Linux下Hadoop2.8.2集群搭建(持续完善中)
------------本文是博主原创,如内容有问题,请予以指正,谢谢。-------------
文档的目的在于个人总结并分享给需要的人。目标是在生产环境能够快速搭建hadoop分布式集群。
第一、环境:
1、两台虚拟机
ip分比为172.16.222.184(master)、172.16.222.186(slave)
2、linux操作系统:Redhat 6.4
1、2操作参考《利用虚拟机快速搭建N个分布式计算节点服务器》
3、JDK1.8
JDK的安装参考《Linux下安装JDK的步骤》
4、Hadoop版本:hadoop2.8.2
5、root用户下操作
第二、Hadoop分布式集群搭建
第一步、修改hostname
1、修改network,新增配置hostname=HadoopMaster,使之永久有效
vim /etc/sysconfig/network

2、执行hostname HadoopMaster ,使之立即有效
hostname HadoopMaster
3、同样方式修改186的network,新增hostname=HadoopNodeA
第二步、host配置
目的是建立hostname和ip之间的映射。集群包含两台虚拟机,一个作为master,一台作为slave。我们把184作为master,186作为slave
1、使用ssh登录作为master的虚拟机系统。
2、修改hosts文件,把集群所有节点的配置都配置在这个文件中。
vim /etc/hosts
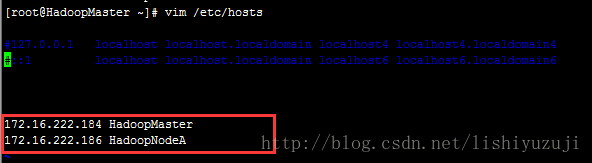
3、其他所有节点也都按照这样的方式配置
第三步、配置Master无密码登录其他slave
1、在master(184)节点上执行下面的命令生成无密码密钥对
ssh-keygen –t rsa –P ''
生成的密钥会在用户的.ssh目录下,root用户在/root/.ssh下,其他用户在/home/用户名/.ssh下
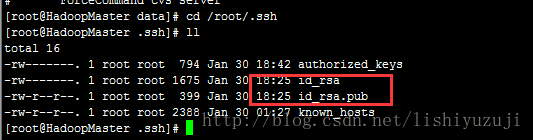
2、 把id_rsa.pub追加到授权的key里面去
cat id_rsa.pub >> authorized_keys
3、启用ssh无密钥登录
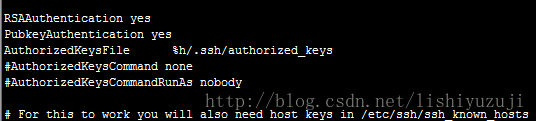
使用root用户操作 vim /etc/ssh/sshd_config 取消一下几行的注释
RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile %h/.ssh/authorized_keys # 公钥文件路径
4、重启ssh服务
service sshd restart
5、把公钥复制到其他所有slave上(这里是186)
ssh-copy-id root@HadoopNodeA(root是用户名,HadoopNodeA是其中一个节点的hostname)
6、测试无密码登录是否成功
在HadoopMaster节点上执行ssh root@HadoopNodeA(root是用户名,HadoopNodeA是其中一个节点的hostname)
看看是否登录成功。
第四步、Hadoop的安装与环境变量配置配置
1、创建文件目录
为了统一管理和配置hdfs路径,在Master及其他节点下新建如下目录(必须保持目录一直)
/data/hdfs/name
/data/hdfs/data
/data/hdfs/tmp
2、把准备好的Hadoop安装包通过ftp上传到/data路径下
3、解压Hadoop2.8.2安装包到/data路径
tar -xzvf hadoop-2.8.2

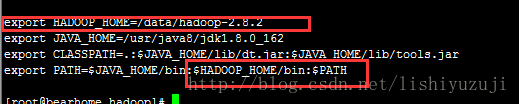
4、hadoop环境变量配置
vim /etc/profile
增加 export hadoop_home=/data/hadoop-2.8.2
路径是hadoop的安装路径
5、source /etc/profile使文件生效
第五步、Hadoop配置文件配置
1、core-site配置
vim /data/hadoop-2.8.2/etc/hadoop/core-site.xml
在configuration节点下新增如下配置
2、hdfs-site.xml配置
vim /data/hadoop-2.8.2/etc/hadoop/hdfs-site.xml
在configuration节点下新增如下配置
3、mapred-site.xml配置
vim /data/hadoop-2.8.2/etc/hadoop/mapred-site.xml
在configuration节点下新增如下配置
4、yarn-site.xml配置
vim /data/hadoop-2.8.2/etc/hadoop/yarn-site.xml
在configuration节点下新增如下配置,其中HadoopMaster是184的hostname
5、slave配置
vim /data/hadoop-2.8.2/etc/hadoop/slave
把作为hdfs节点的hostname配置到里面,每个hostname占一行,这里我们把184既作为主节点也作为子节点

6、将以上HadoopMaster下配置好的整个Hadoop-2.8.2文件夹拷贝到其他所有节点的同样目录
第六步、运行Hadoop
1、格式化Namenode
hadoop name -format


2、启动namenode/datanode
cd /data/hadoop-2.8.2/sbin
start-dfs.sh

3、查看启动是否成功
在HadoopMaster节点上执行jps

在slave节点上执行jps

有如上打印输出则说明hadoop启动成功
4、启动yarn
cd /data/hadoop-2.8.2/sbin
start-yarn.sh 
5、验证集群是否启动成功
在HadoopMaster节点上执行jps

在slave节点上执行jps
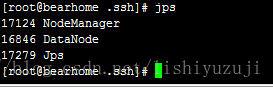
有如上打印输出则说明hadoop集群启动成功
第六步、验证Hadoop集群部署情况
1、查看集群状态
hdfs dfsadmin -report
2、访问yarn
http://masterip:port/cluster
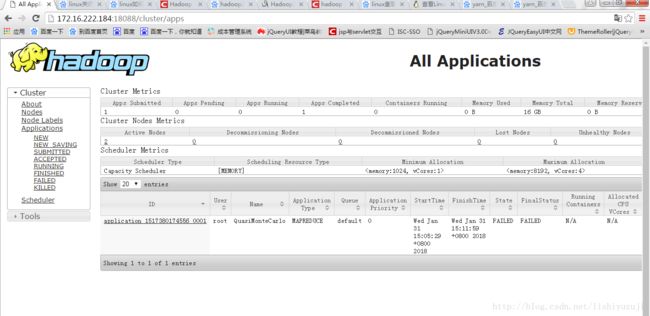
3、测试
hadoop都会自带一些例子,可以测试这些例子是否可以使用
hadoop2.8.2的例子在hadoop的/share/hadoop/mapreduce下
jar xxxx.jar pi 5 10
可以看到Yarn的管理客户端有任务执行,开始时间及结束时间。