分布式数据库HBase安装部署与应用
1.在安装Hbase之,确保 Hadoop 已经成功安装,并且 Hadoop 已经正常启动。 Hadoop 正常启动的验证过程如下:
(1) 使用下面的命令,看可否正常显示 HDFS 上的目录列表
# hdfs dfs -ls /

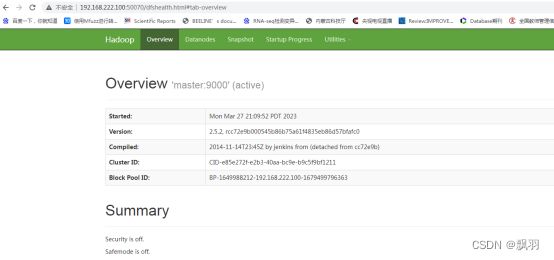
(2) 使用浏览器查看相应界面
输入网址:http://192.168.222.100:50070/
输入网址:http://192.168.222.100:18088/

该页面的结果跟 Hadoop 安装部分浏览器展示结果一致。如果满足上面的两个条件,表示 Hadoop 正常启动。
HBase 需要部署在 HadoopMaster 和 HadoopSlave 上。下面的操作都是通过 HadoopMaster 节点进行。
2.解压并安装 HBase
修改HBase的权限,
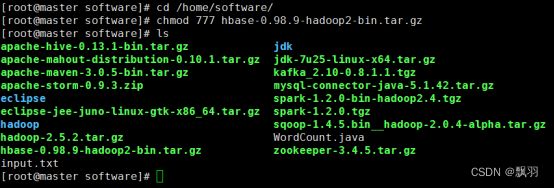
解压缩HBase安装包,会出现以下目录
# tar -zxvf hbase-0.98.9-hadoop2-bin.tar.gz

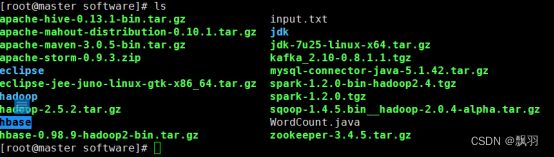
修改HBase的文件名:
3.配置HBase的系统环境变量,在profile文件中配置如下,
# vi /etc/profile
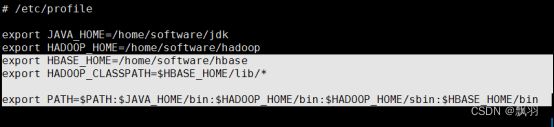
使环境变量配置信息生效,
![]()
验证环境变量配置是否成功:

4.配置Hbase运行环境变量信息,hbase-env.sh

找到以下信息,并且配置jdk的安装路径,并保存退出,如下,

5.配置hbase-site.xml配置文件,配置信息如下,
# vi hbase-site.xml
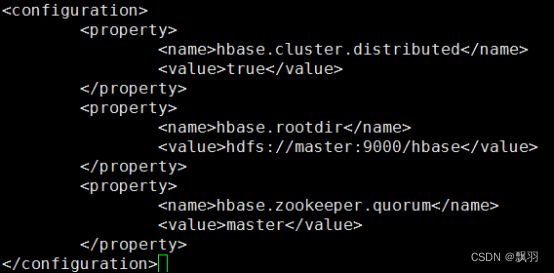
hbase.cluster.distributed
true
hbase.rootdir
hdfs://master:9000/hbase
hbase.zookeeper.quorum
master
6.设置 regionservers,将regionservers文件中的localhost改为slave,
# vi regionservers

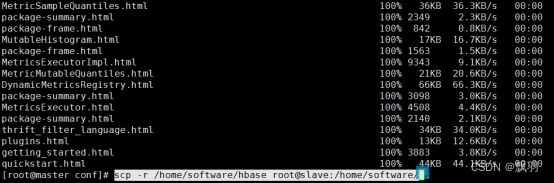
7.将 HBase 安装文件复制到 Hadoop的Slave 节点上,
# scp -r /home/software/hbase root@slave:/home/software/
8.启动HBase并进行验证,

