mysql迁移后数据对比_Oracle/云MySQL/MsSQL“大迁移”真相及最优方案
原标题:Oracle/云MySQL/MsSQL“大迁移”真相及最优方案
最近一段时间碰到一些数据迁移的项目,如:Oracle迁移到MySQL,MsSQL迁移到MySQL,云MySQL迁移到本地MySQL。对于这方面做了系统的整理。包括:迁移方案的选择、如何跳出迁移遇到的坑、怎样修改MySQL参数获取最大性能,加入分库分表的需求如何实现?文章的最后,作者做了很多可行性的总结,码字不易,如果对您有帮助,感谢转发。
迁移方案的选择:
抛开业务逻辑的因素,根据不同的版本、不同平台、不同停机时间需求,有不同的可选路径决定迁移方
法和工具:
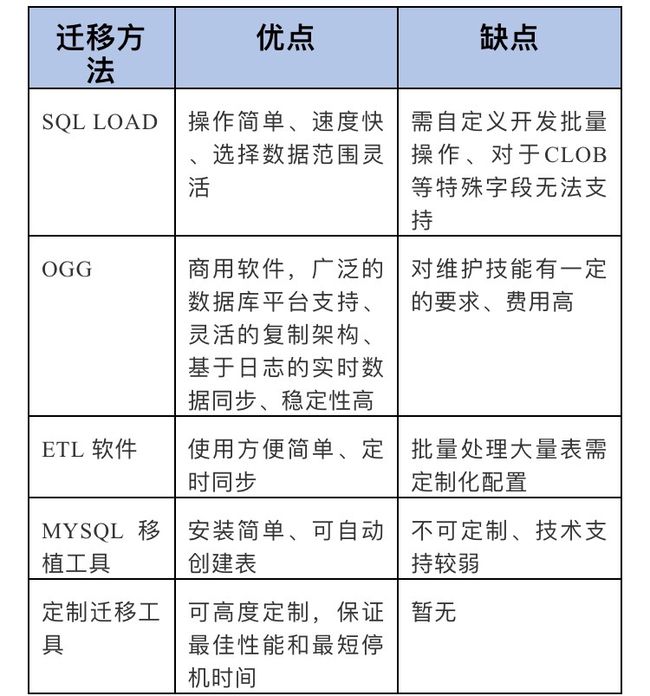
由于不同的数据库版本、不同的组件安装、不同的应用开发特征都会导致迁移计划的复杂性和差异性。
调研中,除了OGG,有几个MySQL迁移的工具,推荐的比较多,但是收费的。
【工具:OGG (goldengate)】
同时支持Oracle,Mssql 迁移到 MySQL 上
参数:filter,COMPUTE 进行分库分表逻辑
● SQLyog
(https://www.webyog.com/product/sqlyog)
● Navicat Premium
(https://www.navicat.com/products/navicat-premium)
● Mss2sql
(http://www.convert-in.com/)
● DB2DB
(http://www.szmesoft.com/DB2DB)
选择迁移软件,必须要考虑 软件易用性, 处理速度和内存占用,数据完整性。这部分很重要。
以上四款软件中:
1. 最不推荐使用的是 Navicat Premium,主要原因是数据的完整性表现较差,转换后的数
据不能立即用于生产环境,需要程序员仔细自行查找原因和分析。
2. SQLyog 有较好的数据完整性,但整体处理速度非常的慢,如果数据较大的情况下,需要浪费非常多宝
贵的时间。比较推荐的是
3. DB2DB,处理速度,数据完整性,整体表现较好,操作起来实在方便。
我本人趋向于自己写python脚本。
迁移中会存在哪些细节上的问题?
1. 字符集
字符集转化:Oracle字符集AL32UTF8,ZHS16GBK,转换成MySQL支持的字符集Latin1,utf8,utf8mb4(emoji的表情符)
Mysql对于字符集里有两个概念:一个是"Character set"另一个是"Collations"。
Collations:Mysql对字符的比较,排序规则
Character set:字符的编码方式
2. 字段类型
Oracle Row, Clob,BINARY_DOUBLE类型转化成MySQL支持的字段类型。
如:Oracle CLOB字段最大长度4G对应MySQL LONGTEXT 等等,但要是把数据这些数据迁移到MySQL上,可以想象到会发生什么事情。
3. 主键
有些源表没有设置主键, 但对于MySQL来说主键的意思非常大,特别是复制环节里。
4. 迁移时间和数据量
对于现在在线不间断提供的业务非常重要,按照这个指标可以制定全量或者增量方式进行迁移。
5. 考虑因素
除了以上内容源数据库还有账号、视图、存储过程、函数、触发器,索引等,同样也很重要,都是需要考虑的一个因素。
6. 校验数据
这一关最后门卡,当数据迁移完成后,如何确保数据的正确迁移、没有遗漏和错误是一个很难的问题。这里的难不是实现起来困难,而是要把它自动化,达到节省人力的目标有点难,因为两者的数据类型不同,数据量偏大,写一些脚本去做检查效果不大。
数据的完整性验证是十分重要的,千万不要怕验证到错误后要花好长时候去抽取同步的操作这一步。因为一旦没有验证到错误,让数据进行了使用却乱掉了,后果将更严重。
一般场景下都是对应查询数据行数count来判断数据的是否存在问题。或则 是用create_time时间字段进行验证数据。或则抽取部分数据进行验证。还有导入过程中的log和警告 ,errors 等信息。
MySQL一些性能参数
可以在导入数据的时候预先修改一些参数,来获取最大性能的处理,比如可以把自适应hash关掉,Doublewrite关掉,然后调整缓存区,log文件的大小,把能变大的都变大,把能关的都关掉来获取最大的性能,接下来说几个常用的:
1. innodb_flush_log_at_trx_commit
· 如果innodb_flush_log_at_trx_commit设置为0,log buffer将每秒一次地写入log file中,并且log file的flush(刷到磁盘)操作同时进行。该模式下,在事务提交时,不会主动触发写入磁盘的操作。
· 如果innodb_flush_log_at_trx_commit设置为1,每次事务提交时MySQL都会把log buffer的数据写入log file,并且flush(刷到磁盘)中去。
