基于用户行为建模和异常检测算法的内部威胁检测
Insider Threat Detection Based on User Behavior Modeling and Anomaly Detection Algorithms
内部威胁是授权用户的恶意活动,如盗窃知识产权或安全信息、欺诈和破坏。尽管内部威胁的数量远低于外部网络攻击,但内部威胁可能会造成广泛的损害。由于内部人员非常熟悉组织的系统,因此很难检测到他们的恶意行为。传统的内部威胁检测方法侧重于领域专家构建的基于规则的方法,但它们既不灵活也不健壮。本文提出了基于用户行为建模和异常检测算法的内部威胁检测方法。基于用户日志数据,我们构建了三类数据集:用户的日常活动摘要、电子邮件内容主题分布和用户的每周电子邮件通信历史。然后,我们应用四种异常检测算法及其组合来检测恶意活动。实验结果表明,该框架适用于不平衡数据集,其中只有少量内部威胁,并且没有提供领域专家的知识。
关键词:内部威胁检测;异常检测;机器学习;行为模型;潜在狄利克雷分配 (LDA);电子邮件网络
1. 背景
(1)会议/刊物级别
Kim J, Park M, Kim H, et al. Insider threat detection based on user behavior modeling and anomaly detection algorithms[J]. Applied Sciences, 2019, 9(19): 4018.
CCF None
(2)作者团队
高丽大学工业管理工程学院(韩国首尔)

