Linux ARM系统调用过程分析(二)——Linux系统调用流程分析
Linux ARM系统调用过程分析(二)——Linux系统调用流程分析
备注:
1. Kernel版本:5.4
2. 使用工具:Source Insight 4.0
3. 参考博客:
(1)arm-linux 系统调用流程
(2)ARM Linux上的系统调用代码分析
文章目录
- Linux ARM系统调用过程分析(二)——Linux系统调用流程分析
-
- 前言
- EABI和OABI
- 系统调用的初始化
-
- syscall_table_start
- NATIVE
- syscall_table_end
- 系统调用的产生
-
- glibc库
- 反汇编代码
- 系统调用产生过程
- 内核中系统调用的处理
-
- 中断向量表
- vector_swi分析
-
- 保存断点部分
- 系统设置
- 执行系统调用
- 返回用户空间
前言
在 linux 中,软硬件是有明显的分层的,出于安全或者是资源统筹考虑,硬件资源由内核进行统一管理,内核拥有绝对的权限,而用户空间无法直接访问硬件.在实际的应用中,用户进程总是无法避免需要操作到硬件,这个硬件可能是磁盘文件,USB接口等,这时候就需要向内核递交申请,让内核帮忙做硬件相关的事情,这个过程就由系统调用完成.
无论从硬件还是从软件角度来说,用户空间与内核空间有一道无法轻易逾越的屏障,如果是简单地一分为二,事情并不会有多复杂,不幸的是,这两者不能简单地完全隔断,用户空间的大部分操作都需要通过内核来完成,就连简单的申请内存操作,用户空间都无法独立自主地做到,因为这涉及到物理内存的分配,而物理内存也是硬件的一种,所以在这道屏障上需要开一扇门,来进行内核与用户之间的交互,这道门也就是系统调用.
用户空间的手不能伸到内核中,内核中的东西自然也不能暴露到用户空间中,所有请求与回复的资源都只能通过传递的方式,而这种信息传递还需要通过严格的检查.这就像在监狱中,服刑人员只能向监管人员提出申请,让他帮忙代办一些事情,而不能提出申请自己亲自出去办某件事,监狱内和外部世界是有严格划分的.
也就是说,用户程序执行系统调用时,由内核代替该进程去执行该用户原本没有权限执行的工作,比如磁盘操作,而用户程序等待内核的执行完成,再返回到该用户程序(实际情况会涉及到各进程的调度,为了理解方便这里简化了概念).该过程的另一种说法叫陷入内核.
从形式上来说,系统调用看起来就跟普通的 API 一样,比如进程需要读磁盘上的文件,使用 read 接口,因为普通用户没有读磁盘的权限,所以需要通过系统调用让内核帮忙做这件事,在实际的编程中,每当我们使用 read 函数时,内核中的 sys_read 函数就会被调用,看起来 sys_read 是 read 函数中的一个子程序一样,但是实际上情况要复杂得多.
read 函数处于用户空间,而 sys_read 处于内核空间,这两者明显不是调用与被调用的关系,而是一方请求另一方帮忙处理工作的过程,而 API 只是简单的程序调用而已,这两者的区别不言而喻.
在这一章中,我们将深入地讨论系统调用的执行过程,看看用户空间到底是如何通过系统调用这道门进入到内核,又是如何从内核返回的.
EABI和OABI
ABI 是应用程序二进制接口,每个操作系统都会为运行在该系统下的应用程序提供应用程序二进制接口(Application Binary Interface,ABI)。ABI包含了应用程序在这个系统下运行时必须遵守的编程约定,对于 arm 的函数调用而言,它定义了函数调用约定,系统调用形式以及目标文件的格式等.
在 arm 平台架构中,存在两种不同的 ABI 形式,OABI 和 EABI,OABI 中的 O 是 old 的意思,表示旧有的 ABI,而 EABI 是基于 OABI 上的改进,或者说它更适合目前大多数的硬件,OABI 和 EABI 的区别主要在于浮点的处理和系统调用,浮点的区别不做过多讨论,对于系统调用而言,OABI 和 EABI 最大的区别在于,OABI 的系统调用指令需要传递参数来指定系统调用号,而 EABI 中将系统调用号保存在 r7 中.
所以在系统调用的源码实现中,尽管大多数情况下都是使用 EABI 的系统调用方式,也会保持对 OABI 的兼容,而 CONFIG_OABI_COMPAT 表示是否保持对 OABI 的兼容,大部分平台都没有定义,所以在本章的讨论中不包括 OABI 的部分.
系统调用的初始化
系统调用由内核中定义的一个静态数组描述的,这个数组名为 sys_call_table,系统调用的数量由 NR_syscalls 这个宏描述,默认为 400,也可以手动地修改,这些系统调用的定义在 entry-common.S (arch/arm/kernel/)中:
syscall_table_start sys_call_table
#define COMPAT(nr, native, compat) syscall nr, native
#ifdef CONFIG_AEABI
#include
#else
#include
#endif
#undef COMPAT
syscall_table_end sys_call_table
#include 这个预编译指令在预编译阶段会将指定文件中的内容全部拷贝到当前地址,而 calls-eabi.S(arch/arm/include/generated) 文件中就是系统调用表列表的定义:
NATIVE(0, sys_restart_syscall)
NATIVE(1, sys_exit)
NATIVE(2, sys_fork)
NATIVE(3, sys_read)
NATIVE(4, sys_write)
// ......
ATIVE(395, sys_pkey_alloc)
NATIVE(396, sys_pkey_free)
NATIVE(397, sys_statx)
NATIVE(398, sys_rseq)
NATIVE(399, sys_io_pgetevents)
于是整个系统调用表的定义变成了:
syscall_table_start sys_call_table
NATIVE(0, sys_restart_syscall)
NATIVE(1, sys_exit)
NATIVE(2, sys_fork)
NATIVE(3, sys_read)
NATIVE(4, sys_write)
// ......
