c++高级编程学习笔记3
函数指针的类型别名
我们通常不考虑函数在内存中的位置,但每个函数实际上都位于某个特定地址。在 C++中,可像使用数据那样使用函数。换言之,可使用函数的地址,就像使用变量那样。函数指针的类型取决于兼容函数的参数类型的返回类型。处理函数指针的一种方式是使用类型别名。类型别名允许将一个类型名指定给具有指定特征的一系列函数。例如,下面的代码行定义了 MatchFunction 类型,该类型表示一个指针,这个指针指向具有两个 int 参数并返回布尔值的任何函数:
using MatchFunction = bool(*) (int,int)
有了这个新类型,可编写将 MatchFunction 作为参数的函数。例如,以下函数接收两个 int 数组及其大小,还接收 MatchFunction。它并行迭代数组,并在两个数组的相应元素上调用 MatchFunction。如果调用返回 true,就打印消息。注意,即使将 MatchFunction 作为变量传入,也仍可像普通函数那样调用它:
void findMatches(int values1[],int value2[],size_t numValues,MatchFunction matcher)
{
for(size_t i = 0;i<numValues;i++)
{
if(matcher(values[i],values2[i]))
{
cout<<"Match found at position "<<i<<"(" <<values1[i] << "," << values2[i]<<")"<<endl;
}
}
}
注意,该实现要求两个数组至少有 numValues 个元素。要调用 findMatches()函数,所需要的就是符合所定义的 MatchFunction 类型的任何函数,即接收两个 int 参数并返回布尔值的函数。例如,考虑以下函数,如果两个参数相等,就返回 true:
bool intEqual(int item1,int item2)
{
return item1 == item2;
}
由于 intEqual()函数与 MatchFunction 类型匹配,可将其作为 fndMatches()的最后一个参数进行传递,如下所示:
int arr1[] = { 2, 5, 6, 9, 10, 1, 1 };
int arr2[] = { 4, 4, 2, 9, 0, 3, 4 };
size_t arrSize = std::size(arr1); // Pre-C++17: sizeof(arr1)/sizeof(arr1[0]);
cout << "Calling findMatches() using intEqual():" << endl;
findMatches(arr1, arr2, arrSize, &intEqual);
通过地址方式将 intEqual()函数传入 findMatches()函数。在技术上,&x字符是可选的,可以只用一个函数名,编译器知道它表示函数的地址。输出如下所示:
Calling findMatches() using intEqual();
Match found at position 3(9,9)
函数指针的好处在于 findMatches0)是比较两个数组中对应值的通用函数。参考上例中的用法,这个函数根据相等性比较两个数组。然而,因为它接收一个函数指针,所以可根据其他标准进行比较。例如,下面的函数也遵循 MatchFunction 的定义:
bool bothOdd(int item1,int item2)
{
return item1 % 2 == 1 && item2 % 2 == 1;
}
下面的代码在调用 findMatches()时使用了 bothOdd:
cout<<"Calling findMatches() using bothOdd() :"<<endl;
findMatches(arr1,arr2,arrSize,&bothOdd);
注意:
如果不使用这些旧式的函数指针,还可以使用 std::function,详情请参阅第 18 章。
考虑一个 DLL(动态链接库),这个 DLL 有一个名为 Connect()的函数。只有需要调用 Connect()时,才会加载这个 DLL。这个在运行时加载的 DLL 由 Windows 的 LoadLibrary()核心调用完成;
HMODULE lib = ::LoadLibrary("hardware.dll");
这个调用的结果就是所谓的“库句柄”,如果发生错误,结果就是NULL。从库加载函数前,需要知道这个函数的原型。假定下面就是 ConnectO函数的原型,这个函数返回一个整数,接收 3 个参数: 一个布尔值、一个整数和一个 C 风格的字符串。
int _stdcall Connect(bool b, int n,const char* p);
_ stdcall 是 Microsoft 特有的指令,指示如何将参数传递到函数以及如何执行清理。现在可使用类型别名为指向函数的指针定义一个缩写名称(ConnectFunction),该函数具有前面所示的原型;
using ConnectFunction = int(_stdcall*)(bool,int,const char*);
在成功加载库并定义函数指针的简短名称后,可获取指向库函数的指针,如下所示:
ConnectFunction connect = (ConnectFunction)::GetProcAddress(lib,"Connect");
如果这个过程失败,connect 将是 nullptr。如果成功,就可采用以下方式调用被加载的函数;
connect(true,3,"Hello world");
C 程序员可能认为在调用函数前,需要对函数指针解引用,如下所示;
(*connect)(true,3,"Hello world");
可创建和使用变量及函数的指针。下面考虑类数据成员和方法的指针。在 C++中,取得类成员和方法的地址,获得指向它们的指针是完全合法的。但不能访问非静态成员,也不能在没有对象的情况下调用非静态方法。类数据成员和方法完全依赖于对象的存在。因此,通过指针调用方法或访问数据成员时,一定要在对象的上下文中解除对指针的引用。下面举一个例子,使用第 1 章介绍的 Employee 类:
Employee employee
int (Employee::*methodPtr)() const = &Employee::getSalary;
cout<<(Employee.*methodPtr)()<<endl;
不必担心上述语法。第二行声明了一个指针类型的变量 methodPtr,该指针指向 Employee 类的一个非静态const 方法,这个方法不接收参数并返回一个 int 值。同时,这行代码将这个变量初始化为指向 Employee 类的getSalary()方法。这种语法和声明简单函数指针的语法非常类似, 只不过在smethodPtr 的前面添加了 Employee::。还要注意,在这种情况下需要使用&。第 3 行代码调用 myCell 对象的 getSalary()方法(通过 methodPtr 指针)。注意在 employlee.*smethodPtr 的周围使用了括号。这些括号是必要的,因为0的优先级比*高。可通过类型别名简化第二行代码
Employee employee;
using PtrToGet = int(Employee::*)()const;
PtrToGet methodPtr = &Employee::getSalary;
cout<<(employee.*methodPtr)()<<endl;
使用 auto 可进一步简化:
Employee employee;auto methodPtr = &Employee::getSalary;cout<<(employes.*methodPtr())<<endl;
注意:
可通过使用 std::mem_fn()来丢弃(.9语法。第 18 章的函数对象上下文将对此进行解释。
类型转换
C++还提供了 4 种类型转换: const_cast()、static_cast()、reinterpret_cast()和 dynamic_cast()。使用()的 C 风格类型转换在 C++中仍然有效,并且在已有的代码中使用广泛。C++风格的类型转换包含这4 种 C++类型转换,但较容易出错,因为得到的结果并不注释很明显,也可能得到意想不到的结果。强烈建议在新代码中仅使用 C++风格的类型转换,因为它们更安全,在语法上更优秀。本节讲述这些 C++类型转换的目的,并指出使用它们的时机。
- const_cast( )
const_cast( )最直接,可用于给变量添加常量特性,或去掉变量的常量特性。这是上述 4 种类型转换中唯一可舍弃常量特性的类型转换。当然从理论上讲,并不需要 const 类型转换。如果某个变量是 const,那么应该一直是 const。然而实际中,有时某个函数需要采用 const 变量,但必须将这个变量传递给采用非 const 变量作为参数的函数“正确的”解决方案是在程序中保持 const 的一致,但是这并非唯一选择,特别是在使用第三方库时。因此,有时需要舍弃变量的常量特性,但只有在确保调用的函数不修改对象的情况下才能这么做,否则就只能重新构建程序。下面是一个示例
extern void ThirdPartyLibraryMethod(char*str);void f(const char* str){ ThirdParityLibraryMethod(const_cast<char*>(str));}
们 从 C++17 开始,中定义了一个辅助方法 std::as_const(),该方法返回引用参数的 const 引用版本。as_const(obj)基本上等同于 const_cast
std::string str = "C++";const std::string& constStr = std::as_const(str);
将 as_const()与 auto 一起使用时要保持警惕。回顾第 1 章可知,auto 将去除引用和 const 限定符! 因此,下面的 result 变量具有类型 std::string 而非 const std::string&:
auto result = std::as_const(str);
- static_cast( )
可使用 static_cast( )显式地执行 C++语言直接支持的转换。例如,如果编写了一个算术表达式,其中需要将int 转换为 double 以避免整除,可以使用 static_cast( )。在这个示例中,使用带参数 i 的 static_cast( )就足够了,因为只要把两个操作数之一设置为 double,就可确保 C++执行浮点数除法:
int i = 3;int j = 4;double result = static_cast<double>(i) / j;
如果用户定义了相关的构造函数或转换例程,也可使用 static_cast( )执行显式转换。例如,如果类 A 的构造函数将类 B 的对象作为参数,就可使用 static_cast( )将 B 对象转换为 A 对象。许多情况下都需要这一行为,然而编译器会自动执行这个转换。static_cast( )的另一种用法是在继承层次结构中执行向下转换。例如,
class Base{ public: virtual ~Base() = default;};class Derived : public Base{ public: virtual ~Derived() = default;};int main(){ Base* b; Derived* d = new Derived(); b = d; d = static_cast<Derived*>(b); Base base; Derived derived; Base& br = derived; Derived& dr = static_cast<Derived&>(br); return 0;}
这种类型转换可以用于指针和引用,而不适用于对象本身。注意 static_cast( )类型转换不执行运行期间的类型检测。它允许将任何 Base 指针转换为 Derived 指针,或将Base 引用转换为 Derived 引用,哪怕在运行时 Base 对象实际上并不是 Derived 对象,也是如此。例如,下面的代码可以编译并执行,但使用指针 d 可能导致灾难性结果,包括内存重写超出对象的边界。
Base* b = new Base();Derived* d = static_cast<Derived*>(b);
为执行具有运行时检测功能的更安全的类型转换,可以使用稍后介绍的 dynamic_cast()。static_cast()并不是全能的。使用 static_cast()无法将某种类型的指针转换为不相关的其他类型的指针。如果没有可用的转换构造函数,static_cast()无法将某种类型的对象直接转换为另一种类型的对象。static_cast()法将 const 类型转换为非 const 类型,无法将指针转换为int。基本上,无法完成 C++类型规则认为没意义的转换。
- reinterpret_cast( )
reinterpret_cast( )的功能比 static_cast()更强大,同时安全性更差。可以用它执行一些在技术上不被 C++类型规则允许,但在某些情况下程序员又需要的类型转换。例如,可将某种引用类型转换为其他引用类型,即使这两个引用并不相关。同样,可将某种指针类型转换为其他指针类型,即使这两个指针并不存在继承层次上的关系。这种用法经常用于将指针转换为 void*这可隐式完成,不需要进行显式转换。但将 void*转换为正确类型的指针需要 reinterpret_cast0)。void*指针指向内存的某个位置。void*指针没有相关的类型信息。下面是一些示例:
class X{};
class Y{};
int main()
{
X x;
Y y;
X* xp = &x;
Y* yp = &y;
// Need reinterpret cast for pointer conversion from unrelated classes
// static_cast does't work
xp = reinterpret_cast<X*>(yp);
// No cast required for conversion from pointer to void*
void *p = xp;
// Need reinterpret cast for pointer conversion from void*
xp = reinterpret_cast<X*>(p);
// Need reinterpret cast for reference conversion from unrelated classes
// static_cast doesn't work
X& xr = x;
Y& yr = reinterpret_cast<Y&>(x);
return 0;
}
reinterpret_cast()的一种用法是与普通可复制类型的二进制 io一起使用。所谓普通可复制类型,是指构成对象的基础字节的类型可复制到数组中。如果此后要将数组的数据复制回对象,对象将保持其原始值。例如,可将这种类型的单独字节写入文件中。将文件读入内存时,可使用 reinterpret cast()来正确地解释从文件读入的字节。但一般而言,使用 reinterpret_cast( )时要特别小心,因为在执行转换时不会执行任何类型检测 。
警告
理论上,还可使用 reinterpret_cast()将指针转换为 int,或将 int 转换为指针,只能将指针转换为足以容纳它的int 类型。例如,使用 reinterpret_cast()将 64 位的指针转换为 32 位的整数会导致编译错误。
- dynamic_cast( )
dynamic_cast( )为继承层次结构内的类型转换提供运行时检测。可用它转换指针或引用。dynamic_cast( )在运行时检测底层对象的类型信息。如果类型转换没有意义,dynamic_cast( )将返回一个空指针(用于指针)或抛出-个 std::bad_cast 异常(用于引用)。例如,假设具有以下类层次结构:
class Base{ public: virtual ~Base() = default;};class Derived : public Base{ public: virtual ~Derived() = default;};
下例显示了 dynamic_cast()的正确用法:
Base* b;Derived* d = new Derived();b = d;d = dynamic_cast<Derived*>(b);
下面用于引用的 dynamic_cast( )将抛出一个异常;
Base base;Derived derived;Base& br = base;try{ Derived& dr = dynamic_cast<Derived&>(br);}catch(const bad_cast&){ cout<<"Bad cast!"<<endl;}
注意可使用 static_cast( )或 reinterpret_cast( )沿着继承层次结构向下执行同样的类型转换。dynamic_cast( )的不同之处在于它会执行运行时(动态)类型检测,而 static_cast( )和 reinterpret_cast( )甚至会执行不正确的类型转换。如第 10 章所述,运行时类型信息存储在对象的虚表中。因此,为使用dynamic cast(),类至少要有一个虚方法。如果类不具有虚表,举试使用 dynamic_cast())将导致编译错误。例如,在 Microsof VC++中,将给出以下错误:
error C2683: 'dynamic_cast' : "MYClass' is not a polymorphic type.
- 类型转换总结
表 11-1 总结了不同情形下应该使用的类型转换。
| 情形 | 类型转换 |
|---|---|
| 删除 const 特性 | const_cast() |
| 显式地执行语言支持的类型转换(例如,将 int 转换为 double,将 int 转换为bool) | static_cast() |
| 显式地执行用户自定义构造函数或转换例程支持的类型转换 | static_cast() |
| 将某个类的对象转换为其他(无关)类的对象 | 无法完成 |
| 将某个类对象的指针(pointer-to-objecb)转换为同一继承层次结构中其他类对象的指针 | static_cast()或 dynamic_cast()(推荐) |
| 将某个类对象的引用(reference-to-objecb)转换为同一继承层次结构中其他类对象 的引用 | static_cast()或 dynamic_cast()(推荐) |
| 将某种类型的指针转换(pointer-to-type)为其他无关类型的指针 | reinterpret_cast() |
| 将某种类型的引用转换(reference-to-type)为其他无关类型的引用 | reinterpret_cast() |
| 将某个函数指针(pointer-to-functiom)转换为其他函数指针 | reinterpret_cast() |
作用域解析
有时某个作用域内的名称会隐藏其他作用域内的同一名称。在另一些情况下,程序的特定行中的默认作用域解析并不包含需要的作用域。如果不想用默认的作用域解析某个名称,就可以使用作用域解析运算符::和特定的作用域限定这个名称。例如,为访问类的静态方法,第一种方法是将类名(方法的作用域)和作用域解析运算符放在方法名的前面,第二种方法是通过类的对象访问这个静态方法。下例演示了这两种方法。这个示例定义了一个具有静态方法 get()的 Demo类、一个具有全局作用域的get()函数以及一个位于NS 名称空间的 get()函数。
class Demo{ public: static int get(){ return 5;}};int get(){ return 10; }namespace NS{ int get(){return 20;}}
全局作用域没有名称,但可使用作用域解析运算符本身(没有名称前缀)来访问。可采用以下方式调用不同的 get()函数。在这个示例中,代码本身在 main()函数中,main()函数总是位于全局作用域内:
int main(){ auto pd = std::make_unique<Demo>(); Demo d; std::cout<<pd->get()<<std::endl; //prints 5 std::cout<
注意,如果 NS 名称空间是一个匿名名称空间,下面的行将导致名称解析歧义错误,因为在全局作用域内定义了一个 get()函数,在匿名名称空间中也定义了一个 get()函数。
std::cout<<get()<<std::endl;
如果在 main()函数之前使用 using 子句,也会发生同样的错误:
using namespace NS;
特性
特性(attribute)是在源代码中添加可选信息(或者供应商指定的信息)的一种机制。在 C++11 之前,供应商决定如何指定这些信息,例如_attribute_和_ declspec 等。自 C++11 以后,使用两个方括号语法[fattribute]]支持特性。C++标准只定义了 6 个标准特性。其中的[[carries_dependency]]是一个相当怪异的特性,此处不予讨论。下面将介绍其他几个特性。
[[noreturn]]特性
[[Inoreturn]]意味着函数永远不会将控制交还调用点。典型情况是函数导致某种终止(进程终止或线程终止)或者抛出异常。使用该特性,编译器可避免给出某种警告或错误,因为它现在对函数的意图了解更多。下面是一个例子
[[noreturn]] void forceProgramTermination(){ std::exit(1);}bool isDongleAvailable(){ bool isAvailable = false; // Check whether a licensing dongle is available... return isAvailable;}bool isFeatureLicensed(int featureId){ if (!isDongleAvailable()) { // No licensing dongle found, abort program execution! forceProgramTermination(); } else { bool isLicensed = false; // Dongle available, perform license check of the given feature... return isLicensed; }}int main(){ bool isLicensed = isFeatureLicensed(42);}
这个代码片段可正常编译,不会发出任何警告或错误。但如果删除[[noretum]]特性,编译器将生成以下警告消息(Visual C++的输出);warning C4715: ,isFeatureLicensed’: not all control paths return a value
[[deprecated]]特性
- [[deprecated]]特性可用于把某个对象标记为废弃,表示仍可以使用,但不鼓励使用。这个特性接收一个可选参数,可用于解释废弃的原因,例如:
[[deprecated("Unsafe method, please use xyz")]] void func();
如果使用这个特性,将看到编译错误或警告。例如,GCC 会给出以下警告消息:
warning: 'void func()' is deprecated: Unsafe method, please use xyz
[[fallthrough]]特性
从 C++17 开始,可使用[lthrough]]特性告诉编译器: 在 switch 语句中,fall through 是有意安排的。如果没有指定该特性,用以说明这是有意为之的,编译器将给出警告消息。不需要为空的 case 分支指定这个特性,例如:
switch (backgroundColor) { case Color::DarkBlue: doSomethingForDarkBlue(); [[fallthrough]]; case Color::Black: // Code is executed for both a dark blue or black background color doSomethingForBlackOrDarkBlue(); break; case Color::Red: case Color::Green: // Code to execute for a red or green background color break;}
[[nodiscard]]特性
[[nodiscard]]特性可用于返回值的函数,如果函数什么也没做,还返回值,编译器将发出警告消息。下面是一个示例:
[[nodiscard]] int func(){ return 42;}int main(){ func(); return 0;}
编译器将给出如下警告消息:
warning: ignoring return value of ‘int func()’, declared with attribute nodiscard [-Wunused-result]
例如,可将这个特性用于返回错误代码的函数。通过给此类函数添加[[nodiscard]]特性,将无法忽略错误代码。
[[maybe_unused]]特性
如果未使用某项,[[maybe_unused]]特性可用于阻止编译器发出警告消息:
int func(int param1,int param2){ return 42;}
如果将编译器警告级别设置得足够高,这个函数定义将导致两个编译器警告。例如,Microsoft VC++给出
下列警告;
warning C4100: "param2’: unreferenced formal parameter
warning C4100: "paraml’: unreferenced formal Parameter
通过使用[[maybe_unused]]特性,可以阻止显示此类警告消息:
int func(int param1,[[maybe_unused]] int param2){ return 42;}
这里给第二个参数标记了[[maybe_unused]]特性。编译器将只为 paraml 显示警告消息:
warning C4100: "paraml’: unreferenced formal Parameter
用户定义的字面量
C++有许多可在代码中使用的标准字面量(litera),如下所示。
下例使用熟模式字面量运算符实现了用户定义的字面量 i,_i 用来定义一个复数字面量。
std::complex<long double> operator""_i(long double d){ return std::complex<long double>(0,d);}
_i字面量可这样使用,
std::complex<long double> c1 = 9.634_i;auto c2 = 1.23_i;// c2 has as type std::complex另一个示例用热模式字面量运算符实现了用户定义的字面量 s, 用于定义 std::string 字面量:
std::string operator"" _s(const char* str, size_t len){ return std::string(str, len);}
字面量可这样使用,
std::string str1 = "Hello World"_s;auto str2 = "Hello World"_s;// str2 has as type std::string
标准的用户定义字面量
C++定义了如下标准的用户定义字面量。注意,这些标准的用户定义字面量并非以下画线开头:
“s”用于创建 std::string
例如: auto mystring = "Hello World"s;
需要 using namespace std::string_literals;
“sv”用于创建 std::string_views
例如:,auto mystringView = "Hello World"sv;
需要 using namespace std::string_view_literals;
“h”“min”“s”“ms”“us”“ns”用于创建 std::chrono::duration 时间段,参见第 20 章
例如:, auto mypuration = 42min;
需要 using namespace std: :chrono_literalsy
“ii”“il”“if” 分别用于创建复数 complex 、complex 和 complex
例如:,auto mycomplexNumber = 1.3i;
需要 using namespace std::complex_literals;
头文件
头文件是为子系统或代码段提供抽象接口的一种机制。使用头文件需要注意的一点是: 要避免循环引用或多次包含同一个头文件。例如, 假设 A.h 包含 Logger.h, 里面定义了一个 Logger 类; B.h 也包括 Logger.h。 如果有一个源文件 App.cpp包含 A.h 和 B.h,最终将得到 Logger 类的重复定义,因为 A.h 和 B.h 都包含 Logger.h 头文件。可使用文件保护机制(include guards)来避免重复定义。下面的代码片段显示了包含文件保护机制的 Logger.h头文件。在每个头文件的开头,用#ifndef 指令检测是否还没有定义某个键值。如果这个键值已经定义,编译器将跳到对应的#endif,这个指令通常位于文件的结尾。如果这个键值没有定义,头文件将定义这个键值,这样以后包含的同一文件就会被忽略。
#ifndef LOGGER_H#define LOGGER_Hclass Logger{};#endif
如今,几乎所有编译器都支持#pragma once 指令(该指令可替代前面的文件保护机制)。例如:
#pragma onceclass Logger{}
前置声明是另一个避免产生头文件问题的工具。如果需要使用某个类,但是无法包含它的头文件(例如,这个类严重依赖当前编写的类),就可告诉编译器存在这么一个类,但是无法使用#include 机制提供正式的定义。当然,在代码中无法真正地使用这个类,因为编译器对此一无所知,只知道在链接之后存在这个已命名的类。然而,仍可在代码中使用这个类的指针或引用。也可声明函数,使其按值返回这种前置声明类,或将这种前置声明类作为按值传递的函数参数。当然,定义函数的代码以及调用函数的任何代码都需要添加正确的头文件,在头文件中要正确定义前置声明类。例如,假设 Logger 类使用另一个类 Preferences(跟踪用户设置)。Preferences 类又使用 Logger 类,由于产生了循环依赖,因此无法使用文件保护机制来解决。此时需要使用前置声明。在下面的代码中,Logger.h 头文件为 Preferences 类使用前置声明,后来在引用 Preferences 类时未包含其头文件。
#pragma once#include <string_view>class Preference; //forward declarationclass Logger{ public: static void setPreference(const Preferences& prefs); static void logError(std::string_view error);}
建议尽可能在头文件中使用前置声明,而不是包含其他头文件。这可减少编译和重编译时间,因为破坏了一个头文件对其他头文件的依赖。当然,实现文件需要包含前置声明类的正确头文件,否则就不能编译。 为了查询是否存在某个头文件,C++17 添加了_has_include("filename和_ has_include()预处理器常量。如果头文件存在,这些常量的结果就是 1; 如果头文件不存在,常量的结果就是 0。例如,在为 C++17完全批准头文件之前,存在预备版 本。可以使用_has include()来检查系统上有哪个头文件:
#if __has_include(<optional>)#include <optional>#elif __has_include(<experimental/optional>)#include <experimental/optional>#endif
C 的实用工具
某些上涩的 C 功能在 C++中也可用,并且在某些情况下仍然有用。本节讲述两个功能,变长参数列表(variable-length argument lists)和预处理器宏(preprocessor macros)。
变长参数列表
本节介绍旧的 C 风格变长参数列表。你应该理解其运行方式,因为在比较老的代码中会看到它们。然而,在新的代码中应该通过 variadic 模板使用类型安全的变长参数列表,variadic 模板将在第 22 章介绍。
考虑中的 C 函数 printf()。可使用任意数量的参数调用这个函数:
printf("int %d\n", 5);printf("String %s and int %d\n", "hello", 5);printf("Many ints: %d, %d, %d, %d, %d\n", 1, 2, 3, 4, 5);
C/C++提供了语法和一些实用宏,以编写参数数目可变的自定义函数,这些函数通常看上去很像 printf()。尽管并非经常需要,但是偶尔需要这个功能。例如,假定要编写一个快速调试函数,如果设置了调试标记,这“个函数向 stderr 输出字符串,如果没有设置调试标志,就什么都不做。与 printf()一样,这个函数应能接收任意数目和类型的参数并输出字符串。这个函数的简单实现如下所示;
#include 首先,注意 debugOut()函数的原型包含一个具有类型和名称的参数 str,之后是.…(省略号),这代表任意数目和类型的参数.为访问这些参数, 必须使用中定义的宏。声明一个 va_list类型的变量, 并调用 va_start()来初始化它。va_start()的第二个参数必须是参数列表中最右边的已命名变量。所有具有变长参数列表的函数都至少应该有一个已命名参数。debugOut()函数只是将列表传递给 vfprintf()(中的标准函数)。当 vfprintf()返回时,debugOut()调用 va_end()来终止对变长参数列表的访问。在调用 va_start()之后必须调用 va_end(),以确保函数结束后,堆栈处于稳定状态。
访问参数
如果要自行访问实参,可使用 va_arg(); 它的第一个实参是 va_list,接收要截获的实参类型。遗憾的是,如果不提供显式的方法,就无法知道参数列表的结尾是什么。例如,可以让第一个参数计算参数的数目,或者当参数是一组指针时,可以要求最后一个指针是 nullptr。方法有很多,但对于程序员来说,所有方法都很麻烦。下例演示了这种技术,其中调用者在第一个已命名参数中指定了所提供参数的数目。函数接收任意数目的int 参数,并将其输出。
void printInts(size_t num, ...){ int temp; va_list ap; va_start(ap, num); for (size_t i = 0; i < num; ++i) { temp = va_arg(ap, int); cout << temp << " "; } va_end(ap); cout << endl;}
可以用下面的方法调用 printInts()。注意第一个参数指定了后面整数的数目;
printInts(5, 5, 4, 3, 2, 1);
警告:
避免使用 C 风格的变长参数列表。 传递 std::array、值矢量或者使用第 1 章介绍的初始化列表会更好。也可以通过 variadic 模板使用类型安全的变长参数列表,这一主题将在第 22 章讲述。
类模板
类模板定义了一个类,其中,将一些变量的类型、方法的返回类型和/或方法的参数类型指定为参数。类模板主要用于容器,或用于保存对象的数据结构。本节使用一个 Grid 容器作为示例。为了让这些例子长度合理,上且足够简单地演示特定的知识点,本章中不同的小节会向 Grid 容器添加一些接下来的几节不会用到的功能。
\1. 编写不使用模板的代码
如果不使用模板,编写通用棋盘最好的方法是采用多态技术,保存通用的 GamePiece 对象。然后,可让每种游戏的棋子继承 GamePiece 类。例如,在象棋游戏中,ChessPiece 可以是 GamePiece 的派生类。通过多态技术,能保存 GamePiece 的 GameBoard 也能保存 ChessPiece。GameBoard 可以复制,所以 GameBoard 需要能复制 GamePiece。这个实现利用了多态技术, 所以一种解决方法是给 GamePiece 基类添加虚方法 clone()。GamePiece基类如下:
class GamePiece
{
public:
virtual std::unique_ptr<GamePiece>clone() const = 0;
};
GamePiece 是一个抽象基类。ChessPiece 等具体类派生于它,并实现了 clone()方法:
class ChessPiece : public GamePiece
{
public:
virtual std::unique_ptr<GamePiece> clone() const override;
};
std::unique_ptr<GamePiece> ChessPiece::clone() const
{
//Call the copy constructor to copy this instance
return std::make_unique<ChessPiece>(*this);
}
GameBoard 的实现使用 unique_ptr 矢量的矢量存储 GamePiece。
class GameBoard{ public: explicit GameBoard(size_t width = kDefaultWidth,size_t height = kDefaultHeight); GameBoard(const GameBoard& src); //copy constructor virtual ~GameBoard() = default; //virtual defaulted destructor GameBoard& operator=(const GameBoard& rhs); //assignment operator GameBoard(GameBoard&& src) = default; GameBoard& operator=(GameBoard&& src) = default; std::unique_ptr & at(size_t x,size_t y); const std::unique_ptr& at(size_t x,size_t y) const; size_t getHeight() const{ return mHeight; } size_t getWidth() const{ return mWidth; } static const size_t kDefaultWidth = 10; static const size_t kDefaultHeight = 10; friend void swap(GameBoard& first, GameBoard& second) noexcept; private: void verifyCoordinate(size_t x,size_t y) const; std::vector>>mCells; size_t mWidth,mHeight;}
在这个实现中,at()返回指定位置的棋子的引用,而不是返回棋子的副本。GameBoard 用作一个二维数组的抽象,所以它应给出实际对象的索引,而不是给出对象的副本,以提供数组访问语义。客户代码不应存储这个引用供将来使用,因为它可能是无效的,而应在使用返回的引用之前调用 at()。这遵循了标准库中 std::vector类的设计原理。
注意
GameBoard 类的这个实现提供了 at()的两个版本,一个版本返回引用,另一个版本返回 const 引用。下面是方法定义。注意,这个实现为赋值运算符使用了“复制和交换”惯用语法,还使用 Scott Meyer 的const_cast()模式来避免代码重复,第 9 章讨论了这些主题。
GameBoard::GameBoard(size_t width,size_t height) :mWidth(width),mHeight(height) { mCells.resize(mWidth); for(auto& column : mCells) { column.resize(mHeight); } }GameBoard::GameBoard(const GameBoard& src) :GameBoard(src.mWidth,src.mHeight) { // The ctor-initializer of this constructor delegates first to the // non-copy constructor to allocate the Proper amount of memory. // The next step is to copy the data- for(size_t i = 0; i < mWidth; i++) { for(size_t j = 0;j < mHeight; j++) { if(src.mCells[i][j]) mCells[i][j] = src.mCells[i][j]->clone(); } } }void GameBoard::verifyCoordinate(size_t x,size_t y) const{ if(x >= mWidth || y >= mHeight) throw std::out_of_range("");}void swap(GameBoard& first, GameBoard& second) noexcept{ using std::swap; swap(first.mWidth,second.mWidth); swap(first.mHeight,second.mHeight); swap(first.mCells,second.mCells);}GameBoard& GameBoard::operator=(const GameBoard& rhs){ //Check for self-assignment if(this == &rhs) return *this; //Copy-and-swap idiom GameBoard temp(rhs); //Do all the work in a temporary instance swap(*this,temp); //Commit the work with only non-throwing operations return *this;}const unique_ptr& GameBoard::at(size_t x,size_t y) const{ verifyCoordinate(x,y); return mCells[x][y];}unique_ptr& GameBoard::at(size_t x,size_t y){ return const_cast&>(as_const(*this).at(x,y));}
这个 GameBoard 类可以很好地完成任务。
GameBoard chessBoard(8,8);auto pawn = std::make_unique<ChessPiece>();chessBoard.at(0,0) = std::move(pawn);chessBoard.at(0,1) = std::make_unique<ChessPiece>();chessBoard.at(0,1) = nullptr;
- 模板 Grid 类
前面定义的 GameBoard 类很好,但不够完善。第一个问题是无法使用 GameBoard 来按值存储元素,它总是存储指针。另一个更重要的问题与类型安全相关。GameBoard 中的每个网格都存储 unique_ptr。即使存储 ChessPiece,当使用 at()来请求某个网格时,也会得到 unique_ptr。这意味着,只有将检索到的 GamePiece 向下转换为 ChessPiece,才能使用 ChessPiece 的特定功能。GameBoard 的另一个缺点是不能用来存储原始类型,如 int 或 double,因为存储在网格中的类型必须从 GamePiece 派生。因此,最好编写一个通用的 Grid 类,该类可用于存储 ChessPiece、SpreadsheetCell、int 和 double 等。在C++中,可通过编写类模板来实现这一点,编写类模板可避免编写需要指定一种或多种类型的类。客户通过指定要使用的类型对模板进行实例化。这称为泛型编程,其最大的优点是类型安全。类及其方法中使用的类型是具体的类型,而不像多态方案中的抽象基类类型。例如,假设不仅是ChessPiece,还是 TicTacToePiece:
class TicTacToePiece : public GamePiece{ public: virtual std::unique_ptr<GamePiece> clone() const override;};std::unique_ptr<GamePiece> TicTacToePiece::clone() const{ //Call the copy constructor to copy this instance return std::make_unique(*this);}
使用前面介绍的多态解决方案,当然可在同一棋盘中存储象棋棋子和井字游戏棋子:
GameBoard chessBoard(8,8)
chessBoard.at(0, 0) = std::make_unique<ChessPiece>();
chessBoard.at(0, 1) = std::make_unique<TicTacToePiece>();
最大的问题在于,在一定程度上,只有记住网格中存储的内容,才能在调用 at()时正确地向下转换。
Grid 类定义
为理解类模板,最好首先看一下类模板的语法。下例展示了如何修改 GameBoard 类,得到模板化的 Grid类。代码之后会对所有语法进行解释。注意,类名从 GameBoard 变为 Grid。这个 Grid 类还应可用于基本类型,如 int 和 double。因此,这里选用不带多态性的值语义来实现这个解决方案,而 GameBoard 实现中使用了多态指针语义。与指针语义相比,使用值语义的缺点在于不能拥有真正的空网格,也就是说,网格始终要包含一些值。而使用指针语义,在空网格中可以存储 nullptr。幸运的是,C++17 的 std::optional(在中定义)可弥补这一点。它允许使用值语义,同时允许表示空网格。
template<typename T>class Grid{ public: explicit Grid(size_t width = kDefaultWidth,size_t height = kDefaultHeight); virtual ~Grid() = default; //Explicity default a copy constructor and assignment operator Grid(const Grid& src) = default; Grid& operator=(Grid&& rhs) = default; std::optional& at(size_t x,size_t y); const std::optional& at(size_t x,size_t y) const; size_t getHeight() const{ return mHeigth; } size_t getWidth() const{ return mWidth; } static const size_t kDefaultWidth = 10; static const size_t kDefaultHeight = 10; private: void verifyCoordinate(size_t x,size_t y) const; std::vector>> mCells; size_t mWidth,mHeight;};
现在已展示了完整的类定义,下面逐行分析这些代码:
template <typename T>
第一行表示, 下面的类定义是基于一种类型的模板。template 和 typename 都是 C++中的关键字。如前所述,模板“参数化”类型的方式与函数“参数化”值的方式相同。就像在函数中通过参数名表示调用者要传入的参数一样,在模板中使用模板参数名称(例如 表示调用者要指定的类型。名称 T 没有什么特别之处,可使用任何名称。按照惯例,只使用一种类型时,将这种类型称为 T,但这只是一项历史约定,就像把索引数组的整数命名为i或j一样。这个模板说明符应用于整个语句,在这里是整个类定义。
注意:
基于历史原因,指定模板类型参数时,可用关键字 class 替代 typename。因此,很多书籍和现有的程序使用了这样的语法: template 。不过,在这个上下文中使用 class 这个词会产生一些误解,因为这个词暗示这种类型必须是一个类,而实际上并不要求这样。这种类型可以是类、struct、union、语言的基本类型(例如int 或 double 等)。
在前面的 GameBoard 类中,mCells 数据成员是指针的矢量的矢量,这需要特定的复制代码,因此需要复制构造函数和赋值运算符。在 Grid 类中,,mCells 是可选值的矢量的矢量,所以编译器生成的复制构造函数和赋值运算符可以运行得很好。但如第 8 章所述,一旦有了用户声明的析构函数,建议不要使用编译器隐式生成复制构造函数或赋值运算符,因此 Grid 类模板将其显式设置为默认,并且将移动构造函数和赋值运算符显式设置为默认。下面将复制赋值运算符显式设置为默认:
Grid<T>& operator=(const Grid& rhs) = default;
从中可以看出,rhs 参数的类型不再是 const GameBoard& 了,而是 const Grid&,还可将其指定为 const Grid&。 在类定义中,编译器根据需要将 Grid 解释为 Grid。但在类定义之外,需要使用 Grid。在编. 写类模板时,以前的类名(Grid)现在实际上是模板名称。讨论实际的 Grid 类或类型时,将其作为 Grid,讨论的是 Grid 类模板对某种类型实例化的结果,例如 int、SpreadsheetCell 或 ChessPiece。mCells 不再存储指针,而是存储可选值。at()方法现在返回 optional&或 const optional&,而不是返回 unique_ptr:
std::optional<T>& at(size_t x,size_t y);const std::optional<T>& at(size_t x,size_t y) const;
Grid 类的方法定义
template 访问说明符必须在 Grid 模板的每一个方法定义的前面。构造函数如下所示:
template<typename T>Grid<T>::Grid(size_t width,size_t height) :mWidth(width),mHeight(height) { mCells.resize(mWidth); for(auto& column:mCells) { column.resize(mHeight); } }
模板要求将方法的实现也放在头文件中,因为编译器在创建模板的实例之前,需要知道完整的定义,包括方法的定义。本章后面将讨论一些突破这些限制的方法。
注意:之前的类名是 Grid, 而不是 Grid。 必须在所有的方法和静态数据成员定义中将 Grid指定为类名。构造函数的函数体类似于 GameBoard 构造函数。其他方法定义也类似于 GameBoard 类中对应的方法定义,只是适当地改变了模板和 Grid的语法:
template<typename T>void Grid<T>::verifyCoordinate(size_t x,size_t y) const{ if(x >= mWidth || y >= mHeight) { throw std::out_of_range(""); }}template<typename T>const std::optional<T>& Grid<T>::at(size_t x,size_t y) const{ verifyCoordinate(x,y); return mCells[x][y];}template <typename T>std::optional<T>& Grid<T>::at(size_t x,size_t y){ return const_cast<std::optional<T>&>(std::as_const(*this).at(x,y));}
注意:
如果类模板方法的实现需要特定模板类型参数(例如 T)的默认值,可使用 T()语法。 如果 T 是类类型,T()调用对象的默认构造函数,或者如果T是简单类型,则生成 0。这称为“初始化为 0”语法。最好为类型尚不确定的变量提供合理的默认值。
- 使用 Grid 模板
创建网格对象时,不能单独使用 Grid 作为类型;必须指定这个网格保存的元素类型。为某种类型创建一个模板类对象的过程称为模板的实例化。下面举一个示例:
Grid<int> myIntGrid; //declare a grid that stores ints //using default arguments for the constructorGrid myDoubleGrid(11,11); //declares an 11x11 Grid of doublesmyIntGrid.at(0,0) = 10;int x = myIntGrid.at(0,0).value_or(0);Grid grid2(myIntGrid); //Copy constructorGrid anotherIntGrid;anotherIntGrid = grid2; //Assignment operator
注意 myIntGrid、grid2 和 anotherIntGrid 的类型为 Grid。不能将 SpreadsheetCell 或 ChessPiece 保存在这些网格中,和否则编译器会生成错误消息。另外, 这里使用了 value_or()。at()方法返回 std::optional 引用 。optional 可包含值, 也可不包含值.如果 optional包含值,value_or()方法返回这个值;,和否则返回给 value_or()提供的实参。类型规范非常重要,下面两行代码都无法编译:
Grid test; //WILL NOT COMPILEGrid<> test; //WILL NOT COMPILE
编译器对第一行代码会给出如下错误:“使用类模板要求提供模板参数列表。”编译器对第二行代码会给出,如下错误:“模板参数太少。”如果要声明一个接收 Grid 对象的函数或方法,必须在 Grid 类型中指定保存在网格中的元素类型。
void processGrid(Grid<int>&grid){}
另外,可使用将在本章后面介绍的函数模板,基于网格中的元素类型来编写函数模板。
注意;为避免每次都编写完整的 Grid 类型名称,例如 Grid,可通过类型别名指定一个更简单的名称:
using IntGrid = Grid<int>;
现在可编写以下代码:
void processIntGrid(IntGrid& grid){}
Grid 模板能保存的数据类型不只是 int。例如,可实例化一个保存 SpreadsheetCell 的网格:
Grid<SpreadsheetCell> mySpreadsheet;SpreadsheetCell myCell(1.234);mySpreadsheet.at(3,4) = myCell;
还可保存指针类型;
Grid<const char*>myStringGrid;myStringGrid.at(2,2) = "hello";
指定的类型甚至可以是另一个模板类型;
Grid<vector<int>> gridOfVectors;vector<int> myVector{1,2,3,4};gridOfVectors.at(5,6) = myVector;
还可在堆上动态分配 Grid 模板实例;
auto myGridOnHeap = make_unique<Grid<int>>(2,2);//2x2 Grid on the heapmyGridOnHeap->at(0,0) = 10;int x = myGridOnHeap->at(0,0).value_or(0);
编译器处理模板的原理