(3)研究背景
内部威胁是一种安全问题,由能够访问公司网络、系统和数据的人员引起,如员工和可信合作伙伴[1]。虽然内部威胁并不经常发生,但损害的程度比外部入侵的程度更大[2,3]。由于内部人员非常熟悉其组织的计算机系统和操作流程,并且有权使用这些系统,因此很难确定他们何时有恶意行为[4]。已经开发了许多系统保护技术,以防外部人员试图入侵,例如,量化连接互联网协议(IP)的模式和攻击类型[5]。然而,过去关于公司内部信息安全的研究主要集中在检测和防止外部入侵,很少有研究涉及检测内部威胁的方法[6]。
内部威胁检测有三种主流研究策略。
- 第一种策略是开发基于规则的检测系统[7,8]。在这种策略中,一组专家生成一组规则来识别内部人员的恶意活动。然后,将每个用户的行为记录为日志,并进行测试,以确定其是否符合任何预先设计的规则。Cappelli等人[9]讨论了内部威胁的类型以及防止/检测内部威胁的领域知识。基于规则的检测方法有一个关键的局限性,即规则必须通过领域专家的知识不断更新,因此有人规避规则的风险始终存在[10]。因此,基于专家知识的基于规则的方法对不断变化的内部威胁方法缺乏灵活性,从而导致检测性能不理想[7,10,11]。
- 第二种策略是构建网络图,通过监控图结构的变化来识别可疑用户或恶意行为[12]。基于图形的内部威胁识别不仅分析数据本身的价值,还分析数据之间的关系。数据之间的关系由连接图中节点的边表示,可以分析其属性以确定特定节点与内部威胁的关系。Eberle等人[12]定义了一种异常活动,如果正常数据图的底层结构发生修改、插入或删除。为了确定正常数据图的结构,他们采用了一种基于图的知识发现系统,称为“制服”。Parveen等人[13]使用基于图的异常检测(GBAD)-MDL、GBAD-P和GBAD-MPS来确定图的理想结构,并在“1998林肯实验室入侵检测”数据集中添加了一种基于集成的方法来检测异常的内部活动。
- 第三种策略是基于之前的数据建立统计或机器学习模型,以预测潜在的恶意行为[14]。机器学习是一种方法,在这种方法中,计算机学习一种算法,从训练数据中优化适当的性能标准,以执行给定的任务[15]。使用机器学习的内部威胁检测旨在开发一种方法,在所有用户中自动识别那些在没有先验知识或规则的情况下执行异常活动的用户。由于机器学习方法能够不断地从数据中学习和更新算法,因此与基于规则的检测相比,机器学习方法能够执行稳定而准确的检测。Gavai等人[16]利用随机林[17]和隔离林[18]对“Vegas”数据集的退休人员进行分类,其中从电子邮件传输模式和内容、登录和注销记录、网页浏览模式和文件访问模式中提取行为特征。Ted等人[4]使用名为“SureView”的工具(美国德克萨斯州奥斯汀Forcepoint)收集了5500名用户的用户活动数据。他们通过考虑内部人员潜在的恶意活动场景、隐含的异常活动、时间顺序和高级统计模式,从数据中提取特征。他们创建了涉及内幕人士各种行为的变量,如电子邮件、文件和登录,并应用15个统计指标和各种机器学习算法来确定最合适的算法组合。Eldardiry等人[10]通过测量用户实际所属的角色组和他/她不属于的另一个角色组之间行为的相似性来检测内部威胁,假设相同角色组中的用户具有相似的活动模式。
虽然基于模型的学习策略的优势在于它不依赖于领域专家的知识来定义一组规则或构建关系图,但它有两个实际障碍:(1)量化用户行为数据的方式;(2)缺乏可用于建模的异常情况。由于大多数统计/机器学习模型都将连续值作为检测模型的输入,因此每个用户在特定时间段(如一天)内的行为都应转换为数字向量,其中每个元素表示特定的行为特征。由于用户的行为可以从不同的数据源中提取,例如系统使用日志、电子邮件发送和接收网络以及电子邮件内容,因此构建成功的内部威胁检测模型的关键之一是为不同类型的数据定义有用的特征,并将非结构化原始数据转换为结构化数据集。从建模的角度来看,当只有少数异常示例存在时,几乎不可能训练二进制分类算法[19]。在这种类别不平衡的情况下,大多数统计/机器学习算法倾向于将所有活动归类为正常活动,这导致了无用的内部威胁检测模型。为了解决这些不足,我们提出了一种基于用户活动建模和一类分类的内部威胁检测框架。在用户活动建模阶段,我们考虑三种类型的数据。首先,收集公司系统中记录的个人用户的所有活动日志。然后,通过总结特定活动来提取候选特征。例如,如果系统日志包含用户何时将其个人通用串行总线(USB)驱动器连接到系统的信息,则每天的USB连接总数可以提取为候选变量。其次,我们考虑用户生成的内容,如电子邮件正文,以创建候选特征。具体来说,我们使用主题建模将非结构化文本数据转换为结构化向量,同时尽可能保留文本的含义。最后,我们构建了一个基于电子邮件交换记录的用户通信网络。然后,计算包含中心度指数的节点的汇总统计信息,并将其用作候选特征。在内部威胁检测模型构建阶段,我们基于三类候选特征集,采用一类分类算法来学习正常活动的特征。然后,我们采用四种单独的一类分类算法,并利用它们组合的可能优势。通过考虑异构特征集,我们期望与基于单个数据集的检测模型相比,检测性能有所提高。此外,通过采用一类分类算法,实际上可以在不需要以往异常记录的情况下建立内部威胁检测模型。
本文的其余部分组织如下。在第2节中,我们将介绍本研究中使用的数据集,并演示用户活动建模,即如何将非结构化日志或内容转换为结构化数据集。在第3节中,我们介绍了用于构建内部威胁检测模型的一类分类算法。在第4节中,通过一些有趣的观察结果展示了实验结果。最后,在第5节中,我们总结了我们的研究,并提出了一些未来的研究方向。
2.数据集和用户活动建模
在本节中,我们将简要介绍我们研究中使用的数据集。然后,我们将演示如何定义内部威胁检测模型的候选特征,以及如何将三种不同类型的用户活动数据转换为数字向量。
2.1 CERT数据集
由于很难获得实际的公司系统日志,我们使用了“CERT内部威胁工具”数据集(美国宾夕法尼亚州匹兹堡卡内基梅隆软件工程研究所)[20]。CERT数据集不是真实的企业数据,但它是人为生成的数据集,用于验证内部威胁检测框架[1]。
CERT数据集包括员工计算机使用日志(登录、设备、http、文件和电子邮件),以及一些组织信息,如员工部门和角色。每个表由与用户ID、时间戳和活动相关的列组成。CERT数据集有六个主要版本(R1到R6),最新版本有两个变体:R6。1和R6。2.使用信息的类型、变量数量、员工数量和恶意内幕活动的数量因数据集版本而异。我们使用R6进行了这项研究。2,这是最新和最大的数据集。在这个版本中,数据集包括4000个用户,其中只有5个用户有恶意行为。登录活动表的说明见表1,其他活动见附录A表A1。

