FlinkKafkaConsumer并行度设置
最近使用Flink的时候注意到一个不大不小的问题,就是关于Flink中使用FlinkKafkaConsumer时并行度设置的问题,这个算子的并行度最好是等于kafka中使用的topic的分区数。大于或者小于分区数都是有问题的,小于这个分区数不能够充分利用kafka的并发性能,大于分区数则会导致算子线程空转,浪费计算资源。
Flink在使用FlinkKafkaConsumer时,topic分区在分配给task线程的时候遵循一个很简单的原则:一个topic partition只会被分配给一个task线程;反过来一个task线程可能被会分配到多个topic parttiion,也有可能一个都分不到。这个逻辑的核心源码实现如下:
public static int assign(KafkaTopicPartition partition, int numParallelSubtasks) {
int startIndex =
((partition.getTopic().hashCode() * 31) & 0x7FFFFFFF) % numParallelSubtasks;
// here, the assumption is that the id of Kafka partitions are always ascending
// starting from 0, and therefore can be used directly as the offset clockwise from the
// start index
return (startIndex + partition.getPartition()) % numParallelSubtasks;
}这个代码简单来说就是用分区id对算子并行度进行取余,算子并行度就决定了task线程的数量,至于这里的startIndex我没太懂它的意义,不过也不影响上面的结论,这个余数就是相应被分配到的task 线程的索引号(indexOfSubtask)。如下代码所示,如果得到的余数等于当前task的索引号,那么这个分区就会分配给当前的这个task线程。
public boolean setAndCheckDiscoveredPartition(KafkaTopicPartition partition) {
if (isUndiscoveredPartition(partition)) {
discoveredPartitions.add(partition);
return KafkaTopicPartitionAssigner.assign(partition, numParallelSubtasks)
== indexOfThisSubtask;
}
return false;
}所以当source算子并行度大于topic分区数时,有的task线程就会分配不到相应的分区,就会出现空转的情况,浪费资源,而且这里影响到的不仅仅是source单个算子,还包括被包含在同一个JobVertex的其他算子。这里用一个简单的代码来说明:
env.setParallelism(6)
.addSource(getFlinkKafkaConsumer())
.map(new MapFunction>() {
@Override
public Tuple2 map(String value) throws Exception {
Entity entity=JSON.parseObject(value, Entity.class);
return new Tuple2<>(entity.getName(), entity.getNum());
}
}
)
.keyBy((KeySelector, String>) value -> value.f0)
.sum(1)
.print(); 这个代码有 5个算子(StreamOperator),经过算子合并后,生成的JobGraph包含两个JobVertex,第一个JobVertex包含Source: Custom Source、 Map两个算子;第二个JobVertex包含Keyed Aggregation 、Sink: Print to Std. Out两个算子。两个JobVertex被keyBy隔离,而keyBy里的KeySelector会被封装进KeyGroupStreamPartitioner。
这个代码里的addSource、map里面的自定义函数会被分配进同一个JobVertex,这里的JobVertex跟Spark里面的Stage几乎是等价的概念,同一个JobVertex的算子会放进同一个task线程里执行,上一个算子的数据会直接通过方法调用传递给下一个算子。在WebUI看到的JobGraph如下:

这里的topic有三个分区,但是并行度设置为6,那么就会出现task线程空转的情况,WebUI可以看到如下的情况: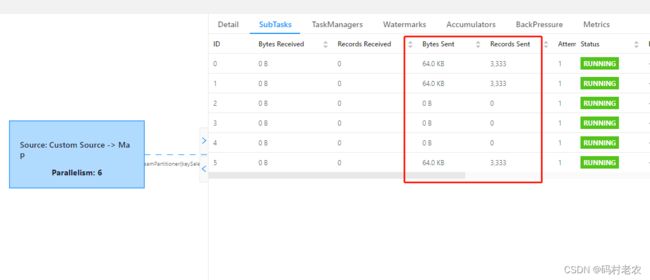
可以看到有的subtask是得不到数据的。所以我们这里就要对并行度做一些设置:
env.setParallelism(6)
.addSource(getFlinkKafkaConsumer())
.setParallelism(3)
.map(new MapFunction>() {
@Override
public Tuple2 map(String value) throws Exception {
Entity entity=JSON.parseObject(value, Entity.class);
return new Tuple2<>(entity.getName(), entity.getNum());
}
}
)
.keyBy((KeySelector, String>) value -> value.f0)
.sum(1)
.print(); 这里把addSource的平行度设置成了topic的分区数。相应生成的JobGraph也会发生改变,如下图所示:
这里Source: Custom Source与Map被分开了,成了独立的JobVertex,中间用REBALANCE连接,这里的REBALANCE相当于Spark中的Repartition,因为前后两个算子的并行度不一样,所以这里需要做一次数据再平衡。这样设置后对于source算子就不会出现空转,而且经过数据再平衡后,后面的算子会均匀地得到前面算子的输出。

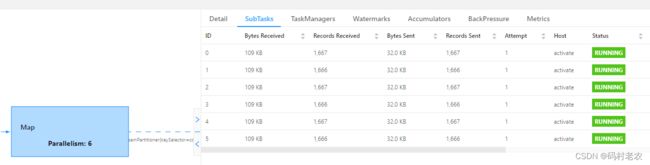 但是数据再平衡会出现数据序列化/反序列化以及网络传输等操作,也会带来一定的性能损耗,所以合理设置topic分区数量至关重要,要综合Flink应用一起考虑。
但是数据再平衡会出现数据序列化/反序列化以及网络传输等操作,也会带来一定的性能损耗,所以合理设置topic分区数量至关重要,要综合Flink应用一起考虑。