ATIVE(395, sys_pkey_alloc)
NATIVE(396, sys_pkey_free)
NATIVE(397, sys_statx)
NATIVE(398, sys_rseq)
NATIVE(399, sys_io_pgetevents)
syscall_table_end sys_call_table
这里有三个部分需要关注,syscall_table_start、syscall_table_end 和 NATIVE 这三个宏,接下来就一个个解析。
syscall_table_start
/* 定义 sys_call_table,并将 __sys_nr 清 0 */
.macro syscall_table_start, sym
.equ __sys_nr, 0 // 定义一个 __sys_nr 值为零
.type \sym, #object // 表示指定符号的类型为 object
ENTRY(\sym) // 定义一个全局符号
.endm
syscall_table_start 宏接收一个参数 sym,然后定义一个 __sys_nr 值为零,.type 表示指定符号的类型为 object。需要注意的是,这里的 ENTRY 并不是链接脚本中的 ENTRY 关键字,实际上这也是一个宏定义:
#define ENTRY(name) \
.globl name; \
name:
上面的调用中传入的参数是 sys_call_table,syscall_table_start sys_call_table 这个宏的意思就是:
- 创建一个 sys_call_table 的符号并使用 .globl 导出到全局符号
- 定义一个内部符号 __sys_nr,初始化为 0,这个变量主要用于后续系统调用好的计算和判断。
NATIVE
紧接着 syscall_table_start sys_call_table 这个语句的就是以 NATIVE 描述的系统调用列表,NATIVE 带两个参数:系统调用号和对应的系统调用函数,它的定义同样是一个宏:
#define NATIVE(nr, func) syscall nr, func
.macro syscall, nr, func
//__sys_nr 从0开始,总是指向已初始化系统调用的下一个系统调用号,
// 如果需要初始化的系统调用号小于 __sys_nr,
// 表示和已初始化的系统调用号冲突,报错。
.ifgt __sys_nr - \nr
.error "Duplicated/unorded system call entry"
.endif
// .rept 指令表示下一条 .endr 指令之前的指令执行次数
.rept \nr - __sys_nr
// 放置 sys_ni_syscall 函数到当前地址,
// sys_ni_syscall 是一个空函数,
// 直接返回 -ENOSYS,
// 即如果定义的系统调用号之间有间隔,填充为该函数
.long sys_ni_syscall
.endr
.long \func // 将系统调用函数放置在当前地址
.equ __sys_nr, \nr + 1 // 将 __sys_nr 更新为当前系统调用号 +1
.endm
其实就是使用 NATIVE 指令实现一个 sys_call_table 的数组,不断地在数组尾部放置函数指针,而系统调用号对应数组的下标,只是添加了一些异常处理。
syscall_table_end
接下来就是系统调用的收尾部分:syscall_table_end,sys_call_table,传入的参数为 sys_call_table,它也是通过宏实现的:
.macro syscall_table_end, sym
// __NR_syscalls 是当前系统下静态定义的最大系统调用号,
// 当前初始化的系统调用号不能超出
.ifgt __sys_nr - __NR_syscalls
.error "System call table too big"
.endif
.rept __NR_syscalls - __sys_nr
// 当前已定义系统调用号到最大系统调用之间未使用的
// 系统调用号使用 sys_ni_syscall 这个空函数填充
.long sys_ni_syscall
.endr
.size \sym, . - \sym // 设置 sym 也就是 sys_call_table 的 size
.endm
系统调用的产生
系统调用尽管是由用户空间产生的,但是在日常的编程工作中我们并不会直接使用系统调用,只知道在使用诸如 read、write 函数时,对应的系统调用就会产生,实际上,发起系统调用的真正工作封装在 C 库中,要查看系统调用的产生细节,一方面可以查看 C 库,另一方面也可以查看编译时的汇编代码。
glibc库
既然系统调用基本都是封装在 glibc 中,最直接的方法就是看看它们的源代码实现,因为只是探究系统调用的流程,找一个相对简单的函数作为示例即可,这里以 close 为例,下载的源代码版本为 glibc-2.30.
close 的定义在 close.c 中:
int __close (int fd)
{
return SYSCALL_CANCEL (close, fd);
}
SYSCALL_CANCEL 是一个宏,被定义在 sysdeps/unix/sysdep.h 中,由于该宏的嵌套有些复杂,全部贴上来进行解析并没有太多必要,就只贴上它的调用路径:
SYSCALL_CANCEL
->INLINE_SYSCALL_CALL
->__INLINE_SYSCALL_DISP
->__INLINE_SYSCALLn(n=1~7)
->INLINE_SYSCALL
整个实现流程几乎全部由宏实现,在最后的 INTERNAL_SYSCALL_RAW 中,执行了以下的指令:
asm volatile ("swi 0x0 @ syscall " #name \
: "=r" (_a1) \
: "r" (_nr) ASM_ARGS_##nr \
: "memory"); \
_a1; })
其中的 swi 指令正是执行系统调用的软中断指令,在新版的 arm 架构中,使用 svc 指令代替 swi,这两者是别名的关系,没有什么区别.
在 OABI 规范中,系统调用号由 swi(svc) 后的参数指定,在 EABI 规范中,系统调用号则由 r7 进行传递,系统调用的参数由寄存器进行传递.
这里需要区分系统调用和普通函数调用,对于普通函数调用而言,前四个参数被保存在 r0~r3 中,其它的参数被保存在栈上进行传递.
但是在系统调用中,swi(svc)指令将会引起处理器模式的切换,user->svc,而 svc 模式下的 sp 和 user 模式下的 sp 并不是同一个,因此无法使用栈直接进行传递,从而需要将所有的参数保存在寄存器中进行传递,在内核文件 include/linux/syscall.h 中定义了系统调用相关的函数和宏,其中 SYSCALL_DEFINE_MAXARGS 表示系统调用支持的最多参数值,在 arm 下为 6,也就是 arm 中系统调用最多支持 6 个参数,分别保存在 r0~r5 中.
反汇编代码
在Linux下系统调用是用软中断实现的,下面以一个简单的open例子简要分析一下应用层的open是如何调用到内核中的sys_open的。
// open.c
#include
#include
#include
#include
int main(int argc, const char *argv[])
{
int fd;
fd = open(".", O_RDWR);
close(fd);
return 0;
}
这里需要注意的是:open是C库提供的库函数,并不是系统调用,系统调用时在内核空间的,应用空间无法直接调用。在《Linux内核设计与实现》中说:要访问系统调用(在Linux中常称作syscall),通常通过C库中定义的函数调用来进行。将open.c进行静态编译,然后反汇编,看一下是如何调用open的?
arm-linux-gnueabihf-gcc open.c --static -o open
arm-linux-gnueabihf-objdump -DS open > open.dis
下面截取open.dis中的一部分进行说明:
0001049c :
1049c: b580 push {r7, lr}
1049e: b084 sub sp, #16
104a0: af00 add r7, sp, #0
104a2: 6078 str r0, [r7, #4]
104a4: 6039 str r1, [r7, #0]
104a6: 2102 movs r1, #2
104a8: f242 300c movw r0, #8972 ; 0x230c
104ac: f2c0 0005 movt r0, #5
104b0: f010 fae6 bl 20a80 <__libc_open>
104b4: 60f8 str r0, [r7, #12]
104b6: 68f8 ldr r0, [r7, #12]
104b8: f010 fc22 bl 20d00 <__libc_close>
104bc: 2300 movs r3, #0
104be: 4618 mov r0, r3
104c0: 3710 adds r7, #16
104c2: 46bd mov sp, r7
104c4: bd80 pop {r7, pc}
...
