Java Map和Set
目录
-
- 1. 二叉排序树(二叉搜索树)
-
- 1.1 二叉搜索树的查找
- 1.2 二叉搜索树的插入
- 1.3 二叉搜索树的删除(7种情况)
- 1.4 二叉搜索树和TreeMap、TreeSet的关系
- 2. Map和Set的区别与联系
-
- 2.1 从接口框架的角度分析
- 2.2 从存储的模型角度分析【2种模型】
- 3. 关于Map
-
- 3.1 Map的注意事项
- 3.2 TreeMap 和 HashMap的对比
- 3.3 Map.Entry
- 4. 关于Set
-
- 4.1 Set的注意事项
- 4.2 TreeSet 和 HashSet的对比
- 4.3 迭代器遍历Set
- 5. 哈希表
-
- 5.1 哈希函数
- 5.2 冲突
- 5.3 冲突的解决:开放地址法和链地址法
- 5.4 哈希表与Java集合类的关系
- 6. HashMap源码分析
-
- 6.1 成员变量
- 6.2 构造方法
- 6.3 put方法源码
1. 二叉排序树(二叉搜索树)
二叉搜索树又称二叉排序树
- 若左子树不为空,则左子树上所有节点的值都小于根节点的值
- 若右子树不为空,则右子树上所有节点的值都大于根节点的值
- 左右子树也分别是二叉搜索树
【左小右大】
1.1 二叉搜索树的查找
【二叉搜索树的查找,一般情况下一次可以干掉很多数据】
为了保证每次可以干掉很多数据
思路:取遍历节点为cur,每次要查找的值val和cur的val进行比较,如果要查找的值比cur的val小,则去cur的左边继续查找,如果大则去cur的右边继续查找。
public boolean search(int val) {
TreeNode cur = root;
while (cur != null) {
if (cur.val == val) {
return true;
}else if (cur.val > val) {
cur = cur.left;
}else {
cur = cur.right;
}
}
return false;
}
1.2 二叉搜索树的插入
思路:整体思路与查找的思路类似,但是二叉搜索树的每次插入的节点一定是叶子节点,因此需要记录待插入节点的双亲。
当cur为空时,parent记录了待插入结点的父亲位置,再用val和parent的val比较进行插入。
public void insert (int val) {
Node node = new Node(val);
if (root == null) {
root = node;
return;
}
Node cur = root;
Node parent = root;
while (cur != null) {
if (cur.val == val) {
return;
}else if (cur.val > val) {
parent = cur;
cur = cur.left;
}else {
parent = cur;
cur = cur.right;
}
}
if (parent.val > val) {
parent.left = node;
}else {
parent.right = node;
}
}
1.3 二叉搜索树的删除(7种情况)
设待删除结点为cur,待删除结点的双亲结点为parent
整体看分以下3种大情况:
①cur的左为空
②cur的右为空
③cur的左和右都不为空
继续细分:cur是不是root;cur不是root的话,是parent的左还是parent的右
故有3 + 3 + 1 = 7种情况。
- cur.left == null
①cur是root
则 root = cur.right;
②cur不是root,cur是parent.left
则 parent.left = cur.right;
③cur不是root,cur是parent.right
则 parent.right = cur.right; - cur.right == null
①cur是root
则 root = cur.left;
②cur不是root,cur是parent.left
则 parent.left = cur.left;
③cur不是root,cur是parent.right
则 parent.right = cur.left; - cur.left != null && cur.right != null
此时需要使用替换法进行删除,即在它的右子树种寻找中序下的第一个结点(关键码最小),用它的值填补到被删除节点中,再来处理该结点的删除问题。1.4 二叉搜索树和TreeMap、TreeSet的关系
TreeMap和TreeSet是Java种利用搜索树实现的Map和Set,实际上用的是红黑树,红黑树是一颗近似平衡的二叉搜索树,即在二叉搜索树的基础之上+颜色以及红黑树性质。
2. Map和Set的区别与联系
2.1 从接口框架的角度分析
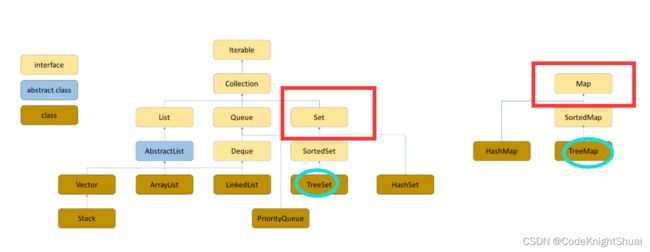
Map是一个独立的接口,而Set继承自Collection接口。
TreeMap 和 TreeSet 都继承了一个Sorted接口,说明 Tree某某 都是经过排序的,即 Tree某某 都是关于key有序的。
2.2 从存储的模型角度分析【2种模型】
- Map中存储的是键值对key-value
- Set中只存储了key
3. 关于Map
Map是一个接口类,该类没有继承collection,该类中存储的是
3.1 Map的注意事项
- Map是一个接口,不能直接实例化对象,如果要实例化对象只能实例化其实现类TreeMap或者HashMap。
Map<Integer, Integer> map1 = new HashMap<>();
Map<Integer, Integer> map2 = new TreeMap<>();
- Map中存放键值对的键key是唯一的,key不可以重复,但是value可以重复。
- 在TreeMap中插入键值队的时候,key不能为空,否则会抛出NPE(空指针异常),但是value可以为空,因为TreeMap中的key是要进行比较的;反而HashMap的key和value都可以为空,因为HashMap不涉及比较。
- Map中的key可以全部分离出来,存储到Set中进行访问(因为key不能重复,set是天然的去重),Map中的value可以全部分离出来,存储到Collection的任何一个子集合中(value可能有重复)
3.2 TreeMap 和 HashMap的对比
| Map底层结构 | TreeMap | HashMap |
|---|---|---|
| 底层结构 | 红黑树 | 哈希桶 |
| 插入/删除/查找时间复杂度 | O(log2N) | O(1) |
| 是否有序 | 关于key有序 | 无序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 需要进行元素比较 | 通过哈希函数计算哈希地址 |
| 比较与覆写 | key必须能够比较,否则会抛出类型转换异常 | 自定义类型需要覆写equals和hashcode方法 |
| 应用场景 | 需要key有序的场景下 | key是否有序不关心,需要更高的时间性能 |
3.3 Map.Entry的用法 (遍历)
Set

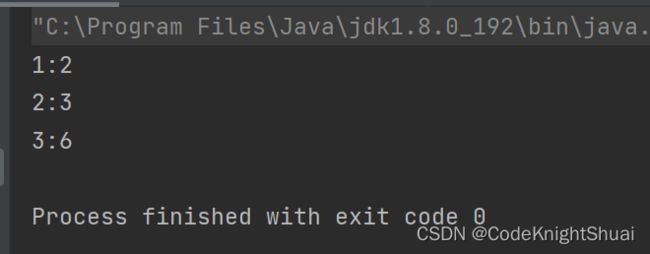
Map<Integer, Integer> map = new TreeMap<>();
map.put(1,2);
map.put(2,3);
map.put(3,6);
//key一定是可以进行比较的
for(Map.Entry<Integer,Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
分析:
打印所有的键值对
entrySet():将Map中的键值对放在Set中返回了。
4. 关于Set
Set与Map主要的不同有2点:
①Set是继承自Collection的接口类
②Set中只存储了Key
Map不能使用迭代器遍历,但是Set可以,因为Set实现了Iterable接口
4.1 Set的注意事项
-
Set是继承自Collection的一个接口类
-
Set中只存储了key,并且要求key一定要唯一
-
Set的底层使用Map来实现的,其使用key与Object的一个默认对象作为键值对插入到Map中

-
Set最大的功能就是对集合中的元素进行去重
-
TreeSet中不能插入null的key,但是HashSet可以
4.2 TreeSet 和 HashSet的对比
| Set底层结构 | TreeSet | HashSet |
|---|---|---|
| 底层结构 | 红黑树 | 哈希桶 |
| 插入/删除/查找时间复杂度 | O(log2N) | O(1) |
| 是否有序 | 关于key有序 | 不一定有序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 按照红黑树的特性进行插入和删除 | 通过哈希函数计算哈希地址 |
| 比较与覆写 | key必须能够比较,否则会抛出类型转换异常 | 自定义类型需要覆写equals和hashcode方法 |
| 应用场景 | 需要key有序的场景下 | key是否有序不关心,需要更高的时间性能 |
4.3 迭代器遍历Set
Iterator< E> iterator() 返回迭代器,可以利用其进行遍历
Set<Integer> set = new TreeSet<>();
set.add(1);
set.add(3);
set.add(2);
set.add(8);
set.add(4);
Iterator<Integer> iterator = set.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next() + " ");
}
运行结果:

5. 哈希表
5.1 哈希函数
- 哈希表的效率非常高,查找、删除、插入的时间复杂度都是O(1)。
- 理想的搜索方法:不经过任何比较,一次直接从表中得到想要搜索的元素,即一一映射关系。
- 哈希方法中使用的转换函数称为哈希函数,构造出来的结构称为哈希表(Hash Table)。
- 哈希函数计算出来的地址能均匀分布在整个空间中。
5.2 冲突
- 冲突: 不同关键字通过相同哈希函数计算出相同的哈希地址
- 冲突的发生是必然的,冲突是不可避免的,只能降低冲突率。
- 避免冲突:负载因子调节,其值= 填入表中的元素个数/哈希表的长度,因此可以增加哈希表的长度避免冲突。Java的系统库限制了荷载因子为0.75。
5.3 冲突的解决:开放地址法和链地址法
- 开放地址法(闭散列)
①线性探测
②二次探测
闭散列最大的缺陷:空间利用率比较低 - 链地址法(开散列) 数组+链表+红黑树
思路:首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于桶一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
注意:数组长度>=64,链表长度>=8,就会变成红黑树。
5.4 哈希表与Java集合类的关系
- HashMap和HashSet是用哈希表实现的Map和Set。
- Java会在冲突链表长度大于一定阈值后,将链表转变成红黑树(搜索树)。
- Java中计算哈希值实际上调用的是类的hashcode方法,进行key的相等性比较是调用key的equals方法。
- 所有自定义类的HashMap的key或者HashSet的值,必须重写hashcode和euqals方法,而且必须做到euqals相等的对象,hashcode一定也是一样的。
- 扩容之后要注意每个元素都要重新计算hashcode哈希值。
面试问题:
- 问:如果2个对象hashcode一样,equals一定一样吗?
答:不一定,hashcode一样只能证明我们要找的位置一样,位置一样的下面有很多值,无法确定2个对象的euqals。- 问:如果2个对象equals一样,hashcode一定一样吗?
答:一定,equals一样则hashcode一定一样。
6. HashMap源码分析
6.1 成员变量
- 默认容量:16,最大容量:2的30次方

- 默认的负载因子:0.75

- 树化的条件(数组+链表变成红黑树)
链表长度超过8,数组的容量大于等于64
- 解树的条件(红黑树退化为链表+数组)
链表的阈值为6的时候

- table数组的每一个元素是node类型的结点地址

6.2 构造方法
- 不带参数的构造方法
负载因子等于默认的负载因子0.75,没有给table数组进行初始化,意味着table数组没有分配内存,数组的大小是0。
(所以,为什么等会put元素可以put进去?----> 说明在第一次put的时候,会把数组进行初始化为默认容量16)

- 带2个参数的构造方法
一个是给定的容量参数,一个是给定的负载因子参数
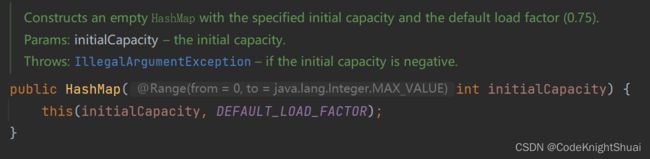
如果给定的参数容量大于2的30次方,则容量为2的30次方;
如果给定的参数容量小于0或者给定的负载因子小于0那么就抛异常。
最后负载因子满足条件直接赋值,但是容量还需要经过tableSizeFor进一步筛选。

tableSizeFor里面:返回最接近目标的一个二次幂整数。
例如:
传入10:2的3次方=8,2的4次方16,因此返回16。
面试题:调用构造方法给了1000,请问最后哈希数组的长度是多少?
答:1024

HashMap的最大容量保证是2的n次方,但是如果没有传入一个2的次方怎么办?
答:HashMap会将传入的参数做校验,返回距离传参最近的一个2的n次方的值,例如传入15会初始化为16。
那么,为什么返回二次幂呢?
分析put源码。
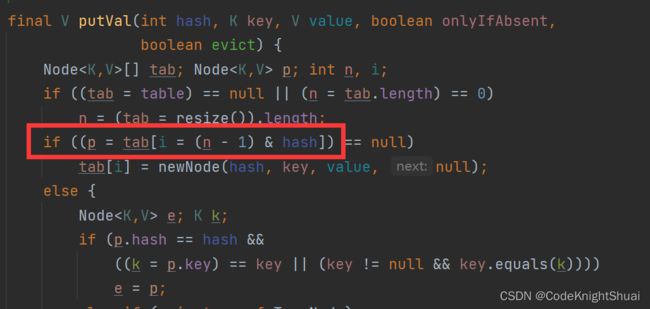
6.3 put方法源码

①先把key给到hash函数中,hash(key),调用hash方法,将引用类型key转换成整数类型

②hash这个方法中调用了hashcode方法,如果key重写了hashcode方法则会调用自己的hashcode方法,如果没有重写,则会调用Object类的hashcode方法。
h是通过hashcode方法得到的32位的整数,h 异或上 h右移16位
为什么要右移16位?
答:为了更好的均匀分布,低16位和高16位异或,可以让结果更均匀。

③i = (n - 1) & hash 等价于 n % len,位运算一定是最快的,一定要保证n是2的次幂,这样2个公式才等价。【所以初始化的长度为2的整数次幂】