PostgreSQL 数据库初体验

10月15日,由山东华鲁科技咨询顾问高强老师在“DBA+济南群”进行了一次关于PostgreSQL数据库初体验的线上主题分享。小编特别整理出其中精华内容,供大家学习交流。
嘉宾简介
高强,“DBA+济南群”联合发起人。现就职于山东华鲁科技发展股份有限公司。擅长Oracle、AIX、Linux、PostgreSQL和DB2等产品的实施、运维和故障处理。曾是一名存储工程师,负责实施存储、双机和备份等产品,在接触到数据库产品后,一发不可收拾的投入了DBA的浩瀚大军中,在众多的项目中,积累了较丰富的数据库、主机以及集群的运维经验。
曾参与多个省级政府单位项目的实施和运维工作,具有丰富的运维经验。经常在个人博客积极分享在项目中遇到的问题解法、钻研的技术、收获的感悟和宝贵资料。热衷于与网友交流技术、行业资讯和从业感悟等想法,希望为行业的发展和繁荣贡献自己微博的力量。
演讲实录
今天的内容是关于一个用萌萌的大象作为Logo的数据库产品,他的名字叫做PostgreSQL,一般都简称他为“PG”。
“PostgreSQL是数据库世界里的"锤子"。它既广为人知,又容易获得,还很坚固,如果你抡得够猛,它所能解决的问题数量惊人。如果不了解这个最常用的工具,你就不可能成为建筑专家。”
摘自《Seven Databases In Seven Weeks》
第2章PostgreSQL
PostgreSQL的起源
1977年,Michael Stonebraker开始和学生一起做关系型数据相关的研究并成立了项目Ingres,“Interactive Graphics and Retrieval System”的缩写,是PostgreSQL数据库的前身。
Stonebraker后来成立了Ingres Corporation公司, 开始做一个叫”post-INGRES”的项目,尝试去解决一些原有关系模型的限制,后来被称作POSTGRES。
POSTGRES 项目是由防务高级研究项目局(DARPA),陆军研究办公室(ARO),国家科学基金(NSF), 以及 ESL, Inc 共同赞助的。
PostgreSQL是完全由社区驱动的开源项目,由全世界超过1000名贡献者所维护。它提供了单个完整功能的版本,而不像MySQL那样提供了多个不同的社区版、商业版与企业版。PostgreSQL基于自由的BSD/MIT许可,组织可以使用、复制、修改和重新分发代码,只需要提供一个版权声明即可。
可靠性是PostgreSQL的最高优先级。它以坚如磐石的品质和良好的工程化而闻名,支持高事务、任务关键型应用。PostgreSQL的文档非 常精良,提供了大量免费的在线手册,还针对旧版本提供了归档的参考手册。PostgreSQL的社区支持是非常棒的,还有来自于独立厂商的商业支持。
使用限制
PostgreSQL在数据存储方面所能支持的容量是相当大的。

体系架构
像绝大多数数据库产品一样,PostgreSQL也是由数据库实例和相关文件组成,其中实例包括数据库的一些各负其职的进程与内存结构组成,数据库的文件也包含控制文件、WAL文件、数据文件和各种配置文件。
PostgreSQL的基本结构我借用了网上的图并做了标注:
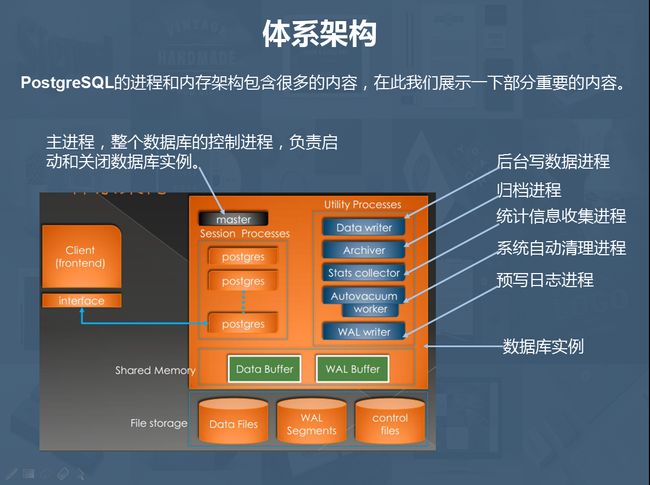
下面我们用实际操作演示的形式简单介绍一下PostgreSQL数据库的日常维护操作和高可用集群方案:
1 【实验1】创建数据库
实验内容:在指定路径路径 /pgdata/music下创建数据库music,后续实验都会在该库中进行。
由于现如今存储价格成本降低,数据量增长迅速,所以很多项目中都会采用外挂存储的架构,因此存放数据的核心地带一般都会选择放在外置存储上。所以一般选择自定义的方式指定路径创建数据库。
PG中创建数据库之前需要先在操作系统中建好文件系统路径,然后在指定路径上创建表空间,最后创建数据库即可,命令非常简单。通过本次的实验你可以看到,PG的命令语法与绝大多数的数据库都很相似,他支持标准的SQL,自己的维护命令也有很强的可读性,直观、易理解。