00020a80 <__libc_open>:
20a80: f8df c04a ldr.w ip, [pc, #74] ; 20ace <__libc_open+0x4e>
20a84: 44fc add ip, pc
20a86: f8dc c000 ldr.w ip, [ip]
20a8a: f09c 0f00 teq ip, #0
20a8e: b480 push {r7}
20a90: d108 bne.n 20aa4 <__libc_open+0x24>
20a92: 2705 movs r7, #5
20a94: df00 svc 0
20a96: bc80 pop {r7}
20a98: f510 5f80 cmn.w r0, #4096 ; 0x1000
20a9c: bf38 it cc
20a9e: 4770 bxcc lr
20aa0: f002 baf6 b.w 23090 <__syscall_error>
20aa4: b50f push {r0, r1, r2, r3, lr}
20aa6: f001 faa9 bl 21ffc <__libc_enable_asynccancel>
20aaa: 4684 mov ip, r0
20aac: bc0f pop {r0, r1, r2, r3}
// 系统调用sys_open的系统调用号是5,将系统调用号存放到寄存器R7当中
20aae: 2705 movs r7, #5
// 在arch/arm/include/asm/unistd.h中:
// #define __NR_open (__NR_SYSCALL_BASE+5)
// 其中,__NR_OABI_SYSCALL_BASE是0
20ab0: df00 svc 0 // 产生软中断
20ab2: 4607 mov r7, r0
20ab4: 4660 mov r0, ip
20ab6: f001 fae5 bl 22084 <__libc_disable_asynccancel>
20aba: 4638 mov r0, r7
20abc: f85d eb04 ldr.w lr, [sp], #4
20ac0: bc80 pop {r7}
20ac2: f510 5f80 cmn.w r0, #4096 ; 0x1000
20ac6: bf38 it cc
20ac8: 4770 bxcc lr
20aca: f002 bae1 b.w 23090 <__syscall_error>
20ace: 00058288 andeq r8, r5, r8, lsl #5
20ad2: 0000bf00 andeq fp, r0, r0, lsl #30
系统调用产生过程
user_func()(如:open) ---> __libc_open() ---> svc 0 ---> vector_swi --->system_call ---> sys_func
内核中系统调用的处理
系统调用的处理完全不像是想象中那么简单,从用户空间到内核需要经历处理器模式的切换,svc 指令实际上是一条软件中断指令,也是从用户空间主动到内核空间的唯一通路(被动可以通过中断、其它异常) 相对应的处理器模式为从 user 模式到 svc 模式,svc 指令执行系统调用的大致流程为:
- 执行 svc 指令,产生软中断,跳转到系统中断向量表的 svc 向量处执行指令,这个地址是 0xffff0008 处(也可配置在 0x00000008处),并将处理器模式设置为 svc.
- 保存用户模式下的程序断点信息,以便系统调用返回时可以恢复用户进程的执行.
- 根据传入的系统调用号(r7)确定内核中需要执行的系统调用,比如 read 对应 syscall_read.
- 执行完系统调用之后返回到用户进程,继续执行用户程序.
中断向量表
linux 的中断向量表的定义在 arch/arm/kernel/entry-armv.S 中:
.section .vectors, "ax", %progbits
.L__vectors_start:
W(b) vector_rst
W(b) vector_und
W(ldr) pc, .L__vectors_start + 0x1000
W(b) vector_pabt
W(b) vector_dabt
W(b) vector_addrexcptn
W(b) vector_irq
W(b) vector_fiq
整个向量表被单独放置在 .vectors 段中,包括 reset,undefined,abort,irq 等异常向量,svc 异常向量在第三条,这是一条跳转指令,其中 .L 表示 后续的 symbol 为 local symbol,这条指令的含义是将 __vectors_start+0x1000 地址处的指令加载到 pc 中执行, __vectors_start 的地址在哪里呢?
通过链接脚本 arch/arm/kernel/vmlinux.lds 查看对应的链接参数:
__vectors_start = .;
.vectors 0xffff0000 : AT(__vectors_start) {
*(.vectors)
}
. = __vectors_start + SIZEOF(.vectors);
__vectors_end = .;
__stubs_start = .;
.stubs ADDR(.vectors) + 0x1000 : AT(__stubs_start) {
*(.stubs)
}
可以看到, .vectors 段链接时确定的虚拟地址指定为 0xffff0000,加载地址指定为 __vectors_start 的地址, __vectors_start 被赋值为当前的地址定位符,并不确定,紧随着上一个段放置,可以确定的是 __vectors_start 是 .vectors 段的起始部分.
根据下一条 .stubs 段的描述,该段被放置在 .vectors + 0x1000 地址处,等于 __vectors_start + 0x1000,正是我们要找的 svc 向量的跳转地址,于是在内核向量代码部分搜索 .stub 段就可以找到 svc 跳转代码了:
.section .stubs, "ax", %progbits
@ This must be the first word
.word vector_swi
.stubs 部分放置的是 vector_swi 这个符号的地址,所以绕来绕去,svc 向量处放置的指令相当于:mov pc,vector_swi,即跳转到 vector_swi 处执行.
vector_swi 是一个标号,被定义在 arch/arm/kernel/entry-common.S 中,在查看 vector_swi 的实现源码之前,有几个宏需要了解一下,这些宏直接影响到程序执行的分支,了解这些宏是否被定义或者为何值,才能掌握源码的执行路径,它们分别是:
-
CONFIG_CPU_V7M :针对 armv7-M 处理器,而我们基于 armv7-A 架构分析,所以该宏未定义。
-
ARM(instruct) 、THUMB(instruct) :这两个宏的定义取决于另一个宏
CONFIG_THUMB2_KERNEL,该宏用于指定使用 thumb 指令集还是 arm 指令集,如果使用 arm 指令集,CONFIG_THUMB2_KERNEL 不被 defined,则 ARM(instruct) 括号中的指令被执行,THUMB(instruct) 括号中的指令不被执行,反之亦然。在当前版本(4.14) linux 内核中, CONFIG_THUMB2_KERNEL 未被定义,即使用 arm 指令集,因此在源码分析中忽略 THUMB(instruct) 部分。 -
TRACE(instruct):顾名思义,这是程序追踪相关的,如果定义了 CONFIG_TRACE_IRQFLAGS 或者 CONFIG_CONTEXT_TRACKING 两个宏,括号中的指令就会被执行,否则就忽略,在本章中专注于分析系统调用流程,对于 TRACE 的实现不做过多探讨。
-
CONFIG_OABI_COMPAT:是否兼容 OABI 宏,在当前平台上不兼容,未定义。
-
CONFIG_AEABI:是否使用 EABI 宏,当前平台默认使用 EABI,所以该宏支持并被定义,实际上 EABI 和 OABI 是可以共存的。
-
CONFIG_ARM_THUMB:arm 和 thumb 指令集的支持,支持并被定义。
对于上述的宏,CONFIG_CPU_V7M 、THUMB(instruct)、TRACE(instruct)、CONFIG_OABI_COMPAT 未支持,所以这四个宏对应的代码部分可以忽略,简化源代码的分析工作。
vector_swi分析
/*=============================================================================
* SWI handler
*-----------------------------------------------------------------------------
*/
.align 5
ENTRY(vector_swi)
#ifdef CONFIG_CPU_V7M // 针对 armv7-M 处理器
v7m_exception_entry
#else
/************** 保存断点部分 ***************/
// PT_REGS_SIZE 的大小为 = 72,
// 该指令在栈上分配 72 字节的空间用于保存参数
sub sp, sp, #PT_REGS_SIZE
// 将 r0 ~ r12 保存到栈上,对于 user 模式和 svc 模式,
// r0 ~ r12 是共用的
stmia sp, {r0 - r12} @ Calling r0 - r12
// 定位到栈上应该保存 PC 寄存器的地址,
// 存放到 r8 中,S_PC 的值为 60,
// 因为栈是向下增长,所以 add 指令相当于栈的回溯
ARM( add r8, sp, #S_PC )
// 将用户空间的 sp 和 lr 保存到 r8 地址处,详解见下文
ARM( stmdb r8, {sp, lr}^ ) @ Calling sp, lr
THUMB( mov r8, sp )
THUMB( store_user_sp_lr r8, r10, S_SP ) @ calling sp, lr
// saved_psr 其实就是 r8 的一个别名,
// 该指令表示将 spsr 保存到 r8 中,
// spsr 中保存了 user 下的 APSR
mrs saved_psr, spsr @ called from non-FIQ mode, so ok.
