5.2 办公自动化&爬虫讲义
5.2 办公自动化&爬虫讲义
- 1. 办公自动化
-
- 1.1 文件操作
- 1.2 异常处理
- 1.3 处理csv文件
- 1.4 pip包管理⼯具
- 1.5 处理excel文件
-
- 1.5.1 excel⽂件的读取
- 1.5.2 excel文件的写入
- 1.6 word文件操作
- 1.7 PDF处理
-
- 1.7.1 word文件转PDF文件
- 1.7.2 PDF读取
- 1.7.3 添加水印
- 1.8 发送邮件
- 2. 数据爬虫
-
- 2.1 理论基础
-
- 2.1.1 HTTP协议简介
- 2.1.2 HTML基础
- 2.2 Requests爬虫
- 2.3 BeautifulSoup爬虫
1. 办公自动化
1.1 文件操作
打开文件有两种方式
f = open('1.txt','r',encoding='utf-8').read()
with open('1.txt','r',encoding='utf-8') as f:
f.read()
with语句在每次使⽤完后,⽆论是否产⽣异常,都会⾃动将⽂件关闭
| 函数 | 说明 |
|---|---|
| open() | 打开文件 |
| close() | 关闭文件 |
| read() | 读取文件 |
| write() | 写入文件 |
| readlines() | 逐行读取文档,配合for循环使用 |
open函数的mode参数可⽤的模式如下:
| 字符 | 含义 |
|---|---|
| ‘r’ | 读取(默认) |
| ‘w’ | 写⼊,并先截断⽂件 |
| ‘x’ | 排它性创建,如果⽂件已存在则失败 |
| ‘a’ | 写⼊,如果⽂件存在则在末尾追加 |
| ‘b’ | ⼆进制模式 |
| ‘t’ | ⽂本模式(默认) |
| ‘+’ | 打开⽤于更新(读取与写⼊) |
1.2 异常处理
try…except…finally 的这种写法就是⽤来捕捉处理异常,在try代码块中的代码是我们认为有可能会发⽣异常的代码,如果发⽣异常,将会中断try代码块中剩余部分的执⾏,开妈执⾏except代码块中的逻辑,最后,不管有没有发⽣异常,都会执⾏finally块中的代码。
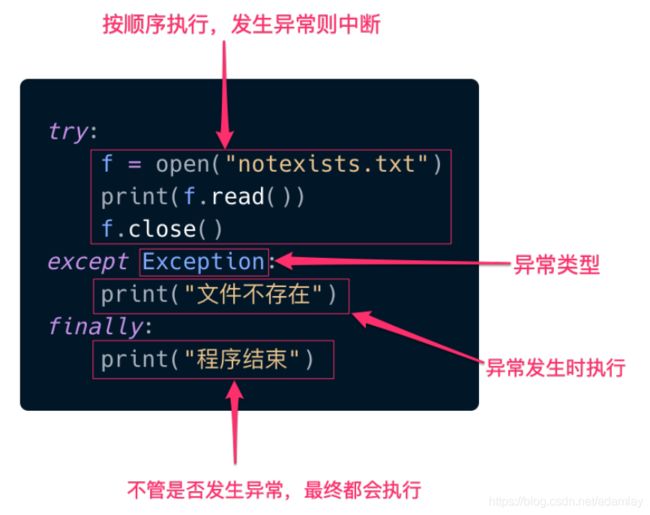
上例中的Exception 是所有异常的基类,事实上在Python中有很多类型的异常,我们⿎励尽量捕捉具体的异常,⽐如这个异常就是⽂件不存在,所以我们可以明确指定它的类型
try:
f = open("notexists.txt")
print(f.read())
f.close()
except FileNotFoundError:
print("⽂件不存在")
finally:
print("程序结束")
如果觉得麻烦,我们可以使⽤with 关键字,这样在每次使⽤完后,⽆论是否产⽣异常,都会⾃动将⽂件关闭。
with open("contacts.txt") as f:
print(f.read())
1.3 处理csv文件
csv内的列与列之间是⽤逗号隔开的,那如果单元格内的内容本身就包含逗号怎么办呢 ?可以使⽤双引号将内容包含起来。
csv模块⾃动提供了这些功能,下⾯的例⼦使⽤内置的csv模块来读取csv⽂件。
import csv
with open('./data_files/example1.csv', 'r') as f:
# 按⾏读取,每⼀⾏是⼀个列表
reader = csv.reader(f)
for row in reader:
for col in row:
print(col, end="\t")
print()
另⼀种读取⽅法:
with open('./data_files/example1.csv', 'r') as f:
# 按⾏读取,每⼀⾏是个字典,字典的key就是每列的表头
reader = csv.DictReader(f)
for row in reader:
print(row['产品类⽬'], row['销售额'])
写⼊的时候也可以以两种⽅式写⼊:
第⼀种:
sales = (
("Peter", (78, 70, 65)),
("John", (88, 80, 85)),
("Tony", (90, 99, 95)),
("Henry", (80, 70, 55)),
("Mike", (95, 90, 95)),
)
with open('./data_files/sales.csv', 'w') as f:
writer = csv.writer(f)
writer.writerow(['name', 'Jan', 'Feb', 'Mar'])
for name, qa in sales:
writer.writerow([name, qa[0], qa[1], qa[2]])