2 【实验2】CRUD(增查改删)
实验内容:
在刚才创建的music数据库中创建表,命名summary,并插入四条数据,每条数据的ID都是1,然后修改ID,让每条数据的ID唯一。
CRUD的操作在后续的Hot_standby和PGPOOL中会陆续出现,删除操作在PGPOOL试验中体现。
3 【实验3】数据库配置变更
对于DBA来说,在日常数据库维护中,可能需要根据业务需求和客户需求的变化调整数据库参数配置,PostgreSQL的参数调整相对较方便,其配置文件postgresql.conf中有对各个参数的注释解释。
基本上参数配置后有立刻生效和重启生效两种情况。
查看和修改参数的命令非常简单,查看参数可以在数据库中用如 show work_mem 查看,还可以看配置文件,也可以查pg_settings表;修改参数也可以直接调整配置文件,也可以通过命令如 set work_mem = '16MB'生效。
Set仅对当前会话生效,也就是说我们可以对个别的操作或者事务进行定制的配置,如临时给其分配大一点的缓存以供排序等操作。
建议:自己尝试体验一下开启归档模式和归档路径的变更调整,实验如果遇到问题可随时与我沟通交流。
实验内容:
调整work_mem,该参数立刻生效;
调整shared_buffers,该参数需重启生效。
知识补充:
PostgreSQL数据库的关闭和重启操作命令:
停库:pg_ctl stop -m fast ,“-m fast”相当于Oracle中的immediate。
启库:pg_ctl start
4 性能监控:
PostgreSQL数据库有很多监控软件,有很多类似Oracle AWR的工具,如pgstatspack和pg_statsinfo等等,还有很多图形化界面的实时监控工具。这些工具的数据来源都是PostgreSQL本身丰富的性能表,都是状态收集进程收集并写进去的。
实验内容:
1.查看数据库的相关性能的表,如pg_lock、pg_stat_activity等,远程发起查询并查看视图中的信息同步情况。
2.使用pgstatspack 做数据库快照并生成性能报告,并浏览性能报告的信息。
5 备份恢复:
PostgreSQL的备份恢复工具有很多,如PGDUMP、PG_RMAN和BARMAN等。在本次试验中,我们演示pgdump的备份和恢复功能。
Pgdump在较新的版本中可以实现并行备份,以充分利用计算机硬件资源提高备份效率,具体内容可参照我的博文:《PostgreSQL数据库备份之pg_dump并行备份 》
实验内容:
备份数据库后删除刚才实验中创建的表summary,恢复数据库后验证数据是否可用。
6 Hot Standby
PostgreSQL的Hot Standby功能可以实现主从数据库的实时同步,可用于容灾、备份、读写分离分担性能压力和数据分析等场景。此实验中使用了Streaming Replication(流复制)方式,同步速度比较快。Hot Standby也支持一主多从的架构,即一台主服务器,多台从服务器,这样的话,可以有多台设备保证数据完整性,也可以在读写分离的场景中有获得更好的的读性能。
PG也可以跟后面要讲到的PGPOOL结合,做一个高可用(故障切换)或者是负载均衡(高性能)的集群。
实验内容:
演示过程中左边的窗口里的库为主库,主机名dbserver1;右边的为从库,主机名dbserver2。窗口上方的标签变为蓝色则表示当前操作窗口。
1.在主库中创建测试表test,备库中验证;
2.主库中插入新的记录,备库中验证。
7 PGPOOL
PGPOOL是一个中间件工作在多个PostgreSQL和客户端之间,是PostgreSQL的集群方案之一。它具有连接池、复制、负载均衡、并行查询和高可用等功能。
其实我们刚才一直操作的环境就是在PGPOOL下面的PostgreSQL数据库中操作,当时没有用到PGPOOL的功能是因为我们直接连接的数据库而不是PGPOOL。连接PGPOOL的话一般默认的端口是9999,而连接数据库的话,默认的端口是5432.
PGPOOL的架构图如下:
(图中用了2台PG做集群,实际上还可以增加数据库服务器的数量;本次试验中PGPOOL是安装在了主库所在的系统中,即只用了2台服务器搭建环境):
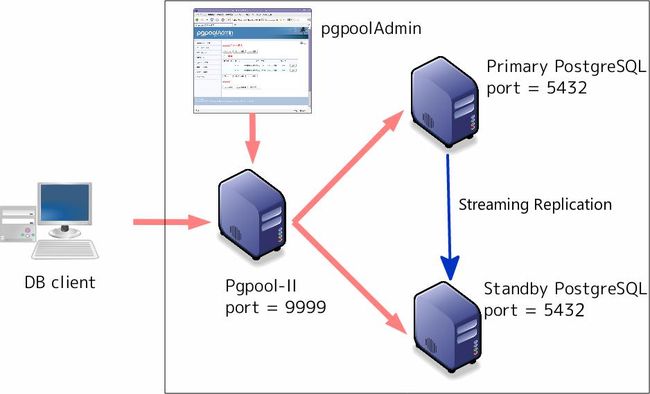
实验内容:
1.启动PGPOOL: pgpool -n ,可以从输出中看到使用了9999作为PGPOOL的端口并且提供了很多进程以供客户端连接进来;
2.用我自己笔记本上的客户端连接PGPOOL(而不是直接连数据库,可以在图形界面窗口左上方看到连接信息的端口号是9999而不是5432),然后做CRUD(增查改删)操作,并检查主、从数据库的数据同步情况。(依然是左边命令行窗口为主库,右边为从库)
Q&A精选
疑难解答
【问题1】:
我一直在使用PG数据库,在做主备双机的时候有些问题:主备数据库不能在故障时候自动切换,必须手动进行切换,而且PG数据与主流的双机软件如rosemirrorha无法很好的兼容配置。
答:
PostgreSQL HA的话,PG界的大牛德哥有一个方案: 说到rosemirrorha跟pg的问题,最好具体说一下问题或者错误信息。
问:
rosemirrorha一般同步SQL的时候,就是将SQL的三个服务作为条件添加,服务期间使用双绞心跳线作为介质。但是pg在添加服务条件时无法正常添加。PG HA群集的时候,仲裁节点损坏怎么办?
答:
vote节点确实有单点故障的隐患。这样的架构我在别人博客中看过,但是没有自己经历过。我认为首先在部署的时候,应该选择业务压力比较小的设备作为vote节点,减少其压力和故障率。然后在监控的时候需要关注一下vote设备的状态,这也是运维的及时性的要求。
这个方案我没用过,我觉得vote宕机后,主备的架构可能不会改变,也许业务不会受影响,只是在故障发生的时候可能会导致切换问题,这是我的理解。
问:
运维的时候,PG HA是一个可靠性是个很关键的因素。我们这边使用的PG一直都不错,唯独切换问题一直困扰。
答:
PG的HA方案有很多种选择,据我所知,keepalive+Postgresql是一种,还有用pacemaker+corosync的。
问:
曾经想使用过vote节点,但是考虑到vote节点增加后反而会成为一个新的故障点,不如主备手动切换的可靠。
答:
这个问题我认为就像“50万的车安全,还是5万的车安全?”一样,我觉得设备和架构的安全都是相对的,绝对的安全是运维同事的负责任的态度、对业务和架构的熟练掌握,以及使命感。
即使是有仲裁节点的备机,那如果仲裁节点有问题,或者是双机有一台机器故障了,我们还是需要第一时间去现场处理,避免事态恶化。
问:
运维中故障可靠性处理和及时性是必须的,监测软件和主板切换有时候还是存在不靠谱。我碰到一回ha软件,将损坏的数据库同步到没有损坏的数据库上,结果就是主备全坏。
答:
我之前实施过Rose HA,感觉还是不错的。
问:
比较成熟的ha软件不知道为什么总是跟pg过不去?
答:
不是说跟它过不去,每一款软件都有他特别擅长、特别针对的对象和场景,也有不是特别擅长的。当然还是得具体问题具体分析,结合你提供的信息和报错截图来分析一下。
【问题2】可以说说pg的应用场景吗,和mysql比较有什么优势?
PostgreSQL数据库大多数OLTP和OLAP场景都适用。很惭愧MySQL和MariaDB我了解的不深入,据我了解2者有很多不同,比如PG用的是进程,MySQL则使用线程;PG的查询优化器很强大;PG的性能统计表比较丰富;PG和MySQL的多版本控制机制也不同,还有很多不同的特性。每种产品都有自己的亮点和短板,MySQL现在有Oracle的研发团队推动的话,感觉上可能会越来越好,因为Oracle的眼光和思路感觉很超前。PostgreSQL的社区和贡献者也是很强大,一直也在为PG注入更多亮点功能以适应发展需要。
DBA+有很多的专家,如果兄弟遇到方案选型的问题,可以来讨论一下,把具体的需求说一下,咱们具体问题具体讨论,条件允许的话,我们可以适当的模拟测试一下,用结果说话,争取为你找到最佳实践。
【问题3】确实没学过pg,除了官方文档外,讲师最推荐看什么书入门,当然,最好中文的。
PostgreSQL国内社区一直都在努力的做文档中文化工作,国内也有出相关的PostgreSQL的中文教材,唐成老师今年出版了一本《PostgreSQL修炼之道》,拜读了一下,感觉写的挺全面的;还有一本《PostgreSQL 9.0性能调教》感觉也挺好。
【问题4】去O说的这么火,用pg来替代O有没有什么坑需要事先考虑?
个人感觉Oracle的功能和产品优势还是很好的,如果经济上允许,Oracle还是最好的选择,RMAN和ASM等功能在日常维护工作中还是比较让人省心,Oracle的RAC和DG也很成熟,很有优势。如果非要去O,感觉还是需要谨慎、循序渐进的处理,具体事情具体对待,可先针对费核心业务业务进行迁移,待PG知识消化和经验积累一段时间后尝试更大业务的迁移,当然目前也有很多PG云平台可供选择。PG转O的话貌似代码修改工作量可能不需要太多,但是两个数据库的某些内部机制有区别,同样的代码在不同的库里跑,可能效果不同,所以需要辩症处理、细致调整。
【问题5】发个BCT问题:数据库的备份策略是第一次全备份后就每天增量备份,且BCT(block_change_tracking)已经打开。如果有人额外手工发起了一个全备份并使用不同的catalog库,那么,下次增量备份的时候会出现什么情况?
这种情况没在项目中对比过,我只知道BCT的记录文件是放在库里的,使用不同的恢复目录是可以看到之前的备份信息的。
各抒已见
【问题1】有个问题问一下,我看pg的支持厂商很多,pg是否有很多分支?各个分支有什么特点?
观点1:PostgreSQL只有单独的一个版本,数据库稳定、功能丰富、支持标准SQL语句,方便下载,思路清晰。
观点2:pg只有社区版,其它厂家很多是基于pg的技术,做自己的特性。但是pg已经非常稳定和可靠,部署也非常多,关于支持,国内做专业支持的不多,做得好并且技术也好的就毛鳞凤角了。
【问题2】每个数据库都有优点和缺点,反过来问pg有什么缺点?
观点1:PostgreSQL是有一些不足,跟Oracle相比的话,没有RMAN这种基于块级别的备份机制,PG_RMAN是通过检验文件更改信息后直接备份整个文件;Oracle RAC这种的架构目前PG好像还没有特别成熟、稳定的产品和支持。可能还有其他的不足,社区一直在努力的让PG更成熟、更强大。原厂服务的话Oracle的知识库和售后还是很给力的。
观点2:我觉得最大的不好就是国内对这个这么优秀的PostgreSQL数据库了解太少,误解太多。实际上pg在中国以外的地区部署量是非常庞大的,并且是在银行、电信、航天、军工里面要求真正7*24*365不能停机的关键应用。
【问题3】我听说pg和oracle比,单表查询效率较高,多表联合不行,老师有这种说法吗?
观点1:具体需要看是什么样的语句,什么类型、规模的表,最好还是实际测试一下。PostgreSQL的优化器还是很强劲的。
观点2:那是mysql。不管是olap,还是oltp应用,还是功能,pg的效率在绝大多数情况下能达到Oracle效能的95%。有些情况下会比Oracle的性能更好。
【问题4】standby中网络问题等会对主库造成影响吗?对数据类型有啥要求不?
观点1:网络问题会有一定程度的影响,这一点不论任何产品都有这可能。stream是目前比较新的复制方案,不需要等待日志写完,提交后即可同步,目前看到的比较成熟的案例都是同构的。
本文来自云栖社区合作伙伴"DBAplus",原文发布时间:2015-10-15