为理解模板的复杂性,必须学习编译器处理模板代码的原理。编译器遇到模板方法定义时,会进行语法检查,但是并不编译模板。编译器无法编译模板定义,因为它不知道要使用什么类型。不知道x 和y 的类型,编译器就无法为x=y这样的语句生成代码。编译器遇到一个实例化的模板时,例如 Grid myIntGrid,就会将模板类定义中的每一个T 替换为int,从而生成 Grid 模板的 int 版本代码。当编译器遇到这个模板的另一个实例时,例如 GridmySpreadsheet,就为 SpreadsheetCell 生成另一个版本的 Grid 类。 编译器生成代码的方式就好像语言不支持模板时程序员编写代码的方式: 为每种元素类型编写一个不同的类。这里没有什么神奇之处,模板只是自动完成一个令人厌烦的过程。如果在程序中没有将类模板实例化为任何类型,就不编译类方法定义。这个实例化的过程也解释了为什么需要在定义中的多个地方使用 Grid语法。当编译器为某种特定类型实例化模板时,例如 int,就将T蔡换Int,变成 Grid类型。
- 选择性实例化
编译器总为泛型类的所有虚方法生成代码。但对于非虚方法,编译器只会为那些实际为某种类型调用的非虚方法生成代码。例如,给定前面定义的 Grid 模板类,假设在 main()中编写这段代码(而且只有这段代码);
Grid<int> myIntGrid;myIntGrid.at(0,0) = 10
编译器只会为int 版本的 Grid 类生成无参构造函数、析构函数和非常量 at()方法的代码, 不会为其他方法生成代码,例如复制构造函数、赋值运算符或 getHeight()。
- 模板对类型的要求
编写与类型无关的代码时,肯定对这些类型有一些假设。例如,在 Grid 模板中,假设元素类型(用T表示)是可析构的。Grid 模板实现的假设并不多,而其他模板会假设支持的模板类型参数(如赋值运算符)。如果在程序中试图用一种不支持模板使用的所有操作的类型对模板进行实例化,那么这段代码无法编译,而且错误消息几乎总是晦涩难懂。然而,就算要使用的类型不支持所有模板代码所需的操作,也仍然可以利用选择性实例化使用某些方法,而避免使用另一些方法。
将模板代码分布在多个文件中
通常情况下,将类定义放在一个头文件中,将方法定义放在一个源代码文件中。创建或使用类对象的代码会通过#include 来包含对应的头文件,通过链接器访问这些方法代码。模板不按这种方式工作。由于编译器需要通过这些“模板”为实例化类型生成实际的方法代码,因此在任何使用了模板的源代码文件中,编译器都应该能同时访问模板类定义和方法定义。有好几种机制可以满足这种包含需求。
- 将模板定义放在头文件中
方法定义可与类定义直接放在同一个头文件中。当使用了这个模板的源文件通过#include 包含这个文件时,编译器就能访问需要的所有代码。该机制用于前面的 Grid 实现。此外,还可将模板方法定义放在另一个头文件中,然后在类定义的头文件中通过#include 包含这个头文件。一定要保证方法定义的include 在类定义之后,和否则代码无法编译。例如:
template<typename T>class Grid{ };#include "GridDefinitions.h"
任何需要使用Grid模板的客户只需要包含 Grid.h头文件即可。这种分离方式有助于分开类定义和方法定义。
- 将模板定义放在源文件中
将方法实现放在头文件中看上去很奇怪。如果不喜欢这种语法,可将方法定义放在一个源代码文件中。然而,仍然需要让使用模板的代码能访问到定义,因此可在模板类定义头文件中通过#include 包含类方法实现的源文件。尽管如果之前没有看过这种方式,会感到有点奇怪,但是这在 C++中是合法的。头文件如下所示:
template<typename T>class Grid{ };#include "Grid.cpp"
使用这种技术时,一定不要把 Grid.cpp 文件添加到项目中,因为这个文件本不应在项目中,而且无法单独编译,这个文件只能通过#include 包含在一个头文件中。实际上, 可任意命名包含方法实现的文件.有些程序员喜欢给包含的源代码文件添加.inl 后绥, 例如 Grid.inl。
限制模板类的实例化
如果希望模板类仅用于某些已知的类型,就可使用下面的技术。假定 Grid 类只能实例化 int、double 和 vector,那么头文件应如下所示;
template<typename T>class Grid{};
注意在这个头文件中,没有方法定义,末尾也没有#include 语句。这里,需要在项目中添加一个真正的.cpp 文件,它包含方法定义,如下所示:
#include "Grid.h"#include <utility>template<typename T>Grid<T>::Grid(size_t width,size_t height) :mWidth(width),mHeight(height) { mCells.resize(mWidth); for(auto& column : mCells) { column.resize(mHeight); } }
为使这个方法能运行,需要给允许客户使用的类型显式实例化模板。这个.cpp 文件的末尾应如下所示:
// Explicit instantiations for the types you want to allow.template class Grid;template class Grid;template class Grid>;
有了这些显式的实例化,就不允许客户代码给其他类型使用 Grid 类模板,例如 SpreadsheetCell。注意:使用显式类模板实例化,无论是否调用方法,编译器都会为类模板的所有方法生成代码。
注意:
使用显式类模板实例化,无论是否调用方法,编译器都会为类模板的所有方法生成代码。
模板参数
在 Grid 示例中,Grid 模板包含一个模板参数: 保存在网格中的元素的类型。编写这个类模板时,在尖括号中指定参数列表,如下所示,
template <typename T>
这个参数列表类似于函数或方法中的参数列表。与函数或方法一样,可使用任意多个模板参数来编写类。此外,这些参数未必是类型,而且可以有默认值。
- 非类型的模板参数
非类型的模板参数是“普通”参数,例如 int 和指针: 函数和方法中你十分熟悉的那种参数。然而,非类型的模板参数只能是整数类型(char、int、long 等)、枚举类型、指针、引用和 std::nullptr。从 C++17 开始,也可指定 auto、auto&和 auto*等作为非类型模板参数的类型。此时,编译器会自动推导类型。在 Grid 类模板中,可通过非类型模板参数指定网格的高度和宽度,而不是在构造函数中指定它们。在模板列表中指定非类型参数而不是在构造函数中指定的主要好处是: 在编译代码之前就知道这些参数的值了。前面提到,编译器为模板化的方法生成代码的方式是在编译之前替换模板参数。因此,在这个实现中,可使用普通
template<typename T,size_t WIDTH,size_t HEIGHT>class Grid{ public: Grid() = default; virtual ~Grid() = default; // Explicitly default a copY constructor and assignment operator. Grid(const Grid& src) = default; Grid& operator=(const Grid& rhs) = default; std::optional& at(size_t x,size_t y); const std::optional& at(size_t x,size_t y) const; size_t getHeight() const{ return HEIGHT;} size_t getWidth() const{ return WIDTH; } private: void verifyCoordinate(size_t x,size_t y) const; std::optional mCells[WIDTH][HEIGHT];};
这个类没有显式地将移动构造函数和移动赋值运算符设置为默认,原因是 C 风格的数组不支持移动语义。注意,模板参数列表需要 3 个参数:网格中保存的对象类型以及网格的宽度和高度。宽度和高度用于创建保存对象的二维数组。下面是类方法定义:
template<typename T,size_t WIDTH,size_t HEIGHT>void Grid<T,WIDTH,HEIGHT>::verifyCoordinate(size_t x,size_t y) const{ if(x >= WIDHT || y >= HEIGHT) { throw std::out_of_range(""); }}template<typename T,size_t WIDTH,size_t HEIGHT>const std::optional<T>& Grid<T,WIDTH,HEIGHT>::at(size_t x,size_t y) const{ verifyCoordinate(x,y); return mCells[x][y];}template<typename T,size_t WIDTH,size_t HEIGHT>std::optional<T>& Grid<T,WIDTH,HEIGHT>::at(size_t x,size_t y){ return const_cast<std::optional<T>&>(std::as_const(*this).at(x,y));}
注意之前所有指定 Grid的地方,现在都必须指定 Grid
Grid<int,10,10>myGrid;Grid<int,10,10>anotherGrid;myGrid.at(2,3) = 42;anotherGrid = myGrid;cout<<anotherGrid.at(2,3).value_or(0);
这段代码看上去很棒。遗城的是, 实际中的限制比想象中的要多。 首先,不能通过非常量的整数指定高度或宽度。下面的代码无法编译:
size_t height = 10;Grid<int,10,height> testGrid;//DOES NOT COMPILE
然而,如果把 height 声明为 const,这段代码就可以编译了:
const size_t height = 10;Grid<int,10,height> testGrid;//Compiles and works
带有正确返回类型的 constexpr 函数也可以编译。例如,如果有一个返回 size t 的 constexpr 函数,就可以使用它初始化 height 模板参数,
constexpr size_t getHeight(){ return 10;}...Grid<double,2,getHeight()> myDoubleGrid;
另一个限制可能更明显。既然宽度和高度都是模板参数,那么它们也是每种网格类型的一部分。这意味着Grid
注意:非类型模板参数是实例化的对象的类型规范中的一部分。
- 类型参数的默认值 ,
如果继续采用将高度和宽度作为模板参数的方式,就可能需要为高度和宽度(它们是非类型模板参数)提供默认值,就像之前 Grid类的构造函数一样。C++人允许使用类似的语法向模板参数提供默认值。在这里也可以给T类型参数提供默认值。下面是类定义:
template<typename T = int,size_t WIDTH = 10,size_t HEIGHT = 10>class Grid{};
不需要在方法定义的模板规范中指定T、WIDTH 和 HEIGHT 的默认值。例如,下面是 at()方法的实现: ,
template<typename T,size_t WIDTH,size_t HEIGHT>const std::optional<T>& Grid<T,WIDTH,HEIGHT>::at(size_t x,size_t y) const{ verifyCoordinate(x,y); return mCells[x][y];}
现在,实例化 Grid 时,可不指定模板参数,只指定元素类型,或者指定元素类型和宽度,或者指定元素类型、宽度和高度:
Grid<>myIntGrid;Grid<int>myGrid;Grid<int,5>anotherGrid;Grid<int,5,5>aFourthGrid
注意,如果未指定任何类模板参数,那么仍需要指定一组空尖括号。例如,以下代码无法编译!
Grid myIntGrid;
模板参数列表中默认参数的规则与函数或方法是一样的。可以从右向左提供参数的默认值。
- 构造函数的模板参数推导
C++17 添加了一些功能,支持通过传递给类模板构造函数的实参自动推导模板参数。在 C++17 之前,必须显式地为类模板指定所有模板参数。例如,标准库有一个类模板 std::pair(在中定义),详见第 17 章。至此,你必须知道的是,pair 存储两种不同类型的两个值,必须将其指定为模板参数:
std::pair<int,double> pair1(1,2.3);
为避免编写模板参数的必要性,可使用一个辅助的函数模板 std::make_pair()。本章后面将详细讨论函数模板。函数模板始终支持基于传递给函数模板的实参自动推导模板参数。因此,make_pair()能根据传递给它的值自动推导模板类型参数。例如,编译器为以下调用推导 pair
auto pair2 = std::make_pair(1,2.3);
在 C++17 中,不再需要这样的辅助函数模板。现在,编译器可以根据传递给构造函数的实参自动推导模板类型参数。对于 pair 类模板,只需要编写以下代码:
std::pair pair3(1,2.3);
当然,推导的前提是类模板的所有模板参数要么有默认值,要么用作构造函数中的参数。
注意
std::unique_ptr 和 shared_ptr 会禁用类型推导。 给它们的构造函数传递 T*,这意味着,编译器必须选择推导还是
用户定义的推导原则
也可编写自己的推导原则,即用户定义的推导原则。这允许你编写如何推导模板参数的规则。这是一个高级主题,这里不对其进行详细讨论,但会举一个例子来演示其功能。假设具有以下 SpreadsheetCell 类模板:
template<typename T>class SpreadsheetCell{ public: SpreadsheetCell(const T& t):mContent(t){} const T& getContent() const{ return mContent; } private: T mContent;};
通过自动推导模板参数,可使用 std::string 类型创建 SpreadsheetCell:
std::string myString = "Hello world!";SpreadsheeCell cell(myString);
但是,如果给 SpreadsheetCell 构造函数传递 const char*,那么会将类型 T推导为 const char*,这不是需要的结果。可创建以下用户定义的推导原则, 在将 const char*作为实参传递给构造函数时,将了推导为 std::string:
SpreadsheetCell(const char*)->SpreadsheetCell<std::string>;
在与 SpreadsheetCell 类相同的名称空间中,在类定义之外定义该原则。通用语法如下。explicit 关键字是可选的。它的行为与单参构造函数的 explicit 相同,因此只适用于单个参数的推导原则。
explicit TemplateName(Parameters) -> DeducedTemplate;
方法模板
C++人允许模板化类中的单个方法。这些方法可以在类模板中,也可以在非模板化的类中。在编写模板化的类方法时,实际在为很多不同的类型编写很多不同版本的方法。在类模板中,方法模板对赋值运算符和复制构造函数非常有用。
警告:
不能用方法模板编写虚方法和析构函数。
考虑最早只有一个模板参数全元素类型的 Grid 模板。可实例化很多不同类型的网格,例如int网格和double网格:
Grid<int> myIntGrid;Grid<double> myDoubleDrid;
然而,Grid和 Grid是两种不同的类型。如果编写的函数接收类型为 Grid的对象,就不能传入 Grid。即使int 网格中的元素可以复制到 double 网格中(因为 int 可以强制转换为 double),也不能将类型为 Grid的对象赋给类型为 Grid的对象, 也不能从 Grid构造 Grid。下面两行代码都无法编译:
myDoubleGrid = myIntGrid; //DOES NOT COMPILEGrid newDoubleGrid(myIntGrid); //DOES NOT COMPILE
问题在于 Grid 模板的复制构造函数和赋值运算符如下所示:
Grid(const Grid<T>& src);Grid<T>& operator=(const Grid<T>& rhs);
注意,在生成的 Grid类中,构造函数或 operator=都不接收 Grid作为参数。幸运的是, 在 Grid 类中添加模板化的复制构造函数和赋值运算符,可生成将一种网格类型转换为另一种网格类型的方法,从而修复这个疏漏。下面是新的 Grid 类定义:
template <typename T>class Grid{ public: template<typename E> Grid(const Grid<E>& src); template<typename E> Grid<T>& operator=(const Grid<E>& rhs); void swap(Grid& other) noexcept;};
首先检查新的模板化的复制构造函数:
template<typename E>Grid(const Grid<E>& src);
可看到另一个具有不同类型名称 E(Element 的简写)的模板声明。这个类在类型 T 上被模板化,这个新的复制构造函数又在另一个不同的类型 E 上被模板化。通过这种双重模板化可将一种类型的网格复制到另一种类型的网格。下面是新的复制构造函数的定义:
template<typename T>template<typename E>Grid<T>::Grid(const Grid<E>& src) :Grid(src.getWidth(),src.getHeight()){ //The ctor-initializer of this constructor delegates first to the //non-copy constructor to allocate the proper amount of memory //The next step is to copy the data for(size_t i = 0;i < mWidth; i++) { for(size_t j = 0; j < mHeight;j++) { mCells[i][j] = src.at(i,j); } }}
可以看出,必须将声明类模板的那一行(带有 T 参数)放在成员模板的那一行声明(带有 E 参数)的前面。不能像下面这样合并两者:
template<typename T,typename E> //Wrong for nested template constructorGrid::Grid(const Grid& src)
除了构造函数定义之前的额外模板参数行之外, 注意必须通过公共的访问方法 getWidth()、getHeight()和 at()访问 src 中的元素。这是因为复制目标对象的类型为 Grid,而复制来源对象的类型为 Grid。这两者不是同一类型,因此必须使用公共方法。模板化的赋值运算符接收 const Grid&作为参数,但返回 Grid&:
template <typename T>template <typename E>Grid<T>& Grid<T>::operator=(const Grid<E>& rhs){ // no need to check for self-assignment because this version of // assignment is never called when T and E are the same // Copy-and-swap idiom Grid temp(rhs); // Do all the work in a temporary instance swap(temp); // Commit the work with only non-throwing operations return *this;}
在模板化的赋值运算符中不需要检查自赋值,因为相同类型的赋值仍然通过老的、非模板化的 operator=版本进行,因此在这里不可能进行自赋值。这个赋值运算符的实现使用第 9 章介绍的“复制和交换”惯用语法。但是,不使用友元函数 swap(),Grid()模板使用的是 swap()方法,因为本章后面才讨论函数模板。注意,swap()方法只能交换同类网格,但这是可行的,因为模板化的赋值运算符首先使用模板化的复制构造函数,将给定的 Grid转换为 Grid(称为temp)。此后,它使用 swap()方法,用 this(也是 Grid类型)蔡换临时的 Grid 。下面是 swap()方法的定义:
template<typename T>void Grid<T>::swap(Grid<T>& other) noexcept{ using std::swap; swap(mWidth, other.mWidth); swap(mHeight, other.mHeight); swap(mCells, other.mCells);}
带有非类型参数的方法模板
在之前用于 HEIGHT 和 WIDTH 整数模板参数的例子中,一个主要问题是高度和宽度成为类型的一部分。因为存在这个限制,所以不能将一个拥有某种高度和宽度的网格赋值给另一个拥有不同高度和宽度的网格。然而在某些情况下,需要将某种大小的网格赋值或复制到另一个大小的网格。不一定要把源对象完美地复制到目标对象, 可从源数组中只复制那些能够放在目标数组中的元素; 如果源数组在任何一个维度上都比目标数组小,可以用默认值填充。有了赋值运算符和复制构造函数的方法模板后,完全可实现这个操作,从而允许对不同大小的网格进行赋值和复制。下面是类定义:
template<typename T,size_t WIDTH=10,size_t HEIGHT = 10>class Grid{ public: Grid() = default; virtual ~Grid() = default; // Explicitly default a copy constructor and assignment operator. Grid(const Grid& src) = default; Grid& operator=(const Grid& rhs) = default; template Grid(const Grid&src); template Grid& operator=(const Grid&rhs); void swap(Grid& other) noexcept; std::optional& at(size_t x,size_t y); const std::optional& at(size_t x,size_t y) const; size_t getHeight() const{ return HEIGHT; } size_t getWidth() const { return WIDTH; } private: void verifyCoordinate(size_t x,size_t y) const; std::optional mCells[WIDTH][HEIGHT];};
这个新定义包含复制构造函数和赋值运算符的方法模板,还包含辅助方法 swap()。注意,将非模板化的复制构造函数和赋值运算符显式设置为默认(原因在于用户声明的析构函数)。这些方法只是将 mCells 从源对象复制或赋值到目标对象,语义和两个一样大小的网格的语义完全一致。下面是模板化的复制构造函数:
template<typename T,size_t WIDTH,size_t HEIGHT>template<typename E,size_t WIDTH2,size_t HEIGHT2>Grid<T,WIDHT,HEIGHT>::Grid(const Grid<E, WIDTH2,HEIGHT2>& src){ for(size_t i = 0;i < WIDTH;i++) for(size_t j = 0;j < HEIGHT; j++) { if(i < WIDTH2 && j < HEIGHT2) { mCells[i][j] = src.at(i,j); } else { mCells[i][j].reset(); } }}
注意, 该复制构造函数只从src在x维度和y维度上分别复制WIDTH 和HEIGHT个元素,即使src比 WIDTH和 HEIGHT 指定的大小要大,也是如此。如果 src 在任何一个维度上都比这个指定值小,那么使用 reset()方法重置附加点中的 std::optional 对象.下面是 swap()和 operator=的实现:
template<typename T,size_t WIDTH,size_t HEIGHT>void Grid<T,WIDTH,HEIGHT>::swap(Grid<T,WIDTH,HEIGHT>& other) noexcept{ using std::swap; swap(mCells,other.mCells);}template<typename T,size_t WIDTH,size_t HEIGHT>template<typename E,size_t WIDTH2,size_t HEIGHT2>Grid<T,WIDTH,HEIGHT>& Grid<T,WIDTH,HEIGHT>::operator=(const Grid<E,WIDTH2,HEIGHT2>&ths){ // no need to check for self-assignment because this version of // assignment is never called when T and E are the same // Copy-and-swap idiom Grid temp(rhs); // Do all the work in a temp instance swap(temp); // Commit the work with only non-throwing operations return *this; }
类模板的特例化
对于特定类型,可给类模板提供不同的实现。例如,Grid 的行为对 const char*(C 风格的字符串)来说没有意义。Grid
// When the template specialization is used, the original template must be// visible too. Including it here ensures that it will always be visible// when this specialization is visible.#include "Grid.h"template <>class Grid{ public: explicit Grid(size_t width = kDefaultWidth, virtual ~Grid() = default; // Explicitly default a copy constructor and assignment operator. Grid(const Grid& src) = default; Grid& operator=(const Grid& rhs) = default; // Explicitly default a move constructor and assignment operator. Grid(Grid&& src) = default; Grid& operator=(Grid&& rhs) = default; std::optional& at(size_t x, size_t y); const std::optional& at(size_t x, size_t y) const; size_t getHeight() const { return mHeight; } size_t getWidth() const { return mWidth; } static const size_t kDefaultWidth = 10; static const size_t kDefaultHeight = 10; private: void verifyCoordinate(size_t x, size_t y) const; std::vector>> mCells; size_t mWidth, mHeight;};
注意,在这个特例化中不要指定任何类型变量,例如 T,而是直接处理 const char*。现在有个明显的问题是,为什么这个类仍然是一个模板。也就是说,下面这种语法有什么意义?