TRACE( mov saved_pc, lr )
// 一般模式下,saved_pc 是 lr 的别名,
// 将返回地址保存在栈上对应位置
str saved_pc, [sp, #S_PC] @ Save calling PC
// 将 spsr 保存在栈上对应位置
str saved_psr, [sp, #S_PSR] @ Save CPSR
// 将 r0 保存到 OLD_R0 处,OLD_R0 解释见下文
str r0, [sp, #S_OLD_R0] @ Save OLD_R0
#endif
/**************** 系统设置 ****************/
// 等于 mov fp,#0,在 arm 编译器中 frame point 为 r11
zero_fp
// 通过读写 SCTLR 寄存器与 __cr_alignment
// 标号处设置的对齐参数对比来决定是否设置对齐检查,
// 该寄存器由 cp15 协处理器操作,需要使用 mrs 和 msr 指令。
alignment_trap r10, ip, __cr_alignment
// trace irq 部分,CONFIG_TRACE_IRQFLAGS 未定义,这个宏不执行操作
asm_trace_hardirqs_on save=0
// 执行 cpsie i 指令,打开中断
enable_irq_notrace
// 因为未定义 CONFIG_CONTEXT_TRACKING 宏,该宏不执行操作
ct_user_exit save=0
/*
* Get the system call number.
*/
#if defined(CONFIG_OABI_COMPAT)
/*
* If we have CONFIG_OABI_COMPAT then we need to look at the swi
* value to determine if it is an EABI or an old ABI call.
*/
#ifdef CONFIG_ARM_THUMB
tst saved_psr, #PSR_T_BIT
movne r10, #0 @ no thumb OABI emulation
USER( ldreq r10, [saved_pc, #-4] ) @ get SWI instruction
#else
USER( ldr r10, [saved_pc, #-4] ) @ get SWI instruction
#endif
ARM_BE8(rev r10, r10) @ little endian instruction
#elif defined(CONFIG_AEABI)
/*
* Pure EABI user space always put syscall number into scno (r7).
*/
#elif defined(CONFIG_ARM_THUMB)
/* Legacy ABI only, possibly thumb mode. */
tst saved_psr, #PSR_T_BIT @ this is SPSR from save_user_regs
addne scno, r7, #__NR_SYSCALL_BASE @ put OS number in
USER( ldreq scno, [saved_pc, #-4] )
#else
/* Legacy ABI only. */
USER( ldr scno, [saved_pc, #-4] ) @ get SWI instruction
#endif
/* saved_psr and saved_pc are now dead */
// tbl 是 r8 寄存器的别名,uaccess_disable 宏的功能
// 在于设定处理器模式下对于内存块的访问权限,详解见下文
uaccess_disable tbl
/************** 执行系统调用 ****************/
// tbl 是 r8 的别名,sys_call_table 在上文中有介绍,
// 这是系统调用表的基地址,将系统调用表基地址放在 r8 中
adr tbl, sys_call_table @ load syscall table pointer
#if defined(CONFIG_OABI_COMPAT)
/*
* If the swi argument is zero, this is an EABI call and we do nothing.
*
* If this is an old ABI call, get the syscall number into scno and
* get the old ABI syscall table address.
*/
bics r10, r10, #0xff000000
eorne scno, r10, #__NR_OABI_SYSCALL_BASE
ldrne tbl, =sys_oabi_call_table
#elif !defined(CONFIG_AEABI)
bic scno, scno, #0xff000000 @ mask off SWI op-code
eor scno, scno, #__NR_SYSCALL_BASE @ check OS number
#endif
// tsk 是 r9 的别名,该宏将 thread_info
// 的基地址放在 r9 中,详解见下文
get_thread_info tsk
/*
* Reload the registers that may have been corrupted on entry to
* the syscall assembly (by tracing or context tracking.)
*/
TRACE( ldmia sp, {r0 - r3} )
local_restart:
// tsk 中保存 thread_info 基地址,
// 基地址+偏移值就是访问结构体内成员,
// TI_FLAGS 偏移值对应 thread_info->flags 成员,保存在 r10 中
ldr r10, [tsk, #TI_FLAGS] @ check for syscall tracing
// 将 r4 和 r5 的值保存在栈上,
// 这两个寄存器中保存着系统调用第五个和第六个参数(如果存在)
stmdb sp!, {r4, r5} @ push fifth and sixth args
// tst 指令执行位与运算,并更新状态寄存器,
// 这里用于判断是否在进行系统调用tracing(跟踪),
// 如果处于系统调用跟踪,thread_info->flags 中与
// _TIF_SYSCALL_WORK 对应的位将会被置位
tst r10, #_TIF_SYSCALL_WORK @ are we tracing syscalls?
// thread_info->flags| _TIF_SYSCALL_WORK 的结果不为0,
// 表示处于系统调用 tracing,跳转到 tracing 部分执行,
// 这将走向系统调用的另一个 slow path 分支,
// 关于 tracing 部分不做详细讨论
bne __sys_trace
// 从名称可以看出,这条宏用于执行系统调用,
// 第一个参数是 tbl,表示系统调用表基地址,
// 第二个参数为 scno(r7),第三个参数为 r10,
// 第四个参数为 __ret_fast_syscall(返回程序),
// 注意这里的参数是 invoke_syscall(entry-header.S) 宏的参数,
// 并不是系统调用的参数。 详解见下文
invoke_syscall tbl, scno, r10, __ret_fast_syscall
add r1, sp, #S_OFF
2: cmp scno, #(__ARM_NR_BASE - __NR_SYSCALL_BASE)
eor r0, scno, #__NR_SYSCALL_BASE @ put OS number back
bcs arm_syscall
mov why, #0 @ no longer a real syscall
b sys_ni_syscall @ not private func
#if defined(CONFIG_OABI_COMPAT) || !defined(CONFIG_AEABI)
/*
* We failed to handle a fault trying to access the page
* containing the swi instruction, but we're not really in a
* position to return -EFAULT. Instead, return back to the
* instruction and re-enter the user fault handling path trying
* to page it in. This will likely result in sending SEGV to the
* current task.
*/
9001:
sub lr, saved_pc, #4
str lr, [sp, #S_PC]
get_thread_info tsk
b ret_fast_syscall
#endif
ENDPROC(vector_swi)
当执行vector_swi的时候,硬件已经做了不少的事情,包括:
(1)将CPSR寄存器保存到SPSR_svc寄存器中,将返回地址(用户空间执行swi指令的下一条指令)保存在lr_svc中
(2)设定CPSR寄存器的值。具体包括:CPSR.M = ‘10011’(svc mode),CPSR.I = ‘1’(disable IRQ),CPSR.IT = ‘00000000’(TODO),CPSR.J = ‘0’(),CPSR.T = SCTLR.TE(J和Tbit和Instruction set state有关,和本文无关),CPSR.E = SCTLR.EE(字节序定义,和本文无关)。
(3)PC设定为swi异常向量的地址
随后的行为都是软件行为了,因为代码中涉及压栈动作,所以首先要确定的就是当前在哪里这个问题。sp_svc早在进程切换的时候就已经设定好了,就是该进程的内核栈。
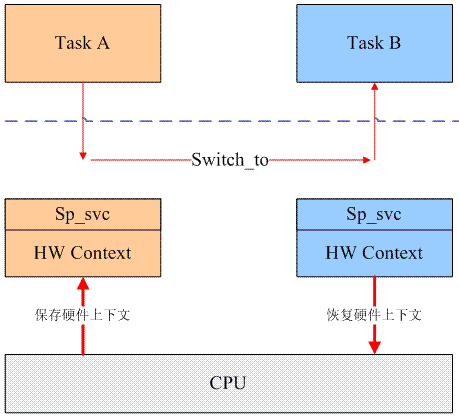
当Task A切换到Task B的时候,有一个很重要的步骤就是HW context的切换,由于Task A和Task B都在同一个CPU上运行,因此需要把当前CPU的各种寄存器以及状态信息保存在一块memory data block中(也就是硬件上下文了),并且用Task B的硬件上下文的数值来加载CPU,这里面就包括sp_svc。在内核态,完成进程切换后,最终会返回task B的用户空间执行,但是这时候Task B对应的内核栈(sp_svc0)是确定的了。
当通过系统调用进入内核的时候,内核栈已经是准备好了,不过这时候内核栈上是空的,执行完上述代码之后,在内核栈上形成如下的用户空间现场:

保存断点部分
在从用户跳转到内核之初,硬件实现了用户级别的 APSR 保存到 svc 模式下的 SPSR(注意,APSR 是受访问限制版本的 CPSR,是同一个寄存器,而 SPSR 是 bank 类型的),返回值保存到 svc 模式下的 lr 操作,然后执行跳转到中断向量表 svc 向量处,对于 user 模式下的寄存器断点保存与恢复,还是需要软件来实现,这部分代码及解析如下:
/************** 保存断点部分 ***************/
// PT_REGS_SIZE 的大小为 = 72,
// 该指令在栈上分配 72 字节的空间用于保存参数
sub sp, sp, #PT_REGS_SIZE
// 将 r0 ~ r12 保存到栈上,对于 user 模式和 svc 模式,
// r0 ~ r12 是共用的
stmia sp, {r0 - r12} @ Calling r0 - r12
// 定位到栈上应该保存 PC 寄存器的地址,
// 存放到 r8 中,S_PC 的值为 60,
// 因为栈是向下增长,所以 add 指令相当于栈的回溯
ARM( add r8, sp, #S_PC )
// 将用户空间的 sp 和 lr 保存到 r8 地址处,详解见下文
ARM( stmdb r8, {sp, lr}^ ) @ Calling sp, lr
THUMB( mov r8, sp )
THUMB( store_user_sp_lr r8, r10, S_SP ) @ calling sp, lr
// saved_psr 其实就是 r8 的一个别名,
// 该指令表示将 spsr 保存到 r8 中,
// spsr 中保存了 user 下的 APSR
mrs saved_psr, spsr @ called from non-FIQ mode, so ok.
TRACE( mov saved_pc, lr )
// 一般模式下,saved_pc 是 lr 的别名,
// 将返回地址保存在栈上对应位置
str saved_pc, [sp, #S_PC] @ Save calling PC
// 将 spsr 保存在栈上对应位置
str saved_psr, [sp, #S_PSR] @ Save CPSR
// 将 r0 保存到 OLD_R0 处,OLD_R0 解释见下文
str r0, [sp, #S_OLD_R0] @ Save OLD_R0
#endif
为什么在刚开始要在栈上分配 72 字节的参数,这是怎么计算得来的?
PT_REGS_SIZE 宏对应 sizeof(struct pt_regs),而 struct pt_regs 的定义为 unsigned long uregs[18],这些空间全部用于保存参数,对应 18 个寄存器值。这 18 个寄存器包括 16 个核心寄存器 r0~r15,一个 CPSR(APSR) 状态寄存器,以及一个 old_r0 寄存器。
有一个 r0,为什么还要分配一个 old_r0 呢?这是因为,在异常发生时,自然要将用户空间的 r0 压栈以保存断点值,但是系统调用本身也会有返回值需要传递到用户空间,而这个返回值正是保存在 r0 中的,因此发生系统调用前的 r0 就会被返回值覆盖,在一般情况下,这其实也不会有什么问题,但是在两种场合下有意义:
- ptrace,这和 debug 相关
- system call restart
用户空间使用 svc 指令产生系统调用时 r0 用于传递参数,并复制一份到 OLD_r0,当系统调用返回的时候,r0 是系统调用的返回值。
对于保存用户空间的 sp 和 lr指令:
ARM( stmdb r8, {sp, lr}^ ) @ Calling sp, lr
这里有两个细节需要注意,stmdb 中的 db 表示 decrement before,也就是在操作之前先递减 r8,于是 r8 的地址指向了应该存放 lr 的空间,而 stm* 指令操作顺序为从右往左,因此把 lr 和 sp 保存到了正确的地址上。
主要到指令最后的 ^,这个特殊符号表明:所操作的寄存器不是当前模式下的,而是 user 模式下的寄存器,这是一条特殊指令用于跨模式访问寄存器。
到这里,整个断点保存的工作就圆满完成了,给自己留好了后路,就可以欢快地去做正事了。
系统设置
/**************** 系统设置 ****************/
// 等于 mov fp,#0,在 arm 编译器中 frame point 为 r11
zero_fp
// 通过读写 SCTLR 寄存器与 __cr_alignment
// 标号处设置的对齐参数对比来决定是否设置对齐检查,
// 该寄存器由 cp15 协处理器操作,需要使用 mrs 和 msr 指令。
alignment_trap r10, ip, __cr_alignment
// trace irq 部分,CONFIG_TRACE_IRQFLAGS 未定义,这个宏不执行操作
asm_trace_hardirqs_on save=0
// 执行 cpsie i 指令,打开中断
enable_irq_notrace
// 因为未定义 CONFIG_CONTEXT_TRACKING 宏,该宏不执行操作
ct_user_exit save=0
/*
* Get the system call number.
*/
#if defined(CONFIG_OABI_COMPAT)
/*
* If we have CONFIG_OABI_COMPAT then we need to look at the swi
* value to determine if it is an EABI or an old ABI call.
*/
#ifdef CONFIG_ARM_THUMB
tst saved_psr, #PSR_T_BIT
movne r10, #0 @ no thumb OABI emulation
USER( ldreq r10, [saved_pc, #-4] ) @ get SWI instruction
#else
USER( ldr r10, [saved_pc, #-4] ) @ get SWI instruction
#endif
ARM_BE8(rev r10, r10) @ little endian instruction
#elif defined(CONFIG_AEABI)
/*
* Pure EABI user space always put syscall number into scno (r7).
*/
#elif defined(CONFIG_ARM_THUMB)
/* Legacy ABI only, possibly thumb mode. */
tst saved_psr, #PSR_T_BIT @ this is SPSR from save_user_regs
addne scno, r7, #__NR_SYSCALL_BASE @ put OS number in
USER( ldreq scno, [saved_pc, #-4] )
#else
/* Legacy ABI only. */
USER( ldr scno, [saved_pc, #-4] ) @ get SWI instruction
#endif
/* saved_psr and saved_pc are now dead */
// tbl 是 r8 寄存器的别名,uaccess_disable 宏的功能
// 在于设定处理器模式下对于内存块的访问权限,详解见下文
uaccess_disable tbl
对于 uaccess_disable 这条指令,是和 VMSA(Virtual Memory System Architecture 虚拟内存架构) 相关的内容,主要是和内存的权限控制相关,相对应的寄存器为 DACR(Domain Access Control Register),这个寄存器由协处理器进行操作,对应的协处理器读指令为 mcr p15 arm_r c3, c0, 0,其中,arm_r 是 arm 核心寄存器(r0,r1等),该指令表示将 DACR 中的值读取到 arm_r 寄存器中。
DACR 定义了 16 块内存区域的访问权限,每块的访问权限由两个位来控制,uaccess_disable 这条指令就是禁止某些内存区域的访问权限。
执行系统调用
做完相应的系统设置,就来到了我们的正题,系统调用的执行:
/************** 执行系统调用 ****************/
// tbl 是 r8 的别名,sys_call_table 在上文中有介绍,
// 这是系统调用表的基地址,将系统调用表基地址放在 r8 中
adr tbl, sys_call_table @ load syscall table pointer
#if defined(CONFIG_OABI_COMPAT)
/*
* If the swi argument is zero, this is an EABI call and we do nothing.
*
* If this is an old ABI call, get the syscall number into scno and
* get the old ABI syscall table address.
*/
bics r10, r10, #0xff000000
eorne scno, r10, #__NR_OABI_SYSCALL_BASE
ldrne tbl, =sys_oabi_call_table
#elif !defined(CONFIG_AEABI)
bic scno, scno, #0xff000000 @ mask off SWI op-code
eor scno, scno, #__NR_SYSCALL_BASE @ check OS number
#endif
// tsk 是 r9 的别名,该宏将 thread_info
// 的基地址放在 r9 中,详解见下文
get_thread_info tsk
/*
* Reload the registers that may have been corrupted on entry to
* the syscall assembly (by tracing or context tracking.)
*/
TRACE( ldmia sp, {r0 - r3} )
local_restart:
// tsk 中保存 thread_info 基地址,
// 基地址+偏移值就是访问结构体内成员,
// TI_FLAGS 偏移值对应 thread_info->flags 成员,保存在 r10 中
ldr r10, [tsk, #TI_FLAGS] @ check for syscall tracing
// 将 r4 和 r5 的值保存在栈上,
// 这两个寄存器中保存着系统调用第五个和第六个参数(如果存在)
stmdb sp!, {r4, r5} @ push fifth and sixth args
// tst 指令执行位与运算,并更新状态寄存器,
// 这里用于判断是否在进行系统调用tracing(跟踪),
// 如果处于系统调用跟踪,thread_info->flags 中与
// _TIF_SYSCALL_WORK 对应的位将会被置位
tst r10, #_TIF_SYSCALL_WORK @ are we tracing syscalls?
// thread_info->flags| _TIF_SYSCALL_WORK 的结果不为0,
// 表示处于系统调用 tracing,跳转到 tracing 部分执行,
// 这将走向系统调用的另一个 slow path 分支,
// 关于 tracing 部分不做详细讨论
bne __sys_trace
// 从名称可以看出,这条宏用于执行系统调用,
// 第一个参数是 tbl,表示系统调用表基地址,
// 第二个参数为 scno(r7),第三个参数为 r10,
// 第四个参数为 __ret_fast_syscall(返回程序),
// 注意这里的参数是 invoke_syscall(entry-header.S) 宏的参数,
// 并不是系统调用的参数。 详解见下文
invoke_syscall tbl, scno, r10, __ret_fast_syscall
add r1, sp, #S_OFF
2: cmp scno, #(__ARM_NR_BASE - __NR_SYSCALL_BASE)
eor r0, scno, #__NR_SYSCALL_BASE @ put OS number back
bcs arm_syscall
mov why, #0 @ no longer a real syscall
b sys_ni_syscall @ not private func
#if defined(CONFIG_OABI_COMPAT) || !defined(CONFIG_AEABI)
/*
* We failed to handle a fault trying to access the page
* containing the swi instruction, but we're not really in a
* position to return -EFAULT. Instead, return back to the
* instruction and re-enter the user fault handling path trying
* to page it in. This will likely result in sending SEGV to the
* current task.