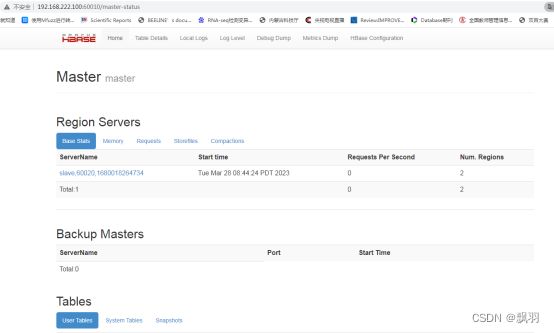
使用 Web UI 界面查看启动情况,打开浏览器,在地址栏中输入http://192.168.222.100:60010,会看到如下图的 HBase管理页面:如下图,看到这些表明 HBase 已经启动成功。
9.启动hbase的命令终端,
# hbase shell

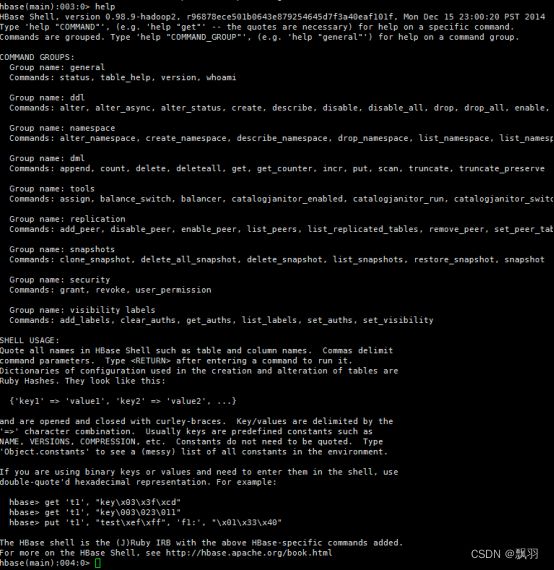
10.获取帮助
# help
11.获取命令详细信息
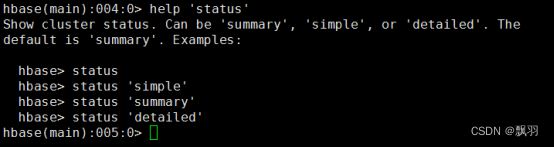
12.查看服务器状态

13.查看版本信息,

14.查看所有数据表,

15.创建表,命令格式:create ‘表名称’, ‘列族名称 1’,‘列族名称 2’,‘列名称 N’

16.查看表基本信息,命令格式:desc ‘表名’
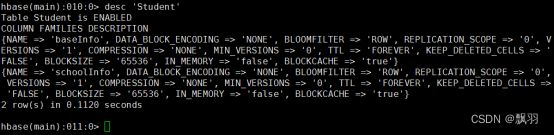

17.表的启用/禁用,enable 和 disable 可以启用/禁用这个表,is_enabled 和 is_disabled 来检查表是否被禁用。
禁用表:

# 检查表是否被禁用 is_disabled 'Student'

# 启用表 enable 'Student'

# 检查表是否被禁用 is_disabled 'Student'

#检查表是否存在 disable 'Student'

#删除表
# 删除表前需要先禁用表 disable 'Student' # 删除表 drop 'Student'

重新创建Student表

添加列族,命令格式: alter ‘表名’, ‘列族名’

删除列族,命令格式:alter ‘表名’, {NAME => ‘列族名’, METHOD => ‘delete’}
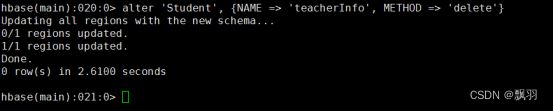
更改列族存储版本的限制
默认情况下,列族只存储一个版本的数据,如果需要存储多个版本的数据,则需要修改列族的属性。修改后可通过 desc 命令查看

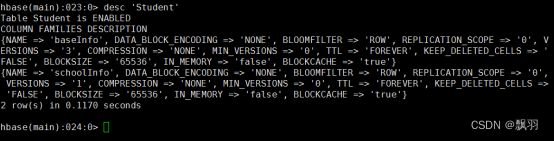
插入数据
命令格式:put ‘表名’, ‘行键’,‘列族:列’,‘值’
注意:如果新增数据的行键值、列族名、列名与原有数据完全相同,则相当于更新操作

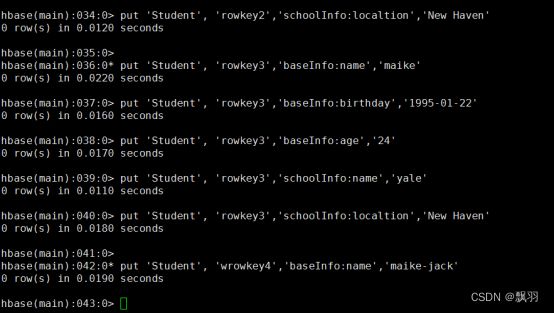
put 'Student', 'rowkey1','baseInfo:name','tom'
put 'Student', 'rowkey1','baseInfo:birthday','1990-01-09'
put 'Student', 'rowkey1','baseInfo:age','29'
put 'Student', 'rowkey1','schoolInfo:name','Havard'
put 'Student', 'rowkey1','schoolInfo:localtion','Boston'
put 'Student', 'rowkey2','baseInfo:name','jack'
put 'Student', 'rowkey2','baseInfo:birthday','1998-08-22'
put 'Student', 'rowkey2','baseInfo:age','21'
put 'Student', 'rowkey2','schoolInfo:name','yale'
put 'Student', 'rowkey2','schoolInfo:localtion','New Haven'
put 'Student', 'rowkey3','baseInfo:name','maike'
put 'Student', 'rowkey3','baseInfo:birthday','1995-01-22'
put 'Student', 'rowkey3','baseInfo:age','24'
put 'Student', 'rowkey3','schoolInfo:name','yale'
put 'Student', 'rowkey3','schoolInfo:localtion','New Haven'
put 'Student', 'wrowkey4','baseInfo:name','maike-jack'
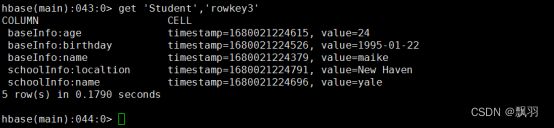
获取指定行、指定行中的列族、列的信息
# 获取指定行中所有列的数据信息 get 'Student','rowkey3'
# 获取指定行中指定列族下所有列的数据信息 get 'Student','rowkey3','baseInfo'

# 获取指定行中指定列的数据信息 get 'Student','rowkey3','baseInfo:name'

查看表中数据信息:
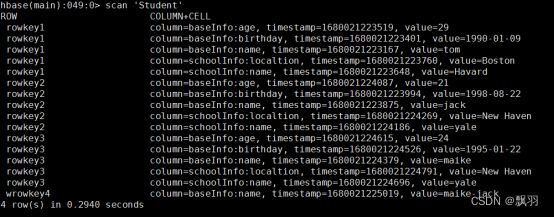
删除指定行、指定行中的列
# 删除指定行中指定列的数据 delete 'Student','rowkey3','baseInfo:name'

# 删除指定行 deleteall 'Student','rowkey3'

查询指定列簇的数据
条件查询
# 查询指定列的数据
scan 'Student', {COLUMNS=> 'baseInfo:birthday'}

除了列 (COLUMNS) 修饰词外,HBase 还支持 Limit(限制查询结果行数),STARTROW(ROWKEY 起始行,会先根据这个 key 定位到 region,再向后扫描)、STOPROW(结束行)、TIMERANGE(限定时间戳范围)、VERSIONS(版本数)、和 FILTER(按条件过滤行)等。
如下代表从 rowkey2 这个 rowkey 开始,查找下两个行的最新 3 个版本的 name 列的数据:
# scan 'Student', {COLUMNS=> 'baseInfo:name',STARTROW => 'rowkey2',STOPROW => 'wrowkey4',LIMIT=>2, VERSIONS=>3}

Filter 可以设定一系列条件来进行过滤。如我们要查询值等于 29 的所有数据:
scan 'Student', FILTER=>"ValueFilter(=,'binary:29')"

值包含 yale 的所有数据:
scan 'Student', FILTER=>"ValueFilter(=,'substring:yale')"

FILTER 中支持多个过滤条件通过括号、AND 和 OR 进行组合:
# 列名中的前缀为birth且列值中包含1998的数据
scan 'Student', FILTER=>"ColumnPrefixFilter('birth') AND ValueFilter ValueFilter(=,'substring:1998')"

PrefixFilter 用于对 Rowkey 的前缀进行判断:
