【Flink Scala】Process Function API(底层)
Process Function API(底层)
- Process Function API(底层)
-
- Keyed Process Function
- Timer Service和定时器(Timers)
- 侧输出流(Side Output)
Process Function API(底层)
我们之前学习的转换算子是无法访问事件的时间戳信息和水位线信息的。而这 在一些应用场景下,极为重要。例如MapFunction这样的map转换算子就无法访问 时间戳或者当前事件的事件时间。
基于此,DataStream API提供了一系列的Low-Level转换算子。可以访问时间戳、watermark以及注册定时事件。还可以输出特定的一些事件,例如超时事件等。 Process Function用来构建事件驱动的应用以及实现自定义的业务逻辑(使用之前的 window函数和转换算子无法实现)。例如,Flink SQL就是使用 Process Function实现的。
ProcessFunction可以看作是最底层的API
Flink提供了 8 个 Process Function:
-
ProcessFunction -
KeyedProcessFunction -
CoProcessFunction -
ProcessJoinFunction -
BroadcastProcessFunction -
KeyedBroadcastProcessFunction -
ProcessWindowFunction -
ProcessAllWindowFunction
Keyed Process Function
这里我们重点介绍 KeyedProcessFunction。
KeyedProcessFunction用来操作 KeyedStream。KeyedProcessFunction 会处理流 的每一个元素,输出为 0 个、1 个或者多个元素。所有的 Process Function 都继承自RichFunction 接口,所以都有 open()、close()和 getRuntimeContext()等方法。而 KeyedProcessFunction[KEY, IN, OUT]还额外提供了两个方法:
-
processElement(v: IN, ctx: Context, out: Collector[OUT]), 流中的每一个元素 都会调用这个方法,调用结果将会放在Collector数据类型中输出。Context可以访问元素的时间戳,元素的key,以及TimerService时间服务。Context还可以将结果输出到别的流(side outputs)。 -
onTimer(timestamp: Long, ctx: OnTimerContext, out: Collector[OUT])是一个回 调函数。当之前注册的定时器触发时调用。参数timestamp为定时器所设定 的触发的时间戳。Collector为输出结果的集合。OnTimerContext和processElement的Context参数一样,提供了上下文的一些信息,例如定时器 触发的时间信息(事件时间或者处理时间)。
自定义一个KeyedProcessFunction
/**
* 三个参数是:key的数据类型
* 输入的数据类型
* 输出的数据类型
*/
class MyKeyedProcessFunction extends KeyedProcessFunction[String, SensorReading, String] {
var myState: ValueState[Int] = _
override def open(parameters: Configuration): Unit = {
myState = getRuntimeContext.getState(new ValueStateDescriptor[Int]("valueState", classOf[Int]))
}
override def processElement(i: SensorReading, context: KeyedProcessFunction[String, SensorReading, String]#Context,
collector: Collector[String]): Unit = {
//获取当前的key,其实还可以直接从数据里面获取
context.getCurrentKey
//获取当前数据的时间戳
context.timestamp()
//获取当前的watermark
context.timerService().currentWatermark()
/**
* 定义一个一分钟后触发的定时器,当定时器触发后,会执行onTimer方法
* 可以注册多个定时器,定时器的区别就是时间戳
* 不同的定时器执行时都是在onTimer方法里面
*/
context.timerService().registerEventTimeTimer(context.timestamp() + 60 * 1000l)
/**
* 定时器的删除,删除也是传入一个参数,参数就是时间戳
*/
// context.timerService().deleteEventTimeTimer()
}
/**
*
* @param timestamp是定时器触发的时间 ,我们可以将根据不同的时间戳来判断不同的定时器,然后执行不一样的方法
* @param ctx
* @param out
*/
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[String, SensorReading, String]#OnTimerContext
, out: Collector[String]): Unit = {
}
}
可以大概的认为可以在ProcessFunction中做任何的操作
在创建多个定时器的时候,他们是依靠输入的时间戳来彼此间区分的,但是不论多少个定时器,最后都是在onTimer方法里来执行,onTimer方法里的timestamp就是定时器触发时的时间戳,可以依靠这个来区分不同的定时器
跳转顶部
Timer Service和定时器(Timers)
Context 和 OnTimerContext 所持有的 TimerService 对象拥有以下方法:
currentProcessingTime(): Long返回当前处理时间
currentWatermark(): Long返回当前 watermark的时间戳
registerProcessingTimeTimer(timestamp: Long): Unit会注册当前 key 的 processing time的定时器。当 processing time到达定时时间时,触发 timer。
registerEventTimeTimer(timestamp: Long): Unit会注册当前 key的 event time定时器。当水位线大于等于定时器注册的时间时,触发定时器执行回调函数。
deleteProcessingTimeTimer(timestamp: Long): Unit 删除之前注册处理时间定 时器。如果没有这个时间戳的定时器,则不执行。