# 最后⼀句也可以写成这样
writer.writerow([name, *qa])
第⼆种,可以将上⾯的数据合并⼀下,换⼀种形式写⼊到csv⽂件中,这次我们采⽤DictWriter来写⼊数据。
# 合并数据
data = [{'name': name, 'amount': sum(qa)} for name, qa in sales]
# 先看⼀下合并后的数据
import pprint
pprint.pprint(data)
with open('./data_files/sales2.csv', 'w') as f:
fieldnames = ['name', 'amount']
writer = csv.DictWriter(f, fieldnames)
writer.writeheader()
for row in data:
writer.writerow(row)
1.4 pip包管理⼯具
在学习更多的⽂件格式处理⽅法之前,我们先学习⼀下Python的包管理⼯具。Python包罗万象的第三库是它被⼈喜爱的⼀个重要原因,官⽅的⽹址:https://pypi.org/ ,在这⾥⼏乎可以找到你能想象的任何功能的包。
如果我们想在代码⾥使⽤第三⽅库,需要先安装,这时候就需要使⽤pip命令,pip是Python⾃带的包管理⼯具
pip install faker
如果想⼀次性安装多个包,可以将这些包的名字和版本写在⼀个⽂件⾥,通常这个⽂件叫requestments.txt ,⽂件的内容是这样的格式
Faker==0.8.7
jupyter==1.0.0
numpy
⽤两个等于号指定版本,如果不指定版本,pip会帮我们⾃动选择最新版本。
pip install -r requirements.txt
升级第三⽅包
pip install -U faker
pip install -U pip
卸载第三⽅包:
pip uninstall faker
由于pip默认的官⽅服务器是在国外,所以下载的速度会⽐较慢,我们可以将下载源改为国内的服务器,下⾯这些是⼀些速度⽐较快的服务器
阿⾥云 http://mirrors.aliyun.com/pypi/simple/
中国科技⼤学 https://pypi.mirrors.ustc.edu.cn/simple/
⾖瓣(douban) http://pypi.douban.com/simple/
清华⼤学 https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术⼤学 http://pypi.mirrors.ustc.edu.cn/simple/
我们可以在⽤户⽬录下新建⼀个名为"pip"的⽬录,然后再在pip⽬录中新建⼀个pip.conf⽂件,写⼊以下内容
[global]
index-url = http://pypi.doubanio.com/simple
trusted-host = pypi.doubanio.com
⽂件保存好了后,以后再使⽤pip下载包就会快很多了。
1.5 处理excel文件
要处理excel⽂件 ,我们需要使⽤借助第三⽅库,Python中能够处理excel⽂件格式的库有很多
- xlrd:⽤于读取 Excel ⽂件;
- xlwt:⽤于写⼊ Excel ⽂件;
- xlutils:⽤于操作 Excel ⽂件的实⽤⼯具,⽐如复制、分割、筛选等;
注意:这⼏个库只能处理xls格式的excel⽂件,对于⽐较新的excel版本,⽂件名通常是xlsx,需要先将其转存为xls⽂件。
1.5.1 excel⽂件的读取
| 函数 | 说明 |
|---|---|
| xlrd.open_workbook | 打开excel,返回xlrd.book.Book格式数据 |
| xlrd.xldate_as_datetime(cell.value,0) | 数值型转化为日期 |
xlrd.book.Book数据属性
| 函数 | 说明 |
|---|---|
| .nsheets | 返回表数量 |
| .sheets() | 返回所有表,生成一个列表 |
| .sheet_names() | 返回所有表名称 |
| .sheet_by_name() | 根据名称获取表(sheet格式数据) |
| .sheet_by_index() | 根据索引获取表 |
sheet格式数据属性
| 函数 | 说明 |
|---|---|
| .name | 返回单个表名称 |
| .nrows | 表中行数 |
| .ncols | 表中列数 |
| .row() | 根据索引返回列 |
| .col() | 根据索引返回行 |
| .row_values() | 根据索引返回行值 |
| .col_values() | 根据索引返回列值 |
