ML:阿里云计算平台之搜索推荐演讲分享《多场景智能推荐助力业务增长》、《阿里云智能推荐应用实践:PAI-EasyRec Framework》、《新一代数仓架构漫谈》
ML:阿里云计算平台之搜索推荐演讲分享《多场景智能推荐助力业务增长》、《阿里云智能推荐应用实践:PAI-EasyRec Framework》、《新一代数仓架构漫谈》
目录
《多场景智能推荐助力业务增长》
开箱即用+推荐精准+灵活适配
实时的互动式推荐功能
新商品冷启动
物品圈选、人群圈选、流量策略
标签沉淀、人群分析、人群圈选
基于归档算法定制
召回和排序
基于原子组件定制
为趣短视频个性化推荐方案
阿里云智能推荐应用实践:PAI-EasyRec Framework
智能推荐流程及挑战
个性化推荐模型
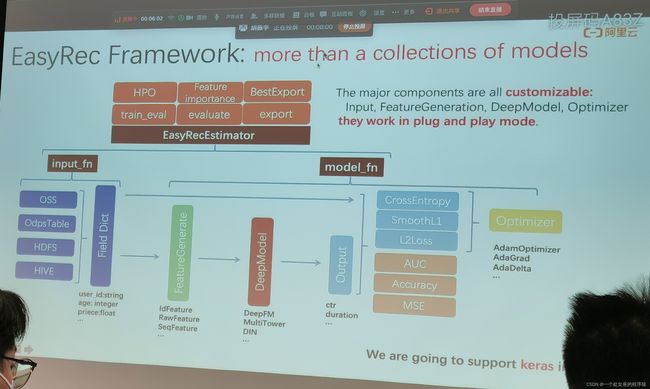
EasyRec Framework: more than a collections of models
EasyRec的优势:多平台训练,部署简单;
EasyRec的优势:丰富多样的特征
EasyRec的优势: Feature Generation(FG):一致性保证
EasyRec的优势:实现了业界领先的模型
EasyRec的优势:自动调参
EasyRec的优势:推理性能优化
EasyRec的优势:在实际场景中得到验证
新一代数仓架构漫谈
传统数据仓库数据流程
Lambda:割裂的架构,需要改变
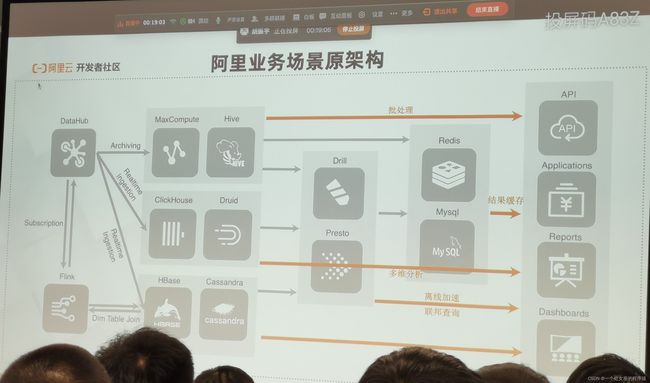
阿里业务场景原架构
下一代实时数仓如何选型
阿里搜索推荐:从N到1,Hologres简化大数据架构
云上实时数据分析技术选型
Hologres : Better OLAP + Better Serving+Cost Reduced
DataWorks数据集成:一键实时同步至Hologres
小红书:推荐业务OLAP分析
《多场景智能推荐助力业务增长》


| 搭建成本 |
人员要求高:自建推荐系统对人员要求较高,系统开发、数据处理、召回、排序模型开发及调优,均需要高级开发&算法工程师长期参与; 上线周期长:推荐系统架构复杂,为达到上线效果需要反复调优,所需开发时间多于3个月; 运维成本高:升级迭代、自建系统后期有较高的维护成本。 |
| 推荐效果 |
冷启动效果差:上线初期无历史行为数据积累的情况下,推荐系统效果较差; 效果调优困难:套用主流算法不一定有好的效果,还需考虑应用领域数据、相关性、新颖度、时效性等多维度推荐效果; 核心指标难统一:想提高CTR的同时又增加用户停留时长,无法兼顾多个核心指标。 |
| 后续维护 |
适配难度大:任何一套推荐引擎都无法完全适配企业的业务诉求,智能推荐提供了黑白盒一体化; 运营易用性:推荐系统较复杂,不具备算法知识但需要干预的运营人员上手难度大; 服务稳定性:推荐场景通常用于高流量页面,对系统性能及稳定性以及弹性要求极高; |
开箱即用+推荐精准+灵活适配
开箱即用:高度产品化、行业化;行业与阿里自研主流算法封装;覆盖全链路(支持友盟SDK行为采集);
推荐精准:行业、场景定向优化;多目标模型训练;多种模型策略;全托管:保障在线服务稳定性;灵活升降配服务;丰富的数据质量诊断功能,在线服务监控告警;
灵活适配:运营助手;产品和运营可快速干预推荐开发和算法;集成强大的离线、在线链路开发能力;

实时的互动式推荐功能
实时交互是促进消费者沉浸式浏览的必备基础功能。推荐PLUS可实时学习消费者当前兴趣表达、变化,并更新在下一次生成的推荐结果中,从而实现实时的互动式推荐功能。

推荐系统在与用户互动的过程中,有可能出现不符用户预期的推荐结果

推荐系统在与用户互动的过程中,有可能出现不符用户预期的推荐结果,而负反馈成为推荐与用户对话的重要入口。推荐PLUS支持单个商品维度、商品类目维度以及商品其他特征类维度的负反馈功能。
禁推-A
注意:针对小明,将不再推荐A-羽毛球拍商品((这一款)。
降权-B
注意:针对小明,将减少推荐B-手风琴商品(这一类)。
降权-C
注意:针对小明,将减少推荐C-高跟鞋商品(这一品牌/店铺/标签等)。
新商品冷启动
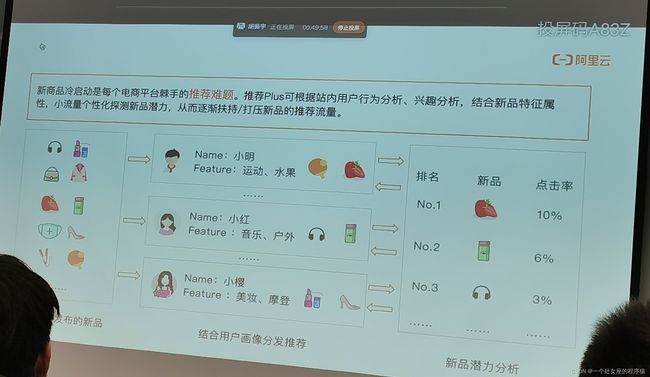
新商品冷启动是每个电商平台棘手的推荐难题。推荐Plus可根据站内用户行为分析、兴趣分析,结合新品特征属性,小流量个性化探测新品潜力,从而逐渐扶持/打压新品的推荐流量。
发布的新品→结合用户画像分发推荐→新品潜力分析
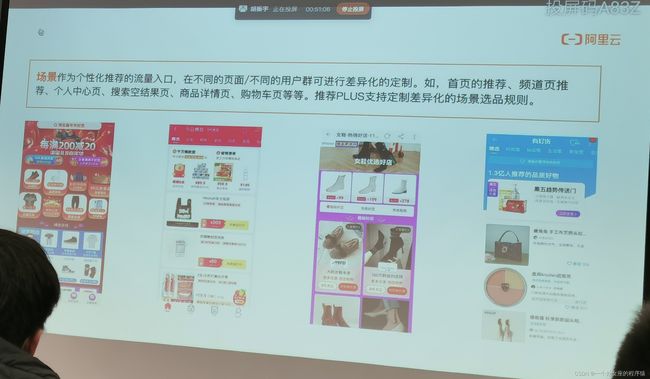
场景作为个性化推荐的流量入口,在不同的页面/不同的用户群可进行差异化的定制。如,首页的推荐、频道页推荐、个人中心页、搜索空结果页、商品详情页、购物车页等等。推荐PLUS支持定制差异化的场景选品规则。
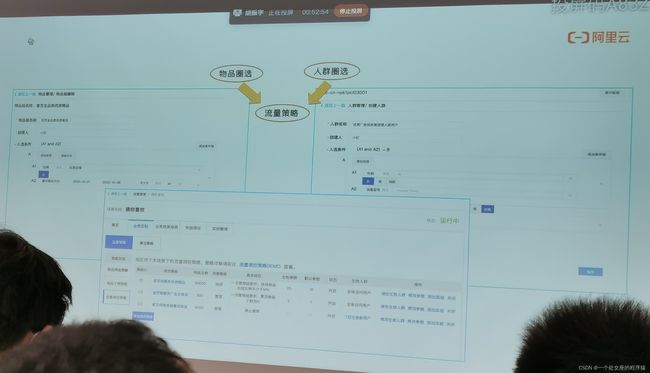
物品圈选、人群圈选、流量策略

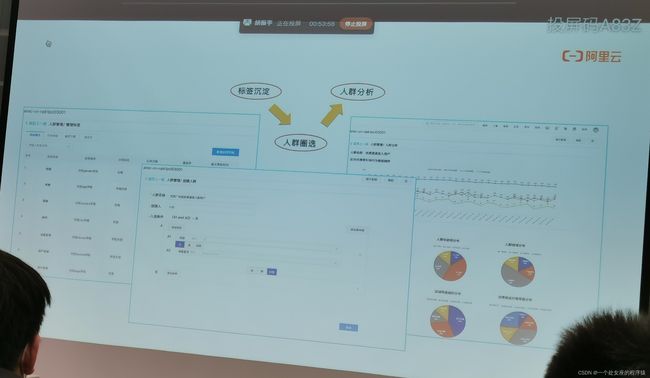
标签沉淀、人群分析、人群圈选
基于归档算法定制
定制算法策略的同时,无需关注上游的数据埋点、清洗逻辑、以及下游的在线链路拼接逻辑,仅需在控制台手动创建实验,即可对一组、多组配置进行修改,进行效果的追踪与实验的决策。

召回和排序
| 召回 |
I2I(拼接与截断、叶子类目优先级) U2X2I(截断数量,特征选举-类目、作者、频道、标签等)Hot(截断数量) New(截断数量,特征选举-类目、作者、频道、标签等) Embedding(截断数量,item2vec、tag2vec、title2vec) 新增自定义召回链路 Etrec (12i、集团内部业务应用的i2I算法) GraphSage(u2I,行业内唯一能输出GNN算法的平台,GNN是目前技术领域比较领先的框架 ALS实现user和item向量产出 |
| 排序 |
DeepFM(业内目前知名度最高的深度学习排序算法,基于论文自行实现版本) MultiTower(基于Youtube论文,PAI自行实现的一版) BST(阿里自研,用户历史行为序列建模) ESMM、MMoE(实现多目标优化的排序模型) DIN(阿里自研,目前在业内比较出名的一款产自阿里的深度学习排序算法) 基础排序模型如LR、GBDT等 |

基于原子组件定制
通离线平台结合预采用的行业内算法模型,通过拖拽的简易方式,进行上下游数据连通,节点参数配置,串通一套完整的召回/排予侯全,并生成召回表/生排序模型。

| 启用/创建实验 实验模板创建 基准/缺省实验 实验置信校验 |
定制算法配置1-n 定制召回 定制排序 定制实时行为 |
实验调试与分桶 桶号指定 实验生命周期管理 体验测试 |
实验效果分析 单实验效果报表 多实验效果报表 多元指标选择 |
实验决策 下线 推全 实验记录与溯源 |

为趣短视频个性化推荐方案
为趣是微信小程序中的长视频应用,在小程序总榜名列Top10,
·CTR提升接近3%
·人均使用时长提升11%
·在长尾视频挖掘方面得到显著提升,多曝光了2-3倍的视频
以上目标的提升带动了用户上传视频的积极性,总体提升了23%的视频上传量

阿里云智能推荐应用实践:PAI-EasyRec Framework

基于阿里云的推荐技术架构
推荐服务(在线)
训练(离线)
数据加工存储(离线)
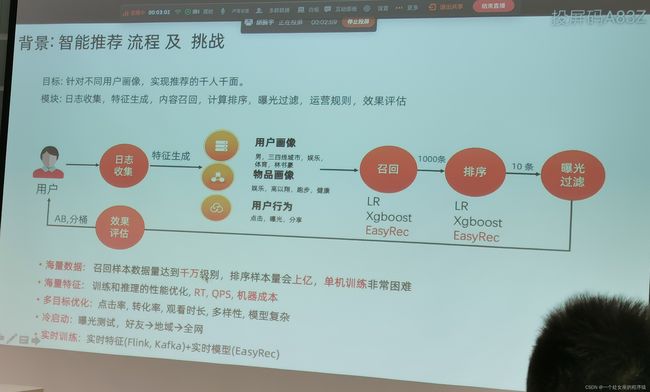
智能推荐流程及挑战
目标:针对不同用户画像,实现推荐的千人千面。
模块:日志收集,特征生成,内容召回,计算排序,曝光过滤,运营规则,效果评估
用户→日志收集→特征生成→用户画像/物品画像/用户行为→召回→排序→曝光过滤→效果评估→AB,分桶→用户
用户画像:男,三四线城市,娱乐,体育,林书豪
物品画像:娱乐,高以翔,跑步,健康
用户行为:点击,曝光,分享
·海量数据:召回样本数据量达到千万级别,排序样本量会上亿,单机训练非常困难
·海量特征:训练和推理的性能优化, RT,QPS,机器成本
·多目标优化:点击率,转化率,观看时长,多样性,模型复杂;
·冷启动:曝光测试,好友→地域→全网
·实时训练:实时特征(Flink,Kafka)+实时模型(EasyRec)

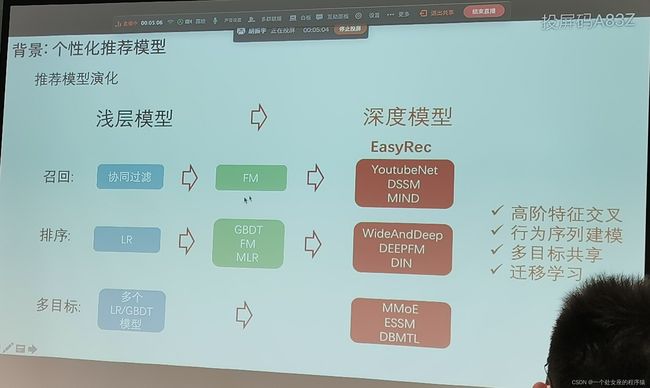
个性化推荐模型
推荐模型演化
| 浅层模型 |
深度模型 |
||
| 召回 |
协同过滤→FM |
EasyRec YoutubeNet DSSM MIND |
>> 高阶特征交叉 >> 行为序列建模 >> 多目标共享 >> 迁移学习 |
| 排序 |
LR→GBDT、FM、MLR |
WideAndDeep DEEPFM DIN |
|
| 多目标 |
多个LR/GBDT模型 |
MMoE ESSM DBMTL |
EasyRec Framework: more than a collections of models
主要组件都是可定制的:Input, FeatureGeneration, DeepModel, Optimizer,他们工作在即插即用模式。
EasyRec的优势:多平台训练,部署简单;

EasyRec的优势:丰富多样的特征
>>ldFeature:离散特征
对于推荐系统很关键,如user_id, item_id等。
>>RawFeature:连续值特征
如身高、体重、价格、历史点击率等;
也支持word2vec, cnn和bert产生的embedding,做多模态训练,短视频、新闻推荐常用。
>>TagFeature:多值特征
如标签特征:健身、音乐、旅游等,电商、短视频推荐常用。
>>ComboFeature:组合特征,如年龄+地域
>>LookupFeature:查找特征,如从user的访问列表中查询item
>>MatchFeature:双层查找特征,根据类别和item进行两次查找
>>SequenceFeature:序列特征,用户行为建模必备(DIN/BST)
基于FeatureColumn 实现,和tensorflow的接口完全兼容。
特征是提升效果的关键因素
训练、评估、导出共享一套特征处


EasyRec的优势: Feature Generation(FG):一致性保证
特征生成(FG)是最复杂的部分,容易导致线上线下不一致。为了保证一致性, EasyRec线上线下使用相同的FG代码

EasyRec的优势:实现了业界领先的模型
>>召回模型(Candidate Generation):DSSM/ FM
>>排序模型(Rank Models):
FM/ WideAndDeep / DeepFM
DeepKFM / DeepCross / Autolnt / MultiTower
DIN/ BST
>>多目标模型(MultiTask Model):
Simple MultiTask/MMoE/ ESMM / DBMTL
>>More models in development:
ListWise, ReRank模型
DeepGBM,连续值建模优化
多臂老虎机,冷启动模型
迁移学习
多目标建模、多兴趣建模

EasyRec的优势:自动调参

EasyRec的优势:推理性能优化
深度模型效果好,但是对工程能力的挑战比较大
如何保证QPS和RT? In EasyRec, we optimize tensorflow graph:

EasyRec的优势:在实际场景中得到验证

新一代数仓架构漫谈

传统数据仓库数据流程
批量数据分析流程
(1)、T+0数据接入
多种数据源接入
(2)、定时数据开发与应用
数据提取/数据转换/数据加载
ODS数据处理
DWD标准数据场景
MDM元数据
数据集市应用
(3)、核心痛点
ETL计算/存储/时间成本过高
数据处理链路过长

Lambda:割裂的架构,需要改变
数据源分为T+1和T+0数据
T+1数据→Batch View:离线数仓,数据周期性更新,面向复用。
T+0数据→Real-Time View:实时数仓,数据实时更新,面向应用。

阿里业务场景原架构
下一代实时数仓如何选型
实时写入、实时计算、实时洞察
实时离线一体化,减少数据移动
业务与技术解耦,支持自助式分析
拥抱标准,拥抱生态,拥抱云原生

阿里搜索推荐:从N到1,Hologres简化大数据架构

云上实时数据分析技术选型

Hologres : Better OLAP + Better Serving+Cost Reduced
Hologres是一款实时HSAP产品,隶属阿里自研大数据品牌MaxCompute,云原生分布式分析引擎,支持对PB级数据进行高并发、低延时的分析,支持实时数仓,大数据交互式分析等场景。

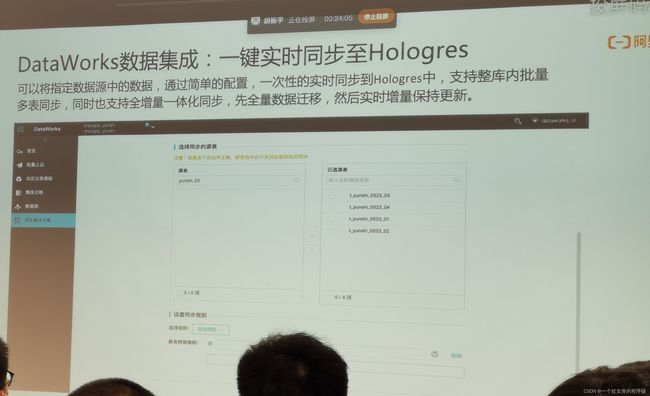
DataWorks数据集成:一键实时同步至Hologres
可以将指定数据源中的数据,通过简单的配置,一次性的实时同步到Hologres中,支持整库内批量多表同步,同时也支持全增量一体化同步,先全量数据迁移,然后实时增量保持更新。
小红书:推荐业务OLAP分析
小红书推荐业务下4种典型OLAP分析场景,按实验分组实时分析、多计算中心上线业务指标验证、灰度发包按版本实时指标对比、实时业务指标告警。
