redis-数据结构、io
1.redis 数据结构
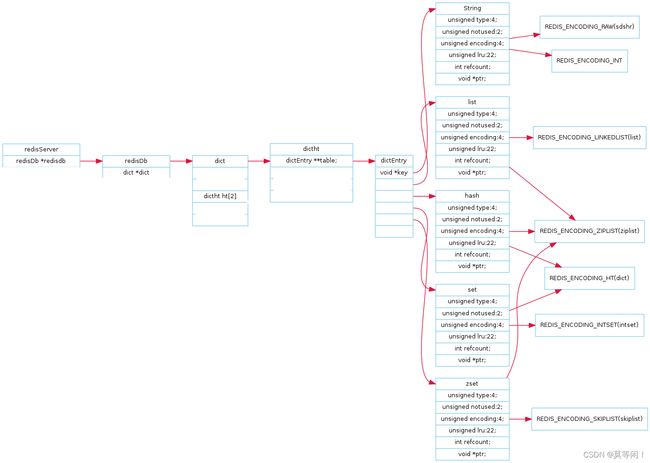
1.1 字典 kv是什么
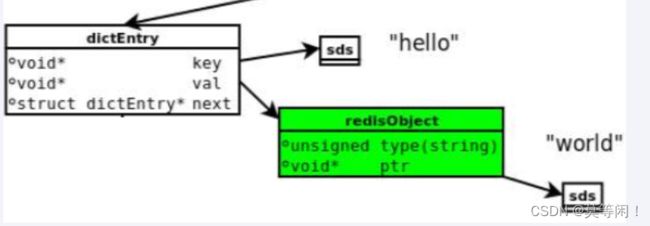
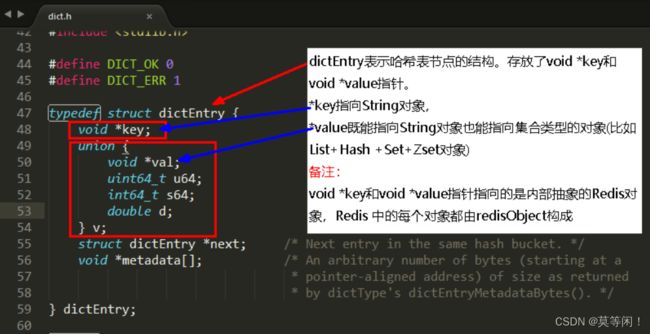
每个键值对都会是一个dictEntry
·set hello word为例,因为Redis是KV键值对的数据库,每个键值对都会有一个dictEntry(源码位置:dict.h)
简单描述 加载原理
server 启动,加载redisdb进内存形成数据库,形成数据库后,马上读取dict 字典。
形成dict 字典后,读取dictht ht[2] 哈希表 ,里面有dictentry 数组, 数组里面每个都是dictentry对象
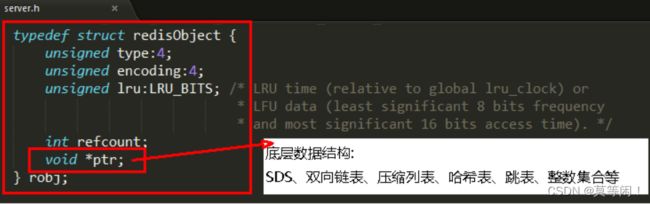
1.1.2 redisObject 作用
为了便于操作,redis 采用redisobject结构体来统一五种不同的数据类型。这样可以方便在函数之间传递。

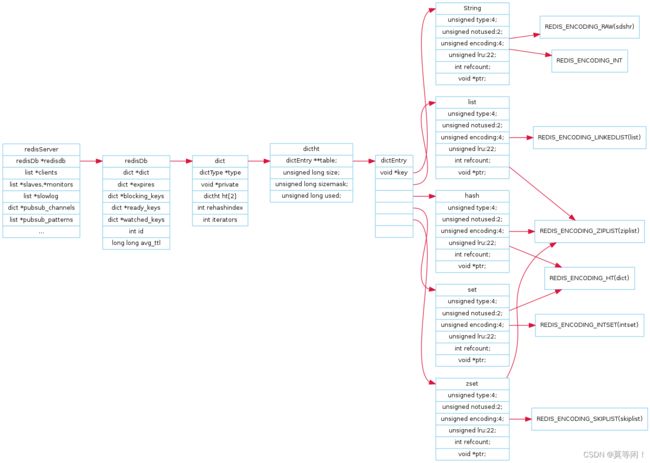
1.2 redis 数据结构
redis6
- String
- SDS (int raw embstr)
- set
- intset + hashtable(dict)
- hash
- hahshtable dict + ziplist
- list
- 3.2 后quicklist、3.2前 ziplist(<=512 <=64Byte) 超过 linkedlist
- sortedset
- skiplist + ziplist
2. 5大底层
2.1 sds
int
embstr 小于44字节
raw
| C 字符串 | sds |
|---|---|
| 获取字符串长度的复杂度为 O(N) 。 | 获取字符串长度的复杂度为 O(1) 。 |
| API 是不安全的,可能会造成缓冲区溢出。 | API 是安全的,不会造成缓冲区溢出。 |
| 修改字符串长度 N 次必然需要执行 N 次内存重分配。 | 修改字符串长度 N 次最多需要执行 N 次内存重分配。 内存预先分配 |
| 二进制不安全 只能存储文本字符串 | 二进制安全 可以保存文本或者二进制数据。 |
非二进制安全 指的是在 字符串内容中 存在 结束标识符,那么读取到一半就以为结束了。 |
- 空间分配
- 新的字符串小于1m,新空间为,新的字符串长度*2+1
- 新的字符串大于1m,新空间为 ,新的字符串长度+1m+1; 称为内存预分配
- 空间释放
- SDS 缩短时并不会回收多余的内存空间,而是使用
free 字段将多出来的空间记录下来。如果后续有变更操作,直接使用 free 中记录的空间,减少了内存的分配。
- SDS 缩短时并不会回收多余的内存空间,而是使用