| .cell(行索引,列索引) | 获取单元格(Cell格式) |
| .cell_value(行索引,列索引) | 单元格数值 |
| .cell_ctype(行索引,列索引) | 单元格数值类型 |
Cell格式数据属性
| 函数 | 说明 |
|---|---|
| Cell.value | 单元格数值 |
| Cell.ctype | 单元格数值的类型 |
单元格数值类型
| Type symbol | ctype值 | Python类型y |
|---|---|---|
| XL_CELL_EMPTY | 0 | 空字符串 |
| XL_CELL_TEXT | 1 | 字符串 |
| XL_CELL_NUMBER | 2 | float |
| XL_CELL_DATE | 3 | float |
| XL_CELL_BOOLEAN | 4 | int; 1表示True, 0表示False |
| XL_CELL_ERROR | 5 | 错误 |
| XL_CELL_BLANK | 6 | 空 |
遍历显示出整个excel⽂件的内容
# 打开excel⽂件
wb = xlrd.open_workbook("test.xls")
# 根据 sheet 索引获取内容
sh = wb.sheet_by_index(0)
# 快速遍历所有表单内容
for i in range(sh.nrows):
for j in range(sh.ncols):
cell = sh.cell(i, j)
cv = cell.value
if cell.ctype == 2:
cv = int(cv)
elif cell.ctype == 3:
value = xlrd.xldate_as_tuple(cell.value, 0)
date = datetime(*value)
cv = date.strftime('%Y-%d-%m')
print(str(cv).center(10), end='\t')
print()
1.5.2 excel文件的写入
| 函数 | 说明 |
|---|---|
| xlwt.Workbook() | 创建excel,返回xlwt.Workbook.Workbook格式数据 |
xlwt.Workbook.Workbook格式数据属性
| 函数 | 说明 |
|---|---|
| .add_sheet(表名,cell_overwrite_ok=True) | 添加表并命名,Worksheet格式 |
| wd.save(’./data_files/test_write.xls’) | 保存文件并命名 |
Worksheet格式数据属性
| 函数 | 说明 |
|---|---|
| .write(行索引,列索引,值) | 写入单元格值 |
| .row() | 行,Row格式 |
| .col() | 列,Column l格式 |
1.6 word文件操作
pip install python-docx
| 函数 | 说明 |
|---|---|
| from docx import Document | 导入Document包 |
| from docx.enum.text import WD_PARAGRAPH_ALIGNMENT | 导入包,文档设置的常量 |
| from docx.shared import Mm,RGBColor | 导入包,文档设置单位和颜色,此处导入毫米 |
| Document() | 创建文档,Document格式 |
Document格式数据属性
| 函数 | 说明 |
|---|---|
| .add_heading(标题,n) | 添加标题,n代表标题级别,Paragraph格式 |
| .add_paragraph(内容) | 添加段落 |
| .add_paragraph(内容,style=‘List Number’) | 添加有序列表 |
| .add_paragraph(内容,style='List Bullet) | 添加无序列表 |
| .add_table(rows=1,cols=3) | 添加表格 |
| .add_picture(地址,width=Mm(5)) | 添加图片 |
| .add_page_break() | 添加分页符 |
| .save() | 保存文档并命名 |
Paragraph格式数据属性
| 函数 | 说明 |
|---|---|
| .paragraph_format.alignment | 段落格式-对齐 |
| .paragraph_format.left_indent | 缩进 |
| .add_run().bold=True | 追加段落内容,加粗字体 |
| .font.name | 设置字体样式 |
| .font.size | 设置字体大小 |