template<>class Grid<const char*>
上述语法告诉编译器,这个类是 Grid 类的 const char*特例化版本。假设没有使用这种语法,而是尝试编写下面这样的代码;
class Grid;
编译器不允许这样做,因为已经有一个名为 Grid 的类(原始的类模板)。只能通过特例化重用这个名称。特例化的主要好处就是可对用户隐藏。当用户创建 int 或 SpreadsheetCell 类型的 Grid 时,编译器从原始的 Grid 模板生成代码。当用户创建 const char*类型的 Grid 时,编译器会使用 const char*的特例化版本。这些全部在后台自动完成。
Grid<int> myIntGrid; // Uses original Grid templateGridstringGrid1(2,2); //Uses const char* specializationconst char* dummy = "dummy";stringGrid1.at(0,0) = "hello";stringGrid1.at(0,1) = dummy;stringGrid1.at(1,0) = dummy;stringGrid1.at(1,1) = "there";GridstringGrid2(stringGrid1);
特例化一个模板时,并没有“继承”任何代码: 特例化和派生化不同。必须重新编写类的整个实现。不要求提供具有相同名称或行为的方法。例如, Grid 的 const char*特例仅实现 at()方法, 返回 std::optional
Grid<const char*>::Grid(size_t width,size_t height) :mWidth(width),mHeight(height) { mCells.resize(mWidth); for(auto &column:mCells) { column.resize(mHeight); } }void Grid<const char*>::verifyCoordinate(size_t x,size_t y) const{ if(x >= mWidth || y >= mHeight) { throw std::out_of_range(""); }}const std::optional<std::string>& Grid<const char*>::at(size_t x,size_t y) const{ verifyCoordinate(x,y); return mCells[x][y];}std::optional<std::string>& Grid<const char*>::at(size_t x,size_t y){ return const_cast<std::optional<std::string>&>(std::as_const(*this).at(x,y));}
从类模板派生
可从类模板派生。如果一个派生类从模板本身继承,那么这个派生类也必须是模板。此外,还可从类模板派生某个特定实例, 这种情况下, 这个派生类不需要是模板。下面针对前一种情况举一个例子, 假设通用的 Grid类没有提供足够的棋盘功能。确切地讲,要给棋盘添加 move()方法,允许棋盘上的棋子从一个位置移动到另一个位置。下面是这个 GameBoard 模板的类定义:
#include "Grid.h"template<typename T>class GameBoard:public Grid<T>{ public: explicit GameBoard(size_t width = Grid<T>::kDefaultWidth, size_t height = Grid<T>::kDefaultHeight); void move(size_t xSrc,size_t ySrc,size_t xDest,size_t yDest);}
这个 GameBoard 模板派生自 Grid 模板,因此继承了 Grid 模板的所有功能。不需要重写 at()、getHeight()以及其他任何方法。也不需要添加复制构造函数、operator=或析构函数,因为在 GameBoard 中没有任何动态分配的内存。-. 继承的语法和普通继承一样,区别在于基类是 Grid,而不是 Grid。设计这种语法的原因是 GameBoard模板并没有真正地派生自通用的 Grid 模板。相反,GameBoard 模板对特定类型的每个实例化都派生自 Grid 对那种类型的实例化。例如, 如果使用 ChessPiece 类型实例化 GameBoard, 那么编译器也会生成 Grid的代码。“: public Grid ”语法表明,这个类继承了 Grid 实例化对类型参数T有意义的所有内容。注意 C++模板继承的名称查找规则要求指定 kDefaultWidth 和 kDefaultHeight 在基类 Grid中声明,因而依赖基类Grid。下面是构造函数和 move()方法的实现。同样,要注意调用基类构造函数时对 Grid的使用。此外,尽管很多编译器并没有强制使用 this 指针或 Grid::引用基类模板中的数据成员和方法, 但名称查找规则要求使用this 指针或 Grid::。 ,
template<typename T>GameBoard<T>::GameBoard(size_t width,size_t height) :Grid<T>(width,height){}template<typename T>void GameBoard<T>::move(size_t xSrc,size_t ySrc,size_t xDest,size_t yDest){ Grid<T>::at(xDest,yDest) = std::move(Grid<T>::at(xSrc,ySrc)); Grid<T>::at(xSrc,yStc).reset(); //Reset source cell}
可使用如下 GameBoard 模板:
GameBoard<ChessPiece> chessboard(8,8);ChessPiece pawn;chessBoard.at(0,0) = pawn;chessBoard.move(0,0,0,1);
继承还是特例化
有些程序员感觉模板继承和模板特例化之间的区别很难理解。表 12-1 总结了两者的区别。
| 继承 | 特化 | |
|---|---|---|
| 是否重用代码? | 是: 派生类包含基类的所有成员和方法 | 否: 必须在特例化中重写需要的所有代码 |
| 是否重用名称? | 否: 派生类名必须和基类名不同 | 是: 特例化的名称必须和原始名称一致 |
| 是否支持多态? | 是: 派生类的对象可以代替基类的对象 | 否: 模板对一种类型的每个实例化都是不同类型 |
注意:通过继承来扩展实现和使用多态。通过特例化自定义特定类型的实现。
模板别名
第 11 章介绍了类型别名和 typedef 的概念。通过 typedef 可给特定类型赋予另一个名称。例如可编写以下类型别名,给类型 int 指定另一个名称:
using MyInt = int;
类似地,可使用类型别名给模板化的类赋予另一个名称。假定有如下类模板:
template<typename T1,typename T2>class MyTemplateClass{}
可定义如下类型别名,给定两个模板类型参数:
using OtherName = MyTemplateClass<int,double>;
也可用 typedef 替代类型别名。
还可仅指定一些类型,其他类型则保持为模板类型参数,这称为别名模板(alias template),例如:;
template<typename T1>using otherName = MyTemplateClass<T1,double>;
这无法用 typedef 完成。
函数模板
还可为独立函数编写模板。例如,可编写一个通用函数,该函数在数组中查找一个值并返回这个值的索引:
static const size_t NOT_FOUND = static_cast<size_t>(-1);template<typename T>size_t Find(const T& value,const T* arr,size_t size){ for(size_t i = 0;i < size;i++) { if(arr[i] == value) { return i; //Found it:return the index } } return NOT_FOUND; //Failed to find it : return NOT_FOUND}
注意:
当然,如果找不到元素, 可以不返回一些 sentinel 值(例如NOT FOUND),,可重写代码, 返回 std::optional而非 Size_t。这有是使用 std::optional 的有趣练习。
这个 Find()函数可用于任何类型的数组。例如,可通过这个函数在 int 数组中查找一个 int 值的索引,还可在 SpreadsheetCell 数组中查找一个 SpreadsheetCell 值的索引。可通过两种方式调用这个函数: 一种是通过尖括号显式地指定类型,另一种是忽略类型,让编译器根据参数自动推断类型。下面列举一些例子:
int myInt = 3,intArray[] = {1,2,3,4};const size_t sizeIntArray = std::size(intArray);size_t res;res = Find(myInt,intArray,sizeIntArray); //calls Find by deductionres = Find(myInt,intArray,sizeIntArray); //calls Find explicitlyif(res != NOT_FOUND) cout< by deductionres = Find(myDouble,doubleArray,sizeDoubleArray);//calls Find explicitlyres = Find(myDouble,doubleArray,sizeDoubleArray);if(res != NOT_FOUND) cout< explicitly,event with myIntres = Find(myInt,doubleArray,sizeDoubleArray);SpreadsheetCell cell1(10),cellArray[] = {SpreadsheetCell[4],SpreadsheetCell[10]};const size_t sizeCellArray = std::size(cellArray);res = Find(cell,cellArray,sizeCellArray);res = Find(cell,cellArray,sizeCellArray);
”前面 Find()函数的实现需要把数组的大小作为一个参数。有时编译器知道数组的确切大小,例如,基于堆栈的数组。用这种数组调用 Find()函数,就不需要传递数组的大小。为此,可添加如下函数模板。该实现仅把调用传递给前面的 Find()函数模板。这也说明函数模板可接收非类型的参数,与类模板一样。
template<typename T,size_t N>size_t Find(const T& value,const T(&arr)[N]){ return Find(value,arr,N);}
这个版本的 Find()函数语法有些特殊,但其用法相当直接,如下所示:
int myInt = 3,intArray[] = {1,2,3,4};size_t res = Find(myInt,intArray);
与类模板方法定义一样, 函数模板定义(不仅是原型)必须能用于使用它们的所有源文件。因此,如果多个源文件使用函数模板,或使用本章前面讨论的显式实例化,就应把其定义放在头文件中。函数模板的模板参数可以有默认值,与类模板一样。
函数模板的特例化
就像类模板的特例化一样,函数模板也可特例化。例如,假设想要编写一个用于 const char* C 风格字符串的 Find()函数,这个函数通过 strcmp()而不是 operator一来比较字符串。下面是完成这个任务的特例化的 Find()函数:
template<>size_t Find<const char*>(const char* const& value,const char* const* arra,size_t size){ for(size_t i = 0;i < size;i++) { if(strcmp(arr[i],value) == 0) { return i; //FOUND it,return the index } } return NOT_FOUND; //Failed to find it;return NOT_FOUND}
如果参数类型可通过参数推导出来,那么可在函数名中忽略
template<>size_t Find(const char* const& value,const char* const* arr,size_t size)
然而如果还涉及重载(详见 12.3.2 节),那么类型推导规则就会显得很诡异,因此为了避免出错,最好显式地注明类型。
尽管特例化的 Find()函数可接收 const char*而不是 const char*&作为第一个参数,但最好让参数和函数非特例化版本的参数保持一致,这样可让函数推导规则正常工作。
这个特例化版本的使用示例如下:
const char* word = "two";const char* words[] = {"one","two","three","four"};const size_t sizeWords = std::size(words);size_t res;//Calls const char* specializationres = Find(word,words,sizeWords);//Calls const char* specializationres = Find(word,words,sizeWords);
函数模板的重载
还可用非模板函数重载模板函数。例如,如果不编写用于 const char*的 Find()函数模板,那么需要编写一个非模板的独立 Find()函数以直接操作 const char*:
size_t Find(const char* const& value,const char* const arr,size_t size){ for(size_t i = 0;i < size;i++) { if(strcmp(arr[i],value) == 0) { return ;//Found it; return the index } } return NOT_FOUND;//Failed to find it; return NOT_FOUND}
这个函数的行为等同于 12.3.1 节中的特例化版本。然而,这个函数的调用规则有所不同:
const char* word = "two";const char* words[] = {"one","two","three","four"};const size_t sizeWords = std::size(words);size_t res;//Calls template with T=const char*res = Find(word,words,sizeWords);res = Find(word,words,sizeWords); //Calls non-template function!
因此,如果想要函数在显式指定了 const char*时能正常工作,以及在没有指定时能通过自动类型推导正常工作,那么应该编写一个特例化的模板版本,而不是编写一个非模板的重载版本。
同时使用函数模板重载和特例化
可同时编写一个适用于 const char*的特例化 Find()函数模板, 以及一个适用于 const char*的独立 Find()函数。编译器总是优先选择非模板化的函数,而不是选择模板化的版本。然而,如果显式地指定模板的实例化,那么会强制编译器使用模板化的版本:
const char* word = "two";const char* words[]= {"one","two","three","four"};const size_t sizeWords = std::size(words);size_t res;//Calls const char*specialization of the templateres = Find(word,words,sizeWords);res = Find(word,words,sizeWords);//Calls the Find non-template Function
类模板的友元函数模板
如果需要在类模板中重载运算符, 函数模板会非常有用。 例如, 可重载 Grid 类模板的相加运算符 operator+,把两个网格加在一起,得到的网格大小与两个操作数中较小的网格相同。只有在两个网格都包含实际值时,才会将相应的网格相加。假定 operator+是一个独立的函数模板,其定义应该直接放在 Grid.h 中,如下所示,
template<typename T>Grid<T> operator+(const Grid<T>& lhs,const Grid<T>& rhs){ size_t minWidth = std::min(lhs.getWidth(),rhs.getWidth()); size_t minHeight = std::min(lhs.getHeight(),rhs.getHeight()); Grid<T> result(mintWidth,minHeight); for(size_t y = 0;y < minHeight;++y) { for(size_t x = 0;x < minWidth;++x) { const auto& leftElement = lhs.mCells[x][y]; const auto& rightElement = rhs.mCells[x][y]; if(leftElement.has_values() && rightElement.has_value()) result.at(x,y) = leftElement.value() + rightElement.value(); } } return result;}
要查询 std::optional 是否包含实际值,可使用 has_value()方法,同时使用 value()方法检索这个值。这个函数模板可用于任何网格,只要网格中的元素支持相加运算符即可。这个实现的唯一问题是 operator+访问了 Grid 类的私有成员 mCells。显然,解决方法是使用公有的 getElementAt()方法,下面看看如何把函数模板作为类模板的友元。对于这个示例,可将该运算符作为 Grid 类的友元。然而,Grid 类和 operator+都是模板。实际上需要以下效果: operator+对每一种特定类型 T 的实例化都是 Grid 模板对这种类型实例化的友元。语法如下所示:
//Forward declare Grid templatetemplateclass Grid;//Prototype for templatized operator+.templateGrid operator+(const Grid& lhs,const Grid& rhs);templateclass Grid{ public: //Omitted for brevity friend Grid operator+(const Grid& lhs, const Grid& rhs); //Omitted for brevity};
友元声明比较棘手, 上述语法表明,对于这个模板对类型 T 的实例,operator+对类型 T 的实例是这个模板实例的友元。换名话说,类实例和函数实例之间存在一对一的友元映射关系。特别要注意 operator+中显式的模板规范(operator+后面的空格是可选的)。这一语法告诉编译器,operator+本身也是模板。
对模板参数推导的更多介绍
编译器根据传递给函数模板的实参来推导模板参数的类型; 而对于无法推导的模板参数, 则需要显式指定。例如,如下 add()函数模板需要三个模板参数: 返回值的类型以及两个操作数的类型。
template<typename RetType, typename T1,typename T2>RetType add(const T1& t1,const T2& t2) { return t1 + t2; }
调用这个函数模板时,可指定如下所有三个参数:
auto result = add<long long,int,int>(1,2);
但由于模板参数 TI 和 T2 是函数的参数,编译器可以推导这两个参数,因此调用 add()时可仅指定返回值的类型
auto result = add<long long>(1,2);
当然,仅在要推导的参数位于参数列表的最后时,这才可行。假设以如下方式定义函数模板:
template<typename T1,typename RetType,typename T2>RefType add(const T1& t1,const T2& t2){ return t1 + t2; }
必须指定 RetType,因为编译器无法推导该类型。但由于 RetType 是第二个参数,因此必须显式指定 T1;
auto result = add<int,long long>(1,2);
也可提供返回类型模板参数的默认值,这样调用 add()时可不指定任何类型:
template<typename RefType = long long,typename T1, typename T2>RetType add(const T1& t1,const T2& t2) { return t1 + t2;}...auto result = add(1,2);
函数模板的返回类型
继续分析 add()函数模板的示例,让编译器推导返回值的类型岂不更好? 确实是好, 但返回类型取决于模板类型参数,如何才能做到这一点? 例如,考虑如下模板函数:
template<typename T1,typename T2>RefType add(const T1& t1,const T2& t2){ return t1 + t2; }
在这个示例中, RetType 应当是表达式 tl+t2 的类型, 但由于不知道 TI 和 T2 是什么, 因此并不知道这一点。如第 1 章所述,从 C++14 开始,可要求编译器自动推导函数的返回类型。因此,只需要编写如下 add()函数模板:
template<typename T1,typename T2>auto add(const T1& t1, const t2& t2){ return t1+t2;}
但是, 使用 auto 来推导表达式类型时去掉了引用和 const 限定符, decltype 没有去除这些。在继续使用 add()函数模板前,先分析 auto 和 decltype(使用非模板示例)之间的区别。假设有以下函数,
const std::string message = "Test";const std::string& getString(){ return message;}
可调用 getString(),将结果存储在 auto 类型的变量中,如下所示;
auto s1 = getString();
由于 auto 会去掉引用和 const 限定符, 因此 s1 的类型是 string, 并制作一个副本。如果需要一个 const 引用,可将其显式地设置为引用,并标记为 const,如下所示:
const auto& s2 = getString();
这里,s3 的类型是 const string&,但存在代码元余,因为需要将 getString()指定两次。如果 getString()是更复杂的表达式,这将很麻烦。为解决这个问题,可使用 decltype(auto):
decltype(auto) s4 = getString();
s4 的类型也是 const string&。了解到这些后,可使用 decltype(auto)编写 add()函数,以避免去掉任何 const 和引用限定符:
template<typename T1,typename T2>decltype(auto) add(const T1& t1,const T2& t2){ return t1+t2;}
在 C++14 之前,不支持推导函数的返回类型和 decltype(auto)。C++ll 引入的 decltype(expression)解决了这个问题。例如,你或许会编写如下代码:
template<typename T1,typename T2>decltype(t1+t2) add(const T1& t1,const T2& t2){ return t1+t2; }
但这是错误的。你在原型行的开头使用了 tl 和 世, 但这些尚且不知。 在语义分析器到达参数列表的末尾时,才能知道t1 和t2。
通常使用替换函数语法(altemative function syntax)解决这个问题。注意在这种新语法中,返回类型是在参数列表之后指定的(拖尾返回类型),因此在解析时参数的名称(以及参数的类型,因此也包括 tl+t2 类型)是已知的:
template<typename T1,typename T2>auto add(const T1& t1, const T2& t2)->decltype(t1+t2){ return t1+t2;}
但现在,C++支持自动返回类型推导和 decltype(auto),建议你使用其中的一种机制,而不要使用替换函数语法。
可变模板
除了类模板、类方法模板和函数模板外,C++14 还添加了编写可变模板的功能。语法如下;:
template <typename T>constexpr T pi = T(3.141592653589793238462643383279502884);
这是pi值的可变模板。为了在某种类型中获得 pi 值,可使用如下语法:
float piFloat = pi<float>;long double piLongDouble = pi<long double>;
C++ 1/0 揭秘