//lsb 代表有效位的意思,
//__attribute__ ((__packed__)) 代表structure 采用手动对齐的方式。
struct __attribute__ ((__packed__)) sdshdr8 {
//buf 已经使用的长度
uint8_t len; /* used */
//buf 分配的长度,等于buf[]的总长度-1,因为buf有包括一个/0的结束符
uint8_t alloc;
/* excluding the header and null terminator */
//只有3位有效位,因为类型的表示就是0到4,所有这个8位的flags
// 有5位没有被用到
unsigned char flags; /* 3 lsb of type, 5 unused bits */
//实际的字符串存在这里
char buf[];
Redis中字符串的实现,SDS有多种结构(sds.h):
sdshdr5、(2^5=32byte)
sdshdr8、(2 ^ 8=256byte)
sdshdr16、(2 ^ 16=65536byte=64KB)
sdshdr32、 (2 ^ 32byte=4GB)
sdshdr64,2的64次方byte=17179869184G用于存储不同的长度的字符串。
len 表示 SDS 的长度,使我们在获取字符串长度的时候可以在 O(1)情况下拿到,而不是像 C 那样需要遍历一遍字符串。
alloc 可以用来计算 free 就是字符串已经分配的未使用的空间,有了这个值就可以引入预分配空间的算法了,而不用去考虑内存分配的问题。
buf 表示字符串数组,真存数据的
2.2 string
| 1 int | Long类型整数时,RedisObject中的·ptr指针直接赋值为整数数据·,·不再额外的指针再指向整数了·,节省了指针的空间开销。 |
| 2 embstr | 当保存的是字符串数据且字符串小于等于44字节时,embstr类型将会调用内存分配函数,只分配一块连续的内存空间,空间中依次包含 redisObject 与 sdshdr 两个数据结构,让元数据、指针和SDS是一块连续的内存区域,这样就可以避免内存碎片 |
| 3 raw | 当字符串大于44字节时,SDS的数据量变多变大了,SDS和RedisObject布局分家各自过,会给SDS分配多的空间并用指针指向SDS结构,raw 类型将会调用两次内存分配函数,分配两块内存空间,一块用于包含 redisObject结构,而另一块用于包含 sdshdr 结构 |
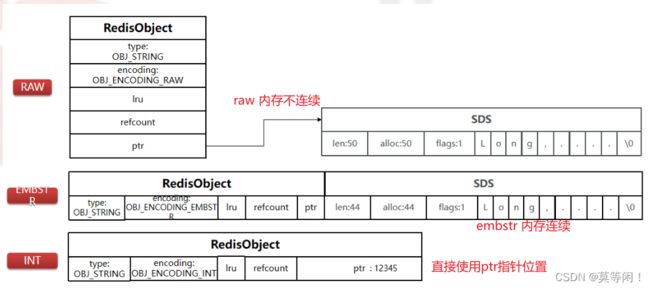
2.2.1 没有超过44b,也是raw

2.3 intset 唯一、有序
小总结:
Intset可以看做是特殊的整数数组,具备一些特点:
- Redis会确保Intset中的元素
唯一、有序 - 具备类型升级机制(倒序拷贝数组元素),可以节省内存空间
- 底层采用二分查找方式来查询

encoding 决定 contents 数组内 数字的范围
升序 保存元素

现在,数组中每个数字都在int16_t的范围内,因此采用的编码方式是INTSET_ENC_INT16,每部分占用的字节大小为:
- encoding:4字节
- length:4字节
- contents:2字节 * 3 = 6字节 (每个长度占用2个字节,方便inset 基于数组角标,快速访问数组的元素)
contents 地址是 数组的 第一个元素的位置,
inset 升级