| .font.color.rgb = RGBColor(0,0,0,) | 设置字体颜色 |
| .italic=True | 设置斜体 |
| .underline=True | 下划线 |
WD_PARAGRAPH_ALIGNMENT 常量
| 常量 | 说明 |
|---|---|
| CENTER | 居中 |
| LEFT | 靠左 |
| RIGHT | 靠右 |
1.7 PDF处理
1.7.1 word文件转PDF文件
pip install docx2pdf
from docx2pdf import convert
convert('daily_report.docx', 'daily_report.pdf')
1.7.2 PDF读取
from io import StringIO #缓冲
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfparser import PDFParser
output_string = StringIO()
with open('data_files/daily_report.pdf', 'rb') as f:
# 从⽂件句柄创建⼀个pdf解析对象
parser = PDFParser(f)
# 创建pdf⽂档对象,存储⽂档结构
doc = PDFDocument(parser)
# 创建⼀个pdf资源管理对象,存储共享资源
rsrcmgr = PDFResourceManager()
# 创建⼀个device对象,指定参数,⾏距、边距等,这⾥使⽤默认参数
device = TextConverter(rsrcmgr, output_string, laparams=LAParams())
# 创建⼀个解释对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
# 按⻚解析pdf⽂件
for page in PDFPage.create_pages(doc):
# 将内容读取到缓存
interpreter.process_page(page)
# 打印出缓冲区的内容
print(output_string.getvalue())
1.7.3 添加水印
from PyPDF2 import PdfFileWriter, PdfFileReader
# 导⼊包含⼀个⽔印的pdf⽂件,只要有⼀⻚即可
watermark_pdf = PdfFileReader('./data_files/⽔印.pdf')
# 获取第⼀⻚
watermark = watermark_pdf.getPage(0)
# 把想要加⽔印的pdf⽂件加载进来
input_pdf = PdfFileReader('./data_files/daily_report.pdf')
# 创建⼀个writer对象,⼀会⼉⽤来写新⽣成的pdf
writer = PdfFileWriter()
for page in range(input_pdf.getNumPages()):
# 逐⻚读取pdf内的内容
page = input_pdf.getPage(page)
# 将当前⻚与⽔印⻚合并
page.mergePage(watermark)
# 将当前⻚加⼊到待写⼊区域
writer.addPage(page)
# 将全部合并完的pdf保存到⽂件
with open('./data_files/包含⽔印.pdf', 'wb') as f:
writer.write(f)
1.8 发送邮件
发送普通⽂本邮件
import smtplib
from email.mime.text import MIMEText
# 1. 设置服务器所需信息
# SMTP服务器域名
mail_host = 'smtp.163.com'
# 邮箱⽤户名
mail_user = '[email protected]'
# 密码或授权码
mail_pass = 'AXNHIKAAAAAKJVRNR'
# 邮件发送⽅邮箱地址,有可能和⽤户名不⼀样
sender = '[email protected]'
# 邮件接收⽅邮箱地址,可以有多个收件⼈,所以⽤列表
receivers = ['[email protected]']
# 2. 设置邮件内容
# 邮件正⽂
message = MIMEText('详情请⻅附件','plain','utf-8')
# 邮件主题
message['Subject'] = '每⽇运营报告'
# 发送⽅信息
message['From'] = sender
# 接受⽅信息
message['To'] = receivers[0]
# 3. 发送邮件
try:
smtpObj = smtplib.SMTP_SSL(mail_host, 465)
