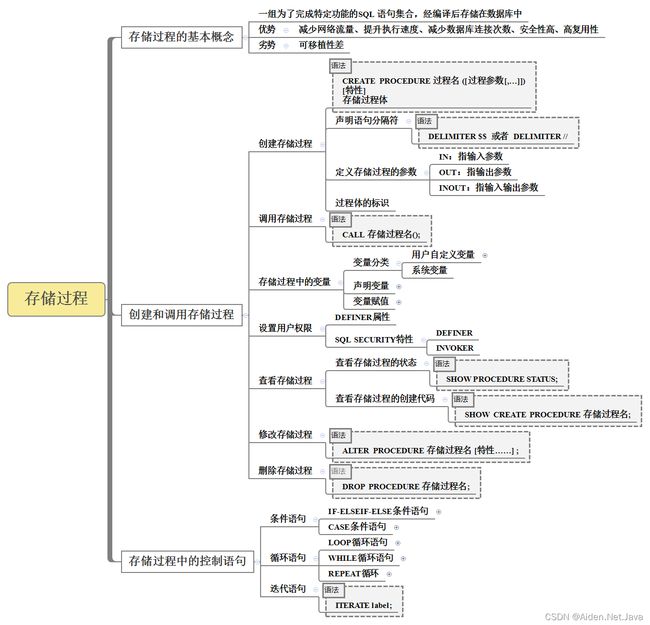
MySQL 05 存储过程
MySQL 05 存储过程
文章目录
- MySQL 05 存储过程
-
-
-
- 一、学习目标
- 二、存储过程
-
- 2.1为什么需要使用存储过程
- 2.2什么是存储过程
- 2.3存储过程的优缺点
- 三、创建存储过程
-
- 3.1语法与特性:
- 3.2声明语句分隔符
- 3.3过程体的标识
- 3.4存储过程参数设置
- 3.5创建、调用存储过程示例
- 四、存储过程中的变量
- 五、MySQL变量
- 六、用户变量在存储过程间传递
- 七、Navicat中创建、调用存储过程
- 八、设置用户执行存储过程的权限
- 九、查看存储过程的状态
-
- 查看数据库中已创建的存储过程
- 查看hosptal数据库中创建的存储过程
- 十、查看存储过程的创建代码
- 十一、修改存储过程
- 十二、删除存储过程
- 十三、存储过程的控制语句
- 十四、IF-ELSEIF-ELSE条件语句
- 十五、CASE条件语句
- 十六、WHILE循环语句
- 十七、LOOP循环语句
- 十八、REPEAT循环语句
- 十九、迭代语句
- 二十、本章总结
-
-
一、学习目标
- 理解存储过程的概念
- 会创建、修改、删除、查看存储过程
- 掌握存储过程的流程控制语句
二、存储过程
2.1为什么需要使用存储过程
问题:
- 网上书店应用中,不同出版社每月需要统计它的书籍销售情况,并希望将数据存储在临时表中进行分析。

基本步骤
- 使用DROP语句删除已有临时表数据
- 设置出版社名称
- 根据出版社名称查询获取出版社的编号
- 根据出版社编号查询当月销量数据,并使用查询结果创建新的临时表
分析:
- 每个步骤都需要执行一个SQL语句
- 查询不同出版社的书籍销量,需要动态设置出版社的名称
- 每个月都要执行相同的操作进行数据分析
- 为了更便捷地解决这个问题,可以使用MySQL的
存储过程2.2什么是存储过程
Stored Procedure
是一组为了完成特定功能的SQL 语句集合
经编译后保存在数据库中
通过指定存储过程的名字并给出参数的值
MySQL5.0版本开始支持存储过程,使数据库引擎更加灵活和强大
可带参数,也可返回结果
可包含数据操纵语句、变量、逻辑控制语句等

2.3存储过程的优缺点
优点
- 减少网络流量
- 提升执行速度
- 减少数据库连接次数
- 安全性高
- 复用性高
缺点
- 可移植性差
经验
- 在实际应用开发中,要根据业务需求决定是否使用存储过程,对于应用中特别复杂的数据处理,可以选用存储过程来进行实现
- 例如:复杂的报表统计,涉及多条件多表的联合查询等
三、创建存储过程
3.1语法与特性:
语法:
CREATE PROCEDURE 过程名 ([过程参数[,…]]) [特性] #可选项,用于设置存储过程的行为 存储过程体常用特性:
特性 说明 LANGUAGE SQL 表示存储过程语言,默认SQL {CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA} 表示存储过程要做的工作类别 默认值为CONTAINS SQL SQL SECURITY { DEFINER | INVOKER } 指定存储过程的执行权限 默认值是DEFINER •DEFINDER:使用创建者的权限 •INVOKER:用执行者的权限 COMMENT ‘string’ 存储过程的注释信息 示例:
- 编写存储过程,输出病人总人数
#如果存在则删除 drop procedure if exists proc_patient_countPatient; #创建存储过程 create procedure proc_patient_countPatient() begin #过程体开始 select count(0) as totalCount from patient; end #过程体结束问题:
- 编译器将其视为普通SQL语句进行处理,编译会报错,怎么办?
3.2声明语句分隔符
- 使用DELIMITER关键字将分隔符设置为“$$”或“//”
DELIMITER $$ #或者 DELIMITER //
- 还原为默认分隔符“;”
DELIMITER ;3.3过程体的标识
- 定义存储过程的过程体时,需要标识开始和结束
BEGIN # … END DELIMITER ; #END后,必须使用DELIMITER语句中设置的分隔符为结束注意事项:
//如果没有声明分隔符,编译器会将其视为普通SQL语句进行处理,编译过程会报错 //正确用法:首先用DELIMITER关键字声明当前段的分隔符,最后要将分隔符还原为默认字符示例:
#如果存在则删除 drop procedure if exists proc_patient_countPatient; delimiter// #声明分隔符 create procedure proc_patient_countPatient() begin #过程体开始 select count(0) as totalCount from patient; end// #过程体结束 delimiter; #恢复默认分割符 #调用 call proc_patient_countPatient();3.4存储过程参数设置
定义存储过程的参数
语法:
[IN | OUT | INOUT] 参数名 数据类型示例:
DELIMITER // #声明分隔符 CREATE PROCEDURE proc_patient_countPatient2(OUT patientNum INT) #省略... DELIMITER ; #恢复默认分隔符注意:
- 如果需要定义多个参数,需要使用“,”进行分隔
IN:指输入参数
- 该参数的值必须在调用存储过程时指定
- 存储过程中可以使用该参数,但它不能被返回
OUT:指输出参数
- 该参数可以在存储过程中发生改变,并可以返回
INOUT:指输入输出参数
- 该参数的值在调用存储过程时指定
- 在存储过程中可以被改变和返回
调用执行存储过程
CALL 存储过程名([参数1,参数2, …]);存储过程调用类似于Java中的方法调用
call proc_patient_countPatient();3.5创建、调用存储过程示例
- 使用存储过程查询获取并输出病人总人数
delimiter // create procedure proc_patient_countPatient2(out patientCount int) begin select count(0) into patientCount from patient; end // delimiter ; #调用并输出病人总数 call proc_patient_countPatient2(@patientCount); select @patientCount as '病人总数';
四、存储过程中的变量
- 与Java语言类似,定义存储过程时可以使用变量
DECLARE 变量名[,变量名...] 数据类型 [DEFAULT 值];
- 给变量进行赋值
SET 变量名 = 表达式值[,变量名=表达式...] ;
- 声明交易时间变量trade_time,并设置默认值为2020-07-10
DECLARE trade_time date DEFAULT '2020-07-10';
- 设置变量total的值为100
SET total=100;
- 注意事项:
定义存储过程时,所有局部变量的声明一定要放在存储过程体的开始;否则,会提示语法错误
五、MySQL变量
系统变量
- 指MySQL全局变量,以“@@”开头,形式为“@@变量名”
用户自定义变量
局部变量
- 一般用于SQL的语句块中,如:存储过程中的BEGIN和END语句块
- 作用域仅限于定义该变量的语句块内
- 生命周期也仅限于该存储过程的调用期间
- 在存储过程执行到END时,局部变量就会被释放
会话变量
- 是服务器为每个客户端连接维护的变量,与MySQL客户端是绑定的
- 也称作用户变量
- 可以暂存值,并传递给同一连接中其他SQL语句进行使用
- 当MySQL客户端连接退出时,用户变量就会被释放
- 用户变量创建时,一般以“@”开头,形式为“@变量名”
MySQL变量示例
需求:
- 创建存储过程,通过用户输入的科室编号和病人姓名,查询该病人在该科室最后一次的检查时间
分析:
- 输入参数:科室编号和病人姓名
- 输出参数:病人在该科室最后一次的检查时间
- 根据输入的参数值动态查询获取指定病人在该科室最后一次的检查时间
定义存储过程:
delimiter // create procedure proc_exam_GetLastExamDateByPatientNameAndDepID (in patient_name varchar(50), in dep_id int,out last_exam_date datetime) begin declare patient_id int; #声明局部变量 select patientid into patient_id from patient where patientname= patient_name; select patient_id; #输出病人的id #使用SELECT INTO语句可以一次给多个变量赋值 select max(examdate) into last_exam_date from prescription where patientid = patient_id and depid = dep_id; end // delimiter ;调用存储过程:
#设置用户变量@patientName为'夏颖' set @patientName='夏颖'; #设置用户变量@dep_id为1 set @dep_id=1; #调用存储过程 call proc_exam_GetLastExamDateByPatientNameAndDepID (@patientName,@dep_id,@last_exam_date); #输出病人在某科室最后一次检查时间 select @last_exam_date;
六、用户变量在存储过程间传递
用户变量不仅可以在存储过程内和MySQL客户端中设置,还可以在不同存储过程间传递值
- 创建存储过程proc1,设置用户变量并赋值为“王明”
- 创建另一个存储过程proc2,输出已赋值的用户变量信息
#用户变量在两个存储过程间的传递 #创建存储过程proc1 delimiter // create procedure `proc1`( ) begin set @name = '王明'; end // delimiter ; #创建存储过程proc2 delimiter // create procedure `proc2`( ) begin select concat('name:',@name); end // delimiter ;
七、Navicat中创建、调用存储过程
Navicat提供了良好的开发环境,比MySQL命令行操作更加便捷
创建和调用存储过程的基本步骤
创建存储过程
- 右键点击选定的数据库下的“函数”节点,在弹出的下拉菜单中选择“新建函数”
- 在右侧区域会自动创建存储过程模板,并在其中编写存储过程代码
运行存储过程
- 点击“保存”按钮,存储过程将自动保存在选定的数据库“函数”节点下
- 点击“运行”按钮调用存储过程
- 根据存储过程的定义,在弹出的对话框中输入设定的用户参数值
- 点击“确定”按钮,执行存储过程,并输出结果
注意事项:
存储过程模版自动增加DEFINER赋值语句
Navicat中,编写存储过程时不需使用DELIMITER声明新的分隔符
八、设置用户执行存储过程的权限
通过DEFINER和SQL SECURITY特性控制存储过程的执行权限
语法:
CREATE [DEFINER = { user | CURRENT_USER }] #定义DEFINER,默认为当前用户 PROCEDURE 存储过程名 [SQL SECURITY { DEFINER | INVOKER } | …]#指定DEFINER或INVOKER权限 BEGIN … ENDDEFINER
- 默认DEFINER = CURRENT_USER
- 检查 ‘user_name’@‘host_name’ 的权限
INVOKER
- 执行存储过程时,会检查调用者的权限
注意事项:
- 如果省略sql security特性,则使用definer属性指定调用者,且调用者必须具有EXECUTE权限,必须在mysql.user表中
- 如果将sql security特性指定为invoker,则definer属性无效
示例:
#对存储过程p1具有执行权限的用户可以调用它 create definer = 'admin'@'localhost' procedure p1() sql security definer begin update t1 set counter = counter + 1; end;
- ‘admin’@‘localhost’用户必须同时拥有p1的执行权限和对数据表t1的UPDATE权限,才能执行该存储过程;否则执行失败
#调用执行存储过程p2取决于调用者的权限 create definer = 'admin'@'localhost' procedure p2() sql security invoker begin update t1 set counter = counter + 1; end;
- 如果调用者没有存储过程的执行权限或没有对数据表t1的UPDATE权限,则存储过程调用失败
九、查看存储过程的状态
查看数据库中已创建的存储过程
语法:
show procedure status;查看hosptal数据库中创建的存储过程
#指定数据库名查询存储过程 show procedure status where DB = 'hospital';#使用LIKE关键字匹配存储过程名称 show procedure status like '%patient%';
十、查看存储过程的创建代码
查看数据库中已创建的存储过程代码
SHOW CREATE PROCEDURE 存储过程名;查看存储过程“proc_patient_countPatient”的创建代码
show create procedure proc_patient_countPatient;
十一、修改存储过程
使用ALTER PROCEDURE语句修改创建存储过程时定义的特性
ALTER PROCEDURE 存储过程名 [特性……] ;将存储过程proc_patient_countPatient的SQL SECURITY特性修改为INVOKER