倒序拷贝原数组的元素
数字20 拷贝到 8-12
10 拷贝到 4-8
5 拷贝到 1-4

最后添加 50000 到数组末尾12 -16

我们向该其中添加一个数字:50000,这个数字超出了int16_t的范围,intset会自动升级编码方式到合适的大小。
以当前案例来说流程如下:
升级编码为INTSET_ENC_INT32, 每个整数占4字节,并按照新的编码方式及元素个数扩容数组倒序依次将数组中的元素拷贝到扩容后的正确位置- 将待添加的元素放入数组末尾
- 最后,将inset的encoding属性改为INTSET_ENC_INT32,将length属性改为4
2.4 字典 dict
dict 三部分组成 dict、dicthashtable(哈希表 数组) 、dictentry
小总结:
Dict的结构:
- 类似java的HashTable,底层是数组加链表来解决哈希冲突
- Dict包含两个哈希表,ht[0]平常用,ht[1]用来rehash
Dict的伸缩:
- 当LoadFactor大于5或者LoadFactor大于1并且没有子进程任务时,Dict扩容
- 当LoadFactor小于0.1时,Dict收缩
- 扩容大小为第一个大于等于used + 1的2^n
- 收缩大小为第一个大于等于used 的2^n
- Dict采用
渐进式rehash,每次访问Dict时执行一次rehash - rehash时ht[0]只减不增,新增操作只在ht[1]执行,其它操作在两个哈希表
字典dict 类型


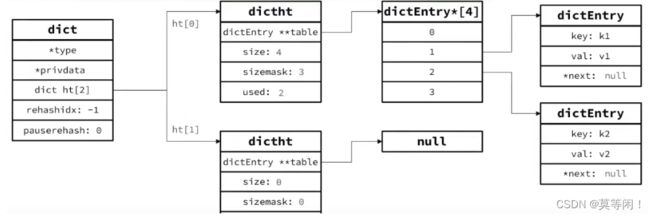
2.4.1 dict的 扩缩容 的条件
dict扩容条件
元素过多,导致hash冲突,链表太长,查询效率降低。
used sieze 在dictht 结构体中
dict 在每次新增键值对 k v的时候 ,会判断负载因子(LoadFactor=used/size) ,满足以下下条件触发扩容:
- 负载因子大于等于1,并且后台没有执行BGSAVE或者BGREWRITE等命令。
- 负载因子>5 也需要扩容。
扩容大小为 used+1 的2^n次
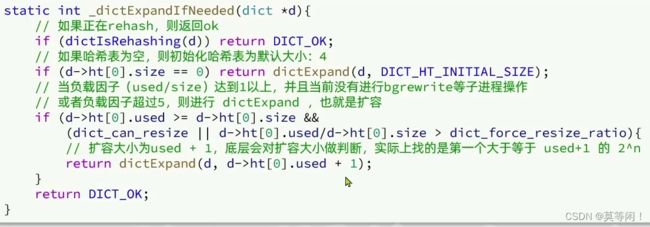
dict 收缩的条件
每次删除元素的时候,会检查负载因子,当LoadFactor<0.1时候,会做hashtable 收缩。
但是需要大于 hashtable 初始化大小 4 ,收缩小于4,那么重置为hashtable 最小值 4.
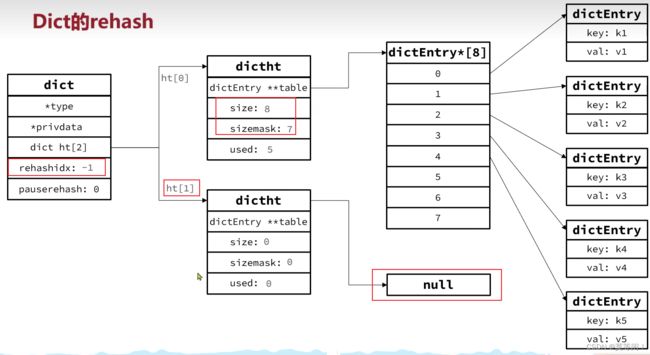
2.4.2 dict 的扩容 过程
dict 的rehash的过程 渐进式hash
rehash:因为进行 扩容或者缩容, 导致hashtable 的size 和sizemask变化,而key 的查询根据sizemask。·需要对每一个 旧的hashtable中的key进行重新计算索引,插入新的hashtable,这个过程称为rehash。
-
计算新的hash表的 realsize,取决于当前扩容还是缩容
- 扩容,realsize 是 第一个大于等于used+1的 2^n的数。
- 缩容 realsize 是第一个大于等于 used的 2^n 的数 但是不得小于4
-
根据realsize大小,申请新的hash表,赋值给dict.ht[1]
-
设置 dict.rehashindex=0,表示开始rehash
4.讲dict.ht[0] 中的每个entry 转移到 dict.ht[1] -
·
每次新增、查询、修改、添加 元素,都检查一下 dict.rehashindex 是否大于 -1,如果大于-1,就将dict.ht[0].table[rehashindex] entry链表 rehash 到dict.ht[1] 中,并且rehashindex++,最后知道dict.ht[0]的元素都迁移到dict.ht[1]中 -
讲dict.ht[1] 赋值给 dict.ht[0],dict.ht[1]为空,释放原来旧的dict.ht[0]的内存
-
·
讲rehashindex 置为-1, 表示rehash结束。 -
修改、查询、删除的操作,都会在dict.ht[0]和dict.ht[1] 中执行。新增 直接添加到dict.ht[1]中
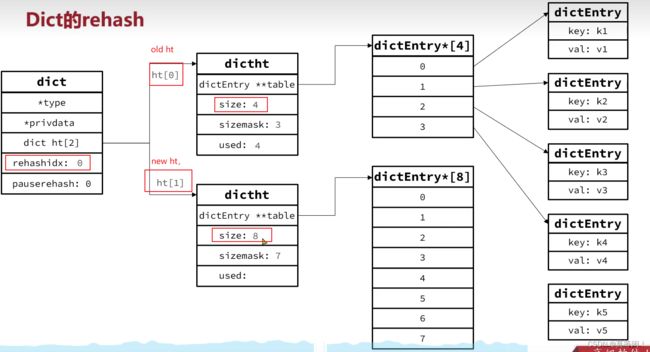
rehash 后
2.5 ziplist
dict 内部使用大量指针(8Byte),内存不连续,容易产生内存碎片。内存浪费。
引入ziplist
ziplist 是特殊的"双端链表",是特殊编码的连续内存块组成。任意一端可以进行压入/弹出。时间复杂度为0(1);
小总结:
ZipList特性:
- 压缩列表的可以看做一种连续内存空间的"双向链表"
- 列表的节点之间不是通过指针连接,而是记录上一节点和本节点长度来寻址,内存占用较低
- 如果列表数据过多,导致链表过长,可能影响查询性能
- 增或删较大数据时有可能发生连续更新问题
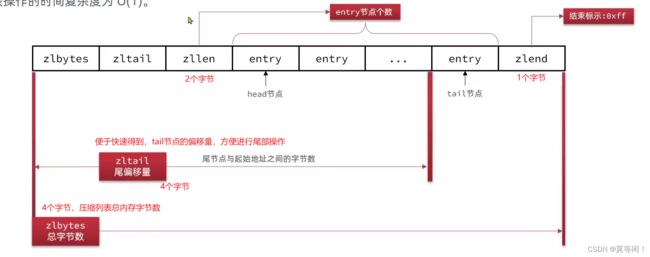
2.5.1 ziplist entry

