='list_con']/li[*]/div[1]/p/text()").extract()
for i in pay:
self.pays.append(i)
#将信息存入items容器
for i in range(len(self.pays)):
items=SpiderdemoItem()
items['name'] = self.names[i]
items['pay'] = self.pays[i]
yield items
items.py
import scrapy
class SpiderdemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
pay = scrapy.Field()
pipelines.py
# -*- coding: utf-8 -*-
import codecs
import json
class SpiderdemoPipeline(object):
def process_item(self, item, spider):
print(item)
return item
runzhaoping.py
from scrapy import cmdline
cmdline.execute('scrapy crawl zhaoping -o zhaoping.csv -t csv'.split())
2.多进程源码
Paihang.py
# -*- coding: utf-8 -*-
import scrapy
from gongwei.items import GongweiItem1,GongweiItem2
#爬宫位网站内容
class PaihangSpider1(scrapy.Spider):
name = 'paihang1'
allowed_domains = ['cn.astrodoor.cc']
start_urls = ['https://cn.astrodoor.cc/keyword/house.jsp']
gongweis = []
custom_settings = {
'ITEM_PIPELINES': {'gongwei.pipelines.GongweiPipeline1': 300,},
}
def parse(self, response):
link_gongwei = response.xpath("//*[@id='context']/ul/li[*]/a").extract()
for i in link_gongwei:
self.gongweis.append(i)
#将信息存入items容器
for i in range(len(self.gongweis)):
items1=GongweiItem1()
items1['link_gongwei'] = self.gongweis[i]
yield items1
#爬行星网站内容
class PaihangSpider2(scrapy.Spider):
name = 'paihang2'
allowed_domains = ['cn.astrodoor.cc']
start_urls = ['https://cn.astrodoor.cc/keyword/planet.jsp']
names2 = []
planets = []
custom_settings = {
'ITEM_PIPELINES': {'gongwei.pipelines.GongweiPipeline2': 301,},
}
def parse(self, response):
link_planets = response.xpath("//*[@id='context']/ul/li[*]/a").extract()
for i in link_planets:
self.planets.append(i)
#将信息存入items容器
for i in range(len(self.planets)):
items2=GongweiItem2()
items2['link_planets'] = self.planets[i]
yield items2
items.py
import scrapy
#第一类items容器返回宫位
class GongweiItem1(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
link_gongwei = scrapy.Field()
pass
#第二类items值返回行星
class GongweiItem2(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
link_planets = scrapy.Field()
pass
pipelines.py
import json
#写入宫位文件
class GongweiPipeline1(object):
def process_item(self, item, spider):
with open('gongwei.txt', 'a',encoding='utf-8') as file:
file.write(json.dumps(item['link_gongwei'],ensure_ascii=False)+'\n')
return item
#写入行星文件
class GongweiPipeline2(object):
def process_item(self, item, spider):
with open('planet.txt', 'a',encoding='utf-8') as file:
file.write(json.dumps(item['link_planets'],ensure_ascii=False)+'\n')
return item
setting.py
添加:
LOG_LEVEL = "WARNING"
runpaihang.py
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
crawler = CrawlerProcess(settings)
crawler.crawl('paihang1')
crawler.crawl('paihang2')
crawler.start()