deleteEventTimeTimer(timestamp: Long): Unit删除之前注册的事件时间定时 器,如果没有此时间戳的定时器,则不执行。 当定时器timer触发时,会执行回调函数 onTimer()。注意定时器timer只能在keyed streams上面使用。
下面举个例子说明 KeyedProcessFunction如何操作KeyedStream。 需求:监控温度传感器的温度值,如果温度值在指定时间内之内(processing time)连 续上升,则报警
我们现需要思考该如何实现此功能,如果我们使用窗口来完成操作就会出现以下的问题
使用时间滚动窗口函数所带来的问题,我们假设红框是一个窗口,在下图中,每一个窗口中都是连续上升的,但是两个窗口的首尾却不是,该如何解决?
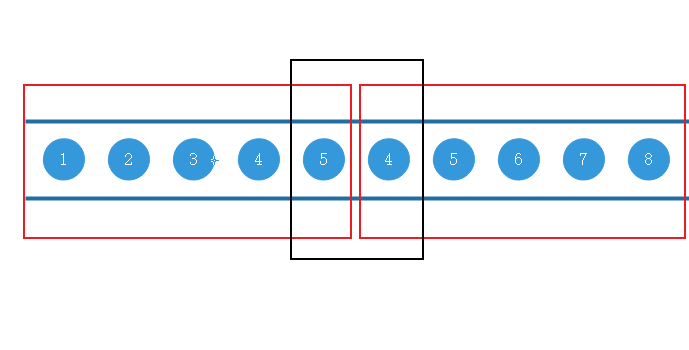
虽然滑动窗口可以稍微解决一些首尾不连续上升的问题,但是当数据量十分庞大是,我们该如何确定每次的滑动值?
所以我们应该换种方式,可以使用定时器的方式,当数据上升且没创建定时器时(保证只有一个定时器),创建一个定时器;当数据温度下降时,删除定时器
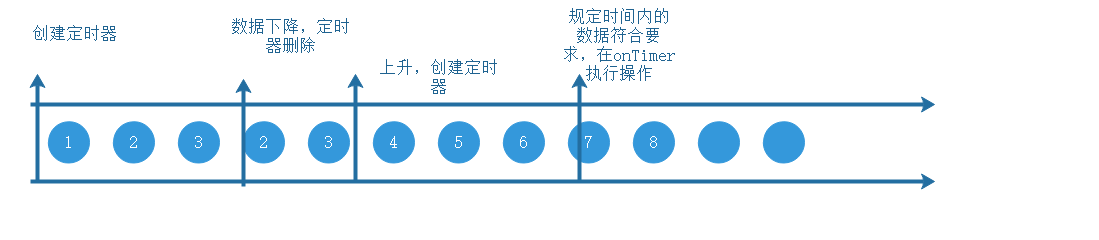
class TempIncreWarning(interval: Long) extends KeyedProcessFunction[String, SensorReading, String] {
//定义状态,保留上一个温度值
lazy val lastTempState: ValueState[Double] = getRuntimeContext.getState(
new ValueStateDescriptor[Double]("lastTemp", classOf[Double]))
//保存定时器的时间戳用于删除
lazy val timerTsState: ValueState[Long] = getRuntimeContext.getState(
new ValueStateDescriptor[Long]("ts", classOf[Long]))
override def processElement(i: SensorReading, context: KeyedProcessFunction[String, SensorReading, String]#Context,