2.2 基于日常活动摘要的用户活动建模
在CERT数据集中,用户行为存储在五个数据表中:登录、USB、http、文件和电子邮件。为了综合利用异构用户行为数据,有必要按时间顺序将行为信息集成到一个标准化的数据表中。由于本研究中开发的拟议用户级内部威胁检测模型每天或每周工作,我们首先整合用户每天的零碎活动记录,并对其进行汇总,以量化活动强度,这成为检测模型中的一个输入变量。例如,根据登录表中存储的信息,可以提取用户在特定日期登录计算机的次数。
为了确定内部威胁检测的候选输入变量,我们检查了过去研究中使用的输入变量,如表2所示。从这些引用中,我们创建了可以从CERT数据集提取的所有可能的输入变量。候选输入变量的总数为60个,每个变量的描述见附录A表A2。完成每日总结过程后,共获得1394010个实例。每个实例表示特定用户特定日期的行为摘要。
在100多万个实例中,只有73个实例是潜在的实际内部威胁。为了确定恶意内幕人士的特征,我们调查了73个异常实例的作用,如表3所示。我们发现,大多数异常活动(近90%)由三个角色承担:“推销员”、“信息技术(IT)管理员”和“电气工程师”。如果一个角色没有异常实例,或者在角色的异常实例少于三个的情况下,不仅不可能建立良好的检测模型,也不可能验证所开发模型的性能。因此,我们构建了角色相关的内部威胁检测模型,并评估了所开发模型在上述三种角色中的性能。表4显示了三种角色中正常实例和异常实例的频率。


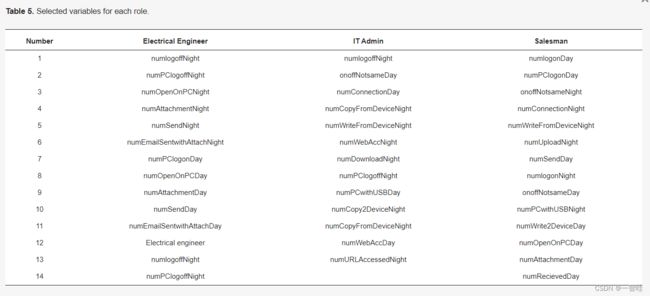
机器学习模型(包括异常检测)的性能受到用于训练模型的输入变量的强烈影响【24】。理论上,当输入变量之间的独立性得到保证时,机器学习模型的性能随着变量数量的增加而提高。然而,当应用于实际数据集时,由于输入变量之间的高度依赖性(多重共线性)和噪声的存在,大量输入变量有时会降低模型的性能。因此,有必要选择一组有效变量,而不是使用所有变量来确保更好的性能。在本研究中,我们使用单变量高斯分布来选择可能的有利变量来检测恶意实例。对于每个变量,我们首先估计高斯分布的参数(均值和标准差)。然后,如果至少有一个异常活动位于某个变量的显著性水平α=0.1的排斥区域,我们将该变量作为输入变量,用于进一步的异常检测建模。表5显示了通过单变量高斯分布测试获得的选定变量。
2.3 基于电子邮件内容的用户活动建模
用户的每日电子邮件使用日志(发送和接收的电子邮件数量)存储如表6所示。虽然表5中的输入变量中包含了一些汇总统计信息,但有时分析每封电子邮件的内容比依赖简单的统计信息更为重要。由于CERT数据集中的电子邮件数据表还包含如表6所示的内容信息和日志记录,因此我们可以进行单独的电子邮件级内容分析。为此,我们使用主题建模将一系列单词(电子邮件正文)转换为固定大小的数字向量,用于训练内部威胁检测模型。