-
previous_entry_length:·
前一节点的长度,占1个或5个字节。- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
- 如果前一节点的长度大于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后
四个字节才是真实长度数据
-
encoding:编码属性,
记录content的数据类型(字符串还是整数)以及长度,占用1个、2个或5个字节 -
contents:负责保存节点的数据,可以是字符串或整数
-
正向遍历
- previous 块字节长度 + encoding 块字节长度 + encoding 中获取 content字节长度 就是 当前entry 的总字节长度。
- 所以只需要 当前entry首地址 + entry 总长度就可以获得下一个entry 首地址
-
反向遍历
- 当前entry 首地址,- previous 中 上个entry 占用字节数,相减就可以得到。
ZipList中所有·存储长度的数值均采用``小端字节序,即低位字节在前,高位字节在后。例如:数值0x1234,采用小端字节序后实际存储值为:0x3412
2.5.2 encoding
Encoding编码
ZipListEntry中的encoding编码分为字符串和整数两种:
字符串:如果encoding是以“00”、“01”或者“10”开头,则证明content是字符串
| 编码 | 编码长度 | 字符串大小 |
|---|---|---|
| |00pppppp| | 1 bytes | <= 63 bytes |
| |01pppppp|qqqqqqqq| | 2 bytes | <= 16383 bytes |
| |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| | 5 bytes | <= 4294967295 bytes |
例如,我们要保存字符串:“ab”和 “bc”