collector: Collector[String]): Unit = {
//先取出状态
val lastTemp = lastTempState.value()
val timerTs = timerTsState.value()
/**
* 判断当前温度和上次温度的大小
* 只有当温度上升,时间状态为0的时候才注册定时器(时间状态为0只有两种可能:一:第一条数据的输入,二:温度不满足连续升温的条件)
*
*/
if (i.temperature > lastTemp && timerTs == 0) {
val ts = context.timerService().currentProcessingTime() + interval //获取当前时间加上时间间隔参数的时间
context.timerService().registerProcessingTimeTimer(ts) //注册一个时间定时器
timerTsState.update(ts) //更新时间状态的数据
} else if (i.temperature < lastTemp) {
//温度下降,删除定时器
context.timerService().deleteProcessingTimeTimer(timerTs)
//更新状态
timerTsState.clear()
}
lastTempState.update(i.temperature) //更新温度
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[String, SensorReading, String]#OnTimerContext,
out: Collector[String]): Unit = {
out.collect("传感器" + ctx.getCurrentKey + "的温度连续" + interval / 1000 + "秒连续上升")
//清空时间戳状态
timerTsState.clear()
}
}
自定义定时器的使用
package ProcessFunctionTest
import Source.SensorReading
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.util.Collector
/**
* 十秒钟内温度连续上升的话就发出警报
* 当数据上升时注册一个定时器,判断十秒内数据是否是全部上升的