*/
9001:
sub lr, saved_pc, #4
str lr, [sp, #S_PC]
get_thread_info tsk
b ret_fast_syscall
#endif
thread_info 中记录了进程中相关的进程信息,包括抢占标志位、对应 CPU 信息、以及一个进程最重要的 task_struct 结构地址等。
每个进程都对应一个用户栈和内核栈,在当前 linux 实现中,内核栈的大小为 8K,占用两个页表,而 thread_info 被存放在栈的顶部,也就是内核栈中的最低地址,内核栈的使用从栈底开始,一直向下增长,当增长过程触及到 thread_info 的区域时,内核栈就检测到溢出,要获取 thread_info 也非常简单,只需要屏蔽当前内核栈 sp 的低 12 位,就得到了 thread_info 的开始地址,达到快速访问的目的,而上面的宏指令 get_thread_info tsk 正是这么做的。
invoke_syscall 宏的源码(arch/arm/kernel/entry-header.S)如下,为了查看方便,将调用参数部分贴在前面方面对照:
.macro invoke_syscall, table, nr, tmp, ret, reload=0
#ifdef CONFIG_CPU_SPECTRE
/* 将系统调用号临时保存在 r10 中 */
mov \tmp, \nr
/* 检查系统调用号是否有效 */
cmp \tmp, #NR_syscalls @ check upper syscall limit
/* 如果系统调用号超过定义的最大值,就改为 0 */
movcs \tmp, #0
/* barrie 指令,防止 CPU 的乱序执行 */
csdb
/*
badr 是一个宏,在这里作用相当于 adr lr,\ret,
也就是把 ret 即 __ret_fast_syscall 的地址保存在 lr 中
*/
badr lr, \ret @ return address
/* reload 默认为 0 ,不执行 */
.if \reload
add r1, sp, #S_R0 + S_OFF @ pointer to regs
ldmiacc r1, {r0 - r6} @ reload r0-r6
stmiacc sp, {r4, r5} @ update stack arguments
.endif
/*
tmp 中保存系统调用号,lsl #2 表示将系统调用号乘以4,
这是因为每个系统调用占用 4 字节,以此作为基于
table(系统调用表) 的偏移地址值,就是相对应的系统调用基地址,
加载到 PC 中,即实现跳转,系统调用函数执行完成后,
将会返回到 lr 中保存的地址处,即上文中赋值给 lr 的
__ret_fast_syscall ,返回值保存在 r0 中。
*/
ldrcc pc, [\table, \tmp, lsl #2] @ call sys_* routine
#else
cmp \nr, #NR_syscalls @ check upper syscall limit
badr lr, \ret @ return address
.if \reload
add r1, sp, #S_R0 + S_OFF @ pointer to regs
ldmiacc r1, {r0 - r6} @ reload r0-r6
stmiacc sp, {r4, r5} @ update stack arguments
.endif
ldrcc pc, [\table, \nr, lsl #2] @ call sys_* routine
#endif
.endm
返回用户空间
系统调用已经执行完成,从上面的源码可以知道,程序返回到了 __ret_fast_syscall 中,接下来查看 __ret_fast_syscall 的源码实现:
/*
* This is the fast syscall return path. We do as little as possible here,
* such as avoiding writing r0 to the stack. We only use this path if we
* have tracing, context tracking and rseq debug disabled - the overheads
* from those features make this path too inefficient.
*/
ret_fast_syscall:
__ret_fast_syscall:
UNWIND(.fnstart )
UNWIND(.cantunwind )
/* 禁止中断 */
disable_irq_notrace @ disable interrupts
/*
将 thread_info->addr_limit 读到 r2 ,
addr_limit 用于界定内核空间和用户空间的访问权限
*/
ldr r2, [tsk, #TI_ADDR_LIMIT]
/*
检查 addr_limit 是否符合规定,
不符合则跳转到 addr_limit_check_failed,
这部分属于安全检查
*/
cmp r2, #TASK_SIZE
blne addr_limit_check_failed
/* 再次检查 thread_info->flags 位与 _TIF_SYSCALL_WORK | _TIF_WORK_MASK */
ldr r1, [tsk, #TI_FLAGS] @ re-check for syscall tracing
tst r1, #_TIF_SYSCALL_WORK | _TIF_WORK_MASK
/*
当 thread_info->flag | _TIF_SYSCALL_WORK | _TIF_WORK_MASK 不为零时,
执行 fast_work_pending
*/
/*
TIF_SYSCALL_WORK | _TIF_WORK_MASK 这两个宏定义
在 arch/arm/include/asm/thread_info.h 中,
包括 tracing 、信号、NEED_RESCHED 的检查,
如果存在未处理的信号或者进程可被抢占时,执行 fast_work_pending ,
否则跳过继续往下执行
*/
bne fast_work_pending
/* perform architecture specific actions before user return */
/* 没有未处理的信号,没有设置抢占标志位 */
/* 架构相关的返回代码,arm 中没有相关代码 */
arch_ret_to_user r1, lr
/* 返回代码 */
restore_user_regs fast = 1, offset = S_OFF
UNWIND(.fnend )
ENDPROC(ret_fast_syscall)
从 __ret_fast_syscall 宏部分分出两个分支,一个是有信号处理或者抢占标志位被置位,需要先行处理,另一个是直接返回,其中直接返回由 restore_user_regs 控制,我们就来看看 fast_work_pending 的分支:
/*
* This is the fast syscall return path. We do as little as possible here,
* such as avoiding writing r0 to the stack. We only use this path if we
* have tracing, context tracking and rseq debug disabled - the overheads
* from those features make this path too inefficient.
