【Linux】Ⅷ基础网络:应用层之HTTP协议
自定义协议(TCP粘包问题)
-
自定制协议:就是在应用层对要传输的数据,进行数据格式的约定,消息的发送方和接收方都遵守该约定
- 自定制协议是工作在应用层,被程序员定义出来的协议
对于应用层调用send接口,只是负责将数据放到TCP的发送缓冲区当中,至于TCP如何发送和之前应用层的发送规律没有任何关系
3. TCP特性:面向字节流
面向字节流好处是对于数据可以灵活的发送和接收,但是也带来了TCP粘包的问题,(对于消息的接收方而言,就不好区分,客户端应用层发送的每一条数据)比如第一次客户端发送l+1第二次发送2+2,但是在接受方看来是粘连在一起的变成了1+12+2
如何解决TCP粘包问题?
1. 按照数据长度来解决通信双方约定数据长度
传输定长数据可以稍微解决tcp粘包问题,但是不能应对复杂情况,例如,一个通信连接当中,有多个定长的数据结构或者没有定长的数据结构
2. 对于tcp粘包问题,我们需要在应用层自定制协议,自定制协议可以增加报头和分隔符
- 【定长报头(数据长度)】+数据
- 【定长报头】+数据+分隔符
- 【不定长的报头】+数据+分隔符
- 【不定长的报头】+数据+分隔符
- 对于定长报头而言,数据的双发都是遵守这样的约定的。
- 对于不定长的报头,由于数据也不是定长,所以引入分隔符,而分隔符在这里面起到的左右是标识当前数据的尾部。
- 当我们接收方和发送方都严格按照自定制协议进行传输的时候,TCP连接当中传输TCP数据都是【报头】+数据+分隔符的方式,所以,找到分隔还可以找到下一条数据的开始。
- 分隔符不一定就是一个字节的字符,可以是一个字符串,通常情况下工业上都是使用\r\n来进行分隔;分隔符其实起到了一个定义数据边界的作用;
序列化:将对象转化成为二进制(字节序列)的过程
反序列化:将二进制(字节序列)转化成为对象的过程
HTTP协议——超文本传输协议
认识URL
URL:http://user:[email protected]:80/dir/index.htm?id=1&wd=C%2B%2B#ch1
1. http://——协议方案名
2. user:passwd——用户名和密码
3. www.baidu.com——域名(服务器的ip地址)
4. 80——服务端侦听端口,http用的是80端口,https用的是443端口
5. /dir/index.htm——带层次的文件路径也就是浏览器要请求的资源路径,“/”并不是linux操作系统当中的根目录,而是http服务器定义的逻辑上的根目录
6. id=1&wd=C%2B%2B——查询字符串,浏览器给http服务器提交的数据
- 提交的单个数据是按照key=value的形式,多个数据中间使用&进行分隔;
- 在提交的数据当中如果不加以区分,有可能造成歧义,例如说,+C++;在传输特殊字符的时候,需要进行url编码(urlencode),编码的方式就是将特殊的字符按照16进制进行传输;为了区别编码之后的字符,需要在编码之后的内容前面加上%,用来区分;
- 对于服务器而言,在接收到url编码之后的查询字符串,需要进行url解码。(urldecode)
7. ch1——片段标识符,表示当前页面被浏览器加载之后,定位到什么位置了
HTTP协议数据包格式
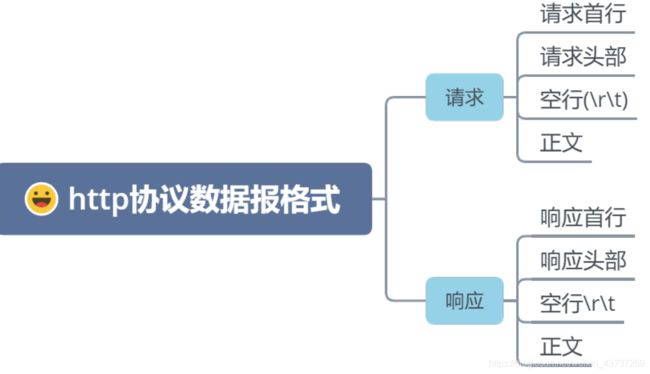
请求报文
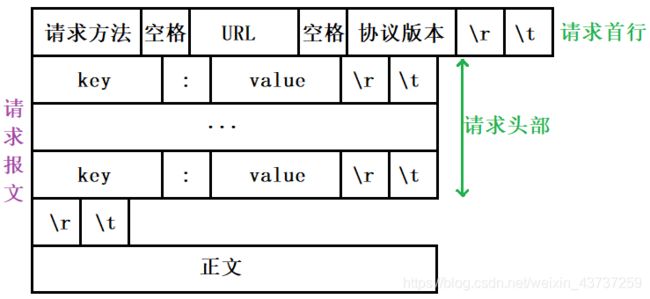
请求首行——请求方法 URL 协议版本 \r\t
1. 请求方法
GET:从服务器上面获取一个资源的方法,GET从服务器获取数据,但是现在也可以给服务器去提交key=value形式的数据,只不过提交的数据是在ur1当中的
POST:向服务器提交数据的方法,POST提交数据是在正文当中
POST方法比GET方法更加私密,想要更加安全,则需要ssl加密

2. 协议版本(现有HTTP/1.0、HTTP/1.1、HTTP/2三个版本)
请求头部——具有多行数据,每行数据都是一个key:value的形式,每行数据使用\r\n进行分隔
1. Content-Length:正文长度,防止粘包