* 该如何判断十秒内的数据全部上升?
* 保留前一秒的数据,然后与当前数据比较,现在的温度必须大于前面的温度
*/
object TimeServer {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val inputStream = env.socketTextStream("localhost", 7777)
//转换成样例类
val dataStream = inputStream
.map(data => {
val arr = data
.split(",")
SensorReading(arr(0), arr(1).toLong, arr(2).toDouble)
})
val warningStream = dataStream
.keyBy(_.id)
.process(new TempIncreWarning(5000l))
warningStream.print()
env.execute()
}
}
运行结果

跳转顶部
侧输出流(Side Output)
大部分的DataStream API的算子的输出是单一输出,也就是某种数据类型的流。 除了 split算子,可以将一条流分成多条流,这些流的数据类型也都相同。process function 的side outputs功能可以产生多条流,并且这些流的数据类型可以不一样。 一个side output可以定义为 OutputTag[X]对象,X是输出流的数据类型。process function可以通过 Context对象发射一个事件到一个或者多个side outputs
侧输出流只要自定义一个基本的ProcessFunction即可
/**
* 自定义ProcessFunction,来进行分流
* 这边定义的输出类型时主流的输出类型
*
* @param threshold
*/
class SplitTempProcessor(threshold: Double) extends ProcessFunction[SensorReading, SensorReading] {
override def processElement(i: SensorReading, context: ProcessFunction[SensorReading, SensorReading]#Context,
collector: Collector[SensorReading]): Unit = {
if (i.temperature > 30) {
//高温流,输出到主流
collector.collect(i)
} else {
//输出到测输出流
context.output(new OutputTag[(String, Long, Double)]("low"), (i.id, i.timeStamp, i.temperature))
}
}
}
侧输出流的使用
package ProcessFunctionTest
import Source.SensorReading
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
/**
* 侧输出流
*/
object SidOutPutTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val inputStream = env.socketTextStream("localhost", 7777)
//转换成样例类
val dataStream = inputStream
.map(data => {
val arr = data
.split(",")
SensorReading(arr(0), arr(1).toLong, arr(2).toDouble)
}).keyBy(_.id)
//分流
val highTempStream = dataStream
.process(new SplitTempProcessor(30.0))
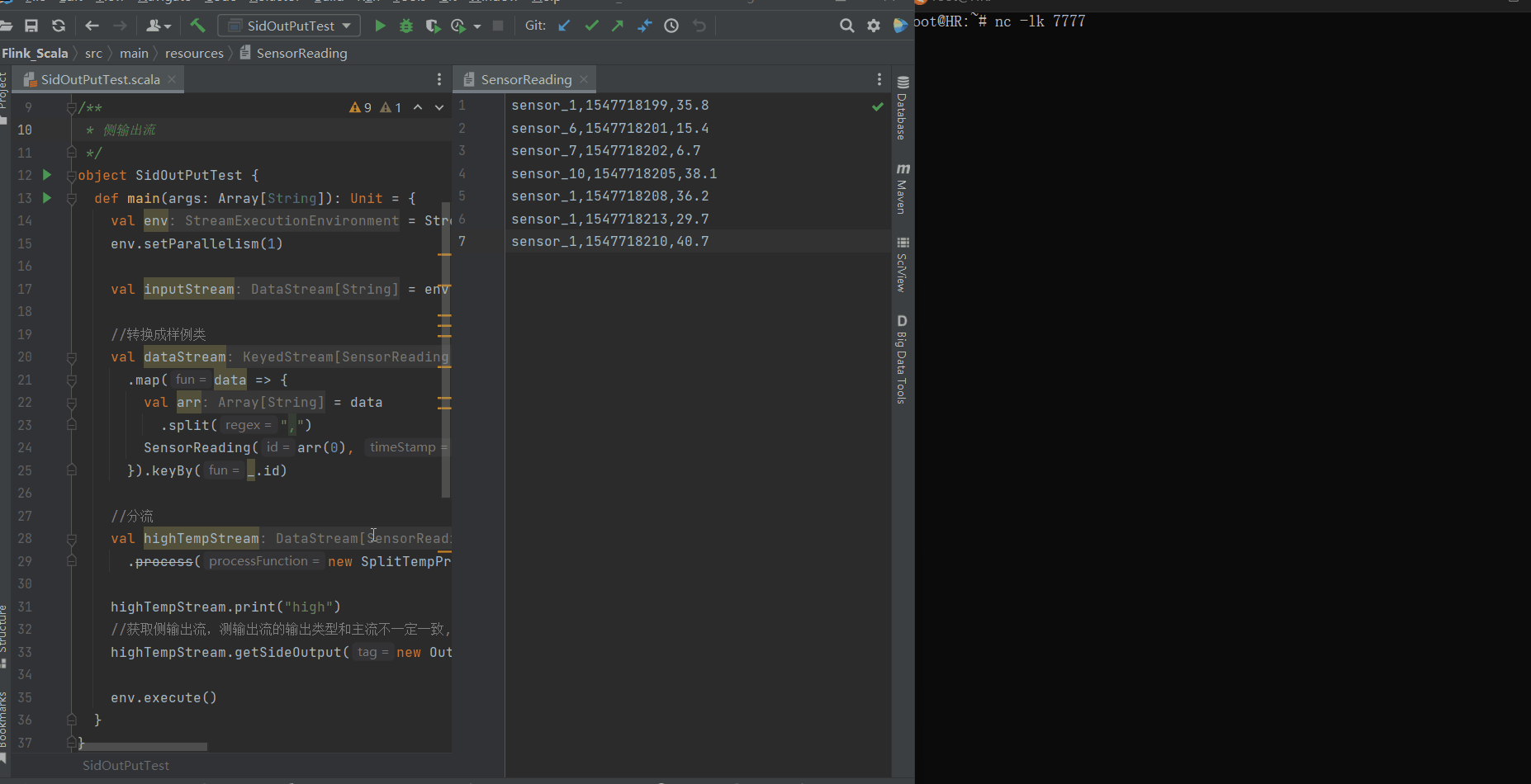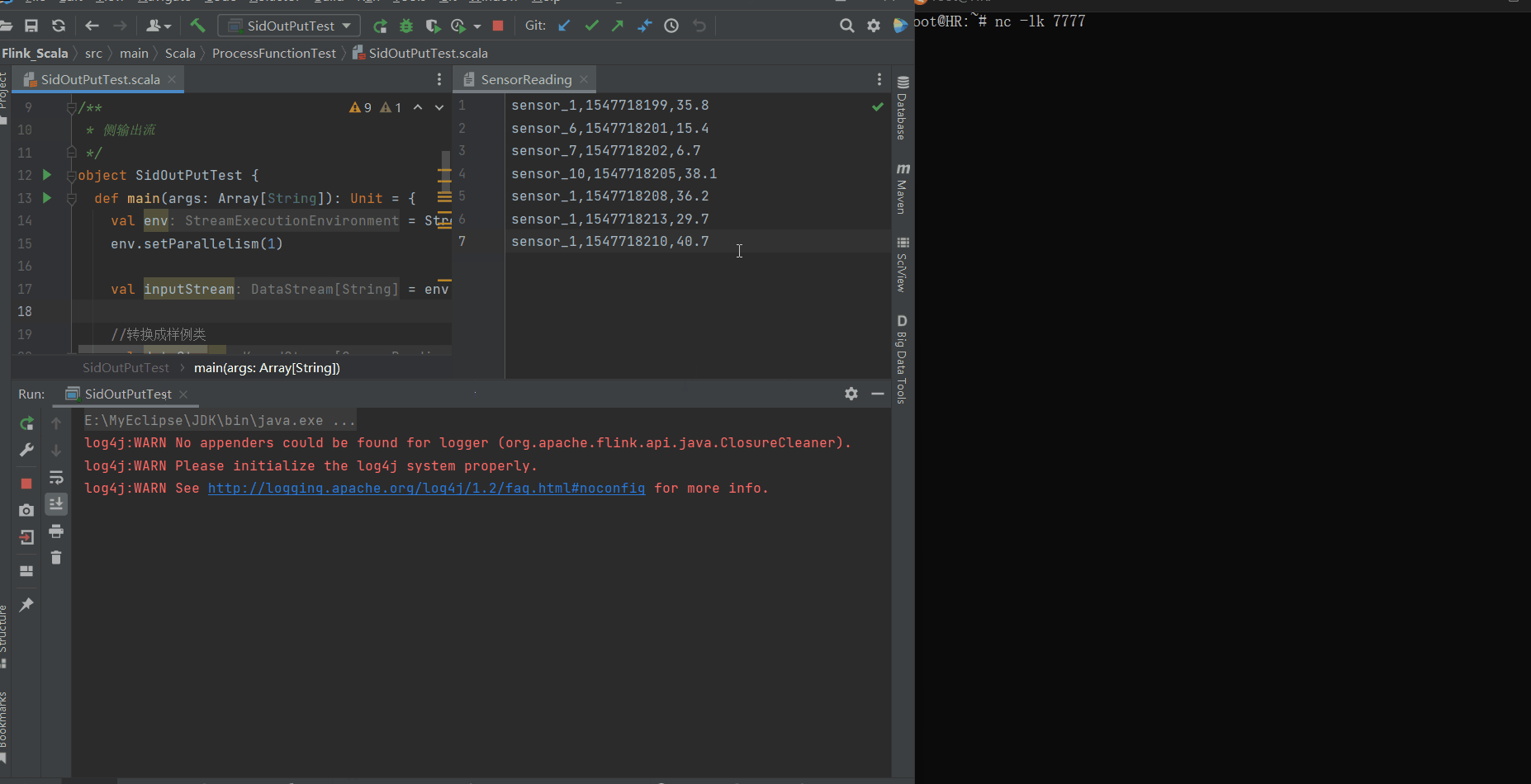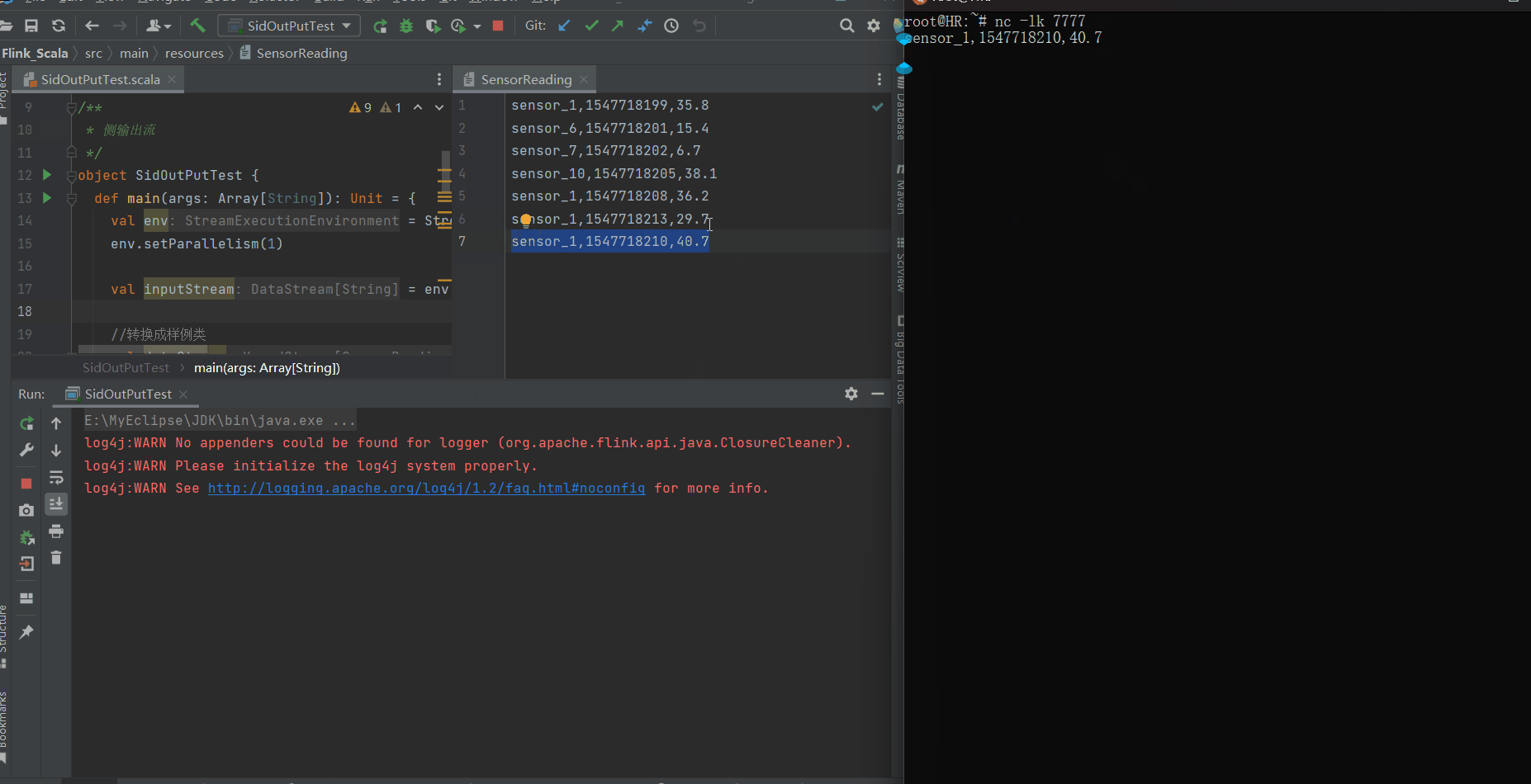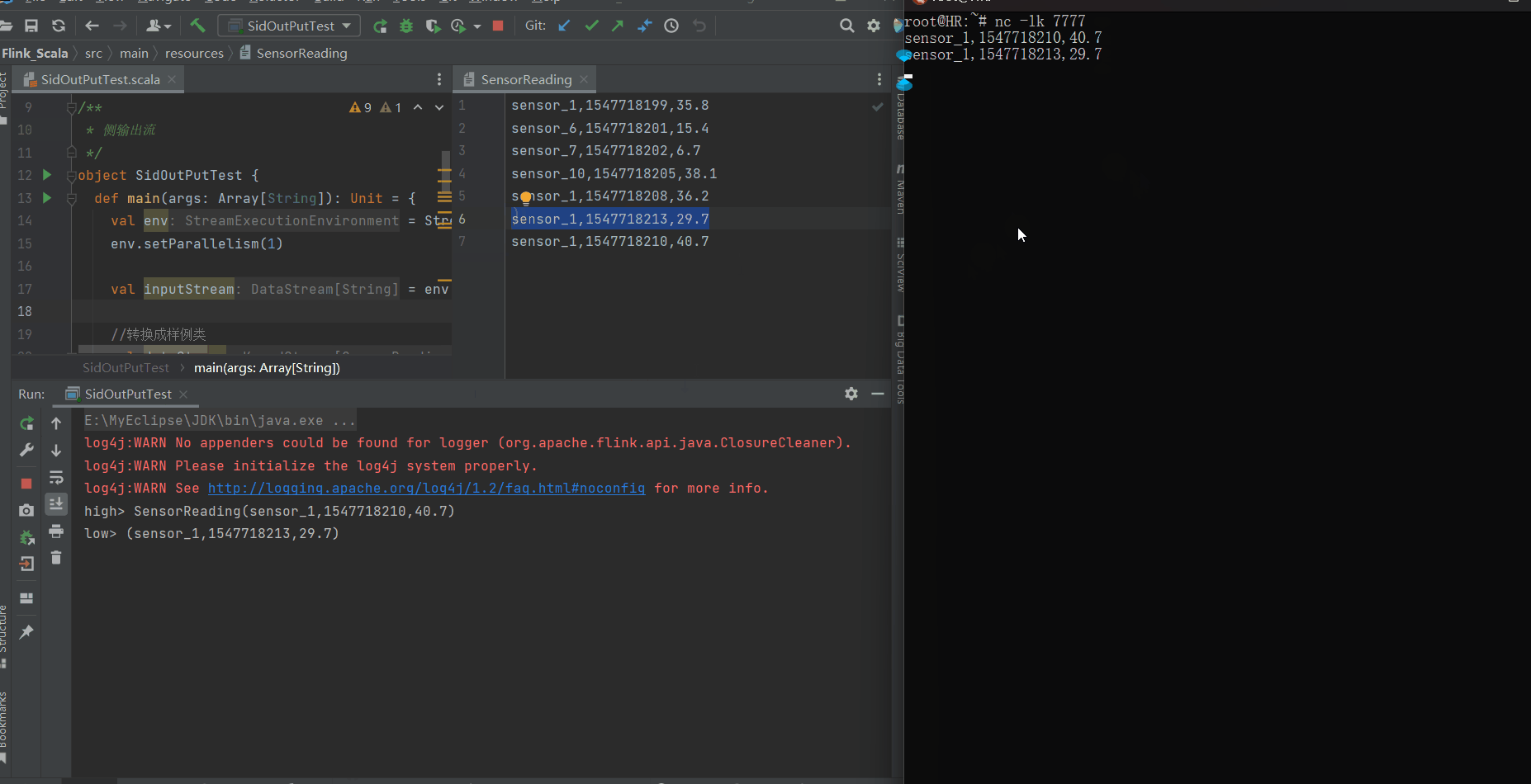
highTempStream.print("high")
//获取侧输出流,测输出流的输出类型和主流不一定一致,这边的输入需要和下面定义的侧输出流一致
highTempStream.getSideOutput(new OutputTag[(String, Long, Double)]("low")).print("low")
env.execute()
}
}
结果展示
跳转顶部