*/
ret_fast_syscall:
__ret_fast_syscall:
UNWIND(.fnstart )
UNWIND(.cantunwind )
/* 禁止中断 */
disable_irq_notrace @ disable interrupts
/*
将 thread_info->addr_limit 读到 r2 ,
addr_limit 用于界定内核空间和用户空间的访问权限
*/
ldr r2, [tsk, #TI_ADDR_LIMIT]
/*
检查 addr_limit 是否符合规定,
不符合则跳转到 addr_limit_check_failed,
这部分属于安全检查
*/
cmp r2, #TASK_SIZE
blne addr_limit_check_failed
/* 再次检查 thread_info->flags 位与 _TIF_SYSCALL_WORK | _TIF_WORK_MASK */
ldr r1, [tsk, #TI_FLAGS] @ re-check for syscall tracing
tst r1, #_TIF_SYSCALL_WORK | _TIF_WORK_MASK
/*
当 thread_info->flag | _TIF_SYSCALL_WORK | _TIF_WORK_MASK 不为零时,
执行 fast_work_pending
*/
/*
TIF_SYSCALL_WORK | _TIF_WORK_MASK 这两个宏定义
在 arch/arm/include/asm/thread_info.h 中,
包括 tracing 、信号、NEED_RESCHED 的检查,
如果存在未处理的信号或者进程可被抢占时,执行 fast_work_pending ,
否则跳过继续往下执行
*/
bne fast_work_pending
/* perform architecture specific actions before user return */
/* 没有未处理的信号,没有设置抢占标志位 */
/* 架构相关的返回代码,arm 中没有相关代码 */
arch_ret_to_user r1, lr
/* 返回代码 */
restore_user_regs fast = 1, offset = S_OFF
UNWIND(.fnend )
ENDPROC(ret_fast_syscall)
no_work_pending 中的执行主体就是:
no_work_pending:
asm_trace_hardirqs_on save = 0
/* perform architecture specific actions before user return */
arch_ret_to_user r1, lr
ct_user_enter save = 0
restore_user_regs fast = 0, offset = 0
在上面另一个分支中(没有信号和抢占标志位),最后调用的也是 restore_user_regs,只是参数不一样:
restore_user_regs fast = 1, offset = S_OFF
这是因为在执行 fast_work_pending 的时候已经把 sp 恢复到断点寄存器信息处,如果没有进入 fast_work_pending,需要手动添加一个偏移值即 S_OFF,来定位断点寄存器信息,同时 fast_work_pending 执行过程中原系统调用返回值 r0 已经被保存到栈上,r0 的值已经被污染,而另一个分支中 r0 没有被破坏,所以 restore_user_regs 宏的两个参数有所区别。
restore_user_regs 宏的执行就是真正地返回断点部分,参考下面的源代码(arch/arm/kernel/entry-header.S):
.macro restore_user_regs, fast = 0, offset = 0
/* 设置内存访问权限 */
uaccess_enable r1, isb=0
#ifndef CONFIG_THUMB2_KERNEL
@ ARM mode restore
/* 将当前 sp 保存到 r2 中 */
mov r2, sp
/* 将保存在栈上的 CPSR 寄存器值取出,保存到 r1 中 */
ldr r1, [r2, #\offset + S_PSR] @ get calling cpsr @ r1保存了pt_regs中的spsr,也就是发生中断时的CPSR
/* 将保存在栈上的 PC 寄存器值取出,保存到 lr 中 */
ldr lr, [r2, #\offset + S_PC]! @ get pc @ lr保存了PC值,同时sp移动到了pt_regs中PC的位置
/*
判断原进程中 CPSR 的 irq 位是否被置位,
如果置位,跳转到 1 处执行,表示出错
*/
tst r1, #PSR_I_BIT | 0x0f
bne 1f
/* 将用户进程的 CPSR 复制到 SPSR_SVC 中 */
msr spsr_cxsf, r1 @ save in spsr_svc @ 赋值给spsr,进行返回用户空间的准备
#if defined(CONFIG_CPU_V6) || defined(CONFIG_CPU_32v6K)
@ We must avoid clrex due to Cortex-A15 erratum #830321
strex r1, r2, [r2] @ clear the exclusive monitor
#endif
/*
将 r2(sp) 中保存的用户进程的 r1~lr push
回用户进程下的寄存器中(^ 表示操作的是用户进程),
r0 ~ r12 是共用的寄存器,r0 中保存了系统调用返回值,
不需要返回到断点 r0
*/
.if \fast
ldmdb r2, {r1 - lr}^ @ get calling r1 - lr
.else
/* 如果执行的是 fast_work_pending 分支,r0 是保存在栈上的,也需要一并重新加载 */
ldmdb r2, {r0 - lr}^ @ get calling r0 - lr @ 将保存在内核栈上的数据保存到用户态的r0~r14寄存器
.endif
mov r0, r0 @ ARMv5T and earlier require a nop @ NOP操作,ARMv5T之前的需要这个操作
@ after ldm {}^
add sp, sp, #\offset + PT_REGS_SIZE @ 现场已经恢复,移动svc mode的sp到原来的位置
movs pc, lr @ return & move spsr_svc into cpsr @ 返回用户空间
1: bug "Returning to usermode but unexpected PSR bits set?", \@
#elif defined(CONFIG_CPU_V7M)
@ V7M restore.
@ Note that we don't need to do clrex here as clearing the local
@ monitor is part of the exception entry and exit sequence.
.if \offset
add sp, #\offset
.endif
v7m_exception_slow_exit ret_r0 = \fast
#else
@ Thumb mode restore
mov r2, sp
load_user_sp_lr r2, r3, \offset + S_SP @ calling sp, lr
ldr r1, [sp, #\offset + S_PSR] @ get calling cpsr
ldr lr, [sp, #\offset + S_PC] @ get pc
add sp, sp, #\offset + S_SP
tst r1, #PSR_I_BIT | 0x0f
bne 1f
msr spsr_cxsf, r1 @ save in spsr_svc
@ We must avoid clrex due to Cortex-A15 erratum #830321
strex r1, r2, [sp] @ clear the exclusive monitor
.if \fast
ldmdb sp, {r1 - r12} @ get calling r1 - r12
.else
ldmdb sp, {r0 - r12} @ get calling r0 - r12
.endif
add sp, sp, #PT_REGS_SIZE - S_SP
/*
lr 中保存的是用户进程的原 pc 值,
执行这条指令就返回到用户空间执行了,
同时 movs 的后缀 s 对应的操作为将 SPSR_SVC
拷贝到 USER 模式下的 CPSR 中
*/
movs pc, lr @ return & move spsr_svc into cpsr
1: bug "Returning to usermode but unexpected PSR bits set?", \@
#endif /* !CONFIG_THUMB2_KERNEL */
.endm
整个代码比较简单,就是用进入系统调用时候压入内核栈的值来进行用户现场的恢复,其中一个细节是内核栈的操作,在调用movs pc, lr 返回用户空间现场之前,add sp, sp, #\offset + S_FRAME_SIZE指令确保用户栈上是空的。此外,我们需要考虑返回用户空间时候的r0设置问题,毕竟它承载了本次系统调用的返回值,这时候的r0有两种情况:
(1)在没有pending work的情况下(fast等于1),r0保存了sys_xxx函数的返回值
(2)在有pending work的情况下(fast等于0),struct pt_regs(返回用户空间的现场)中的r0保存了sys_xxx函数的返回值restore_user_regs还有一个参数叫做offset,我们知道,在进入系统调用的时候,我们把参数5和参数6压入栈上,因此产生了到pt_regs 8个字节的偏移,这里需要补偿回来。
恢复断点和保存断点的操作是相反的,将栈上保存的 r0~r14 寄存器值一个个拷贝回用户空间的 r0~r14,然后恢复用户进程中的 CPSR 寄存器,再更新 PC,跳转到用户空间,即完成了程序的返回。