ZipListEntry中的encoding编码分为字符串和整数两种:
- 整数:如果encoding是以“11”开始,则证明content是整数,且encoding固定只占用1个字节
2.5.3 ziplist 连锁更新问题
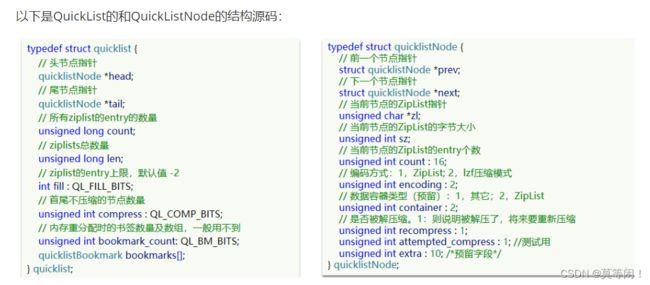
2.6 quicklist
总结:
QuickList的特点:
- 是一个
节点为ZipList的双端链表 - 节点采用
ZipList,解决了传统链表的内存占用问题(传统链表采用指针占用内存) - 控制了ZipList大小,
解决连续内存空间申请效率问题() - 中间节点可以压缩,进一步节省了内存
一句话: qiucklist 采用linkedlist+ziplist,可以双端访问,内存占用较低相对于链表,包含多个ziplist,存储上限高。

ziplist 连续内存空间太大,不在好分配。
引入quicklist
问题1:ZipList虽然节省内存,但申请内存必须是连续空间,如果内存占用较多,申请内存效率很低。怎么办?
答:为了缓解这个问题,我们必须限制ZipList的长度和entry大小。
问题2:但是我们要存储大量数据,超出了ZipList最佳的上限该怎么办?
答:我们可以创建多个ZipList来分片存储数据。
问题3:数据拆分后比较分散,不方便管理和查找,这多个ZipList如何建立联系?
答:Redis在3.2版本引入了新的数据结构QuickList,它是一个双端链表,只不过链表中的每个节点都是一个ZipList。

2.6.1 限制quicklist 中每个ziplist中的 entry 大小
list-max-ziplist-size
为了避免QuickList中的每个ZipList中entry过多,Redis提供了一个配置项:list-max-ziplist-size来限制。
如果值为正,则代表ZipList的允许的entry个数的最大值
如果值为负,则代表ZipList的最大内存大小,分5种情况:
- -1:每个ZipList的内存占用不能超过4kb
- -2:每个ZipList的内存占用不能超过8kb
默认值 - -3:每个ZipList的内存占用不能超过16kb
- -4:每个ZipList的内存占用不能超过32kb
- -5:每个ZipList的内存占用不能超过64kb
2.6.2 quicklist 对ziplist 压缩


2.7 skiplist 升序
可以从中间随机查询
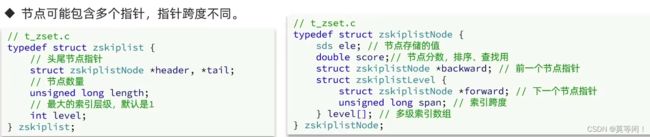
Skiplist 特点
- 元素升序排列存储
- 节点可以包含多个指针,跨度不同
总结
- 跳表是一个双向链表,每个节点有 score(排序查找用) 和ele值 (存储的值)
- 节点根据score 升序排序,score一样,采用ele 排序
- 每个节点 包含多个层,level[],最多32层
- 不同层,指向下一个节点的跨度不同。

3 redis 内部结构
| 数据类型 | 编码方式 |
|---|---|
| OBJ_STRING | int、embstr、raw |
| OBJ_LIST | LinkedList和ZipList(3.2以前)、QuickList(3.2以后) |
| OBJ_SET | intset、HT |
| OBJ_ZSET | ZipList、HT、SkipList |
| OBJ_HASH | ZipList、HT |
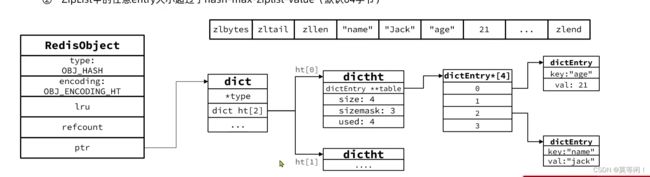
3.1 hash
hash-max-ziplist-entries: 默认 512个field 使用压缩列表保存时哈希集合中的最大元素个数。
hash-max-ziplist-value:默认64byte 使用压缩列表保存时哈希集合中单个元素的最大长度。
当数据量较大时,ZIPLIST编码会转为HT编码,也就是Dict,触发条件有两个:
- ZipList中的元素数量超过了hash-max-ziplist-entries(默认512)
- ZipList中的任意entry大小超过了hash-max-ziplist-value(默认64字节)
3.2 set
底层采用 intset ht 的数据结构
为了查询效率和唯一性,set采用HT编码(Dict)。Dict中的key用来存储元素,value统一为null。
当存储的所有数据都是整数,并且元素数量不超过set-max-intset-entries(512)时,Set会采用IntSet编码,以节省内存·
当intset集合元素超出set-max-intset-entries(512)时候,采用ht.