# 设置⽇志级别,这样万⼀出错就会有详细的输出
smtpObj.set_debuglevel(1)
# 登录到服务器
smtpObj.login(mail_user, mail_pass)
#发送
smtpObj.sendmail(sender, receivers, message.as_string())
smtpObj.quit()
print('邮件发送成功')
except smtplib.SMTPException as e:
print('error', e)
发送带有附件的HTML格式邮件
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.mime.image import MIMEImage
#设置登录及服务器信息
mail_host = 'smtp.163.com'
mail_user = '159*****02'
mail_pass = '7******x'
sender = '159*****[email protected]'
receivers = ['7******[email protected]']
#设置eamil信息
#添加⼀个MIMEmultipart类,处理正⽂及附件
message = MIMEMultipart()
message['From'] = sender
message['To'] = receivers[0]
message['Subject'] = 'title'
#推荐使⽤HTML格式的正⽂内容,这样⽐较灵活,可以附加图⽚地址,调整格式等
with open('abc.HTML','r') as f:
content = f.read()
#设置HTML格式参数
part1 = MIMEText(content,'HTML','utf-8')
#添加⼀个txt⽂本附件
with open('abc.txt','r')as h:
content2 = h.read()
#设置txt参数
part2 = MIMEText(content2,'plain','utf-8')
#附件设置内容类型,⽅便起⻅,设置为⼆进制流
part2['Content-Type'] = 'application/octet-stream'
#设置附件头,添加⽂件名
part2['Content-Disposition'] = 'attachment;filename="abc.txt"'
#添加照⽚附件
with open('1.png','rb')as fp:
picture = MIMEImage(fp.read())
#与txt⽂件设置相似
picture['Content-Type'] = 'application/octet-stream'
picture['Content-Disposition'] = 'attachment;filename="1.png"'
#将内容附加到邮件主体中
message.attach(part1)
message.attach(part2)
message.attach(picture)
#登录并发送
try:
smtpObj = smtplib.SMTP()
smtpObj.connect(mail_host,25)
smtpObj.login(mail_user,mail_pass)
smtpObj.sendmail(
sender,receivers,message.as_string())
print('success')
smtpObj.quit()
except smtplib.SMTPException as e:
print('error',e)
注意事项:
⼀些邮箱登录⽐如 QQ 邮箱需要 SSL 认证,所以 SMTP 已经不能满⾜要求,⽽需要SMTP_SSL,解决办法为:
#启动
smtpObj = smtplib.SMTP()
#连接到服务器
smtpObj.connect(mail_host,25)
#######替换为########
smtpObj = smtplib.SMTP_SSL(mail_host)
2. 数据爬虫
2.1 理论基础
2.1.1 HTTP协议简介
HTTP是基于客户端/服务端(C/S)的架构模型,通过⼀个可靠的链接来交换信息,是⼀个⽆状态的请求/响应协议。
⼀个HTTP"客户端"是⼀个应⽤程序(Web浏览器或其他任何客户端),通过连接到服务器达到向服务器发送⼀个或多个HTTP的请求的⽬的。
⼀个HTTP"服务器"同样也是⼀个应⽤程序(通常是⼀个Web服务,如Apache Web服务器或IIS服务器等),通过接收客户端的请求并向客户端发送HTTP响应数据。
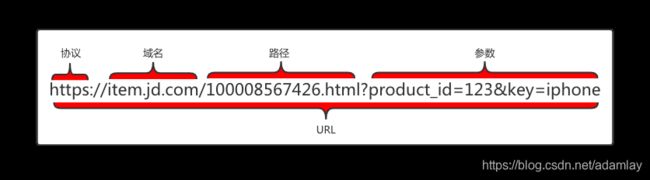
HTTP使⽤统⼀资源标识符(Uniform Resource Identifiers, URI)来传输数据和建⽴连接。
