MMU 和 IOMMU
一、硬件MMU
MMU 即内存管理单元(Memory Manage Unit),是一个与软件密切相关的硬件部件,也是理解linux等操作系统内核机制的最大障碍之一。
1、虚拟地址/物理地址
如果处理器没有 MMU,CPU 内部执行单元产生的内存地址信号将直接通过地址总线发送到芯片引脚,被内存芯片接收,这就是物理地址(physical address),简称 PA。英文 physical 代表物理的接触,所以 PA 就是与内存芯片 physically connected 的总线上的信号。
如果 MMU 存在且启用,CPU 执行单元产生的地址信号在发送到内存芯片之前将被 MMU 截获,这个地址信号称为虚拟地址(virtual address),简称 VA,MMU 会负责把 VA 翻译成另一个地址,然后发到内存芯片地址引脚上,即 VA 映射成 PA,如下图:
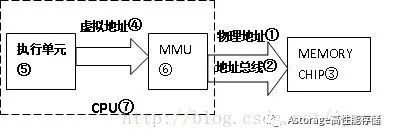
所以物理地址①是通过 CPU 对外地址总线②传给 Memory Chip③使用的地址;而虚拟地址④是CPU内部执行单元⑤产生的,发送给 MMU⑥的地址。硬件上 MMU⑥一般封装于 CPU 芯片⑦内部,所以虚拟地址④一般只存在于CPU⑦内部,到了CPU外部地址总线引脚上②的信号就是MMU转换过的物理地址①。
软件上MMU对用户程序不可见,在启用MMU的平台上(没有MMU不必说,只有物理地址,不存在虚拟地址),用户C程序中变量和函数背后的数据/指令地址等都是虚拟地址,这些虚拟内存地址从CPU执行单元⑤发出后,都会首先被MMU拦截并转换成物理地址,然后再发送给内存。也就是说用户程序运行*pA =100;"这条赋值语句时,假设debugger显示指针pA的值为0x30004000(虚拟地址),但此时通过硬件工具(如逻辑分析仪)侦测到的CPU与外存芯片间总线信号很可能是另外一个值,如0x8000(物理地址)。当然对一般程序员来说,只要上述语句运行后debugger显示0x30004000位置处的内存值为100就行了,根本无需关心pA的物理地址是多少。但进行OS移植或驱动开发的系统程序员不同,他们必须清楚软件如何在幕后辅助硬件MMU完成地址转换。
2、页 / 页帧 / 页表 / 页表项(PTE)
这几个页概念也噎倒了不少人,这里澄清下。MMU 是负责把虚拟地址映射为物理地址,但凡"映射"都要解决两个问题:映射的最小单位(粒度)和映射的规则。
MMU 中 VA 到 PA 映射的最小单位称为页(Page),映射的最低粒度是单个虚拟页到物理页,页大小通常是 4K,即一次最少要把 4K 大小的 VA 页块整体映射到 4K 的 PA 页块(从 0 开始 4K 对齐划分页块),页内偏移不变,如 VA 的一页 0x30004000~0x30004fff 被映射到 PA 的一页 0x00008000~0x00008fff,当 CPU 执行单元访问虚拟地址 0x30004008,实际访问的物理地址是0x00008008(0x30004008 和 0x00008008 分别位于虚实两套地址空间,互不相干,不存在重叠和冲突)。以页为最小单位,就是不能把 VA 中某一页划分成几小块分别映射到不同 PA,也不能把 VA 中属于不同页的碎块映射到 PA 某一页的不同部分,必须页对页整体映射。
页帧(Page Frame)是指物理内存中的一页内存,MMU 虚实地址映射就是寻找物理页帧的过程,对这个概念了解就可以了。
MMU 软件配置的核心是页表(Page Table),它描述 MMU 的映射规则,即虚拟内存哪(几)个页映射到物理内存哪(几)个页帧。页表由一条条代表映射规则的记录组成,每一条称为一个页表条目(Page Table Entry,即 PTE),整个页表保存在片外内存,MMU 通过查找页表确定一个 VA应该映射到什么 PA,以及是否有权限映射。
但如果 MMU 每次地址转换都到位于外部内存的页表上查找 PTE,转换速度就会大大降低,于是出现了 TLB 。
3、TLB
TLB(Translation Lookaside Buffers)即转换快表,又简称快表,可以理解为 MMU 内部专用的存放页表的 cache,保存着最近使用的 PTE 乃至全部页表。MMU 接收到虚拟地址后,首先在 TLB 中查找,如果找到该 VA 对应的 PTE 就直接转换,找不到再去外存页表查找,并置换进TLB。TLB 属于片上 SRAM,访问速度快,通过 TLB 缓存 PTE 可以节省 MMU 访问外存页表的时间,从而加速虚实地址转换。TLB 和 CPU cache 的工作原理一样,只是 TLB 专用于为 MMU 缓存页表。
4、MMU 的内存保护功能
既然所有发往内存的地址信号都要经过 MMU 处理,那让它只单单做地址转换,岂不是浪费了这个特意安插的转换层?显然它有能力对虚地址访问做更多的限定(就像路由器转发网络包的同时还能过滤各种非法访问),比如内存保护。可以在 PTE 条目中预留出几个比特,用于设置访问权限的属性,如禁止访问、可读、可写和可执行等。设好后,CPU访问一个 VA 时,MMU 找到页表中对应 PTE,把指令的权限需求与该 PTE 中的限定条件做比对,若符合要求就把 VA 转换成 PA,否则不允许访问,并产生异常。
5、多级页表
虚拟地址由页号和页内偏移组成。什么东东呢?
前面说过 MMU 映射以页为最小单位,假设页大小为 4K,那么无论页表怎样设置,虚拟地址后 12 比特与 MMU 映射后的物理地址后 12 比特总是相同,这不变的比特位就是页内偏移。为什么不变?拜托,把搭积木想象成一种映射,不管你怎么搭,你也改变不了每块积木内部的原子排列吧。所谓以页为最小单位就是保持一部分不变作为最小粒度。
页号就更有故事了,一个 32bits 虚拟地址,可以划分为 220 个内存页,如果都以页为单位和物理页帧随意映射,页表的空间占用就是 220 * sizeof(PTE) * 进程数(每个进程都要有自己的页表),PTE 一般占 4 字节,即每进程 4M,这对空间占用和 MMU 查询速度都很不利。
问题是实际应用中不需要每次都按最小粒度的页来映射,很多时候可以映射更大的内存块。因此最好采用变化的映射粒度,既灵活又可以减小页表空间。具体说可以把 20bits 的页号再划分为几部分。
简单说每次 MMU 根据虚拟地址查询页表都是一级级进行,先根据 PGD 的值查询,如果查到 PGD 的匹配,但后续 PMD 和 PTE 没有,就以 2(offset + pte + pmd) = 1M 为粒度进行映射,后 20bits 全部是块内偏移,与物理地址相同。
6、操作系统和 MMU
实际上 MMU 是为满足操作系统越来越复杂的内存管理而产生的。OS 和 MMU 的关系简单说:
(1)系统初始化代码会在内存中生成页表,然后把页表地址设置给 MMU 对应寄存器,使 MMU 知道页表在物理内存中的什么位置,以便在需要时进行查找。之后通过专用指令启动 MMU,以此为分界,之后程序中所有内存地址都变成虚地址,MMU 硬件开始自动完成查表和虚实地址转换。
(2)OS 初始化后期,创建第一个用户进程,这个过程中也需要创建页表,把其地址赋给进程结构体中某指针成员变量。即每个进程都要有独立的页表。
(3)用户创建新进程时,子进程拷贝一份父进程的页表,之后随着程序运行,页表内容逐渐更新变化。比较复杂了,几句讲不清楚,不多说了哈,有时间讲 linux 的话再说吧
7、总结
相关概念讲完,VA 到 PA 的映射过程就一目了然:MMU 得到 VA 后先在 TLB 内查找,若没找到匹配的 PTE 条目就到外部页表查询,并置换进 TLB;根据 PTE 条目中对访问权限的限定检查该条VA 指令是否符合,若不符合则不继续,并抛出 exception 异常;符合后根据 VA 的地址分段查询页表,保持 offset(广义)不变,组合出物理地址,发送出去。
二、iommu 主要功能
IOMMU 全称是 Input/Output Memory Management Unit,翻译过来就是输入输出的内存管理单元。我们知道 CPU 里面也有一个 MMU , 它是为了支持多进程的虚拟地址共享同一个物理内存,以及对物理地址的访问进行权限检查的一个硬件单元。IOMMU 作为一个内存管理单元,它提供的是设备端的地址翻译能力,它让具有 DMA(Direct Memory Access)能力的设备可以使用虚拟地址,然后经过 IOMMU 翻译成可以直接访问内存的物理地址。设备端的地址翻译功能(DMA 重定向)只是 IOMMU 的功能之一,IOMMU 另一个重要的功能是中断重映射。
IOMMU 通常是实现在北桥之中,现在北桥通常被集成进 SOC 中了,所以 IOMMU 通常都放在SOC 内部了。不同芯片厂商的实现大同小异,可是名字却不太一样。Intel 的芯片上叫做 VT-d (Virtualization Technology for Directed I/O ),AMD 还是叫做 IOMMU。

1、DMA 地址空间映射
IOMMU 的主要功能为设备 DMA 时刻能够访问机器的物理内存区,同时保证安全性。
在没有 IOMMU 的时候,设备通过 DMA 可以访问到机器的全部的地址空间。
(1)这种机制下如果将设备的驱动放在用户态,那么如何保护机器物理内存区对于用户态驱动框架设计带来挑战。当出现了 IOMMU 以后,IOMMU 通过控制每个设备 DMA 地址到实际物理地址的映射转换,使得在一定的内核驱动框架下,用户态驱动能够完全操作某个设备 DMA 和中断成为可能。
(2)如果将这个物理设备通过透传的方式进入到虚拟化虚拟机里,虚拟机的设备驱动配置设备的DMA 后,hypervisor 必须在透传设备 DMA 访问时刻,对 DMA 访问进行截获,将其中 DMA 访问的虚拟机物理地址,转换为 hypervisor 为虚拟机分配的物理地址,也就是需要将虚拟机透传设备DMA 访问做 vpaddr(虚拟机物理地址)----> ppaddr(物理机物理地址)。这部分截获对虚拟机DMA 来说带来切换到 hypervisor 开销,hypervisor 转换地址开销。
当引入了 IOMMU 以后,这部分开销由 IOMMU 硬件承担,所有 hypervisor 工作就更加简单,只需要将透传设备 IOMMU DMA 地址映射表使用 vpaddr ---> ppaddr 地址转换表即可(这部分表在hypervisor 里配置在 ept 中)。
(3)方便了老式 32 位 PCI 硬件在 64 位机器上的使用。只需要在 IOMMU 地址映射表上配置 32bit PCI 设备 DMA 地址 --> 64 位机器物理地址即可。
(4)方便了主机 OS 配置设备 DMA 工作,因为 DMA 要求使用连续的地址空间进行读写,有了IOMMU 的存在 OS 就可以为设备配置连续的 DMA 地址而真正对应的非连续的物理地址。

2、中断重映射(可选)
在虚拟化透传设备使用中,或者主机侧用户态驱动框架中还有一个问题就是 msi 中断的安全保护。msi 的特点就是只要发起特定的 pci write 消息,机器(在 x86 上是 LAPIC)就能够将此 pci write消息翻译为一次中断信号。在 msi 中断信息里,含有中断源信息,中断 vector 信息以及中断发往哪里,中断模式等等信息。
如果设备透传到虚拟机,而虚拟机里有恶意驱动,那么恶意驱动完全可以操作一个透传设备发起dma write 访问,带有 msi 中断信息,导致 hypervisor 被攻击。在用户态驱动层面也是相同的,用户态驱动可以触发 dma 带有 msi 中断导致主机系统被攻击。
为了防止这种情况发生,Intel 的 iommu 技术(vt-d)里实现了中断重映射技术(intremap)。设备发起的 msi 中断先进入 iommu 的 intremap 模块进行映射得到真正的 msi 中断信息。主机 os 会在这个中断重映射表里限定,某个设备只能发起哪种中断向量,同时会验证 msi 中的信息位(如此提升了恶意软件触发真实 msi 的难度)。
3、iommu cache 、intremap cache 和设备 tlb
在 1 和 2 中我们提到了很多转换表,这些转换表都位于物理内存中,所以在 intel vt-d 中设计了大量主机侧 cache 机制来缓存这些表的表项,提升访问效率。
设备 tlb 是 intel vt-d 中设计的设备侧 tlb 寄存器,在设备进行 dma 的时候在设备一侧缓存 dma 地址到物理地址映射项。
转载:MMU和IOMMU - 墨天轮
(SAW:Game Over)