主题建模是一种文本分析方法,它揭示了大量文档中渗透的主要主题[25,26]。主题模型假设每个文档都是主题的混合物(图1(c-1)),每个主题都有自己的选词概率分布(图1(c-2))。因此,主题建模的目的是估计概率文档生成过程的参数,例如每个文档的主题分布和每个主题的单词分布。潜在Dirichlet分配(LDA)是应用最广泛的主题建模算法[25]。LDA的文档生成过程和两个输出如图1所示。通过观察每个文档中的实际单词wd,i,LDA在给定超参数α的情况下估计每个文档的主题分布θd和每个主题的单词分布φk。在本研究中,我们将主题数设置为50,α值设置为1。
图1:潜在迪利克雷分配(LDA)过程及其两个输出。(a) LDA文档生成过程,(b)LDA文档生成过程的示例,(c)LDA的两个输出((c-1)每个文档主题比例(θd),(c-2)每个主题词分布(Φk))。

表7显示了基于使用LDA的电子邮件内容分析的内部威胁检测的数据格式。“ID”是一个唯一的字符串,用于将特定电子邮件与其他观察结果区分开来。“主题1”到“主题50”列表示分配给每个电子邮件50个主题的概率,并用作异常检测模型的输入变量。请注意,50个主题的概率之和始终为1。“目标”是一个变量,用于指示电子邮件是正常(0)还是异常(1)。表8显示了这三个角色的正常和异常电子邮件数量。我们假设每个角色中的电子邮件主题分布是相似的。因此,如果某封电子邮件的主题分布与其他电子邮件的主题分布明显不同,则应怀疑其为异常/恶意行为。


2.4 基于电子邮件网络的用户活动建模
由于发件人/收件人信息也可从电子邮件日志记录中获得,如表6所示,我们每周构建电子邮件通信网络,并提取量化特征,作为用户活动分析的第三个来源,用于内部威胁检测。根据表6提供的信息,可以构建定向电子邮件通信网络,如图2所示。证书数据的虚拟公司名称为“dtaa”,并使用电子邮件域@dtaa。com。还有21个其他域名。在CERT数据集中,用户使用公司帐户电子邮件域“@dtaa.com”或其他域,如“@gmail.com”。用户向同一部门或同一公司不同部门的用户发送和接收电子邮件。他们还向公司以外的实体发送和接收电子邮件。在本研究中,用户的电子邮件帐户被设置为一个节点,两个电子邮件帐户之间的边缘根据传入和传出电子邮件的数量进行加权。

一旦每周电子邮件通信网络建成,我们为每个用户计算了总共28个特定于网络的量化特征,如附录a表A3所示。这些变量包括个人或商业电子邮件帐户的输入和输出度、根据Jaccard相似度计算的同一帐户两个连续时间戳之间的输入和输出度相似度[27],如等式(1)所示,以及根据介数计算的中心度度量,如等式(2)所示。


其中,gjk是两个节点j和k之间的最短路径数,gjk(Ni)是两个节点j和k之间的最短路径中包含节点i的路径数。当网络中的一个节点对其他节点起桥接作用时,介数中心度往往更高。在四种著名的中心性度量方法中,即度中心性、亲密度中心性、介乎度中心性和特征向量中心性[28],我们使用介乎度中心性来确定特定电子邮件帐户是否在整个电子邮件通信网络中充当信息网关。
在CERT数据集中的4000个用户中,只有四个用户,即CDE1846、CMP2946、DNS1758和HIS1706,发送或接收了不寻常的电子邮件。这些用户的正常和异常电子邮件数量如表9所示。

3. 内部威胁检测
图3显示了本研究中开发的内部威胁检测方法的总体框架。在用户行为建模阶段,将存储在日志系统中的每个用户的行为转换为三种类型的数据集:日常活动摘要、电子邮件内容和电子邮件通信网络。在异常检测阶段,基于这三个数据集训练一类分类算法。一旦有新记录可用,就会将其输入到这三个模型中的一个,以预测潜在的恶意得分。

对于内部威胁检测领域,通常有大量正常用户活动案例可用,而只有少数或没有异常案例可用。在这种情况下,由于缺乏异常类,传统的二进制分类算法无法训练。或者,在实践中,可以在这种不平衡的数据环境中使用单类分类算法[29]。与二值分类不同,单类分类算法只使用正常类数据来学习它们的共同特征,而不依赖于异常类数据。一旦训练了单类分类模型,它将预测新给定实例成为普通类实例的可能性。在本文中,我们采用高斯密度估计(Gauss)、Parzen窗口密度估计(Parzen)、主成分分析(PCA)和K均值聚类(KMC)作为内部威胁检测的一类分类算法,如图4所示。

图4:本文采用了四种异常检测算法。(a) 高斯密度估计,(b)Parzen窗口密度估计(转载自Alpaydin(2014)),(c)主成分分析(PCA)和(d)K-均值聚类(KMC)。
Gauss[30]假设整个正常用户行为案例都来自一个多元高斯分布(图4a),如等式(3)所定义:

因此,训练高斯相当于估计最有可能生成给定数据集的平均向量和协方差矩阵,如等式(4)和(5)所示:

其中,xi是普通训练实例的对象,Xnormal是仅由普通实例组成的整个学习数据集。测试观测的异常分数可以通过使用估计的分布参数估计给定观测的生成概率来确定[31]。
Parzen是一种著名的基于核的非参数密度函数估计方法[32]。Parzen不假设任何类型的先验分布,仅基于给定的观测值,使用核函数K估计概率密度函数,如等式(6)所示:

其中,h是控制估计分布平滑度的核函数的带宽参数。核函数(均匀、三角形、高斯和Epanechnikov)是一个关于原点对称的非负函数,其整数值为1【33】。在本文中,我们使用高斯核函数。通过将某个位置的所有核函数值相加,然后除以观测总数,可以估计给定数据集的密度。如果新观测的密度较低,则很可能是异常的。
PCA是一种统计方法,它可以找到一组新的轴,尽可能保留原始数据集的方差[34]。一旦确定了这些轴,高维原始数据集就可以映射到低维空间,而不会显著丢失信息[15]。求解数据集X的主成分分析∈Rn×p等价于求特征向量矩阵V∈Rn×p和相应的特征值λ1,λ2,⋯,λp(λ1>λ2>⋯>λp)。应用PCA,实例x∈使用前k个特征向量将Rp映射到k维空间(k
V′∈Rn×k由前k个特征向量组成。在主成分分析中,重建误差e(x),即原始向量与其从低维空间重建到原始空间的图像之间的差值,可以用作异常评分:

KMC是一种聚类方法,它将每个观测值(xj)分配给最近的质心(ci),以便分配给相同质心的观测值形成一个聚类[15]:

其中,K是群集数,是算法特定的超参数,必须在执行算法之前确定。在本研究中,我们检查了三个K值(3、5和10)。一旦仅基于正常实例完成KMC,新实例与其最近质心之间的距离信息将用于计算异常分数,如图4d[35]所示。Di是测试实例与其最近质心之间的距离,R是簇的半径(质心与簇中距离质心最远的实例之间的距离)。相对距离Di/R是基于KMC的异常检测中常用的异常分数。
除了个别异常检测算法外,我们还考虑这些算法的组合。即使在学习相同的数据时,为每种算法建立最优模型的方法也不同,因此在机器学习领域,没有哪种算法在所有情况下都优于[36]。在这种情况下,结合不同的技术可能是有利的,因为与单一算法相比,它们通常会提高预测性能[36,37,38,39]。因此,我们检查了四个单独异常检测器的所有可能组合,以确定给定任务和数据集的最佳组合。由于每个算法都有不同的异常分数范围,因此我们使用秩代替分数来生成集合输出。更具体地说,对于每个测试实例,计算集合中每个模型的异常得分排名,并将平均排名的倒数用作集合的异常得分。
4.结果
通常,在大多数实例属于正常类且只有少数实例来自异常类的情况下,仅基于正常数据训练异常检测算法。在这种情况下,无法设置分类模型通常使用的检测截止值。因此,对于基于日常活动的模型和基于电子邮件内容的模型,异常检测器的性能评估如下。首先,将数据集拆分为训练数据集(包含90%随机选择的正常实例)和测试数据集(包含其余10%的正常实例和所有异常实例)。其次,仅基于训练数据集对异常检测算法进行训练。第三,计算测试数据集中实例的异常分数,并按降序排序。最后,我们根据方程式(10)使用七个不同的截止值(1%、5%、10%、15%、20%、25%和30%)计算真实检测率:

为了获得统计上合理的性能,我们对每个异常检测算法重复上述过程30次,并使用前X%的平均真实检测率作为内部威胁检测的性能度量。由于电子邮件网络数据的样本数量不如日常活动数据和电子邮件主要内容数据的样本数量足够,我们使用所有正常实例进行训练,并计算基于电子邮件网络的异常检测模型的所有正常实例和异常实例的异常分数。
4.1 使用日常活动摘要特征的内部威胁检测
表10、表11和表12显示了六个独立异常检测器的内部威胁检测性能,以及我们根据“电气工程师”、“IT管理员”和“推销员”三个角色的日常活动总结数据集确定的最佳组合(即Parzen+PCA)。如前一节所述,我们测试了各个模型的所有组合,“Parzen+PCA”组合在21个案例中的10个案例中表现最好(三个角色,七个截止排名),其次是“Gauss+Parzen+PCA”(5个案例)。附录A中的表A4、表A5和表A6提供了所有可能集合模型的异常检测性能。表A7总结了每个集合模型的最佳情况数。该方法具有良好的检测性能。例如,在高斯预测的“电气工程师”异常得分前1%中,有一半的实际异常行为被成功检测到,这比随机确定1%的测试实例为异常行为的随机模型高出50多倍。
表10。基于每日活动汇总数据集的每个异常检测算法的真实检测率(电气工程师)。最佳性能以粗体和下划线显示(测试集中的正常行为数:14120,测试集中的恶意行为数:10)。
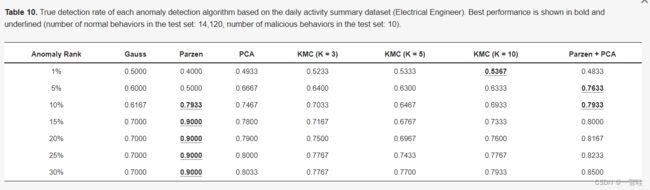
表11。基于每日活动摘要数据集(IT Admin)的每个异常检测算法的真实检测率。最佳性能以粗体和下划线显示(测试集中的正常行为数:3424,测试集中的恶意行为数:23)。

表12。基于每日活动摘要数据集(Saleser)的每个异常检测算法的真实检测率。最佳性能以粗体和下划线显示(测试集中的正常行为数:14120,测试集中的恶意行为数:32)。

对于“电气工程师”角色,当监控前1%的可疑日常行为时,系统最多可以检测到53.66%的实际内部威胁(KMC,K=10)。这意味着,在属于最高异常得分排名1%的141个测试实例中,10个实际恶意行为中有5.367个被正确检测到,这可以通过对可疑行为进行高精度的优先级排序来提高内部监控系统的监控效率。当监测活动的覆盖率分别增加到异常分数的前5%、10%和15%时,该检出率将分别增加到76.33%、79.33%和90%。对于“IT管理员”角色,检测性能不如“电气工程师”明显,但仍比随机猜测模型好得多。真实检测率相对于随机猜测的提升为9.71(截止值为1%)和4.35(截止值为5%)。对于“销售员”角色,虽然检测性能不如“电气工程师”高截止值(1–15%),但当截止值降低(15–30%)时,会逐渐检测到实际的恶意活动。因此,当截止值设置为异常分数的前30%时,Parzen+PCA组合识别出94.79%的实际恶意行为,这是三种角色中最高的检测率(90%用于“电气工程师”,40.87%用于“IT管理员”)。
在单一算法中,Parzen对21例中的8例(7个截止值和3个角色)产生了最佳的检测率。虽然Gauss和Parzen都基于密度估计,但Gauss假设(即整个数据集的单变量高斯分布)过于严格,无法应用于实际数据集,这在许多情况下会导致最差的性能。另一方面,Parzen以更灵活的方式估计概率分布,因此它可以很好地拟合非高斯形状分布。还要注意的是,在大多数情况下,Parzen+PCA组合会产生最佳的检测性能。与单一算法相比,Parzen+PCA在10种情况下的检测性能优于单一最佳算法。模型组合的效果对于“销售员”角色尤为明显。
4.2 基于邮件内容的内部威胁检测
表13、表14和表15显示了基于三个角色的电子邮件内容数据集的六个单独异常检测器的内部威胁检测性能,以及它们的最佳组合,即Parzen+PCA。与日常活动数据集相比,“IT管理员”的异常检测比其他两个角色更成功。Parzen+PCA的检测率为37.56%,最高1%的截止值,而最高30%的截止值的检测率则稳步上升至98.67%。“电气工程师”和“推销员”的异常检测性能相似,真实检测率相对于随机猜测的提升率在4.5以上,截止值为1%,大约三分之二的异常活动是在30%的截止值下检测到的。
表13。基于电子邮件内容数据集的每个异常检测算法的真实检测率(电气工程师)。最佳性能以粗体和下划线显示(测试集中的正常行为数:69405,测试集中的恶意行为数:13)。
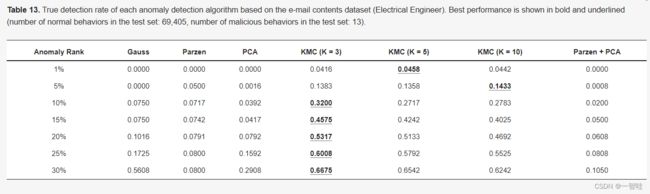
表14。基于电子邮件内容数据集(IT Admin)的每个异常检测算法的真实检测率。最佳性能以粗体和下划线显示(测试集中的正常行为数:17077,测试集中的恶意行为数:15)。
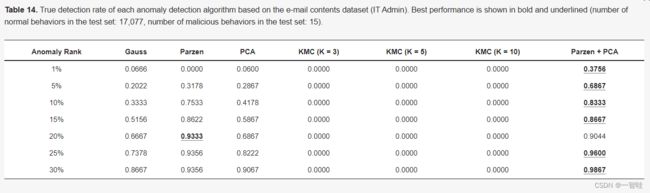
表15。基于电子邮件内容数据集的每种异常检测算法的真实检测率(推销员)。最佳性能以粗体和下划线显示(测试集中的正常行为数:64425,测试集中的恶意行为数:40)。

在异常检测算法中,KMC是“电气工程师”最有效的算法,但没有一种算法对“推销员”的性能最好。另一个值得注意的观察是,单个异常检测算法的性能高度依赖于数据集的特征。Parzen+PCA对“IT管理员”的检测率最高,但对“电气工程师”和“推销员”的检测效果不佳。另一方面,KMC对“电气工程师”的检测率最高,但未能检测到任何针对“it管理员”的实际恶意电子邮件。
4.3 基于邮件网络特征的内部威胁检测
对于4000名用户中的电子邮件通信历史数据集,有四名用户(CDE1846、CMP2946、DNS1758和HIS1706)发送或接收了大量不寻常的电子邮件。表16、表17、表18和表19显示了基于电子邮件通信网络数据集的异常检测模型的用户级内部威胁检测性能。
表16。基于电子邮件通信网络数据集(CDE1846)的每种异常检测算法的真实检测率。最佳性能以粗体和下划线显示(测试集中的正常行为数:456,测试集中的恶意行为数:9)。

表17。基于电子邮件通信网络数据集(CMP2946)的每种异常检测算法的真实检测率。最佳性能以粗体和下划线显示(测试集中的正常行为数:474,测试集中的恶意行为数:7)。

表18。基于电子邮件通信网络数据集(DNS1758)的每种异常检测算法的真实检测率。最佳性能以粗体和下划线显示(测试集中的正常行为数:498,测试集中的恶意行为数:3)。

表19。基于电子邮件通信网络数据集(HIS1706)的每种异常检测算法的真实检测率。最佳性能以粗体和下划线显示(测试集中的正常行为数:493,测试集中的恶意行为数:3)。

值得注意的是,三个用户(CDE1846、DNS1758和HIS1706)的所有恶意电子邮件通信都通过异常检测算法成功检测到,最多使用25%的截止值。令人惊讶的是,Gauss通过仅监视用户CDE1846的前5%的可疑实例,获得了100%的检测率,而KMC通过监视前10%的可疑实例,成功地检测到了用户HIS1706的所有恶意实例。唯一的异常用户是CMP2946,对其而言,异常检测模型未能检测到超过30%的实际恶意电子邮件通信,尽管截止值降低到异常分数的前30%。另一个有趣的观察结果是,与其他两个数据集不同,模型组合并没有实现比单个模型更好的检测性能。对于每个用户来说,最好的算法是针对CDE1846的高斯算法和针对HIS1706的KMC算法。对于其他两个用户,没有一个算法对所有截止值产生最高的检测率。
5. 结论
本文提出了一种基于用户行为建模和异常检测算法的内部威胁检测框架。在用户行为建模过程中,将单个用户的异构行为转换为结构化数据集,其中每一行与一个实例(用户日、电子邮件内容、用户周)关联,每一列与异常检测模型的输入变量关联。基于CERT数据集,我们构建了三个数据集,即基于用户活动日志的日常活动摘要数据集、基于主题建模的电子邮件内容数据集和基于用户帐户和发送/接收信息的电子邮件通信网络数据集。基于这三个数据集,我们利用基于机器学习的异常检测算法构建了内部威胁检测模型,以模拟只有少数内部人员的行为实际上具有潜在恶意的真实世界组织。
实验结果表明,该框架能够很好地检测内部人的恶意行为。基于每日活动摘要数据集,异常检测模型仅监控前1%的可疑实例,最多产生53.67%的检测率。当监测覆盖范围扩大到异常得分的前30%时,在三个被评估角色中,超过90%的实际异常行为被检测到。根据电子邮件内容数据集,最多有37.56%的恶意电子邮件被检测到,截止值为1%,而当监测前30%的可疑电子邮件时,检测率上升到65.64%(最多98.67%)。根据电子邮件通信网络数据集,四分之三的测试用户正确识别了所有恶意实例。
虽然所提出的框架得到了实证验证,但目前的研究仍存在一些局限性,这将引导我们走向未来的研究方向。首先,我们构建了三个结构化数据集来训练异常检测算法。由于这三个数据集的实例彼此不同(用户的日常活动、电子邮件的主题分发、用户的每周电子邮件通信),因此基于每个数据集独立训练异常检测模型。如果这些不同的异常检测结果得到适当集成,就有可能实现更好的内部威胁检测性能。其次,我们建立了基于特定时间单位(例如一天)的内部威胁检测模型。换句话说,这种方法可以检测基于批处理的恶意行为,但不能实时检测。因此,有必要开发一种基于序列的内部威胁检测模型,该模型可以处理在线流数据。第三,提出的模型纯粹是数据驱动的。然而,在安全领域,结合专家知识和纯数据驱动的机器学习模型可以提高内部威胁检测性能。最后,尽管CERT数据集是精心构建的,包含了领域专家设计的各种威胁场景,但它仍然是一个模拟和人工生成的数据集。如果所提出的框架能够通过真实世界的数据集进行验证,那么它的实际适用性就可以得到更多验证。