程序的基本任务是接收输入和生成输出。不能生成任何类型输出的程序不会太有用。所有语言都提供了某种 IO 机制,这种机制既有可能内建在语言中,也有可能提供操作系统特定的 API。优秀的 IO 系统应该兼具灵活性和易用性。灵活的 IO 系统支持通过不同设备进行输入输出,例如文件和用户控制台,还支持读写不同类型的数据。IO 很容易出错,因为来自用户的数据可能是不正确的,或者底层的文件系统或其他数据源有可能无法访问。因此,优秀的 IO 系统还应当能处理错误情形。如果已经熟悉了 C 语言,就肯定用过 printt)和 scanf)。作为 IO 机制,printf)和 scanfO确实很灵活。通过转义代码和变量占位符,这些函数可定制为读取特定格式的数据,或输出格式化代码允许的任何值,此类值仅局限于整数/字符值、浮点值和字符串。然而,printft)和 scanf0)在优秀 IO 系统的其他指标方面表现落后。这些函数不能很好地处理错误,处理自定义数据类型不够灵活,在 C++这样的面向对象语言中,它们根本不是面向对象的!C++通过一种称为流Gstream)的机制提供了更精良的输入输出方法。流是一种灵活且面向对象的 IO 方法。本章介绍如何将流用于数据的输入输出。你还将学习如何通过流机制从不同的来源读取数据,以及向不同的和的地写出数据,例如用户控制台、文件甚至字符串。本章将讲解最常用的 IO 特性。
使用流
需要花一些工夫才能习惯流的隐喻。初看上去,流似乎比传统的 C 风格 IO(例如 printf())要复杂。事实需要花一些工夫才能习惯流的隐喻。初看上去,流似乎比传统的 C 风格 IO(例如 printf())要复杂。事实也不想用旧式的IO 了。
流的含义
第 1 章将 cout 流比喻为数据的洗衣滑槽。把一些变量丢到流中,这些变量就会被写到用户屏幕上,即控制台。更一般地,所有的流都可以看成数据滑槽。流的方向不同,关联的来源和目的地也不同。例如,你已经熟悉的 cout 流是一个输出流,因此它的方向是“流出”。这个流将数据写入控制台,因此它关联的目的地是“控制台”。还有一个称为 cin 的标准流,它接收来自用户的输入。这个流的方向为“流入” 关联的来源为“控制台”。cout 和 cin 都是 C++在 std 名称空间中预定义的流实例。表 13-1 简要描述了所有预定义的流。
缓冲的流和非缓冲的流的区别在于,前者不是立即将数据发送到目的地,而是缓冲输入的数据,然后以块方式发送,而非缓冲的流则立即将数据发送到目的地。缓冲的目的通常是提高性能,对于某些目的地(如文件)而言,一次性写入较大的块时速度更快。注意,始终可使用 ftush()方法刷新缓冲区,强制要求缓冲的流将其当前所有的缓冲数据发送到目的地。这些流还存在宽字符版本: wcin、wcout、wcerr 和 wclog。第 19 章将讨论宽字符。注意,图形用户界面应用程序通常没有控制台,换言之,如果向 cout 写入一些数据,用户无法看到。如果编写的是库,那么绝对不要假定存在 cout、cin、cerr 或 clog,因为不可能知道库会应用到控制台应用程序还是GUI应用程序。
注意:
所有输入流都有一个关联的来源,所有输出流都有一个关联的目的地。有关流的另一个要点是: 流不仅包含普通数据,还包含称为当前位置(current position)的特殊数据。当前位置指的是流将要进行下一次读写操作的位置。
13.1.2 流的来源和目的地
流这个概念可应用于任何接收数据或生成数据的对象。因此可编写基于流的网络类,还可编写 MIDI 设备的流式访问类。在 C++中,流可使用 3 个公共的来源和目的地: 控制台、文件和字符串。你在前面看到了很多用户(或控制台)流的例子。控制台输入流允许程序在运行时从用户那里获得输入,使程序具有交互性。控制台输出流向用户提供反馈和输出结果。顾名思义,文件流从文件系统中读取数据并向文件系统写入数据。文件输入流适用于读取配置数据、读取保存的文件,也适用于批处理基于文件的数据等任务。文件输出流适用于保存状态数据和提供输出等任务。文件流包含 C 语言输出函数 fprintf()、fwrite()和 fputs()的功能,以及输入函数 canf()、fread()和 fgets()的功能。字符串流是将流隐喻应用于字符串类型的例子。使用字符串流时,可像处理其他任何流一样处理字符数据。就字符串流的大部分功能而言,只不过是为 string 类的很多方法能够完成的功能提供了便利的语法。然而,使用流式语法为优化提供了机会, 而且比直接使用 string 类方便得多。 字符串流包含 sprintf()、sprintf()和 sscanf()的功能,以及很多 C 语言字符串格式化函数的功能。本节主要讲解控制台流(cin 和 cout)。本章后面会列举文件流和字符串流的例子。其他类型的流,例如打印机输出和网络 IO 等往往与平台相关,因此本书没有讨论这些流。
流式输出
第 1 章介绍了流式输出,在本书中,几乎每一章都使用了流式输出。本节首先简单回顾一些基本概念,然后介绍一些更高级的内容。
- 输出的基本概念
输出流定义在头文件中。大部分程序员都会在程序中包含头文件,这个头文件又包含输入流和输出流的头文件。头文件还声明了所有预定义的流实例: cout、cin、cerr、clog 以及对应的宽版本。使用输出流的最简单方法是使用<<运算符。通过<<可输出 C++的基本类型,如 int、指针、double 和字符。此外,C++的 string 类也兼容<<,C 风格的字符串也能正确输出。下面列举一些使用<<的示例:
int i = 7;cout<<i<<endl;char ch = 'a';cout<<ch<<endl;string myString = "Hello world";cout<<myString<<endl;
输出如下所示:
7aHello World
cout 流是写入控制台的内建流,控制台也称为标准输出standard output。可将<<的使用串联起来,从而输出多个数据段。这是因为<<运算符返回一个流的引用,因此可以立即对同一个流再次应用<<运算符。例如
int j = 11;cout<<"The value of j is "<<j<<"!"<<endl;
输出如下所示:
The value of is 11
C++流可正确解析 C 风格的转义字符,例如包含\n 的字符串,也可使用 std::endl 开始一个新行。\n 和 endl的区别是, 仅开始一个新行,而 endl 还会刷新缓存区。使用 endl 时要小心,因为过多的缓存区刷新会降低性能。下例使用 endl 输出,通过一行代码可以输出多行文本。
cout<<"Line 1"<<endl<<"Line 2"<<endl<<"Line 3"<<endl;
- 输出流的方法
毫无疑问,<<运算符是输出流最有用的部分。然而,你还需要了解一些额外功能。如果看一下头文件,就会发现重载<<运算符定义的很多代码行(支持输出各种不同的数据类型),还可看到一些有用的公有方法。
put()和 write()
put()和 write()是原始的输出方法。这两个方法接收的不是定义了输出行为的对象或变量,put()接收单个字符,write()接收一个字符数组。传给这些方法的数据按照原本的形式输出,没有做任何特殊的格式化和处理操作。例如,下面的代码段接收一个 C 风格的字符串,并将它输出到控制台,这个函数没有使用<<运算符:
const char* test = "hello there\n";cout.write(test,strlen(test));
下面的代码段通过 put()方法,将 C 风格字符串的给定索引输出到控制台:
cout.put('a');
flush()
向输出流写入数据时,流不一定会将数据立即写入目的地。大部分输出流都会进行缓冲,也就是积累数据,而不是立即将得到的数据写出去。缓冲的目的通常是提高性能,对于某些目的地(如文件)而言,与逐字符写入相比,一次性写入较大的块时速度更快。在以下任意一种条件下,流将刷新(或写出)积累的数据:
遇到 sentinel(如 endl 标记)时 。
流离开作用域被析构时。
要求从对应的输入流输入数据时(即要求从 cin 输入时,cout 会刷新)。在有关文件流的 13.3 节中,将学
习如何建立这种链接。
流缓存满时。
显式地要求流刷新缓存时。显式要求流刷新缓存的方法是调用流的 flush()方法,如下所示:
- 处理输出错误
输出错误可能会在多种情况下出现。比如,你有可能试图打开一个不存在的文件,有可能因为磁盘错误导致写入操作失败,例如磁盘已满。到目前为止,前面使用流的代码都没有考虑这些可能性,主要是为了让代码简洁。然而,处理任何可能发生的错误是非常重要的。
当一个流处于正常的可用状态时,称这个流是“好的” 调用流的 good()方法可以判断这个流当前是否处于正常状态。
if(cout.goog()){ cout<<"All goog"<<endl;}
通过 good()方法可方便地获得流的基本验证信息,但不能提供流不可用的原因。还有一个 bad()方法提供了稍多信息。如果 bad()方法返回 true,意味着发生了致命错误(相对于非致命错误,例如到达文件结尾)。另一个方法 fail()在最近一次操作失败时返回 true,但没有说明下一次操作是否也会失败。例如,对输出流调用 fhush()后,可调用 fail()确保流仍然可用。
cout.flush();if(cout.fail()){ cerr<<"Unable to flush to standard out "<<endl;}
流具有可转换为 bool 类型的转换运算符。转换运算符与调用!fail0时返回的结果相同。因此,可将前面的代码段重写为:
cout.flush();if(!cout){ cerr<<"Unable to flush to standard out"<<endl;}
有一点需要指出,遇到文件结束标记时,good()和 fail()都会返回 false。关系如下:good() == (!fail() && !eof())。
还可要求流在发生故障时抛出异常。然后编写一个 catch 处理程序来捕捉 ios_base::failure 异常,然后对这个异常调用 what()方法,获得错误的描述信息,调用 code()方法获得错误代码。不过,是否能获得有用信息取决于所使用的标准库实现
cout.execeptions(ios::failbit | ios::badbit | ios::eofbit);try{ cout<<"Hello world"<<endl;}catch(const ios_base::failure& ex){ cerr<<"Caught execuption: "<<ex.what()<<",error code = "<<ex.code()<<endl;}
通过 clear()方法重置流的错误状态:
cout.clear();
控制台输出流的错误检查不如文件输入输出流的错误检查频繁。这里讨论的方法也适用于其他类型的流,后面讨论每一种类型时都会回顾这些方法。
输出操作算子
流的一项独特特性是,放入数据滑槽的内容并非仅限于数据。C++流还能识别操作算子(manipulaton,操作算子是能修改流行为的对象,而不是(或额外提供)流能够操作的数据。endl 就是一个操作算子。endl 操作算子封装了数据和行为。它要求流输出一个行结束序列,并且刷新缓存。下面列出了其他有用的操作算子,大部分定义在和标准头文件中。列表后的例子展示了如何使用这些操作算子。
boolalpha 和 noboolalpha,要求流将布尔值输出为 true 和 false(boolalpha)或 1 和 0(noboolalpha)。默认行为是 noboolalpha。
hex、oct 和 dec: 分别以十六进制、八进制和十进制输出数字。
setprecision: 设置输出小数时的小数位数。这是一个参数化的操作算子(也就是说,这个操作算子接收一个参数)。
setw: 设置输出数值数据的字段宽度。这是一个参数化的操作算子。
setfill: 当数字宽度小于指定宽度时,设置用于填充的字符。这是一个参数化的操作算子。
showpoint 和 noshowpoint: 对于不带小数部分的浮点数,强制流总是显示或不显示小数点。
put_money: 一个参数化的操作算子,向流写入一个格式化的货币值。
put_time: 一个参数化的操作算子,向流写入一个格式化的时间值。
quoted: 一个参数化的操作算子,把给定的字符串封装在引号中,并转义嵌入的引号。上述操作算子对后续输出到流中的内容有效,直到重置操作算子为止,但 setw 仅对下一个输出有效。下例通过这些操作算子自定义输出:
//Boolean valuesbool myBool = true;cout<<"This is the default: "<
\1. 输入的基本概念
通过输入流,可采用两种简单方法来读取数据。第一种方法类似于<<运算符,<<向输出流输出数据。读入数据对应的运算符是>>。通过>>从输入流读入数据时,代码提供的变量保存接收的值。例如,以下程序从用户那里读入一个单词,并保存在一个字符串中。然后将这个字符串输出到控制台:
string userInput;cin>>userInput;cout<<"User input was "<<userInput<<endl;
默认情况下, >>运算符根据空白字符对输入值进行标志化。 例如, 如果用户运行以上程序, 并键入 hello there作为输入,那么只有第一个空白字符(在这个例子中为空格符)之前的字符才会存储在 userInput 变量中。输出如下所示:
User input was hello
在输入中包含空白字符的一种方法是使用 get(),本章后面会讨论这个方法。运算符可用于不同的变量类型,就像<<运算符一样。例如,要读取一个整数,代码仅在变量类型上区别:
int userInput;cin>>userInput;cout<<"User input was "<<userInput<<endl;
通过输入流可以读入多个值,并且可根据需要混合和匹配类型。例如,下面这个函数摘自一个餐馆预订系统,它要求用户输入姓氏和聚会就餐的人数,
void getReservationData(){ string guestName; int partySize; cout<<"Name and number of guests: "; cin>>guestName>>partySize; cout<<"Thank you. "<<guestName<<"."<<endl; if(partSize>10) { cout<<"An extra gratuity will apply"<<endl; }}
注意,>>运算符会根据空白字符符号化,因此 getReservationData0函数不允许输入带有空白字符的姓名。一种解决方法是使用本章后面讲解的 unget()方法。注意,尽管这里使用 cout 时没有通过 endl 或 flush()显式地刷新缓存区,但仍可将文本写入控制台,因为使用 cin 会立即刷新 cout 缓存区,cin 和 cout 通过这种方式链接在一起。
\2. 处理输入错误
输入流提供了一些方法用于检测异常情形。大部分和输入流有关的错误条件都发生在无数据可读时。例如,可能到达流尾(称为文件末尾,即使不是文件流)。查询输入流状态的最常见方法是在条件语句中访问输入流。例如,只要 cin 保持在“良好”状态,下面的循环就继续进行:
while(cin){...}
同时可以输入数据;
while(cin>>ch){}
还可在输入流上调用 good()、bad()和 fail()方法,就像输出流那样。还有一个 eof方法,如果流到达尾部,就返回 true。与输出流类似,遇到文件结束标记时,good()和 fail()都会返回false。关系如下: good() == (!fail() && !eof());
你还应该养成读取数据后就检查流状态的习惯,这样可从异常输入中恢复。下面的程序展示了从流中读取数据并处理错误的常用模式。这个程序从标准输入中读取数字,到达文件末尾时显示这些数字的总和。注意在命令行环境中,需要用户键入一个特殊的字符来表示文件结束。在 UNIX 和Linux 中,这个特殊字符是 Control + D,在 Windows 中为 Control+Z。具体的字符与操作系统相关,因此需要了
cout<<"Enter numbers on separate line to add" <<"Use Control+D to finish(Control+Z in Window)"<<endl; int sum = 0; if(!cin.goog()){ cerr<<"Standard input is in a bad state!"<<endl; return 1;}int number;while(!cin.bad()){ cin>>number; if(cin.good()) { sum += number; } else if(cin.eof()) { break; } else if(cin.fail()) { cin.clear(); string badToken; cin>>badToken; cerr<<"WARNING:Bad input encountered :"<<badToken<<endl; }}cout<<"The sum is "<<sum<<endl;
输入方法
与输出流一样,输入流也提供了一些方法,它们可获得相比普通>>运算符更底层的访问功能。
get()
get()方法允许从流中读入原始输入数据。get()的最简单版本返回流中的下一个字符,其他版本一次读入多个字符。get()常用于避免>>运算符的自动标志化。例如,下面这个函数从输入流中读入一个由多个单词构成的名字,一直读到流尾。
string readName(istream& stream){ string name; while(stream) //Or:while(!stream.fail()) { int next = stream.get(); if(!stream || next == std::char_traits::eof()) break; name += static_cast(next);//Append character; } return name;}
在这个 readName()函数中,有一些有趣的发现:
这个函数的参数是一个对 istream 的非 const 引用,而不是一个 const 引用。从流中读入数据的方法会改变实际的流(主要改变当前位置),因为它们都不是 const 方法。因此,不能对 const 引用调用这些方法。
get()的返回值保存在 int 而不是 char 变量中,因为 get()会返回一些特殊的非字符值,例如std::char traits::eof(),因此使用 int。
readName()有一点奇怪,因为可采用两种方式跳出循环。一种方式是流进入“不好的”状态,另一种方式是到达流尾。另一种从流中读入数据的更常用方法是使用另一个版本的 get(),这个版本接收一个字符的引用,并返回一个流的引用。这种模式利用了如下事实;在条件环境中对一个输入流求值时,只有当这个输入流可以用于下一次读取时才会返回 true。如果遇到错误或者到达文件未尾,都会使流求值为 false。 第 15 章将讲解实现这个特性所需的转换操作的底层细节。同一个函数的下面这个版本稍微简洁一些
string readName(istream& stream){ string name; char next; while(stream.get(next)) { name += next; } return name;}
unget()
对于大多数场合来说,理解输入流的正确方式是将输入流理解为单方向的滑槽。数据被丢入滑槽,然后进入变量。unget()方法打破了这个模型,允许将数据塞回滑槽。调用 unget()会导致流回退一个位置, 将读入的前一个字符放回流中。调用 fail()方法可查看 unget()是否成功。例如,如果当前位置就是流的起始位置,那么 unget()会失败。本章前面出现的 getReservationData()函数不允许输入带有空白字符的名字。下面的代码使用了 unget(),人多许名字中出现空白字符。将这段代码逐字符读入,并检查字符是否为数字。如果字符不是数字,就将字符添加到 guestName。如果字符是数字,就通过 unget()将这个字符放回到流中,循环停止,然后通过>>运算符输入一个整数 partySize。 noskipws 输入操作算子告知流不要跳过空白字符, 就像读取其他任何字符一样读取空白字符。
void getReservationData(){ string guestName; int partySize = 0; //Read characters until we find a digit char ch; cin>>noskipws; while(cin>>ch) { if(isdigit(ch)) { cin.unget(); if(cin.fail()) cout<<"unget() failed"<>partySize; if(!cin) { cerr<<"Error getting party size "< 10) { cout<<"An extra gratuity will apply"<
putback()
putback()和 unget()一样,允许在输入流中反向移动一个字符。区别在于 putback()方法将放回流中的字符接收为参数;
char ch1;cin>>ch1;cin.putback('e');//'e' will be the next character read off the stream
peek()
通过 peek()方法可预览调用 get()后返回的下一个值。再次以滑模为例,可想象为查看一下滑槽,但是不把值取出来。peek()非常适合于在读取前需要预先查看一个值的场合。例如下面的代码实现了 getReservationData()函数,允许名字中出现空白字符,但使用的是 peek()而不是 unget():
void getReservationData(){ string guestName; int partySize = 0; //Read characters until we find a digit char ch; cin>>noskipws; while(true) { //'peek' at next character ch = static_cast(cin.peek()); if(!cin) break; if(isdigit(ch)) { //next character will be a digit,so stop the loop break; } //next character will be a non-digit,so read it cin>>ch; if(!cin) break; guestName += ch; } //Read partySize,if the stream is not in error state if(cin) cin>>partySize; if(!cin) { cerr<<"Error getting party size "< 10) { cout<<"An extra gratuity will apply"<
getline()
从输入流中获得一行数据是一种非常常见的需求,有一个方法能完成这个任务。getline()方法用一行数据填充字符缓存区,数据量最多至指定大小。指定的大小中包括\ 字符。因此,下面的代码最多从 cin 中读取kBufferSize - 1 个字符,或者读到行尾为止;
char buffer[kBufferSize] = {0};cin.getline(buffer,kBufferSize);
调用 getline()时,从输入流中读取一行,读到行尾为止。不过,行尾字符不会出现在字符串中。注意,行尾序列和平台相关。例如,行尾序列可以是\n、'Nn 或mv。有个版本的 get()函数执行的操作和 getline()一样,区别在于 get()把换行序列留在输入流中。还有一个用于 C++字符串的 std::getline()函数。这个函数定义在头文件和 std 名称空间中。 它接收一个流引用、一个字符串引用和一个可选的分隔符作为参数。使用这个版本的 getline()函数的优点是不需要指定缓存区的大小。
string myString;std::getline(cin,myString);
\4. 输入操作算子
下面列出了内建的输入操作算子,它们可发送到输入流中,以自定义数据读入的方式。boolalpha 和 noboolalpha: 如果使用了 boolalpha,字符串 false 会被解释为布尔值 false; 其他任何字符串都会被解释为布尔值 true。 如果设置了 noboolalpha, 0 会被解释为 false,其他任何值都被解释为 true。默认为 noboolalpha。
hex、oct 和 dec: 分别以十六进制、八进制和十进制读入数字。skipws 和 noskipws: 告诉输入流在标记化时跳过空白字符, 或者读入空白字符作为标记。 默认为 skipws。 ws: 一个简便的操作算子,表示跳过流中当前位置的一串空白字符。get_money: 一个参数化的操作算子,从流中读入一个格式化的货币值。 get_time: 一个参数化的操作算子,从流中读入一个格式化的时间值。quoted: 一个参数化的操作算子,读取封装在引号中的字符串,并转义嵌入的引号。输入支持本地化。例如,下面的代码为 cin 启用本地化。第 19 章将讨论本地化。
cin.imbue(locale(""));int i;cin>>i;
如果系统被本地化为 U.S. English,那么输入 1.000 会被解析为 1000,输入 1.000 会被解析为 1。如果系统被本地化为 Dutch Belgium,那么输入 1.000 会被解析为 1000,而输入 1,000 会被解析为 1。在这两种情形中,
对象的输入输出
即使不是基本类型,也可以通过<<运算符输出 C++字符串。在 C++中,对象可描述其输入输出方式。 为此,需要重载<<和>>运算符,以理解新的类型或类。为什么要重载这些运算符? 如果熟悉C语言中的printf()函数,就知道printf()在这方面并不灵活尽管printf()知道多种数据类型,但是无法让其知道更多的知识。例如,考虑下面这个简单的类: .