2. Content-Type:正文的编码格式
- text/html:HTML格式
- application/json:json数据格式
- text/plain:纯文本格式
- application/msword:word文档格式’
- text/png:png图片格式
3. referer:当前的页面是从哪一个页面跳转过来的
4. Cookie:向服务器提交浏览器本地保存的认证信息,认证信息是之前登陆服务器的时候,服务器返回回来的
5. Tranfer-Encoding:针对于正文而言,可以支持分块传输
6. Location:和重定向搭配使用,http服务器会告诉浏览器,刚刚请求的页面应该去哪一个地址上面重新申请下
7. User-Agent:生命操作系统和浏览器版本信息
8. Connection:keep-alive 保持长连接
9. Accept-Encoding:能够接收的编码格式
10. Accept-Language:能够接收的语言
http协议应用协议,传输层使用的是tcp协议,早期http是无状态的协议,使用的tcp短连接
响应报文
响应首行——协议版本 状态码 状态码解释\r\n
- 1XX:接收到请求正在处理;
- 2XX:请求正常处理完毕了;eg:200OK
- 3XX:重定向状态,表示浏览器需要进行附加操作,才能完成刚才的请求操作;eg:302临时重定向
- 4XX:服务器无法处理这个请求;eg,404 Page Not Found
- 5XX:服务器处理出错了;eg 502 Bad Gateway
响应头部
响应头部当中也是具有多行数据,每行数据是key:value的形式,行与行之间使用\r\n进行分隔;响应头部的字段也是和请求头部大同小异。
总结
1. http协议是应用层的协议,在传输层使用tCp协议,在网络层使用ip协议
2. htp本身是为了处理大量的请求,设计在传输层使用tCp连接为短连接
3. 目前http已经支持了长连接
4. http是没有加密版本的http协议,加密版本可以使用https,s代表ssl:非对称加密
面试重点
1. get和post的区别
Get 方法的含义是请求从服务器获取资源,这个资源可以是静态的文本、页面、图片视频等。
比如,打开微信公众号的文章,浏览器就会发送GET请求给服务器,服务器就会返回文章的所有文字及资源。
而POST 方法则是相反操作,它向URL指定的资源提交数据,数据就放在报文的body里。
比如,在公众号文章底部,敲入了留言后点击[提交],浏览器就会执行一次POST请求,把留言的文字放进了报文body里,然后拼接好POST请求头,通过TCP协议发送给服务器。
在HTTP协议里,所谓的「安全」,是指请求方法不会[破坏]服务器上的资源。
所谓的「幂等」,意思是多次执行相同的操作,结果都是「相同」的。
那么很明显GET方法就是安全且幂等的,因为它是只读操作,无论操作多少次,服务器上的数据都是安全的,且每次的结果都是相同的。
POST因为是「新增或提交数据」的操作,会修改服务器上的资源,所以是不安全的,且多次提交数据就会创建多个资源,所以不是幂等的。
还有一个区别:
GET产生一个TCP数据包;POST产生两个TCP数据包。
具体来说:
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200 ok(返回数据);
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
也就是说,GET只需要汽车跑一趟就把货送到了,而POST得跑两趟,第一趟,先去和服务器打个招呼“嗨,我等下要送一批货来,你们打开门迎接我”,然后再回头把货送过去。
2. 浏览器输入URL后的流程
3. 长连接短连接区别及其应用场景
长连接与短连接:
- 长连接:client方与server方先建立连接,连接建立后不断开,然后再进行报文发送和接收。这种方式下由于通讯连接一直存在。此种方式常用于P2P通信。
- 短连接:Client方与server每进行一次报文收发交易时才进行通讯连接,交易完毕后立即断开连接。此方式常用于一点对多点通讯。
长连接与短连接的操作过程:
- 短连接的操作步骤是:建立连接——数据传输——关闭连接...建立连接——数据传输——关闭连接
- 长连接的操作步骤是:建立连接——数据传输...(保持连接)...数据传输——关闭连接
长连接与短连接的使用时机:
- 短连接多用于操作频繁,点对点的通讯,而且连接数不能太多的情况。每个TCP连接的建立都需要三次握手,每个TCP连接的断开要四次握手。
- 对于长连接,如果每次操作都要建立连接然后再操作的话处理速度会降低,所以每次操作下次操作时直接发送数据就可以了,不用再建立TCP连接。
应用场景:
数据库的连接用长连接,如果用短连接频繁的通信会造成socket错误,频繁的socket创建也是对资源的浪费。
短连接:web网站的http服务一般都用短连接。因为长连接对于服务器来说要耗费一定的资源。像web网站这么频繁的成千上万甚至上亿客户端的连接用短连接更省一些资源。
试想如果都用长连接,而且同时用成千上万的用户,每个用户都占有一个连接的话,可想而知服务器的压力有多大。所以并发量大,但是每个用户又不需频繁操作的情况下需要短连接。总之:长连接和短连接的选择要视需求而定。
4. HTTP网络状态码,403和404
1. 1XX:接收到请求正在处理;
2. 2XX:请求正常处理完毕了;
200 OK是最常见的成功状态码,表示一切正常。
3. 3XX:重定向状态,表示浏览器需要进行附加操作,才能完成刚才的请求操作;
301 Moved Permanently表示永久重定向,说明请求的资源已经不存在了,需改用新的URL再次访问。
302 Found表示临时重定向,说明请求的资源还在,但暂时需要用另一个URL来访问。
4. 4XX:服务器无法处理这个请求;
403 Forbidden表示服务器禁止访问资源,并不是客户端的请求出错。
404Not Found表示请求的资源在服务器上不存在或未找到,所以无法提供给客户端。
5. 5XX:服务器处理出错了;
502 Bad Gateway 通常是服务器作为网关或代理时返回的错误码,表示服务器自身工作正常,访问后端服务器发生了错误。
5. http的请求方式
get和put具体见上。

6. HTTP请求包含哪些部分
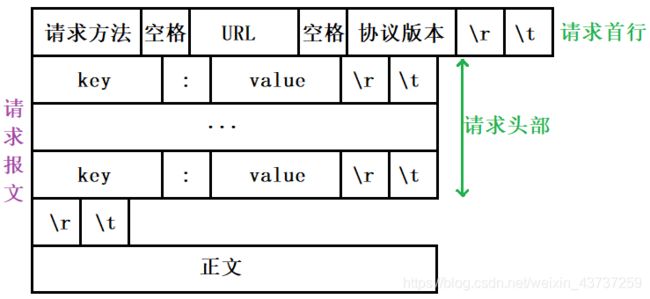
7. HTTP和HTTPS的区别
1. HTTP是超文本传输协议,信息是明文传输,存在安全风险的问题。HTTPS则解决HTTP不安全的缺陷,在TCP和HTTP网络层之间加入了SSL/TLS安全协议,使得报文能够加密传输。
2. HTTP连接建立相对简单,TCP三次握手之后便可进行HTTP的报文传输。而HTTPS在TCP三次握手之后,还需进行SSL/TLS的握手过程,才可进入加密报文传输。
3. HTTP的端口号是80,HTTPS的端口号是443。
4. HTTPS协议需要向CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的。
8. keep-alive在HTTP请求的哪个部分
请求报文的请求头部,以key:value的形式存储,Connection:keep-alive 保持长连接
9. 为什么https是更可靠的,只有非对称加密么
HITTPS采用的是对称加密和非对称加密结合的「混合加密」方式:
- 在通信建立前采用非对称加密的方式交换「会话秘钥」,后续就不再使用非对称加密。
- 在通信过程中全部使用对称加密的「会话秘钥」的方式加密明文数据。
采用「混合加密」的方式的原因:
- 对称加密只使用一个密钥,运算速度快,密钥必须保密,无法做到安全的密钥交换。
- 非对称加密使用两个密钥:公钥和私钥,公钥可以任意分发而私钥保密,解决了密钥交换问题但速度慢。
10. HTTP1.0和HTTP2.0的区别
- HTTP/2采用二进制格式而非文本格式
- HTTP/2是完全多路复用的,而非有序并阻塞的——只需一个连接即可实现并行
- 使用报头压缩,HTTP/2降低了开销
- HTTP/2让服务器可以将响应主动“推送”到客户端缓存中
11. 应用层的协议有哪些
三种常见的应用层协议:HTTP超文本传输协议、FTP 文件传输协议、SMTP简单邮件传输协议