alter procedure proc_patient_countPatient sql security invoker;经验
- 使用ALTER 关键字只能修改存储过程的特性,如果想修改存储过程中过程体的内容,需先删除该存储过程,再进行重新创建
- 在Navicat中,修改存储过程的内容后,可以直接保存
十二、删除存储过程
使用DROP PROCEDURE语句删除已创建的存储过程
DROP PROCEDURE 存储过程名;删除已创建的存储过程proc_patient_countPatient
drop procedure if exists;注意:
- 创建存储过程前,可以使用IF EXISTS语句检查其是否已存在,如果不存在,再进行创建
十三、存储过程的控制语句
与Java语言的流程控制语句类似,MySQL提供的控制语句
条件语句
- IF-ELSEIF-ELSE条件语句
- CASE条件语句
循环语句
- WHILE循环
- LOOP循环
- REPEAT循环
迭代语句
十四、IF-ELSEIF-ELSE条件语句
语法:
IF 条件 THEN 语句列表 [ELSEIF 条件 THEN 语句列表] [ELSE 语句列表] END IF;示例:
- 根据病人的家庭收入,返还补贴不同比例的医疗费用
- 家庭年收入在5000元以下的返还当年总医疗费用的20%
- 家庭年收入在10000以下的返还当年总医疗费用的15%
- 家庭年收入在30000以下的返还总医疗费用的5%
- 30000元以上或未登记的不享受医疗费用返还
- 输入病人编号和年份,计算该患者当年的应返还的医疗费用
#示例10:计算病人获得的返还医疗费用 create definer=`root`@`localhost` procedure `proc_income_calSubsidy` (in i_patientid int ,in i_year varchar(10), out o_subsidy float) begin declare t_totalCost float; declare t_income float default -1; select sum(checkItemCost) into t_totalCost from prescription p1 inner join checkitem on p1.checkItemID = checkitem.checkItemID where patientID = i_patientID and examDate >= concat(i_year,'-01-01') and examDate <= concat(i_year,'-12-31'); select income into t_income from subsidy where patientID = i_patientID; #根据规则计算返还金额 if t_income >=0 and t_income < 5000 then set o_subsidy = t_totalcost * 0.2; elseif t_income >= 5000 and t_income < 10000 then set o_subsidy = t_totalcost * 0.15; elseif t_income >= 10000 and t_income < 30000 then set o_subsidy = t_totalcost * 0.05; else set o_subsidy = 0; end if; end
十五、CASE条件语句
语法1:
CASE WHEN 条件 THEN 语句列表 [WHEN 条件 THEN 语句列表] [ELSE 语句列表] END CASE;语法2:
CASE 列名 WHEN 条件值 THEN 语句列表 [WHEN 条件值 THEN 语句列表] [ELSE 语句列表] END CASE;示例:
#示例11:使用CASE实现计算病人获得的返还医疗费用 create definer=`root`@`localhost` procedure `proc_income_calsubsidy` (in i_patientid int ,in i_year varchar(10), out o_subsidy float) begin declare t_totalcost float; declare t_income float default -1; select sum(checkitemcost) into t_totalcost from prescription p1 inner join checkitem on p1.checkitemid = checkitem.checkitemid where patientid = i_patientid and examdate >= concat(i_year,'-01-01') and examdate <= concat(i_year,'-12-31'); select income into t_income from subsidy where patientid = i_patientid; #根据规则计算返还金额 case when t_income >=0 and t_income < 5000 then set o_subsidy = t_totalcost * 0.2; when t_income < 1000 then set o_subsidy = t_totalcost * 0.15; when t_income < 30000 then set o_subsidy = t_totalcost * 0.05; when t_income >= 30000 or t_income < 0 then set o_subsidy = 0; end case; end注意:在某种情况下(例如,做等值判断),使用第二种写法更加简洁但是,因为CASE后面有列名,功能上会有一些限制
十六、WHILE循环语句
首先判断条件是否成立。如果成立,则执行循环体
[label:] WHILE 条件 DO 语句列表 END WHILE [label]
- label为标号,用于区分不同的循环,可省略
- 用在begin、repeat、while 或者loop 语句前
假设有测试表test,有Id字段、Val字段
根据输入的行数要求,批量插入测试数据
十七、LOOP循环语句
不需判断初始条件,直接执行循环体
[label:] LOOP 语句列表 END LOOP [label] ;遇到LEAVE语句,退出循环
leave lable示例:
- 检查项目,检查项目名称为胃镜、肠镜和支气管纤维镜,各批量插3个新的项检查的价格均为70元
分析:
- 使用字符串保存多个检查项目名称,作为存储过程输入参数
- 检查项目名称之间通过逗号“,”进行分隔
LEAVE语句离开label标号所标识的程序块,类似于Java的break语句
#示例13:批量添加检查项目 create definer=`root`@`localhost` procedure `proc_checkitem_insert` ( in checkitems varchar(100)) begin declare comma_pos int; declare current_checkitem varchar(20); loop_label: loop set comma_pos = locate(',', checkitems); set current_checkitem = substr(checkitems, 1, comma_pos-1); if current_checkitem <> '' then set checkitems = substr(checkitems, comma_pos+1); else set current_checkitem = checkitems; end if; insert into checkitem(checkitemname,checkitemcost) values(current_checkitem,70); if comma_pos=0 or current_checkitem='' then leave loop_label; end if; end loop loop_label; end
十八、REPEAT循环语句
先执行循环操作再判断循环条件
#与Java的do-while循环语句类似 [label:] REPEAT 语句列表 UNTIL 条件 END REPEAT [label]与LOOP循环语句相比较
- 相同点:不需要初始条件直接进入循环体
- 不同点:REPEAT语句可以设置退出条件
使用REPEAT循环语句编码实现
- 根据输入的行数要求,向测试表test中批量插入测试数据
十九、迭代语句
从当前代码处返回到程序块开始位置,重新执行
ITERATE label;
- ITERATE关键字可以嵌入到LOOP、WHILE和REPEAT程序块中
输入需增加数据行数,随机产生的测试数据必须大于0.5
delimiter // create definer=`root`@`localhost` procedure `proc_test_insert2`( in rows int) begin declare rand_val float; loop_label:while rows > 0 do select rand() into rand_val; if rand_val<0.5 then iterate loop_label; end if; insert into test values(null, rand_val); set rows = rows - 1; end while loop_label; end // delimiter ;