class Muffin{ public: virtual ~Muffin() = default; string_view getDestription() const; void setDestription(string_view description); int getSize() const; void setSize(int size); bool hasChocolateChips() const; void setHasChocolateChips(bool hasChips); private: string mDescription; int mSize = 0; bool mHasChocolateChips = false;};string_view Muffin::getDescription() const { return mDescription; }void Muffin::setDescription(string_view description){ mDescription = description;}int Muffin::getSize() const { return mSize;} void Muffin::setSize(int size) { mSize = size; }bool Muffin::hasChocolateChips() const{ return mHasChocolateChips; }void Muffin::setHasChocolateChips(bool hasChips){ mHasChocolateChips = hasChips;}
为通过 printf()输出 Muffn 类的对象,最好将其指定为参数,可能需要使用%m 作为占位符。
printf("Muffin: %m\n",myMuffin);//BUG! printf doesn't understand Muffin
但 printf()函数完全不了解 Muffin 类型,因此无法输出 Muffn 类型的对象。更灶糕的是,由于 printf()函数的声明方式,这样的代码会导致运行时错误而不是编译时错误(不过优秀的编译器会给出警告消息)。要使用 printf(),最好在 Muffn 类中添加新的 output()方法:
class Muffin{ public: //Omitted for brevity void output() const; //Omitted for brevity};//Other method implementations omitted for brevityvoid Muffin::output() const{ printf("%s,Size is %d,%s\n",getDescription().data,getSize(),(hasChocolateChips() ? "has chips":"no chips"));}
不过,使用这种机制显得非常笨拙。如果要在另一行文本的中间输出 Muffin,那么需要将这一行分解为两个调用,在两个调用之间插入一个 Muffin::output()调用,如下所示:
printf("The muffine is ");myMuffin.output();printf(" --yummy!\n");
字符串流
可通过字符串流将流语义用于字符串。通过这种方式,可得到一个内存中的流(in memory stream)来表示文本数据。例如,在 GUI应用程序中,可能需要用流来构建文本数据,但不是将文本输出到控制台或文件中,而是把结果显示在 GUI元素中, 例如消息框和编辑框。另一个例子是, 要将一个字符串流作为参数传给不同函数,同时维护当前的读取位置,这样每个函数都可以处理流的下一部分。字符串流也非常适合于解析文本,因为流内建了标记化的功能。std::ostringstream 类用于将数据写入字符串,std::istringstream 类用于从字符串中读出数据。这两个类都定义在头文件中。由于 ostringstream 和 istringstream 把同样的行为分别继承为 ostream 和 istream,因此这两个类的使用也非常类似。下面的程序从用户那里请求单词,然后输出到一个 ostringstream 中,通过制表符将单词分开。在程序的最后,整个流通过 str()方法转换为字符串对象,并写入控制台。输入标记“done”,可停止标记的输入,按下Control+D(UNIX)或 Control+Z(Windows)可关闭输入流。
cout<<"Enter tokens,Control+D(Unix) or Control+Z(Window) to end"<<endl;ostreamstream outStream;while(cin){ string nextToken; cout<<"Next token"; cin>>nextToken; if(!cin || nextToken == "done") break; outStream << nextToken<<"\t";}cout<<"The end result is: "<<outStream.str();
从字符串流中读入数据非常类似。下面的函数创建一个 Muffin 对象,并填充字符串输入流中的数据(参见此前的例子)。流数据的格式固定,因此这个函数可轻松地将数据值转换为对 Muffn 类的设置方法的调用:
Muffin createMuffin(istringstream& stream){ Muffin muffin; //Assume data is properly formatted; //Description size chips string description; int size; bool hasChips; //Read all three values.Note that chips is represented //by the strings "true" and "false" stream >> description >> size>>boolalpha>>hasChips; if(stream) { //Reading was successful muffin.setSize(size); muffin.setDescription(description); muffin.setHasChocolateChips(hasChips); } return muffin;}
注意;
将对象转换为“扁平”类型(例如字符串类型)的过程通常称为编组(marshall)。将对象保存至磁盘或通过网络发送时,编组操作非常有用 。相对于标准 C++字符串,字符串流的主要优点是除了数据之外,这个对象还知道从哪里进行下一次读或写相对于标准 C++字符串,字符串流的主要优点是除了数据之外,这个对象还知道从哪里进行下一次读或写更加强大。
文件流
文件本身非常符合流的抽象,因为读写文件时,除数据外,还涉及读写的位置。在 C++中,std::ofstream 和std::i&tream 类提供了文件的输入输出功能。这两个类在头文件中定义。 在处理文件系统时,错误情形的检测和处理非常重要。比如,当前处理的文件可能在一个刚下线的网络存储中,或者可能写入磁盘上的一个已满文件,以及也许试图打开一个用户没有访问权限的文件。可以通过前面描述的标准错误处理机制检测错误情形。输出文件流和其他输出流的唯一主要区别在于: 文件流的构造函数可以接收文件名以及打开文件的模式作为参数。默认模式是写文件(ios_base::out),这种模式从文件开头写文件,改写任何已有的数据。给文件流构造函数的第二个参数指定常量 ios_base::app,还可按追加模式打开输出文件流。表 13-2 列出了可供使用的不同常量。
| 常量 | 说明 |
|---|---|
| ios_base::app | 打开文件,在每一次写操作之前,移到文件末尾 |
| ios_base::ate | 打开文件,打开之后立即移到文件末尾 |
| ios_base::binary | 以二进制模式执行输入输出操作(相对于文本模式) |
| ios_base::in | 打开文件,从开头开始读取 |
| ios_base::out | 打开文件,从开头开始写入,覆盖已有的数据 |
| ios_base::trunc | 打开文件,并删除(截断)任何己有数据 |
注意,可组合模式。例如,如果要打开文件用于输出(以二进制模式),同时截断现有数据,可采用如下方式指定打开模式
ios_base::out|ios_base::binary|ios_base::trunc
istream 自动包含 ios_base::in 模式,ofstream 自动包含 ios_base::out 模式,即使不显式地将 in 或 out 指定为模式,也同样如此。下面的程序打开文件 test.txt,并输出程序的参数。ifteam 和 ofstream 析构函数会自动关闭底层文件,因此不需要显式调用 close():
int main(int argc,char *argv[]){ ofstream.outFile("text.txt",ios_base::trunc); if(!outFile.good()) { cerr<<"Error while opening output file!"<<endl; return -1; } outFile<<"There were "<<argc<<" arguments to this program"<<endl; for(int i = 0;i<argc;i++) { outFile<<argv[i]<<endl; } return 0;}
文本模式与二进制模式
默认情况下,文件流在文本模式中打开。如果指定 ios_base::binary 标志,将在二进制模式中打开文件。在二进制模式中,要求把流处理的字节写入文件。读取时,将完全按文件中的形式返回字节。在文本模式中,会执行一些隐式转换,写入文件或从文件中读取的每一行都以\n结束。但是,行结束符在文件中的编码方式与操作系统相关。例如,在 Windows 上,行结束符是\r\n而不是单个\n。因此,如果文件以文本模式打开,而写入的行以\n 结尾, 在写入文件前,底层实现会自动将\n 转换为\r\n。同样,从文件读取行时,从文件读取的\r\n 会自动转换回\n。
通过 seek()和 tell()在文件中转移
所有的输入流和输出流都有 seek()和 tell()方法。seek()方法允许在输入流或输出流中移动到任意位置。seek()有好几种形式。输入流中的 seek()版本实际上称为 seekg()(g 表示 get, 输出流中的 seek()版本称为 seekp() 表示 put。 为什么同时存在 seekg()和 seekp()方法,而不是 seek()方法? 原因是有的流既可以输入又可以输出,例如文件流。这种情况下,流需要记住读位置和独立的写位置。这也称为双向 I/O,将在本章后面讨论。
seekg()和 seekp()有两个重载版本。其中一个重载版本接收一个参数,绝对位置。这个重载版本将定位到这个绝对位置。另一个重载版本接收一个偏移量和一个位置,这个重载版本将定位到距离给定位置一定偏移量的位置。位置的类型为 std::streampos, 偏移量的类型为 std::streamoff,这两种类型都以字节计数。预定义的三个
| 位置 | 说明 |
|---|---|
| ios_base::beg | 表示流的开头 |
| ios_base::end | 表示流的结尾 |
| ios_base::cur | 表示流的当前位置 |
例如,要定位到输出流中的一个绝对位置,可使用接收一个参数的 seekp()版本,如下所示,这个例子通过ios_base::beg 常量定位到流的开头:
outStream.seekp(ios_base::beg);
在输入流中,定位方法完全一样,只不过用的是 seekg()方法:
inStream.seekg(ios_base::beg)
接收两个参数的版本可定位到流中的相对位置。第一个参数表示要移动的位置数, 第二个参数表示起始点。要相对文件的起始位置移动,使用 ios_base::beg 常量。要相对文件的末尾位置移动,使用 ios_base::end 常量。要相对文件的当前位置移动,使用 ios_base::cur 常量。例如,下面这行代码从流的起始位置移动到第二个字节。注意,整数被隐式地转换为 streampos 和 streamoff类型;
outStream.seekp(2,ios_base::beg);
下例转移到输入流中的倒数第 3 个字节:
inStream.seekg(-3,ios_base::end);
可通过 tell()方法查询流的当前位置,这个方法返回一个表示当前位置的 streampos 值。利用这个结果,可在执行 seek()之前记住当前标记的位置,还可查询是否在某个特定位置。和 seek()一样,输入流和输出流也才不同版本的 tell()。输入流使用的是 tellg(),输出流使用的是 tellp()。下面的代码检查输入流的当前位置,并判断是否在起始位置
std::streampos curPos = inStream.tellg();if(ios_base::beg == curPos){ cout<<"We're at the beginning "<<endl;}
下面是一个整合了所有内容的示例程序。这个程序写入 test.out 文件,并执行以下测试:
ofstream fout("test.out");if(!fout){ cerr<<"Error opening test:out for writing" <<endl; return 1;}//1.Output the string "12345"fout<<"12345";//2.Verify that the marker is at position 5;streampos curPos = fout.tellp();if(5 == curPos){ cout<<"Test passed: Currently at position 5"<> testVal;if(!fin){ cerr<<"Error reading from file "<
将流链接在一起
任何输入流和输出流之间都可以建立链接,从而实现“访问时刷新”的行为。换句话说,当从输入流请求.数据时,链接的输出流会自动刷新。这种行为可用于所有流,但对于可能互相依赖的文件流来说特别有用。通过 tie()方法完成流的链接。要将输出流链接至输入流,对输入流调用 tie()方法,并传入输出流的地址。要解除链接,传入 nullptr。下面的程序将一个文件的输入流链接至一个完全不同的文件的输出流。也可链接至同一个文件的输出流,但是双向 IO(详见稍后的描述)可能是实现同时读写同一个文件的更优雅方式。
ifstream inFile("input.txt"); //Note: input.txt must existofstream outFile("output.txt"); //Set up a link between inFile and outFileinFile.tie(&outFile);//Output some text to outFile Normally,this would not flush because std::endl is not sentoutFile<<"Hello there!";//outFile has NOT been flushed//Read some text from inFile, this will trigger flush()//on outFilestring nextToken;inFile>>nextToken;//outFile HAS been flushed
flush()方法在 ostream 基类上定义,因此可将一个输出流链接至另一个输出流:
outFile.tie(&anotherOutputFile);
这种关系意味着: 每次写入一个文件时,发送给另一个文件的缓存数据会被刷新。可通过这种机制保持两个相关文件的同步。这种流链接的一个例子是 cout 和 cin 之间的链接。每当从 cin 输入数据时,都会自动刷新 cout。cerr 和 cout之间也存在链接,这意味着到 cerr 的任何输出都会导致刷新 cout,而 clog 未链接到 cout。这些流的宽版本具有类似的链接。
双向1/O
目前,本章把输入流和输出流当作独立但又关联的类来讨论。事实上,有一种流可同时执行输入和输出。双向流可同时以输入流和输出流的方式操作。双向流是 iostream 的子类,而 iostream 是 istream 和 ostream 的子类,因此这是一个多重继承示例。显然,双向流支持>>和<<运算符,还支持输入流和输出流的方法。fstream 类提供了双向文件流。fstream 特别适用于需要替换文件中数据的应用程序,因为可通过读取文件找到正确的位置,然后立即切换为写入文件。例如,假设程序保存了 ID 号和电话号码之间的映射表。它可能使用以下格式的数据文件:
123 408-555-0394124 415-555-3422263 585-555-3490100 650-555-3434
一种合理方案是当这个程序打开文件时读取整个数据文件,然后在程序结束时,将所有的变化重新写入这个文件。然而,如果数据集庞大,可能无法把所有数据都保存在内存中。如果使用 iostream,则不需要这样做。可轻松扫描文件,找到记录,然后以追加模式打开输出文件,从而添加新的记录。如果要修改已有记录,可使用双向流,例如在下面的函数中,可替换指定 ID 的电话号码:
bool changeNumberForID(string_view filename,int id,string_view newNumber){ fstream ioData(filename.data()); if(!ioData) { cerr<<"Error while opening file "<<filename<<endl; return false; } //Loop until the end of file while(ioData) { int idRead; string number; //Read the next ID ioData >> idRead; if(!ioData) break; //Check to see if the current record is the one being changed if(idRead == id) { //Seek the write position to the current read position ioData.seekp(ioData.tellg()); //Output a space,then the new number ioData<<" "<>number; } return true;}
当然,只有在数据大小固定时,这种方法才能正常工作。当以上程序从读取切换到写入时,输出数据会改写文件中的其他数据。为保持文件的格式,并避免写入下一条记录,数据大小必须相同。还可通过 stringstream 类双向访问字符串流。双向流用不同的指针保存读位置和写位置。在读取和写入之间切换时,需要定位到正确的位置。
错误处理
C++程序不可避免地会遇到错误。例如,程序可能无法打开某个文件,网络连接可能断开,或者用户可能输入不正确的值。C++语言提供了一个名为“异常”的特性,用来处理这些不正常的但能预料的情况。
为简单起见,本书到目前为止实际上忽略了出错的情况。这一章讲述如何在一开始就将错误处理整合到程序中,以改变这种简化状况。本章重点介绍 C++异常包括语法的细节),并讲述如何有效地利用异常创建设计良好的错误处理程序。
错误与异常
程序不是孤立存在的; 它们都依赖于外部工具,例如操作系统界面、网络和文件系统、外部代码(如第三方库)和用户输入。所有这些领域都可能出现这样的状况: 需要响应所遇到的错误。这些潜在问题就是异常情况(exceptional situations),这是一个常见术语。即使编写的较完美的代码,也会遇到错误和异常。因此,编写计算机程序的任何人都必须包含错误处理功能。某些语言(例如 C)没有包含太多用于错误处理的特定语言工具,使用这种语言的程序员通常依赖于函数的返回值和其他专门方法。其他语言(例如 Java)强迫使用名为“异常”的
异常的含义
异常是这样一种机制: 一段代码提醒另一段代码存在“异常”情况或错误情况,所采用的路径与正常的代码路径不同。遇到错误的代码抛出异常,处理异常的代码捕获异常。异常不遵循你所熟悉的逐步执行的规则,当某段代码抛出异常时,程序控制立刻停止逐步执行,并转向异常处理程序(exception handlenD,异常处理程序可在任何地方,可位于同一函数中的下一行,也可在堆栈中相隔好几个函数调用。如果用体育运动做类比,将抛出异常的代码当作棒球的外场手将棒球抛回内场,离球最近的内场手(最近的异常处理程序)会捕获棒球。图14-1 显示了假想堆栈中的三个函数调用。函数 A()具有异常处理程序,A()调用函数 B(),B()调用函数 C(),C()抛出异常。图 14-2 显示了捕获异常的处理程序。C()和 B()的堆栈帧被删除,只留下 A()。
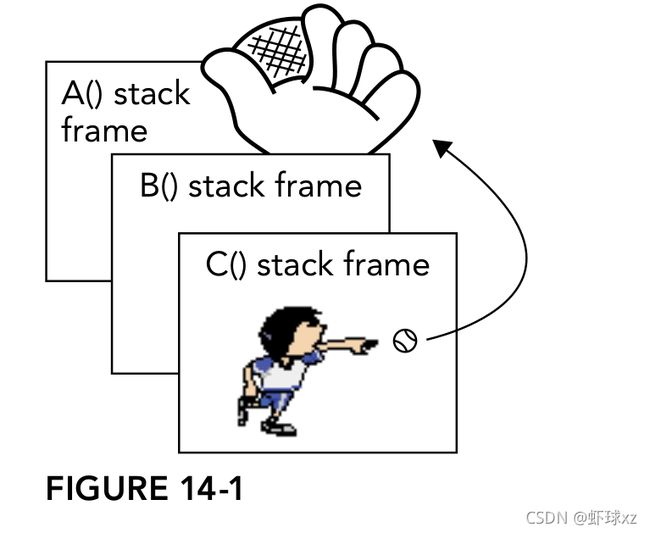

大多数现代编程语言,例如 C#和 Java,都支持异常,C++也全面支持异常。使用 C 的一些程序员可能没有见过异常,但是,一旦习惯使用异常,就可能离不开它们了。
C++中异常的优点
如前所述,程序运行时错误是不可避免的。尽管如此,多数 C 和 C++程序中的错误处理比较混乱,不能普饥适用。事实上,C 错误处理标准使用函数返回的整数代码和 errno 宏表示错误,许多 C++程序也采用了这种方法。每个线程都有自己的 errno 值。errno 用作线程局部整数变量(thread-local integer variable),被调用函数使用这个变量将发生的错误告诉调用函数。
遗憾的是,整数返回代码和 errno 的使用并不一致。有些函数可能用返回值 0 表示成功,用 - 1 表示错误。如果函数返回 - 1,还会将 ermo 设置为某个错误代码。另一些函数用返回值 0 表示成功,用非 0 值表示错误,实际的返回值表示错误代码,这些函数没有使用 ermo。还有一些函数将返回值 0 当作错误而不是成功,这大概是因为在 C 和 C++中,0 的求值结果为 false。这些不一致性可能会引起问题,因为程序员在遇到新函数时,会假定它的返回代码与其他类似函数相同,这一假定并非总是正确的。在 Solaris 9 中,有两个不同的同步对象库: POSIX 版本和 Solaris 版本。在 POSIX版本中初始化信号量的函数是 sm_init(),而在 Solaris 版本中初始化信号量的函数是 sema_init()。不仅如此,这 另一个问题是,C++中函数的返回类型只能有一种。因此,如果需要返回一个错误和一个值,就必须寻找其他机制。解决方案之一是返回 std::pair 或 std::tuple,这两个对象可用来存储两种或多种类型,后面的第 16 章中将讨论这两个对象。另一个选择是定义自己的结构或类,使其包含多个值,然后让函数返回结构或类的实例。还有一个选择是使用引用参数返回值或错误,或将错误代码作为返回类型的一个可能值,例如 nullptr 指针。所有这些情况都要求调用者负责显式地检测函数返回的所有错误,如果函数没有处理错误,就应该将错误提交给调用者。遗憾的是,这样做经常导致遗失与错误有关的重要细节。
C 程序员可能很熟悉 setjmp()/longjmp()机制,这一机制在 C++中无法正确使用,因为会绕开堆栈中的作用域析构函数。应尽力避免使用这一机制,在 C 程序中也是如此; 因此本书不解释这一机制的使用细节。异常提供了方便、一致、安全的错误处理机制。相对于 C 和 C++中的专门方法,异常具有许多优点。将返回代码作为报告错误的机制时,调用者可能会忽略返回的代码,不进行局部处理或不将错误代码向上提交。C++17 的[nodiscard]]特性(见第 11 章中的讨论)提供了可行的解决方案,以防止返回代码被忽略,但这并非周全的方案。异常不能被忽略: 如果没有捕获异常,程序会终止。返回的整数代码通常不会包含足够的信息。使用异常时可将任何信息从发现错误的代码传递到处理错误的代码。除错误信息外,异常还可用来传递其他信息,尽管许多程序员认为这样做是滥用异常机制 。异常处理可跳过调用堆栈的层次。也就是说,某个函数可处理沿着堆栈进行数次函数调用后发生的错误,而中间函数不需要有错误处理程序。返回代码要求堆栈中每一层调用的函数都必须在前一层之后显式地执行清理。在某些编译器中(现在这种编译器越来越少),异常处理让所有具有有异常处理程序的函数都多了一点儿开销。在现代编译器中,不抛出异常时几乎没有这个开销,实际抛出异常时这一开销也非常小。这并不是坏事,因为抛出异常应是例外情况。
异常机制
在文件的输入输出中经常发生异常情况。下面的函数打开一个文件,从这个文件中读取整数列表,然后将整数存储在 std::vector 数据结构中。其中缺少错误处理代码;
vector<int> readIntegerFile(string_view fileName){ ifstream inputStream(fileName.data()); //Read the integers one-by-one and add them to a vector vector integers; int temp; while(inputStream>>temp) { integers.push_back(temp); } return integers;}
下面的代码行从 fstream 持续地读取值,一直到文件的结尾或发生错误为止;
while(inputStream >> temp)
如果>>运算符遇到错误,就会设置 iftream 对象的错误位。在此情况下,bool()转换运算符将返回 false,while 循环将终止。有关流的内容已在第 13 章详细讨论。可这样使用 readIntegerFile():
const string fileName = "integerFile.txt";vector<int> myInts = readIntegerFile(fileName);for(const auto& element : myInts){ cout<<element<<" ";}cout<<endl;
本节的其余内容将说明如何使用异常进行错误处理,但首先需要深入理解如何抛出和捕获异常。
抛出和捕获异常
为了使用异常,要在程序中包括两部分: 处理异常的 try catch 结构和抛出异常的 throw 语句。二者都必须以某种形式出现,以进行异常处理。然而在许多情况下,throw 在一些库的深处(包括 C++运行时)发生,程序员无法看到这一点,但仍然不得不用 try_catch 结构处理抛出的异常。
e try/catch construct looks like this:try {// ... code which may result in an exception being thrown} catch (exception-type1 exception-name) {// ... code which responds to the exception of type 1} catch (exception-type2 exception-name) {// ... code which responds to the exception of type 2}// ... remaining code
导致地出异常的代码可能直接包含 throw 语句,也可能调用一个函数,这个函数可能直接抛出异常,也可能经过多层调用后调用为一个抛出异常的函数。如果没有抛出异常,catch 块中的代码不会执行,其后“剩余的代码”将在 try 块最后执行的语句之后执行。如果抛出了异常,throw 语句之后或者在抛出异常的函数后的代码不会执行,根据抛出的异常的类型,控制会立刻转移到对应的 catch 块。如果 catch 块没有执行控制转移(例如返回一个值,抛出新的异常或者重新殷出异常),那么会执行 catch 块演示异常处理的最简单示例是避免除 0。这个示例抛出一个 std::invalid_argument 类型的异常,这种异常类型需要头文件。
double SafeDivide(double num,double den)
{
if(den == 0)
throw invalid_argument("Divide by zero");
return num/den;
}
int main()
{
try
{
cout<<SafeDivide(5,2)<<endl;
cout<<SafeDivide(10,0)<<endl;
cout<<SafeDivide(3,3)<<endl;
}
catch(const invelid_argument& e)
{
cout<<"Caught exception "<<e.what()<<endl;
}
return 0;
}
输出如下所示:
2.5
Caught exception: Divide by zero
throw 是 C++中的关键字,这是抛出异常的唯一方法。throw 行的 invalid_ argument()部分意味着构建invalid_ argument 类型的新对象并准备将其抛出。这是 C++标准库提供的标准异常。标准库中的所有异常构成了一个层次结构,详见本章后面的内容。该层次结构中的每个类都支持 what()方法,该方法返回一个描述异常的const char*字符串(虽然 what()的返回类型是 const char*,但如果使用 UTF-8 编码,异常可支持 Unicode 字符串。有关 Unicode 字符串的详情,可参阅第 19 章)。该字符串在异常的构造函数中提供。回到 readIntegerFile()函数,最容易发生的问题就是打开文件失败。这正是需要抛出异常的情况,代码抛出一个 std::exception 类型的异常,这种异常类型需要包含头文件。语法如下所示:
vector<int> readIntegerFile(string_view fileName){ ifstream inputStream(fileName.data()); if(inputStream.fail()) { //We failed to open the file : throw an exception throw exception(); } //Read the integers one-by-one and add them to a vector vector integers; int temp; while(inputStream >> temp) { integers.push_back(temp); } return integers;}
注意:
始终在代码文档中记录函数可能抛出的异常,因为函数的用户需要了解可能抛出哪些异常,从而加以适当处理。如果函数打开文件失败并执行了 throw exception();行,那么函数的其余部分将被跳过,把控制转交给最近的异常处理程序。
如果还编写了处理异常的代码,这种情况下抛出异常效果最好。蜡常处理是这样一种方法:“尝试” 执行一块代码,并用另一块代码响应可能发生的任何错误。在下面的 main()函数中,catch 语句响应任何被 try 块抛出的 exception 类型异常,并输出错误消息。如果 try 块结束时没有抛出异常,catch 块将被忽略。可将 try catch 块当作 让语句。如果在 try 块中抛出异常,就会执行 catch 块,否则忽略 catch 块。
int main(){ const string fileName = "IntegerFile.txt"; vector<int> myInts; try { myInts = readIntegerFile(fileName); } catch(const exception& e) { cerr<<"Unable to open file "<<fileName<<endl; return 1; } for(const auto& element : myInts) { cout<<element<<" "; } cout<<endl; return 0;}
异常类型
可抛出任何类型的异常。可以抛出一个 std::exception 类型的对象,但异常未必是对象。也可以抛出一个简单的 int 值,如下所示:
vector<int> readIntegerFile(string_view fileName)
{
ifstream inputStream(fileName.data());
if(inputStream.fail())
{
//we failed to open the file: throw an exception
throw 5;
}
//Omitted for brevity
}
此后必须修改 catch 语句:
try
{
myInts = readIntegerFile(fileName);
}
catch(int e)
{
cerr<<"Unable to open file "<<fileName<<" (" <<e<<") "<<endl;
return 1;
}
另外,也可抛出一个 C 风格的 const char*字符串。这项技术有时有用,因为字符串可包含与异常相关的信息。
vector<int> readIntegerFile(string_view fileName){ ifstream inputStream(fileName.data()); if(inputStream.fail()) { //We failed to open the file:throw an exception throw "Unable to open file"; } //Omitted for brevity}
当捕获 const char*异常时,可输出结果:
try{ myInts = readIntegerFile(fileName);}catch(const char* e){ cerr<<e<<endl; return 1; }
尽管前面有这样的示例,但通常应将对象作为异常地出,原因有以下两点:对象的类名可传递信息。对象可存储信息,包括描述异常的字符串。C++标准库包含许多预定义的异常类,也可编写自己的异常类。本章后面将就此详细讨论。
抛出并捕获多个异常
打开文件失败并不是 readIntegerFile()遇到的唯一问题。 如果格式不正确, 读取文件中的数据也会导致错误。下面是 readIntegerFile()的一个实现,如果无法打开文件,或者无法正确读取数据,就会锰出异常。这里使用从 exception 派生的 runtime_error, 它允许你在构造函数中指定描述字符串。我们在中定义 runtime_error异常。
vector<int> readIntegerFile(string_view fileName)
{
ifstream inputStream(fileName.data());
if(inputStream.fail())
{
//We failed to open the file: throw an exception
throw runtime_error("Unable to open the file");
}
//Read the integers one-by-one and add them to a vector
vector<int> integers;
int temp;
while(inputStream >> temp)
{
integers.push_back(temp);
}
if(!inputStream.eof())
{
//We did not reach the end-of-file
//This means that some error occurred while reading the file
//Throw an exception
throw runtime_error("Error reading the file");
}
return integers;
}
main()中的代码不需要改变,因为已可捕获 exception 类型的异常,runtime_error 派生于 exception。然而,现在可在两种不同情况下抛出该异常;
try{ myInts = readIntegerFile(fileName);}catch(const exception& e){ cerr<<e.what()<<endl; return 1;}
另外,也可让 readIntegerFile()抛出两种不同类型的异常。 下面是 readIntegerFile()的实现,如果不能打开文件,就抛出 invalid_argument 类对象,如果无法读取整数,就抛出 runtime_error 类对象。invalid argument 和runtime_error 都是定义在头文件中的类,这个头文件是 C++标准库的一部分。
vector<int> readIntegerFile(string_view fileName){ ifstream inputStream(fileName.data()); if(inputStream.fail()) { //We failed to open the file:throw an exception throw invalid_argument("Unable to open the file"); } //Read the integers one-by-one and add them to a vector vector integers; int temp; while(inputStream >> temp) { integers.push_back(temp); } if(!inputStream.eof()) { //We did not reach the end-of-file //This means that some error occurred while reading the file //Throw an exception throw runtime_error("Error reading the file"); } return integer;}
invalid_argument 和 runtime_error 类没有公有的默认构造函数,只有以字符串作为参数的构造函数。现在 main()可用两个 catch 语句捕获 invalid_argument 和 runtime_error 异常:
try{ myInts = readIntegerFile(fileName);}catch(const invalid_argument& e){ cerr<<e.what()<<endl; return 1;}catch(const runtime_error& e){ cerr<<e.what()<<endl; return 2;}
如果蜡常在try块内部抛出, 编译器将使用恰当的 catch 处理程序与异常类型匹配。因此, 如果readIntegerFile()无法打开文件并抛出 invalid_argument 异常,第一个 catch 语句将捕获这个异常。如果 readIntegerFile()无法正确读取文件并抛出 runtime_error 异常,第二个 catch 语句将捕获这个异常。
- 匹配和 const
对于想要捕获的异常类型而言, 增加 const 属性不会影响匹配的目的。也就是说, 这一行可以与 runtime_error类型的任何异常匹配:
} catch (const runtime_error& e) {
下面的行也可与 runtime_error 类型的任何异常匹配
} catch (runtime_error& e) {
- 匹配所有异常
可用特定语法编写与所有异常匹配的 catch 行,如下所示;
try{ myInts = readIntegerFile(fileName);}catch(...){ cerr<<"Error reading or opening file "<<fileName<<endl; return 1;}
三个点并非排版错误,而是与所有异常类型匹配的通配符。当调用缺乏文档的代码时,可以用这一技术确保捕获所有可能的异常。然而,如果有被抛出的一组异常的完整信息,这种技术并不理想,因为它将所有异常都同等对待。更好的做法是显式地匹配异常类型,并采取恰当的针对性操作。
与所有异常匹配的 catch 块可以用作默认的 catch 处理程序。当异常抛出时,会按在代码中的显示顺序查找catch 处理程序。下例用 catch 处理程序显式地处理 invalid argument 和 runtime_error 异常,并用默认的 catch 处理程序处理其他所有异常。
try
{
//Code that can throw exceptions
}
catch(const invalid_argument& e)
{
//Handle invalid_argument exception
}
catch(const runtime_error& e)
{
//Handle runtime_error exception
}
catch(...)
{
//Handle all other exceptions
}
未捕获的异常
如果程序抛出的异常没有捕获,程序将终止。可对 main()函数使用 try_catch 结构,以捕获所有未经处理的异常,如下所示:
try{ main(argc,argv);}catch(...){ //issue error message and terminate programe}
然而,这一行为通常并非我们希望的。异常的作用在于给程序一个机会,以处理和修正不希望看到的或不曾预期的情况。
警告:
捕获并处理程序中可能抛出的所有异常。如果存在未捕获的异常, 程序行为也可能发生变化。当程序遇到未捕获的异常时, 会调用内建的 terminate()函数, 这个函数调用中的 abort()来终止程序。可调用 set_ terminate()函数设置自己的 terminate_handler(),这个函数采用指向回调函数(既没有参数,也没有返回值)的指针作为参数。terminate() 、set_terminate()和terminate_ handler()都在头文件中声明。下面的代码高度概括了其运行原理:
try{ main(argc,argv);}catch(...){ if(terminate_handle != nullptr) { terminate_handler(); } else { terminate(); }}
不要为这一特性激动,因为回调函数必须终止程序。错误是无法忽略的,然而可在退出之前输出一条有益的错误消息。下例中,main()函数没有捕获 readIntegerFile()抛出的异常,而将 terminate_handler()设置为自定义回调。这个回调通过调用 exit()显示错误消息并终止进程。exit()函数接收返回给操作系统的一个整数,这个整数可用于确定进程的退出方式。
void myTerminate(){ cout<<"Uncaught exception!"<<endl; exit(1);}int main(){ set_terminate(myTerminate); const string fileName = "IntegerFile.txt"; vector<int> myInts = readIntegerFile(fileName); for(const auto& element : myInts) { cout<<element<<" "; } cout<<endl; return 0;}
当设置新的 terminate_handler()时,set terminate()会返回旧的 terminate_ handler()。terminate_ handler()被应用于整个程序,因此当需要新 terminate_ handler()的代码结束后,最好重新设置旧的 terminate handler)。上面的示例中,整个程序都需要新的 terminate_handler(),因此不需要重新设置。尽管有必要了解 set_terminate(),但这并不是一种非常有效的处理异常的方法。建议分别捕获并处理每个异常,以提供更精确的错误处理。
注意;
在专门编写的软件中,通常会设置 terminate_handler(),在进程结束前创建前溃转储。此后将崩溃转储上传给调试器,从而允许确定未捕获的异常是什么,起因是什么。 但是,崩溃转储的编写方式与平台相关,因此本书不予进一步讨论。
noexcept
使用函数时,可根据需要抛出任何异常。但可使用 noexcept 关键字标记函数,指出它不抛出任何异常。例如,为下面的 readIntegerFile()函数标记了 noexcept,即不允许它抛出任何异常
vector<int> readIntegerFile(string_view fileName) noexcept;
带有 noexcept 标记的函数不应抛出任何异常。如果一个函数带有 noexcept 标记,却以某种方式扫出了异常,C++将调用 terminate()来终止应用程序。在派生类中重写虚方法时,可将重写的虚方法标记为 noexcept(即使基类中的版本不是 noexcep)。反过来也可行。
抛出列表(已不赞成使用/已删除)
C++的旧版本允许指定函数或方法可抛出的异常,这种规范叫作抛出列表(throw list或异常规范(exceptionSpecification)。
警告;
自 C++11 之后,已不鞠成使用异常规范; 自 C++17 之后,已不再支持异常规范。但 noexcept 和 throw()除外,throw()与 noexcept 等效。
由于 C++17 已正式取消对异常规范的支持,本书将不使用它们,也不进行详细解释。自 C++11 之后,异常规范虽然仍受支持,但已经极少使用。这里只对其进行简单介绍,你可大致了解其语法,在遗留代码中遇到它们时不至于陷入迷茫。下面的这个 readIntegerFile()函数包含了异常规范:
vector<int> readIntegerFile(string_view fileName) throw(invalid_argument,runtime_error){ //Remainder of the function is the same as before}
如果函数抛出的异常不在异常规范内, C++运行时 std::unexpected0默认情况下调用 std::terminate()来终止应用程序。
异常与多态性如前所述,可抛出任何类型的异常。然而,类是最有用的异常类型。实际上蜡常类通常具有层次结构,因此在捕获异常时可使用多态性。
标准异常体系
前面介绍了 C++标准异常层次结构中的一些异常, exception、runtime_error 和 invalid_argument。图 14-3 显示了完整的层次结构。为完整起见,图 14-3 中显示了所有标准异常,包括标准库抛出的标准异常,后续章节将介绍这些异常。

C++标准库中抛出的所有异常都是这个层次结构中类的对象。这个层次结构中的每个类都支持 what()方法,这个方法返回一个描述异常的 const char*字符串。可在错误信息中使用这个字符串。大多数异常类(基类 exception 是明显的例外)都要求在构造函数中设置 what()返回的字符串。这就是必须在runtime_error 和 invalid_argument 构造函数中指定字符串的原因。本章的示例都是这么做的。下面是readIntegerFile()的另一个版本,它也在错误消息中包含文件名。另外注意,这里使用了用户定义的标准字面量s(见第 2 章的介绍),将字符串字面量解释为 std::string。
vector<int> readIntegerFile(string_view fileName)
{
ifstream inputStream(fileName.data());
if(inputStream.fail())
{
//We failed to open the file:throw an exception
const string error = "Unable to open file "s + fileName.data();
throw invalid_argument(error);
}
//Read the integers one-by-one and add them to a vector
vector<int> integers;
int temp;
while(inputStream >> temp)
{
integers.push_back(temp);
}
if(!inputStream.eof())
{
//We did not reach the end-of-file
//This means that some error occurred while reading the file
//Throw an exception
const string error = "Unable to read file "s + fileName.data();
throw runtime_error(error);
}
return integers;
}
int main()
{
//Code omitted
try
{
myInts = readIntegerFile(fileName);
}
catch(const invalid_argument& e)
{
cerr<<e.what()<<endl;
return 1;
}
catch(const runtime_error& e)
{
cerr<<e.what()<<endl;
return 2;
}
//Code omitted
}
在类层次结构中捕获异常
异常层次结构的一个特性是可利用多态性捕获异常。例如,如果观察 main()中调用 readIntegerFile()之后的两条 catch 语句,就可以发现这两条语句除了处理的异常类不同之外没有区别。invalid_argument 和 runtime_error都是 exception 的派生类,因此可使用 exception 类的一条 catch 语句替换这两条 catch 语句:
try
{
myInts = readIntegerFile(fileName);
}
catch(const exception& e)
{
cerr<<e.what()<<endl;
return 2;
}
exception 引用的 catch 语句可与 exception 的任何派生类匹配, 包括 invalid_argument 和 runtime_error。 注意捕获的异常在异常层次结构中的层次越高,错误处理就越不具有针对性。通常应该尽可能有针对性地捕获异常。警告;当利用多态性捕获异常时,一定要按引用捕获。如果按值捕获异常,就可能发生截断,在此情况下将丢失对象的信息。关于截断请参阅第 10 章。
当使用了多条 catch 子名时,会按在代码中出现的顺序匹配 catch 子句,第一条匹配的 catch 子句将被执行。如果某条 catch 子句比后面的 catch 子句范围更广,那么这条 catch 子句首先被匹配,而后面限制更多的 catch子句根本不会被执行。因此,catch 子句应按限制最多到限制最少的顺序出现。例如,假定要显式捕获readIntegerFile()的 invalid_argument,就应该让一般的异常与其他类型的异常匹配。正确做法如下所示:
myInts = readIntegerFile(fileName);}catch(const invalid_argument& e){ //List the derived class first //Take some special action for invalid filenames}catch(const exception& e) //Now list exception{ cerr<
第一条 catch 子句捕获 invalid_argument 异常,第二条 catch 子句捕获任何类型的其他异常。然而,如果将catch 子句的顺序和弄反,就不会得到同样的结果:
try{ myInts = readIntegerFile(fileName);}catch(const exception& e) //BUG: catching base class first!{ cerr<
编写自己的异常类
编写自己的异常类有两个好处: C++标准库中的异常数目有限,可在程序中为特定错误创建更有意义的类名,而不是使用具有通用名称的异常类,例如 runtime_error。
可在异常中加入自己的信息,而标准层次结构中的异常只允许设置错误字符串,例如可能想在异常中传递不同信息。建议自己编写的异常类从标准的 exception 类直接或间接继承。如果项目中的所有人都遵循这条规则,就可确定程序中的所有异常都是 exception 类的派生类(假定不会使用第三方库破坏这条规则)。这一指导方针更便于用多态性处理异常。
例如,在 readIntegerFile()中,invalid_argument 和 runtime_error 不能很好地捕获文件打开和读取错误。可为文件错误定义自己的错误层次结构,从泛型类 FileError 开始:
class FileError : public exception{ public: FileError(string_view fileName) : mFileName(fileName){} virtual const char* what() const noexcept override { return mMessage.c_str(); } string_view getFileName() const noexcept{ return mFileName; } protected: void setMessage(string_view message){ mMessage = message; } private: string mFileName; string mMessage;};
作为一名优秀的程序员,应将 FileError 作为标准异常层次结构的一部分,将其作为 exception 的子类是恰当的。编写 exception 的派生类时,需要重写 what()方法,这个方法的原型已经出现过,其返回值为一个在对象销毁之前一直有效的 const char*字符串。在 FileError 中,这个字符串来自 mMessage 数据成员。FileError 的派生类可使用受保护的 setMessage()方法设置消息。泛型类 FileError 还包含文件名以及文件名的公共访问器。readIntegerFile()中的第一种异常情况是无法打开文件。因此,下面编写 FileError 的派生类 FileOpenError:
class FileOpenError : public FileError{ public: FileOpenError(string_view fileName) : FileError(fileName) { setMessage("Unable to open "s + fileName.data()); }};
FileOpenError 修改 mMessage 字符串,令其表示文件打开错误。readIntegerFile()中的第二种异常情况是无法正确读取文件。对于这一异常,或许应该包含文件中发生错误的行号,以及 what()返回的错误信息字符串中的文件名。下面是 FileError 的派生类 FileReadError:
class FileReadError : public FileError
{
public:
FileOpenError(string_view fileName) : FileError(fileName)
{
setMessage("Unable to open "s + fileName.data);
}
};
FileOpenError 修改 mMessage 字符串,令其表示文件打开错误。readIntegerFile()中的第二种异常情况是无法正确读取文件。对于这一异常,或许应该包含文件中发生错误的行号,以及 what()返回的错误信息字符串中的文件名。下面是 FileError 的派生类 FileReadError:
class FileReadError : public FileError{ public: FileReadError(string_view fileName,size_t lineNumber) :FileError(fileName),mLineNumber(lineNumber) { ostringstream ostr; ostr<<"Error reading "<<fileName<<" at line "<<lineNumber; setMessage(ostr.str()); } size_t getLineNumber() const noexcept{ return mLineNumber; } private: size_t mLineNumber;}
当然,为正确地设置行号,需要修改 readIntesgerFile()函数,以跟踪读取的行号,而不只是直接读取整数。下面是使用了新异常的 readIntegerFile()函数:
vector<int> readIntegerFile(string_view fileName)
{
ifstream inputStreamName.data();
if(inputStream.fail())
{
//We failed to open the file: throw an exception
throw FileOpenError(fileName);
}
vector<int> intergers;
size_t lineNumber = 0;
while(!inputStream.eof())
{
//Read one line from the file
string line;
getline(inputStream,line);
++lineNumber;
//create a string stream out of the line
istringstream lineStream(line);
//Read the integers one-by-one and add them to a vector
int temp;
while(lineStream >> temp)
{
integers.push_back(temp);
}
if(!lineStream.eof())
{
//We did not reach the end of the string stream
//This means that some error occurred while reading this line
//Throw an exception
throw FileReadError(fileName,lineNumber);
}
}
return integers;
}
现在,调用 readIntegerFile()的代码可使用多态性捕获 FileError 类型的异常,如下所示:
try
{
myInts = readIntegerFile(fileName);
}
catch(const FileError& e)
{
cerr<<e.what()<<endl;
return 1;
}
在编写将其对象用作异常的类时,有一个诀穿。当某段代码抛出一个异常时,使用移动构造函数或复制构造函数,移动或复制被殷出的值或对象。因此,如果编写的类的对象将作为异常抛出,对象必须复制和/或移动。这意味着如果动态分配了内存,就必须编写析构函数、复制构造函数、复制赋值运算符和/或移动构造函数与移动赋值运算符,人参见第9音。
堆栈的释放与清理
当某段代码抛出一个异常时,会在堆栈中寻找 catch 处理程序。catch 处理程序可以是在堆栈上执行的0个或多个函数调用。当发现一个 catch 处理程序时,堆栈会释放所有中间堆栈帧,直接跳到定义 catch 处理程序的堆栈层。堆栈释放(stack unwinding)意味着调用所有具有局部作用域的名称的析构函数,并忽略在当前执行点之前的每个函数中所有的代码。然而当释放堆栈时,并不释放指针变量,也不会执行其他清理。这一行为会引发问题,下面的代码演示了这一点:
void funcOne();
void funcTwo();
int main()
{
try
{
funcOne();
}
catch(const exception& e)
{
cerr<<"Exception caught"<<endl;
return 1;
}
return 0;
}
void funcOne()
{
string str1;
string* str2 = new string();
funcTwo();
delete str2;
}
void funcTwo()
{
ifstream fileStream;
fileStream.open("filename");
throw exception();
fileStream.close();
}
当 funcTwo()抛出一个异常时,最近的异常处理程序在 main()中。控制立刻从 foncTwo()的这一行:
throw exception();
跳转到 main()的这一行:
cerr << "Exception caught !"<<endl;
在 funcTwo()中,控制依然在抛出异常的那一行,因此后面的行永远没机会执行:
fileStream.close();
然而幸运的是,因为 fileStream 是堆栈中的局部变量,所以会调用 istream 析构函数。ifstream 析构函数会自动关闭文件,因此在此不会泄漏资源。如果动态分配了 fileStream, 那么这个指针不会销毁,文件也不会关闭。在 funcOne中,控制在 funcTwo()的调用中,因此后面的行永远没机会执行:
delete str2;
在此情况下,确实会发生内存泄漏。堆栈释放不会自动调用 str2 上的 delete,然而会正确地销毁 strl,因为strl 是堆栈中的局部变量。堆栈释放会正确地销毁所有局部变量。
警告;
粗心的异常处理会导致内存和资源的泄漏。不应将旧的 C 分配模式(即便使用了 new,看起来也像 C++模式)混入类似于异常的现代编程方法中,这就是原因之一。在 C++中,应该用基于堆栈的内存分配或者下面将要讨论的技术处理这种情况。
使用智能指针
如果基于堆栈的内存分配不可用,就应使用智能指针。在处理异常时,智能指针可使编写的代码自动防止内存或资源的泄漏。无论什么时候销毁智能指针对象,都会释放底层资源。下面使用智能指针 unique ptr(在中定义,如第 1 章所述)重写了前面的 funcOne()函数:
void funcOne(){ string str1; auto str2 = make_unique<string>("hello"); funcTwo();}
当从 funcOne()返回或抛出异常时,将自动删除 str2 指针。当然,只在确有必要时,才进行动态分配。例如,在前面的 funcOne()函数中,没必要使 str2 成为动态分配的字符串。它应当只是一个基于堆栈的字符串变量。这里只将其作为一个简单例子,演示抛出异常的结果。
注意:
使用智能指针或其他RAII对象(见第 28 章)时,永远不必考虑释放底层的资源: RAII 对象的析构函数会自动完成这一操作,无论是正常退出函数,还是抛出异常退出函数,都是如此。
捕获、清理并重新抛出
避免内存和资源泄漏的另一种技术是针对每个函数,捕获可能抛出的所有异常,执行必要的清理,并重新抛出异常,供堆栈中更高层的函数处理。下面是使用这一技术修改后的 fhncOne()函数,
void funcOne()
{
string str1;
string* str2 = new string();
try
{
funcTwo();
}
catch(...)