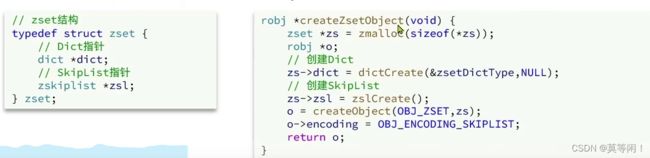
3.3 zset
- 可以根据member 排序
- member必须唯一
- 可以根据member 查询分数
根据键值 存储 、唯一 、排序 ( intset 升序排列,skiplist 根据score 升序)
skiplist 可以排序,并且可以同时 存储score 和 ele 值(member)满足键值存储,可排序- dict 键值存储,根据key 找value 满足 键值存储,唯一
所以 zset 采用 skiplist + dict
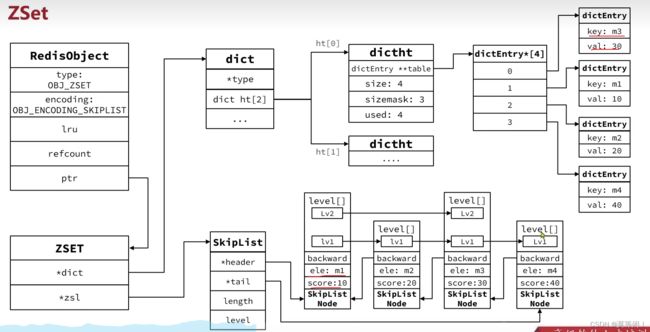
3.3.1 zset ziplist
当元素不多的时候,dict和skiplist的优势不明显,反而浪费内存。因此zset 还会采用ziplist的结构来节省内存。不过需要满足条件。
- 元素数量小于zset-max-ziplist-entries 128
- 每个元素的都小于 zset-max-ziplist-value 64
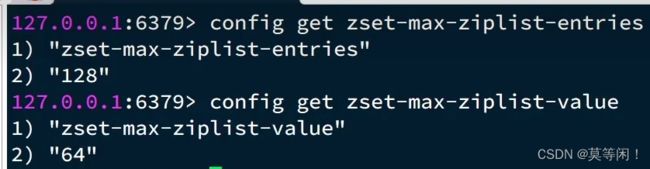
添加元素的时候,会判断 数量 <=128 && entry大小 <64 采用ziplist
否则 转为 dict+skiplist
·ziplist本身没有排序功能,而且没有键值对的概念,因此需要有zset通过编码实现:
- ZipList是连续内存,因此score和element是紧挨在一起的两个entry, ··
element在前,score在后 - score越小越接近队首,score越大越接近队尾,按照score值升序排列

4. redis 网络io模型
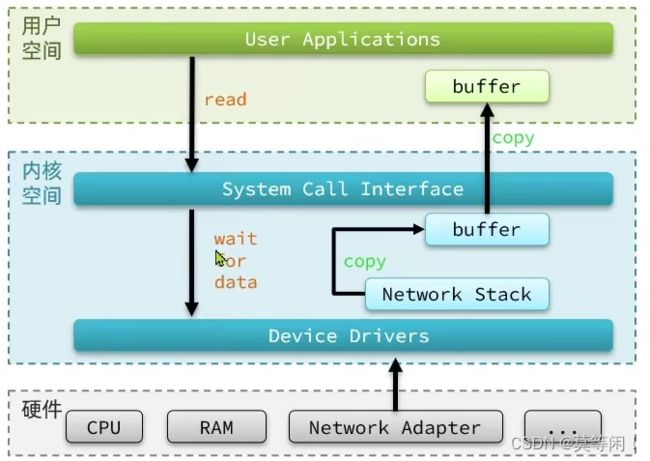
4.1 用户空间、内核空间
Linux系统为了提高IO效率,会在用户空间和内核空间都加入缓冲区:
-
写数据时,要把用户
缓冲数据拷贝到内核缓冲区,然后写入设备 -
读数据时,要从
设备读取数据到内核缓冲区,然后拷贝到用户缓冲区
4.2 阻塞io
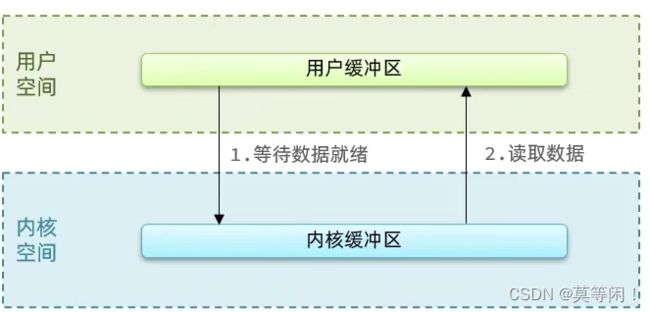
阻塞io 两个阶段都必须阻塞等待。
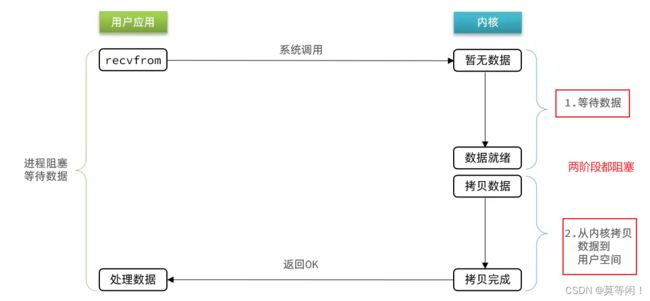
4.3 非阻塞io
recvfrom 操作 立即返回结果而不是阻塞用户进程

可以看到,非阻塞IO模型中,用户进程在第一个阶段是非阻塞,第二个阶段是阻塞状态。虽然是非阻塞,但性能并没有得到提高。而且忙等机制会导致CPU空转,CPU使用率暴增。
4.4 io多路复用
就是一种机制,通过一个进程可以监听多个文件描述符,一旦某个描述符就绪,能够通知程序进行相应的读写操作。
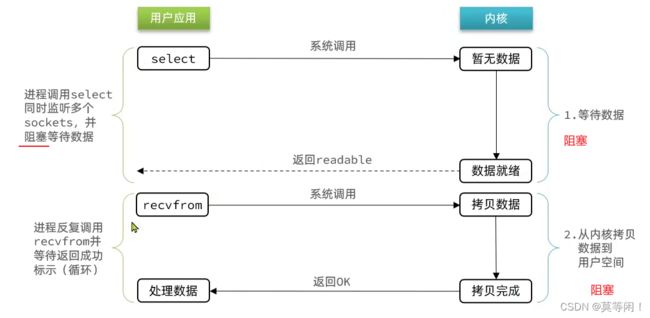
阻塞io 两个步骤也是阻塞的,io多路复用两个步骤也是阻塞的有什么差别??
阻塞io 调用recvfrom产生的阻塞,但是recvfrom 只能监听一个fd。
select 模式,一次性监听多个fd,只要有一个就绪,就可以处理。
4.4.1 select
// 定义类型别名 __fd_mask,本质是 long int
typedef long int __fd_mask;
/* fd_set 记录要监听的fd集合,及其对应状态 */
typedef struct {
// fds_bits是long类型数组,长度为 1024/32 = 32
// 共1024个bit位,每个bit位代表一个fd,0代表未就绪,1代表就绪 ,32*32=1024
// 按比特位 存 fd 1024个
__fd_mask fds_bits[__FD_SETSIZE / __NFDBITS]; // 数组长度32 每个元素32位
// ...
} fd_set;
// select函数,用于监听fd_set,也就是多个fd的集合
// 返回值,有几个就绪的fd
int select(
int nfds, // 要监视的fd_set的最大fd + 1
fd_set *readfds, // 要监听读事件的fd集合 请求的fd
fd_set *writefds,// 要监听写事件的fd集合 响应的fd
fd_set *exceptfds, // // 要监听异常事件的fd集合
// 超时时间,null-用不超时;0-不阻塞等待;大于0-固定等待时间
struct timeval *timeout
);

过程
比如要监听的数据,是1,2,5三个数据,此时会执行select函数,然后将整个fd发给内核态,内核态会去遍历用户态传递过来的数据,如果发现这里边都数据都没有就绪,就休眠,直到有数据准备好时,就会被唤醒,唤醒之后,再次遍历一遍,看看谁准备好了,然后再将处理掉没有准备好的数据,最后再将这个FD集合写回到用户态中去,此时用户态就知道了,奥,有人准备好了,但是对于用户态而言,并不知道谁处理好了,所以用户态也需要去进行遍历,然后找到对应准备好数据的节点,再去发起读请求,我们会发现,这种模式下他虽然比阻塞IO和非阻塞IO好,但是依然有些麻烦的事情, 比如说频繁的传递fd集合,频繁的去遍历FD等问题
select 问题
- 需要将整个fd_set 从用户态拷贝到内核态,select 结束,还要再次拷贝回用户空间。(发生两次数据拷贝)
- select 无法知道那个fd就绪,需要遍历整个fd。
- fd_set 监听的fd数量不能超过1024个。fd 是长度位1024的数组
4.4.2 poll
解决了fd 1024上下问题。其他两个问题没有解决。
poll模式对select模式做了简单改进,但性能提升不明显,部分关键代码如下:
IO流程:
- 创建pollfd数组,向其中添加关注的fd信息,数组大小自定义
- 调用poll函数,将pollfd数组拷贝到内核空间,
转链表存储,无上限 内核遍历fd,判断是否就绪- 数据就绪或超时后,拷贝pollfd数组到用户空间,
返回就绪fd数量n - 用户进程判断n是否大于0,大于0则遍历pollfd数组,找到就绪的fd
与select对比:
select模式中的fd_set大小固定为1024,而pollfd在内核中采用链表,理论上无上限监听FD越多,每次遍历消耗时间也越久·,性能反而会下降

4.4.3 epoll
提供了3个函数
- epoll_create(int size)

- epoll_ctl(int epfd ,int op, int fd ,struct epoll_event *event)

callback触发时,添加到rd list 中 - epoll_wait( int epfd,struct epoll_event *events,int maxevents ,int timeout)


第一个是:eventpoll的函数,他内部包含两个东西
一个是:
1、红黑树-> 记录的事要监听的FD
2、一个是链表-> 一个链表,记录的是就绪的FD
紧接着调用epoll_ctl操作,将要监听的数据添加到红黑树上去,并且给每个fd设置一个监听函数,这个函数会在fd数据就绪时触发,就是准备好了,现在就把fd把数据添加到list_head中去
3、调用epoll_wait函数
就去等待,·在用户态创建一个空的events数组,当就绪之后,我们的回调函数会把数据添加到list_head中去,当调用这个函数的时候,会去检查list_head,当然这个过程需要参考配置的等待时间,可以等一定时间,也可以一直等, 如果在此过程中,检查到了list_head中有数据会将数据添加到链表中,此时将数据放入到events数组中,并且返回对应的操作的数量,用户态的此时收到响应后,从events中拿到对应准备好的数据的节点,再去调用方法去拿数据。
4.4.5 3种总结
小总结:
select模式存在的三个问题:
- 能监听的
FD最大不超过1024 每次select都需要把所有要监听的FD都拷贝到内核空间- 每次都要
遍历所有FD来判断就绪状态
poll模式的问题:
poll利用链表解决了select中监听FD上限的问题,但依然要遍历所有FD,如果监听较多,性能会下降
epoll模式中如何解决这些问题的?
- 基于
epoll实例中的红黑树保存要监听的FD,理论上无上限,而且增删改查效率都非常高 每个FD只需要执行一次epoll_ctl添加到红黑树,以后每次epol_wait无需传递任何参数,无需重复拷贝FD到内核空间- 1
利用ep_poll_callback机制来监听FD状态,无需遍历所有FD,因此性能不会随监听的FD数量增多而下降
4.5 epoll 触发方式
边缘触发 减少epoll_wait() 调用次数,提高程序效率
水平触发:
- 当fd 有数据可读时候,
会重复通知,知道数据处理完成为止。epoll 默认模式/
边缘触发:
- 当fd数据可读时,只会通知一次,不管数据是否读取完成。
举个栗子:
- 假设一个客户端socket对应的FD已经注册到了epoll实例中
- 客户端socket发送了2kb的数据
- 服务端调用epoll_wait,得到通知说FD就绪
- 服务端从FD读取了1kb数据
- 回到步骤3(再次调用epoll_wait,形成循环)
结果:
如果我们采用LT模式,因为FD中仍有1kb数据,则第⑤步依然会返回结果,并且得到通知
如果我们采用ET模式,因为第③步已经消费了FD可读事件,第⑤步FD状态没有变化,因此epoll_wait不会返回,数据无法读取,客户端响应超时。

et 模式,在读取的时候,在一次通知中,为了一次读取完所有数据。可以使用非阻塞io,没数据了就返回。阻塞io没数据回阻塞。
5. redis 多线程处理io
Redis 6.0版本中引入了多线程,目的是为了提高IO读写效率。因此在解析客户端命令、写响应结果时采用了多线程。核心的命令执行、IO多路复用模块依然是由主线程执行。
命令 解析 、解析请求当中的命令。
写响应结果
这两处采用多线程。

6 过期删除策略
** 周期删除模式**
SLOW模式规则:
- 执行频率受server.hz影响,默认为10,即每秒执行10次,每个执行周期100ms。
- 执行清理耗时不超过一次执行周期的25%.默认slow模式耗时不超过25ms
步骤: - 逐个遍历db,逐个遍历db中的bucket,抽取20个key判断是否过期(过期就删除,并统计全局过期的key,和所有的key)
- 如果没达到时间上限(25ms)并且过期key(全局中,过期的key占总的key)比例大于10%,再进行一次抽样,否则结束
FAST模式规则(过期key比例小于10%不执行 ):
- 执行频率受beforeSleep()调用频率影响,但两次FAST模式间隔不低于2ms
- 执行清理耗时不超过1ms
步骤 - 逐个遍历db,逐个遍历db中的bucket,抽取20个key判断是否过期
如果没达到时间上限(1ms)并且过期key比例大于10%,再进行一次抽样,否则结束