请求参数,使⽤⼀个问号附在url的后⾯,多个参数之间⽤“&”符号隔开。
HTTP请求方法
| 方法 | 描述 |
|---|---|
| GET | 请求指定的⻚⾯信息,并返回实体主体。 |
| HEAD | 类似于get请求,只不过返回的响应中没有具体的内容,⽤于获取报头 |
| POST | 向指定资源提交数据进⾏处理请求(例如提交表单或者上传⽂件)。数据被包含在请求体中。POST请求可能会导致新的资源的建⽴和/或已有资源的修改。 |
| PUT | 从客户端向服务器传送的数据取代指定的⽂档的内容。 |
| DELETE | 请求服务器删除指定的⻚⾯。 |
| CONNECT | HTTP/1.1协议中预留给能够将连接改为管道⽅式的代理服务器。 |
| OPTIONS | 允许客户端查看服务器的性能。 |
| TRACE | 回显服务器收到的请求,主要⽤于测试或诊断。 |
最常⽤的是GET和POST请求
常见HTTP状态码
| 状态码 | 状态码英⽂名称 | 中⽂描述 |
|---|---|---|
| 200 | OK | 请求成功。⼀般⽤于GET与POST请求 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使⽤原有URI |
| 400 | Bad Request | 客户端请求的语法错误,服务器⽆法理解 |
| 401 | Unauthorized | 请求要求⽤户的身份认证 |
| 403 | Forbidden | 服务器理解客户端的请求,但是拒绝执⾏此请求 |
| 404 | Not Found | 服务器⽆法根据客户端的请求找到资源(⽹⻚)。通过此代码,⽹站设计⼈员可设置"您所请求的资源⽆法找到"的个性⻚⾯ |
| 500 | Internal Server Error | 服务器内部错误,⽆法完成请求 |
2.1.2 HTML基础
动态网页和静态网页的区别
- 如果不修改⻚⾯源码,⻚⾯⼀成不变,就是静态⻚⾯
- 动态⻚⾯,服务器从数据库提出数据临时⽣成的,会根据时间、是否登录不同,⽽⻚⾯内容也不同
注意事项
- 标签不能创造
- 书写标签的时候应该⽤英⽂半⻆
- 属性值可以单引号、双引号引起来,也可以不写引号,推荐使⽤单引号括起来
- 属性必须写在开始标签⾥
- 标签可以嵌套,⼀个标签要完全嵌套到另外⼀个标签⾥
body常⽤属性: - topmargin 上外边距
- leftmargin 左外边距
- text ⽂字颜⾊
- bgcolor 背景颜⾊
- background 背景图⽚,和bgcolor冲突,设置了背景图⽚,背景颜⾊就是不显示
全局属性
每⼀个标签都有的属性,常⽤的有id、class、name、style
2.2 Requests爬虫
| 函数 | 说明 |
|---|---|
| requests.get(url,params,headers) | 获取网页内容,Response格式数据 |
| requests.post(url,data) | post方式提交表单(form) |
Response格式数据属性
| 函数 | 说明 |
|---|---|
| .status_code | 状态码 |
| .raise_for_status | 异常状态码直接报错,不再往下运行 |
| .encoding | 编码格式 |
| .text | 源码文本 |
| .url | url链接 |
| .json() | 返回json格式内容 |
2.3 BeautifulSoup爬虫
| 函数 | 说明 |
|---|---|
| from bs4 import BeautifulSoup as bs | 导入 |
| BeautifulSoup(html,‘html.parser’) | 将html内容转换返回BeautifulSoup格式数据 |
BeautifulSoup格式数据属性
| 函数 | 说明 |
|---|---|
| .title | 网页标题 |
| .p | 网页段落 |
| … | 根据html标签取相应部分 |
| .get_text() | 取文档内所有文本内容 |
| .prettify() | 工整格式显示代码 |
| .find(‘标签’,class_=‘title’) | 找到html内符合属性筛选的(第一个)指定标签 |
| .find_all(‘标签’) | 找到html内所有指定标签 |
| .find_all(class_=‘title’) | 找到html内所有指定属性的节点 |
| .节点.text | 只取节点文本 |
| .节点.name | 只取节点的标签名称 |
| .节点.parent | 取节点的父节点 |
| .节点.children | 取节点的子节点 |
| .节点[‘属性’] | 取节点的属性 |