redis持久化与架构搭建
记录一下学习笔记。
redis作为一个内存数据库,读写数据非常高效,能够搭建非常好的高可用架构,虽然是内存数据库,但是也提供了不错的持久化方式。
redis支持的持久化方式:
- RDB快照方式(二进制的方式存储)
- AOF方式(命令的方式存储,resp协议)
- 混合方式(rdb+aof的方式)
RDB持久化方式
在redis目录下,有个dump.rdb文件,redis在持久化过程中,会将数据以二进制的方式写进dump.rdb文件。
redis.conf是redis最重要的配置文件,所有配置信息包括集群都在该配置文件中,在redis.conf中有一段配置是
设置RDB持久化策略的:

比如 “save 900 1” 表示900s内至少有一条数据的改动,则进行持久化操作。
持久化不一定要redis来做,也可以手动执行,持久化命令方式有两种:bgsave和save命令,
通过执行该两种命令就可以将数据持久化到新的rdb文件,并且覆盖原有rdb文件中。
redis是使用了bgsave命令持久化的。
bgsave的写时复制:
该命令使用了操作系统的写时复制技术,当命令执行时,主线程会fork一个子线程出来,让该子线程读取主线程的数据,然后将数据进行持久化操作,主线程和子线程互不干扰。当主线程有写操作时,会将被写数据复制一个副本出来,fork子线程会将副本数据进行持久化,主线程仍然可以继续写数据。
save 与 bgsave命令的对比:
| save | bgsave |
|---|---|
| 同步IO | 一部IO |
| 会阻塞其他命令 | 否(在生成子进程执行调用fork函数时会有短暂阻塞) |
| 不会有额外内存开销 | 需要fork子进程,有额外开销 |
AOF(append-only file)持久化方式
在进行持久化操作时,会将每一条命令记录到appendonly.aof文件中,可通过redis.conf设置appendonly yes来开启,如下:
# Please check http://redis.io/topics/persistence for more information.
appendonly yes
# The name of the append only file (default: "appendonly.aof")
appendfilename "appendonly.aof"
设置完重启服务,执行几条命令,可以看到aof文件保存的数据格式如下:
127.0.0.1:6291> set appendonly mode
OK
127.0.0.1:6291> set way 5
OK
127.0.0.1:6291> exit
[root@iZwz9a3e04j4x7s9jarg1iZ redis-6.0.9]# cat appendonly.aof
*2
$6
SELECT
$1
0
*3 # *3表示执行的命令个数是3个
$3 # $3表示当前set命令字符长度是3
set
$10 # $10表示当前命令参数appendonly的字符长度是10
appendonly
$4
mode
*3
$3
set
$3
way
$1
5
这是一种resp协议格式数据,在做数据恢复时,只需要将该文件命令重新执行一遍就行了。
可通过配置实现redis fsync刷新数据的频率,可看如下redis.conf配置信息:
# If unsure, use "everysec".
# appendfsync always # 每更新一条数据就fsync到磁盘,性能并不好,但是数据安全,宕机了最多就只丢失一条数据
appendfsync everysec # 默认开启,每秒刷新一次数据到磁盘
# appendfsync no # 把主动权交给操作系统,会更快,不确定性也更高
AOF还有一个重写机制,我们每写一条数据都会被记录,有可能是一条记录经过几条命令修改,这是一条命令就可以达到的效果,AOF机制会根据内存的最新数据重新生成命令更新aof文件。
来看一段redis.conf配置信息:
# Specify a percentage of zero in order to disable the automatic AOF
# rewrite feature.
# 这个是百分比,当文件大小再次增长100%时,将再次触发重写机制
auto-aof-rewrite-percentage 100
# 当文件大小为64mb时,进行文件重写,如果设置内存太小,则没必要重写,文件小则重启快。
auto-aof-rewrite-min-size 64mb
可根据情况进行设置。
也可以进行手动重写,执行bgrewriteaof命令,类似bgsave命令,会fork一个子线程进行重写。
redis4.0 混合持久化
因为RDB方式不太安全,容易丢失数据,而AOP方式恢复数据速度不够快,所以结合两种方式:
在进行持久化过程中,会将内存中的数据以rdb方式保存在新aof文件中,然后将该aof文件覆盖掉appendonly.aof文件。新加进来的数据会以resp协议的方式追加到aof文件中,也就是aof文件中以两种格式的数据保存着。
混合持久化配置信息(因为是aof文件,所以必须先开启AOF方式):
# When loading, Redis recognizes that the AOF file starts with the "REDIS"
# string and loads the prefixed RDB file, then continues loading the AOF
# tail.
aof-use-rdb-preamble yes
redis提供的架构方式:
- 单体架构:主从架构
- 群体架构:哨兵集群和cluster集群
主从架构
如果我们只启动了一个redis服务,当redis进程宕掉了之后,我们的缓存数据就不能用了,这是很严重的问题,所有访问都打到数据库上,可能会把数据库打挂了,所以需要加强架构,可以加多一个或多个redis实例,当正在使用的实例挂掉了,另一个可以顶上去,这是属于单机体系的架构,保证我们的单机系统可用性,也可以实现读写分离,主写从读,这是我们常见的主从架构。
最简单的主从架构:只有一个从节点,从主节点中备份数据,当主节点挂掉时顶上。
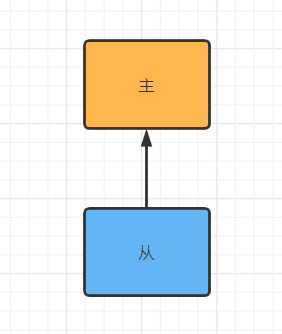
并不是从节点越多就越好,每个从节点都要备份主节点的数据,从节点越多,主节点的压力就越大,这样可以考虑一下结构:

搭建主从架构
redis搭建主从架构很简单的,修改下redis.conf配置,启动主从节点就ok了,步骤如下:
假设条件:服务器已经有redis包
1、复制一份redis.conf文件,目录随意
2、单机情况下修改端口号
# Accept connections on the specified port,default is 6379 (IANA #815344)
# If port 0 is specified Redis will not listen on a TCP socket.
port 6230 # 修改自己想要的
3、修改pid配置文件,可自己指定pid
# Creating a pid file is best effort: if Redis is not able to create it
# nothing bad happens, the server will start and run normally.
pidfile /var/run/redis_6230.pid
4、配置log文件
# output for logging but daemonize, logs will be sent to /dev/null
logfile "6230.log"
5、指定数据目录,默认当前目录
# Note that you must specify a directory here, not a file name.
dir /user/software/redis/redis-6230/data
6、注释掉bind
#bind 127.0.0.1
7、配置主从
replicaof <masterip> <masterport>
8、如果master有配置密码的话,则要配置slave的配置
# If the master is password protected (using the "requirepass" configuration
# directive below) it is possible to tell the replica to authenticate before
# starting the replication synchronization process, otherwise the master will
# refuse the replica request.
#
masterauth 888999
9、启动从节点
[root@iZwz9 redis-6230]# /redis/redis-6.0.9/src/redis-server redis-6230.conf
9、自己写一些数据测试,往master节点上写数据,看看replic节点是否有同步到数据。
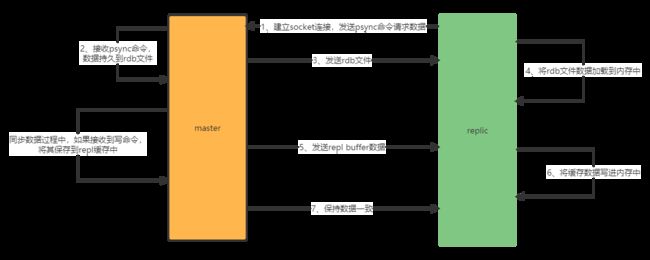
redis主从架构的工作流程:
1、从节点replica(slave)实例启动,请求socket连接主节点master
2、连上master后,发送psync命令请求同步数据
3、master接收到psync命令后,通过bgsave命令将数据持久化到rdb快照文件中,持久化完成后将数据文件发送给replica
3.1、master在数据持久化过程中,可以继续接收读写命令,并将写命令缓存下来
4、replica接收到数据文件后,将其加载到内存中
5、replica接收完文件后,master会将缓存中的数据发送给replica,同步完后数据保持一致性
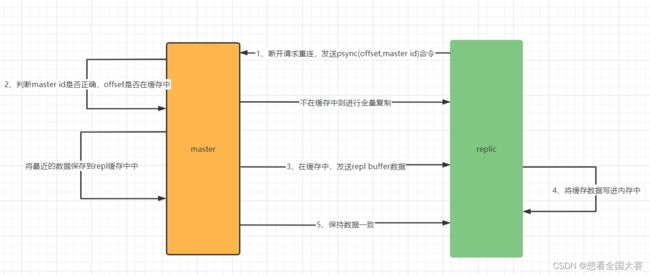
部分复制
当master与replica断开一小段时间又重连后,需要判断是否进行全量复制 or 部分复制。
步骤如下:
1、replica断开后请求重连,连接成功后发送psync命令,并携带offset和master id,offset是指replica副本已经复制的数据偏移下标。
2、master接收到psync命令,进行判断是全量还是部分复制。
– 2.1 判断master id是否是自己的id,不是则全量复制;
– 2.2 判断offset是否在repl buffer缓存里面,如果在,则从offset下标中进行复制,否则全量复制。
repl buffer: master会保存最近的数据到缓存该缓存中。
1、为了单机系统更稳定,又没有足够经费,则可以搭建主从架构。
2、主节点挂掉,从节点要想使用,得编写代码进行切换。
哨兵集群
思考:为何需要哨兵集群?
哨兵集群提供了更高可用的系统,能够监控系统的运行状态,当redis主节点挂掉了,能够检测到并选取从节点作为主节点,提高系统的健壮性。
redis增添了几个实例作为哨兵,哨兵并不会做任何读写操作,只是用来监控redis的主从架构运行状况。当主从架构中的主节点挂掉之后,哨兵们会监控到,并把从节点选取为主节点,架构如图:

当客户端访问集群时,集群会把主节点信息告知客户端,让客户端访问主节点,当主节点挂了重选举时,集群会更新元数据/集群信息并通知客户端,类似于消息订阅与发送功能,
哨兵集群也是使用主从架构。
半数决策:
当从节点发起成为主节点请求时,只有超过半数的哨兵节点同意从节点升主节点时,从节点才能成为主节点,假设我们搭建了3个节点的架构,发起选举请求时,有2个哨兵节点同意时,选举请求才成功,如果搭建了4个节点的架构,得3个节点同意才能选举成功,都是只能选举一次,所以都是建议搭建奇数节点的架构,能省一台节点的经费。
搭建哨兵集群的步骤也很简单,跟主从架构类似

我已经搭好了1主2从的架构了,在此基础上搭建哨兵集群。
步骤如下:
1、复制redis目录的sentinel.conf文件
![]()
[root@iZwz9a3e04j4x7s9jarg1iZ redis-conf]# ls
sentinel-26920.conf sentinel-26921.conf sentinel-26922.conf
2、修改配置信息:



sentinel monitor mastername 172.21.152.205 6291 2
# mastername 这个是哨兵集群的名,随意取,在java代码调用集群时用到
# 172.21.152.205 :如果是阿里云的话,使用外网ip
# 6291 主从架构中的主节点端口号
# 2 表示有两个哨兵节点认为master挂掉了之后,master节点才算是挂掉了
ps:当你修改了sentinel.conf里的集群名时,下面所有配置的集群名也要同步修改,如果有设置密码的话,也要打开密码设置
3、启动sentinel节点

4、连接sentinel节点查看相关信息
src/redis-cli -p 26960

搭建成功后,可以在sentinel的配置文件末尾中查看到集群信息:

试验一下:把主从架构中的master实例kill掉,看看能不能选举成功
连接6230,可以看到6230成为了master节点

从节点配置信息变了

可以看到,哨兵集群可以自主选举新master节点,但是在主节点挂掉,选举新节点这段时间里,集群是没法接收用户的请求的。
哨兵的选举
对于哨兵集群来说,并不是说一定要有多个的,即使只有一个leader的哨兵也是可以完成主从架构的从节点选举,案例里部署了三个,是为了让系统更加高可用,当有多个哨兵节点时,其中一个sentinel节点发现master下线了,可以发送信号给其他sentinel节点,让自己成功sentinel leader节点,获取超过半数以上的sentinel节点同意后,就可以成为leader节点,然后进行主从架构的故障转移工作,选举leader是先到先得的原则。
附上java测试代码
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>3.8.0version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-pool2artifactId>
dependency>
package com.ryoma.note.redis;
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPoolConfig;
import redis.clients.jedis.JedisSentinelPool;
import java.util.HashSet;
import java.util.Set;
// 测试哨兵集群
public class JedisSentinelDemo {
public static void main(String[] args) {
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(20);
config.setMinIdle(5);
config.setMaxIdle(10);
String masterName = "mastername";
// 设置sentinel节点
Set<String> sentinelSet = new HashSet<>();
sentinelSet.add(new HostAndPort("120.24.173.114", 26920).toString());
sentinelSet.add(new HostAndPort("120.24.173.114", 26921).toString());
sentinelSet.add(new HostAndPort("120.24.173.114", 26922).toString());
// 查看运行log可以发现:jedis是通过sentinel节点获取到redis的master节点信息,然后再连接master节点
// 使用阿里云的时候要避坑:避免寻找内网地址导致无法通信, 要填写外网地址
JedisSentinelPool sentinelPool = new JedisSentinelPool(masterName, sentinelSet, config, 3000, "88889999");
Jedis jedis = null;
try{
jedis = sentinelPool.getResource();
System.out.println(jedis.set("sentinel1", "1"));
System.out.println(jedis.get("sentinel1"));
}catch (Exception e){
e.printStackTrace();
}finally {
if (jedis != null){
jedis.close();
}
}
}
}
spring:
redis:
database: 0
timeout: 3000
password: 88889999
sentinel:
master: mastername
nodes: 120.24.173.114:26920,120.24.173.114:26921,120.24.173.114:26922
lettuce:
pool:
max-idle: 20
min-idle: 5
max-active: 30
max-wait: 1000ms
@SpringBootTest
@RunWith(SpringRunner.class)
@ContextConfiguration(classes = Aplication.class)
public class RedisTest {
@Autowired
private StringRedisTemplate redisTemplate;
@Test
public void testSpringBootAddRedis(){
redisTemplate.opsForValue().set("springboot:redis", "1");
}
}
cluster集群
哨兵集群的性能和高可用性等方面一般,比不上cluster集群,如图:

将一个个主从架构组成一个分布式架构,具备复制、分片和高可用的特性,可水平扩展,根据官方文档说可扩展上万个节点,但是建议不超过1000个节点,性能比哨兵集群强,
集群配置也简单。
我以上搭建的都是在一个机器上的伪集群
cluster集群至少需要3个节点,所以搭建一下3个一主一从的架构,步骤如下:
1、创建几个目录存放数据和配置文件, 配置文件复制主从里的redis.conf文件即可:
drwxr-xr-x 3 root root 18 Apr 10 01:05 cluster-6301
drwxr-xr-x 3 root root 18 Apr 10 01:05 cluster-6302
drwxr-xr-x 3 root root 18 Apr 10 01:05 cluster-6303
drwxr-xr-x 3 root root 18 Apr 10 01:05 cluster-6304
drwxr-xr-x 3 root root 18 Apr 10 01:05 cluster-6305
drwxr-xr-x 3 root root 18 Apr 10 01:05 cluster-6306
[root@iZwz9a3e04j4x7s9rg1iZ redis]# ls cluster-6301
data redis.conf
2、依次修改redis配置,搭配主从,案例使用6301-6302,6303-6304,6305-6306
# 1、存储数据目录
dir "/user/software/redis/cluster-6301/data"
# 2、端口
port 6301
# 3、关闭保护模式
protected-mode no
# 4、后台启动
daemonize yes
# 5、pid和log文件
pidfile "/var/run/redis_6301.pid"
logfile "/user/software/redis/redis-6.0.9/log/6301.log"
# 6、密码根据情况设置
requirepass
masterauth
# 7、集群配置
cluster-enabled yes
# 这里我踩了个坑,用绝对路径时,会报错
cluster-config-file redis-6301.conf
cluster-node-timeout 15000
# 8、依次启动redis服务
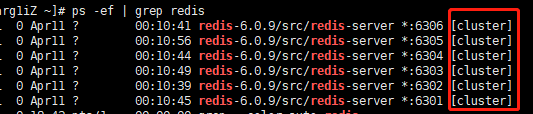
# 可以看到启动的服务有cluster标识。
# 9、使用redis-cli命令启动集群
src/redis-cli -a 88889999 --cluster create --cluster-replicas 1 120.24.173.114:6301 120.24.173.114:6302 120.24.173.114:6303 120.24.173.114:6304 120.24.173.114:6305 120.24.173.114:6306
# -a 表示连接密码
# --cluster-replicas 1 表示从节点的个数
# 可以看到以下创建成功的信息

# 10、验证集群情况,随意选择一个进行连接, -c表示集群方式启动
src/redis-cli -a 88889999 -c -h 120.24.173.114 -p 6301
6301> cluster nodes
6301> cluster info
# 11、关闭集群的时候则需要逐个关闭
src/redis-cli -a 88889999 -c -h 120.24.173.114 -p 6301 shutdown

示例代码跟sentinel的类似,就不贴了。
集群原理
可以看到上面的集群log中,给集群数据区分配了16384个slot槽位,根据master进行平均分配,比如6301端口的分配了0-5460的slot,slot的信息是存储在节点中的,当客户端进行连接时,也会获取slot的信息并缓存在本地中,当访问集群数据时,可以定位到对应slot位的节点。当客户端缓存和集群的不一样时,就需要纠正机制进行更正。slave节点不分配slot槽位。
-
如何进行槽位定位?
cluster集群会根据key进行crc16算法的转换,然后对16384取模得到一个槽位数:
hash_slot = crc16(key) mod 16384 -
跳转重定位
当我们客户端发送一个key获取数据时,如果发现数据不在该节点处,则会进行跳转,此时会携带目标节点的地址,重定向到目标节点上,如下图所示:

集群节点间是怎么进行通信的呢?
通常集群间的数据通信有2种方式:
- 集中式:
集群的元信息(节点ip,主从节点,slot信息等等)都是进行集中管理的,当有集群信息进行变更时,其他节点可以快速的获取到变更的信息,但是集中存储会造成一定的压力。 - gossip协议:
分布式的进行存储,当一个节点信息进行变更时,会按照一定的频率进行传输通知,A传B,B传C这样一节节的往下传,知道整个集群都通知完为止。元数据的更新比较分散,会有一点延时,但是会减少一定的压力
redis cluster节点间使用的是gossip协议进行通信:
gossip协议有多种消息传输方式:ping,pong,meet,fail等
- meet:某节点发送meet消息给新节点,让新节点加入集群中互相通信。
- ping:节点通过ping命令发送节点自身的状态给其他节点,相互交换信息,了解节点间的状态。
- pong:对meet和ping消息的回应,可以用于信息广播和更新。
- fail:当有节点发现另一个节点fail掉了,就会发送fail消息给其他节点。
每个节点间通信都是有端口的,gossip协议进行通信时,默认在当前节点的端口号上+10000,比如6301端口号的节点,则gossip协议给自己开通的端口号就是16301.
网络抖动
有时候我们的网络是不稳定的,这时候会导致通信不顺畅,如果不设置超时时间,则某节点因为网络抖动而联系不上另一个节点就认为该节点fail掉了,发起节点选举,这是很严重的问题,这样会频繁切换主从角色,导致部分数据的丢失。这时候就要设置cluster-node-timeout参数,避免该问题。
脑裂问题
因为网络或其他原因,导致主从切换,如果从节点的数据少于主节点时,主节点宕掉后变为从节点,则需要复制从节点的数据,这样原来的主节点中的新数据就会丢失,要避免这样的情况,可以设置如下配置:
min-replicas-to-write: 1 #配置最少写成功的slave节点数量,主从切换的时候,不会因为复制数据而导致数据丢失。提高一致性,减少可用性
在进行数据存储时,会发现我们的数据是不确定落到哪个节点的,当我们进行mset命令时,可能会分散数据到各个节点中,如果不想这种情况发生,则可以采用以下方式定义key:
在key前面加个{},里面配置一样的value,比如:
mset {name}:zhangsan 1 {name}:lisi 2
这样就会根据{name}去进行运算存储数据,能够保证数据落在同一个节点上。
cluster集群选举
1、当slave发现master宕机了,则会尝试进行failover,将自己记录的集群标记currentEpoch加1,并广播FAILOVER_AUTH_REQUEST信息。
2、只有master节点会接收该信息,并判断合理性(判断master是不是已经fail了),然后发送FAILOVER_AUTH_ACK响应,对每个epoch只发送一个ack。
3、进行failover的slave节点会收集ack,当超过半数的ack响应时,就会变成master,并pong消息广播其他集群节点。
当slave发现master failed了,并不会马上发起failover,而是会有一定的等待时间,这个等待时间跟slave节点的数据量有关,数据信息越新,则等待的时间就越短。所以一般拥有最多备份数据的slave节点会成为master节点。