{
delete str2;
throw; //rethrow the exception
}
delete str2;
}
这个函数用蜡常处理程序封装对 funcTwo()函数的调用,处理程序执行清理(在 str2 上调用 delete)并重新殷出异常。关键字 throw 本身会重新抛出最近捕获的任何异常。注意 catch 语句使用…语法捕获所有异常。这一方法运行良好,但有点繁杂。需要特别注意,现在有两行完全相同的代码在 str2 上调用 delete: 一行用来处理异常,另一行在函数正常退出的情况下执行。
警告:
智能指针或其他RAII类是比捕获、清理和重新抛出技术更好的解决方案。
常见的错误处理问题
是否在程序中使用异常取决于程序员及其同事。然而无论是否使用异常,我们都强烈建议为程序提供正式的错误处理计划。如果使用异常,通常会比较容易地想出统一的错误处理计划,但不使用异常,也可能得到这样的计划。良好设计的最重要特征是所有程序模块的错误处理都是一致的。参与项目的所有程序员都应该理解并遵循这条错误处理规则。
本章讨论使用异常时最常见的错误处理问题,但不使用异常的程序也会涉及这些问题。
内存分配错误
如果无法分配内存,new 和 new[]的默认行为是抛出 bad_alloc 类型的异常,这种异常类型在头文件中定义。代码应该捕获并正确地处理这些异常。
int *ptr = nullptr;
size_t integerCount = numeric_limits<size_t>::max();
try
{
ptr = new int[intergerCount];
}
catch(const bad_alloc& e)
{
cerr<<__FILE__<<"("<<__LINE__<<"):Unable to allocate memory:"<<e.what()<<endl;
//Handle memory allocation failure
return ;
}
//Proceed with function that assumes memory has been allocated;
注意上面的代码使用了预定义的预处理符号_FILE_和_LINE_,这两个符号将被文件名称和当前行号替换掉,从而使调试更容易。
注意:
这个示例向 cerr 输出一条错误消息,这样做的前提是假定程序在控制台模式下运行.在 GUI 应用程序中通常不需要控制台,此时应该以 GUI 特定的方式向用户显示错误消息。当然,可用一个 try/catch 块在程序的高层批量处理许多可能的新错误,如果这样做对程序有效的话。另一个考虑是记录错误时可能尝试分配内存。如果 new 执行失败,可能没有记录错误消息的足够内存。
\1. 不抛出异常的 new
如果不喜欢异常,可回到旧的 C 模式,在这种模式下,如果无法分配内存,内存分配例程将返回一个空指针。C++提供了 new 和 new[]的 nothrow 版本,如果内存分配失败,将返回 nullptr,而不是抛出异常。使用语法 new(nothrow)而不是 new 可做到这一点,如下所示:
int* ptr = new(nothrow) int[integerCount];
if(ptr = nullptr)
{
cerr<<__FILE__<<"(" << __LINE__ << "):Unable to allocate memory!"<<endl;
//Handle memory allocation failure
return;
}
//Proceed with function that assumes memory has been allocated.
- 定制内存分配失败的行为
C++人允许指定 new handler 回调函数。默认情况下不存在 new handler,因此 new 和 new[]只是抛出 bad_alloc异常。然而如果存在 new handler,当内存分配失败时,内存分配例程会调用 new handler 而不是抛出异常。如果new handler 返回,内存分配例程试着再次分配内存;, 如果失败,会再次调用 new handler。这个循环变成无限循环,除非 new handler 用下面的 3 个选项之一改变这种情况。下面列出这些选项,并给出了注释:e ”提供更多的可用内存 ”提供空间的技巧之一是在程序启动时分配一大块内存,然后在 new handler 中释放这块内存。一个实例是,当遇到内存分配错误时,需要保存用户状态,这样就不会有工作丢失。关键在于,在程序启动时,分配一块足以完整保存文档的内存。当触发 new handler 时,可释放这块内存、保存文档、重启应用程序并重新加载保存的文档。e ,抛出异常 ”C++标准指出,如果 new handler 抛出异常,那么必须是 bad_alloc 异常或者派生于 bad_alloc的异常。
。 可编写和抛出 document recovery _alloc 异常,这种异常从bad_alloc 继承而来。可在应用程序的某个地方捕获这种异常,然后触发文档保存操作,并重启应用程序。,。 可编写和抛出派生于 bad_alloc 的 please terminate_me 异常。在顶层函数中,例如 main(),可捕获这种异常,并通过从顶层函数返回来对其进行处理。建议不要调用 exit(),而应从顶层函数返回以终止程序
设置不同的 new handler 从理论上讲,可使用一系列 new handler,每个都试图分配内存,并在失败时设置一个不同的 new handler。然而,这种情形通常过于复杂,并不实用。如果在 new handler 中没有这么做,任何内存分配失败都会导致无限循环。如果有一些内存分配会失败,但又不想调用 new handler,那么在调用 new 之前,只需要临时将新的 new handler 重新设置为默认值 nullptr。调用在头文件中声明的 set_new_handler0),从而设置 new handler。下面是一个记录错误消息并抛出异常的 new handler 示例:
class please_terminate_me : public bad_alloc{};
void myNewHandler()
{
cerr<<"Unable to allocate mempory"<<endl;
throw please_terminate_me();
}
new handler 不能有参数,也不能返回值。如前面列表中的第 2 个选项所述,new handler 抛出please terminate_me 异常。可采用以下方式设置 new handler:
int main()
{
try
{
//Set the new new_handle and save the old one
new_handle oldHandle = set_new_handle(MyNewHandler);
//Generate allocation error
size_t numInts = numeric_limits<size_t>::max();
int* ptr = new int[numInts];
//Reset the old new_handler
set_new_handle(oldHandler);
}
catch(const please_terminate_me&)
{
cerr<<__FILE__<<"("<<__LINE__<<"):Terminating program"<<endl;
return 1;
}
return 0;
}
构造函数中的错误
在异常出现之前, C++程序员经常受到错误处理和构造函数的困扰。如果构造函数没有正确地创建对象,会发生什么? 构造函数没有返回值,因此在异常出现之前,标准的错误处理机制无法运行。如果不使用异常,最多可在对象中设置一个标记,指明对象没有正确构建。可提供一个类似于 checkConstructionStatus()的方法,返回这个标志的值,并期望用户记得在构建对象之后调用这个方法。异常提供了更好的解决方案。虽然无法在构造函数中返回值,但是可以抛出异常。通过异常可很方便地告诉客户是否成功创建了对象。然而在此有一个重要问题: 如果异常离开构造函数,对象的析构函数将无法调用。因此在异常离开构造函数前,必须在构造函数中仔细清理所有资源,并释放分配的所有内存。其他函数也会遇到这个问题,但在构造函数中更微妙,因为我们习惯于让析构函数处理内存分配和释放资源。
本节以 Matrix 类作为示例,这个类的构造函数可正确处理异常。 注意这个示例使用裸指针 mMatrix 来演示问题。在生产级代码中,应避免使用裸指针,而使用标准库容器! Matrix 类模板的定义如下所示;
template<typename T>
class Matrix
{
public:
Matrix(size_t width,size_t height);
virtual ~Matrix();
private:
void cleanup();
size_t mWidth = 0;
size_t mHeigth = 0;
T** mMatrix = nullptr;
}
Matrix 类的实现如下所示。 注意对 new 的第一个调用并没有用 try/catch 块保护。第一个 new 抛出异常也没有关系,因为构造函数此时还没有分配任何需要释放的内存。如果后面的 new 抛出异常,构造函数必须清理所有已经分配的内存。然而,由于不知道工构造函数本身会抛出什么异常,因此用.…捕获所有蜡常,并将捕获的异常嵌套在 bad_alloc 异常中。 注意,使用全语法,通过首次调用 new 分配的数组执行零初始化,即每个元素都是 nullptr。这简化了 cleanup()方法,因为允许它在 nullptr 上调用 delete。
template<typename T>
Matrix<T>::Matrix(size_t width,size_t height)
{
mMatrix = new T*[width] (); //Array is zero-initialized!
//Don't initialize the mWidth and mHeight members in the ctor-initializer
//These should ony be initialized when the above mMatrix allocation successeds
mWidth = width;
mHeight = height;
try
{
for(size_t i = 0;i < width;++i)
{
mMaxtrix[i] = new T[height];
}
}
catch(...)
{
std::cerr<<"Exception caught int constructor,cleaning up...."<<std::endl;
cleanup();
//Nest any caught exception inside a bad_alloc exception
std::throw_with_nested(std::bad_alloc());
}
}
template<typename T>
Matrix<T>::~Matrix()
{
cleanup();
}
template<typename T>
void Matrix<T>::cleaup;
{
for(size_t i = 0;i < mWidth;++i)
delete[] mMatrix[i];
delete[] mMaxtrix;
mMatrix = nullptr;
mWidth = mHeight = 0;
}
警告:
记住,如果异常离开了构造函数,将永远不会调用对象的析构函数!可采用如下方式测试 Matrix 类模板:
class Element
{
//Kept to a bare minimum,but in practice,this Element class
//could throw exceptions in its constructor
private:
int mValue;
};
int main()
{
Matrix<Element>m(10,10);
return 0;
}
如果使用了继承,会发生什么情况? 那样的话,基类的构造函数在派生类的构造函数之前运行,如果派生类的构造函数抛出一个异常,那么 C++会运行任何构建完整的基类的析构函数。
注意:
C++保证会运行任何构建完整的“子对象,的析构邓数。 因此,任何没有发生异常的构造函数所对应的析构子数都会运行.
构造函数的 function-try-blocks
本章到目前为止讨论的异常机制可完美处理函数内的异常。然而,如果在构造函数的 ctor-initializer 中抛出异常,该如何处理呢? 本节介绍能捕获这类异常的 function-try-blocks。function-try-blocks 用于普通函数和构造函数。本节重点介绍 function-try-blocks 如何用于构造函数。大多数 C++程序员,甚至包括经验丰富的 C++程序员,都不了解这一特性的存在,尽管这一特性已经问世很多年了。下面的伪代码显示了构造函数的 function-try-blocks 的基本语法:
MyClass::MyClass()
try:<ctor-initializer>
{
/*...constructor body...*/
}
catch(const exception& e)
{
/*...*/
}
可以看出,try 关键字应该刚好在 ctor-intializer 之前。catch 语句应该在构造函数的右花括号之后,实际上是将 catch 语句放在构造函数体的外部。当使用构造函数的 function-try-blocks 时,要记住如下限制和指导方针:e catch 语句将捕获任何异常,无论是构造函数体还是 ctor-intializer 直接或间接抛出的异常,都是如此。e catch 语句必须重新抛出当前异常或抛出一个新异常。如果 catch 语句没有这么做, 运行时将自动重新抛出当前异常。e catch 语句可访问传递给构造函数的参数。e 当 catch 语句捕获 function-try-blocks 内的异常时,构造函数已构建的所有对象都会在执行 catch 语句之前销毁。e 在 catch 语句中,不应访问对象成员变量,因为它们在执行 catch 语句前就销毁了(参见上一条)。但是,如果对象包含非类数据成员,例如裸指针,并且它们在抛出异常之前初始化,就可以访问它们。如果有这样的裸资源,就必须在 catch 语句中释放它们。ee 对于 fonction-try-blocks 中的 catch 语句而言,其中包含的函数不能使用 retum 关键字返回值。构造函数与此无关,因为构造函数没有返回值。由于有以上限制,构造函数的 fnction-try-blocks 只在少数情况下有用:ee 将 ctor-intializer 抛出的异常转换为其他异常。
下例演示 function-try-blocks 的用法。下面的代码定义了一个 SubObject 类,这个类只有一个构造函数,这个构造函数抛出一个 runtime_error 类型的异常。
class SubObject
{
public:
SubObject(int i);
};
SubObject::SubObject(int i)
{
throw std::runtime_error("Exception by SubObject ctor");
}
MyClass 类有一个 int*类型的成员变量以及一个 SubObject 类型的成员变量:
class MyClass
{
public:
MyClass();
private:
int* mData = nullptr;
SubObject mSubObject;
};
SubObject 类没有默认构造函数这意味着需要在 MyClass 类的 ctor-intializer 中初始化 mSubObject*MyClass类的构造函数将使用 function-try-blocks 捕获 ctor-intializer 中抛出的异常。
MyClass:MyClass()
try:mData(new int[42]{1,2,4}),mSubObject(42)
{
/*..constructor body..*/
}
catch(const std::exception& e)
{
//Cleanup memory
delete[] mData;
mData = nullptr;
cout<<"function-try-block caught: "<<e.what()<<"'"<<endl;
}
记住, 构造函数的 function-try-blocks 中的 catch 语句必须重新抛出当前异常, 或者抛出新异常。前面的 catch语句没有抛出任何异常,因此 C++运行时将自动重新抛出当前异常。下面的简单函数使用了前面的类:
int main()
{
try
{
MyClass m;
}
catch(const std::exception& e)
{
cout<<"main() caught: "<<e.what()<<"'"<<endl;
}
return 0;
}
前面示例的输出如下所示:
function-try-block caught: "Exception by Subobject ctor'
main () caught: "Exception by SubObject ctor'
注意,该例中的代码十分危险。进入 catch 语句时,mData 可能包含垃圾,有具体取决于初始化顺序。删除这样的垃圾指针会导致不确定的行为。在本例中,解决方案是为 mData 成员使用智能指针(如 std::unique_ptr())以删除 function-try-blocks 。
警告;
避免使用 function-try-blocks!通常,仅将裸资源作为数据成员时,才有必要使用 function-try-blocks。可使用诸如 std::unique ptr 的 RAII类来避免使用裸资源。第 28 章将讨论 RAI 类。function-try-blocks 并不局限于构造函数,也可用于普通函数。然而,对于普通函数而言,没理由使用function-try-blocks,因为可方便地将 function-try-blocks 转换为函数体内部的简单 try/catch 块。与构造函数相比,对普通函数使用 fonction-try-blocks 的明显不同在于,catch 语句不需要重新抛出当前异常或新异常,C++运行时也不会自动重新抛出异常。
析构函数中的错误
必须在析构函数内部处理析构函数引起的所有错误。不应该让析构函数抛出任何异常,原因如下:析构函数会被隐式标记为 noexcept,除非添加了 noexcept(false)标记,或者类具有子对象,而子对象的析构函数是 noexcept(false)。如果带 noexcept 标记的析构函数抛出一个异常,C++运行时会调用 std::terminate()来终止应用程序。本书不详细讨论 noexcept(expression)说明符。你只需要知道 noexcept 等同于 noexcept(true),而 noexcept(false)与 noexcept(true)相反,也就是说,标记了 noexcept(false)的方法可抛出任何需要的异常。
(2) 在堆栈释放过程中,如果存在另一个挂起的异常,析构函数可以运行。如果在堆栈释放期间从析构函数抛出一个异常,C++运行时会调用 std::terminate()来终止应用程序。C++确实为勇敢而好奇的人提供了一种功能,用于判断析构函数是因为正常的函数退出或调用了 delete 而执行,还是因为堆栈释放而执行。头文件中声明了一个函数 uncaught_exception(),该函数可返回未捕获异常的数量,所谓未捕获异常,是指已经抛出但尚未到达匹配 catch 的异常。如果 uncaught_exceptions0的结果大于 0,则说明正在执行堆栈释放。但这个函数用起来十分复杂,应避免使用。注意在 C++17 之前,该函数名为 uncaught_ exception(),即 exception 之后不带sS,如果正在执行堆栈释放,该函数返回布尔值 tue。
(3) 客户应该采取什么措施? 客户不会显式调用析构函数: 客户调用 delete,delete 调用析构函数。如果在析构函数中抛出一个异常,让客户怎么办? 客户无法在此使用对象调用 delete,也不能显式地调用析构函数。
(4) 析构函数是释放对象使用的内存和资源的一个机会。如果因为异常而提前退出这个函数,就会浪费这个机会,将永远无法回头释放内存或资源。
警告:
在析构函数中要小心捕获调用析构函数时可能抛出的任何异常。