· 如果innodb_flush_log_at_trx_commit设置为2,每次事务提交时MySQL都会把log buffer的数据写入log file。但是flush(刷到磁盘)的操作并不会同时进行。该模式下,MySQL会每秒执行一次 flush(刷到磁盘)操作。
注意:由于进程调度策略问题,这个“每秒执行一次 flush(刷到磁盘)操作”并不是保证100%的“每秒”。
2. sync_binlog
· sync_binlog 的默认值是0,像操作系统刷其它文件的机制一样,MySQL不会同步到磁盘中去,而是依赖操作系统来刷新binary log。
· 当sync_binlog =N (N>0) ,MySQL 在每写N次 二进制日志binary log时,会使用fdatasync()函数将它的写二进制日志binary log同步到磁盘中去。
注意:如果启用了AUTOCOMMIT,那么每一个语句STATEMENT就会有一次写操作;否则每个事务对应一个写操作。
3. max_allowed_packet
· 在导大容量数据特别是CLOB数据时,可能会出现异常:“Packets larger than max_allowed_packet are not allowed”。这是由于MySQL数据库有一个系统参数max_allowed_packet,其默认值为1048576(1M),可以通过如下语句在数据库中查询其值:show VARIABLES like '%max_allowed_packet%';
· 修改此参数的方法是在MySQL文件夹找到my.cnf文件,在my.cnf文件[MySQLd]中添加一行:max_allowed_packet=16777216
4. innodb_log_file_size
InnoDB日志文件太大,会影响MySQL崩溃恢复的时间,太小会增加IO负担,所以我们要调整合适的日志大小。在数据导入时先把这个值调大一点。避免无谓的buffer pool的flush操作。但也不能把innodb_log_file_size开得太大,会明显增加 InnoDB的log写入操作,而且会造成操作系统需要更多的Disk Cache开销。
5. innodb_log_buffer_size
InnoDB用于将日志文件写入磁盘时的缓冲区大小字节数。为了实现较高写入吞吐率,可增大该参数的默认值。一个大的log buffer让一个大的事务运行,不需要在事务提交前写日志到磁盘,因此,如果你有事务比如update、insert或者delete 很多的记录,让log buffer 足够大来节约磁盘I/O。
6. innodb_buffer_pool_size
这个参数主要缓存InnoDB表的索引、数据、插入数据时的缓冲。为InnoDN加速优化首要参数。一般让它等于你所有的innodb_log_buffer_size的大小就可以,innodb_log_file_size要越大越好。
7. innodb_buffer_pool_instances
InnoDB缓冲池拆分成的区域数量。对于数GB规模缓冲池的系统,通过减少不同线程读写缓冲页面的争用,将缓冲池拆分为不同实例有助于改善并发性。
分库分表方案
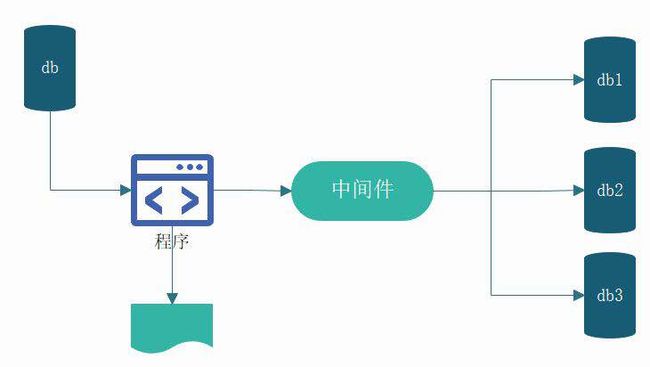
现在加难度加入分库分表需求。
这种情况建议选择传统的方式写一个迁移程序,读源数据库,通过中间件写入目标库db1,db2,db3里。
如果源数据源设计的合理完全可以用全量+增量方式实现。如下图所示:
虽然这种方式很灵活,自行控制,但也有缺点,所有业务逻辑,分库分表方案,验证都需要手动编写
下次可以在不同的平台下使用。
现在业界比较常用的分库分表的中间件有两种:
· proxy形,如:基于阿里开源的Cobar产品而研发的mycat, 需要部署另外服务器,作为分库分表的代理,对外服务,包含分库分表的配置信息,现在版本是mycat2.0。
· client形式,如当当出的sharding-jdbc,现在有京东金融进行维护,现在版本sharding-jdbc4.0开发中。是jar包,使用非常方便。我个人趋向于Sharding-JDBC,这种方式,无需额外部署,替换原有jdbc,DBA也无需改变原有的运维方式,减轻了DBA的任务。
总结
1. 一定要选择合适你的迁移工具,没有哪一个工具是最好的。
2. 数据的检验非常重要,有的时候我们迁过去很开心,校验时发生错误,这个时候必须要重来。
3. 重复地迁移是很正常的,合乎每次迁移可能需要很长时间,总会是有错误的,要做好再迁的心态。
4. 迁移过程中的日志记录非常重要,一段出现故障,可以再问题点开始继续进行迁移。
作者:崔虎龙,云和恩墨-开源架构部-MySQL技术顾问,熟悉金融、游戏、物流等数据中心运营管理的流程、规范以及自动化运维等方面。擅长MySQL,Redis,MongoDB数据库高可用设计和运维故障处理、备份恢复、升级迁移、性能优化。返回搜狐,查看更多
责任编辑: