Spring Cloud之负载均衡策略
Spring Cloud整合了ribbon作为客户端的负载均衡器,其中提供了一些负载均衡的算法,本文就了解这些负载均衡的实现:
一、负载均衡策略
负载均衡策略的顶层接口为IRule,看下其类结构:
public interface IRule{
public Server choose(Object key);
public void setLoadBalancer(ILoadBalancer lb);
public ILoadBalancer getLoadBalancer();
}choose(Object key):根据key值从负载均衡器的所有服务列表或存活的服务列表中选择一个存活的服务,这里的key值一般为服务的实例名称。
setLoadBalancer(ILoadBalancer lb):设置一个负载均衡器
getLoadBalancer():获取一个负载均衡器
接下来,我们看下IRule有哪些实现类,每种实现类都表示哪些算法,查看其类图:
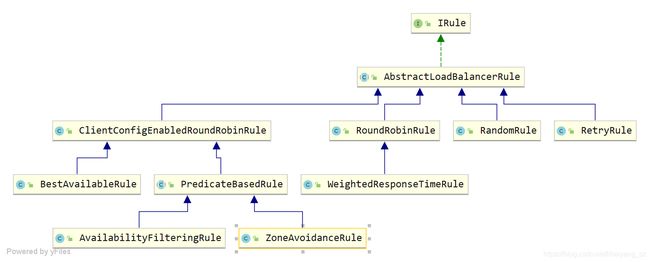
AbstractLoadBalancerRule定义了ILoadBalancer实例,通过setLoadBalancer和getLoadBalancer对负载均衡器进行存取;
RoundRobinRule
最著名和最基本的负载平衡策略,即循环规则。
查看核心算法实现的源码:
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
log.warn("no load balancer");
return null;
}
Server server = null;
int count = 0;
//若服务为空,或循环次数<10,这里为10是不怕总数过大一直循环影响性能,循环10次获取的实例都为空则直接结束
while (server == null && count++ < 10) {
List reachableServers = lb.getReachableServers();
List allServers = lb.getAllServers();
int upCount = reachableServers.size();
int serverCount = allServers.size();
//若存活的实例数量或总实例数量=0则返回空
if ((upCount == 0) || (serverCount == 0)) {
log.warn("No up servers available from load balancer: " + lb);
return null;
}
//获取实例的下标值
int nextServerIndex = incrementAndGetModulo(serverCount);
server = allServers.get(nextServerIndex);
//若是获取的服务为空,则继续循环
if (server == null) {
/* Transient. */
Thread.yield();
continue;
}
//若实例是生效的
if (server.isAlive() && (server.isReadyToServe())) {
return (server);
}
// Next.
server = null;
}
if (count >= 10) {
log.warn("No available alive servers after 10 tries from load balancer: "
+ lb);
}
return server;
}
private int incrementAndGetModulo(int modulo) {
for (;;) {
int current = nextServerCyclicCounter.get();
//当前下标值+1 与总实例数量取模,会获得小于实例数量的值
int next = (current + 1) % modulo;
//当前实例的下标值赋值为得到的下标值
if (nextServerCyclicCounter.compareAndSet(current, next))
return next;
}
} 1.从负载均衡器中获取全部的实例列表和可达的实例列表
2.本地变量维护一个原子类的nextServerCysclicCounter值,该值+1之后与全部实例列表进行取模得到的列表下标对应的服务,另外nextServerCysclicCounter值通过CAS赋值为该下标
RetryRule
考虑到级联,这个类允许向现有规则添加重试逻辑。
public RetryRule() {
}
public RetryRule(IRule subRule) {
this.subRule = (subRule != null) ? subRule : new RoundRobinRule();
}
public RetryRule(IRule subRule, long maxRetryMillis) {
this.subRule = (subRule != null) ? subRule : new RoundRobinRule();
this.maxRetryMillis = (maxRetryMillis > 0) ? maxRetryMillis : 500;
}该构造函数中可以提供一个规则(默认为RoundRobinRule)和最大重试的毫秒数(默认为500),而retryRule为其提供重试的策略
public Server choose(ILoadBalancer lb, Object key) {
long requestTime = System.currentTimeMillis();
long deadline = requestTime + maxRetryMillis;
Server answer = null;
answer = subRule.choose(key);
if (((answer == null) || (!answer.isAlive()))
&& (System.currentTimeMillis() < deadline)) {
InterruptTask task = new InterruptTask(deadline
- System.currentTimeMillis());
while (!Thread.interrupted()) {
answer = subRule.choose(key);
if (((answer == null) || (!answer.isAlive()))
&& (System.currentTimeMillis() < deadline)) {
/* pause and retry hoping it's transient */
Thread.yield();
} else {
break;
}
}
task.cancel();
}
if ((answer == null) || (!answer.isAlive())) {
return null;
} else {
return answer;
}
}很明显,如果通过设置的算法获取的服务实例为null或者不是存活的话,本算法会提供一个重试的机制,重试的时间为设置的最大重试时间内,是通过Timer进行重试的。
RandomRule
一种负荷平衡策略,在现有流量之间随机分配流量。
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
return null;
}
Server server = null;
while (server == null) {
if (Thread.interrupted()) {
return null;
}
List upList = lb.getReachableServers();
List allList = lb.getAllServers();
int serverCount = allList.size();
if (serverCount == 0) {
/*
* No servers. End regardless of pass, because subsequent passes
* only get more restrictive.
*/
return null;
}
int index = chooseRandomInt(serverCount);
server = upList.get(index);
if (server == null) {
/*
* The only time this should happen is if the server list were
* somehow trimmed. This is a transient condition. Retry after
* yielding.
*/
Thread.yield();
continue;
}
if (server.isAlive()) {
return (server);
}
// Shouldn't actually happen.. but must be transient or a bug.
server = null;
Thread.yield();
}
return server;
}
protected int chooseRandomInt(int serverCount) {
return ThreadLocalRandom.current().nextInt(serverCount);
} 这种算法比较简单,就是从全部的服务列表中进行随机抽取一个服务实例返回。
ClientConfigEnabledRoundRobinRule
该算法其实就是包含了RoundRoBinRule。该策略一般不直接使用,有些高级的策略会继承该类,完成一些高级的策略。
BestAvailableRule
一个跳过断路器,选择具有最低并发请求的服务器的规则。
本规则保存了负载均衡器中的每个节点的操作特性和统计信息。
public Server choose(Object key) {
//当loadBalancerStats为空,采用父类的线性轮询
//体现了在ClientConfigEnabledRoundRobinRule的子类无法满足高级策略时,采用
//ClientConfigEnabledRoundRobinRule的线性轮询特性
if (loadBalancerStats == null) {
return super.choose(key);
}
List serverList = getLoadBalancer().getAllServers();
int minimalConcurrentConnections = Integer.MAX_VALUE;
long currentTime = System.currentTimeMillis();
Server chosen = null;
for (Server server: serverList) {
ServerStats serverStats = loadBalancerStats.getSingleServerStat(server);
//过滤掉负载的实例
if (!serverStats.isCircuitBreakerTripped(currentTime)) {
int concurrentConnections = serverStats.getActiveRequestsCount(currentTime);
//找出请求数最小的一个
if (concurrentConnections < minimalConcurrentConnections) {
minimalConcurrentConnections = concurrentConnections;
chosen = server;
}
}
}
if (chosen == null) {
return super.choose(key);
} else {
return chosen;
}
} 这个规则对可见的服务器设置了一个限制,过滤了负载的实例,这确保它只需要在部分服务器中查找最小的并发请求,这避免了大量客户端选择一个具有最低并发请求的服务器而立即不堪重负的问题。
PredicateBasedRule
PredicateBasedRule策略继承ClientConfigEnableRoundRobinRule,该策略主要特性是“先过滤,在轮询”,也就是先过滤掉一些实例,得到过滤后的实例清单,然后轮询该实例清单,PredicateBasedRule中“过滤”功能没有实现,需要继承它的类完成,也就是说不同继承PredicateBasedRule的类有不同的“过滤特性”
AvailabilityFilteringRule
继承自PredicateBasedRule的一个负载平衡规则,过滤掉以下服务器:
连续连接或读取失败,处于断路器"tripped"状态,或有超过可配置限制的活动连接(默认是Integer.MAX_VALUE)
public Server choose(Object key) {
int count = 0;
//通过轮询选择一个server
Server server = roundRobinRule.choose(key);
//尝试10次如果都不满足要求,就放弃,采用父类的choose
//这里为啥尝试10次?
//1. 轮询结果相互影响,可能导致某个请求每次调用轮询返回的都是同一个有问题的server
//2. 集群很大时,遍历整个集群判断效率低,我们假设集群中健康的实例要比不健康的多,如果10次找不到,就用父类的choose,这也是一种快速失败机制
while (count++ <= 10) {
if (predicate.apply(new PredicateKey(server))) {
return server;
}
server = roundRobinRule.choose(key);
}
return super.choose(key);
}这里轮询采用的是RoundRobinRule,另外再看predicate是如何判断Server的呢?
public boolean apply(@Nullable PredicateKey input) {
LoadBalancerStats stats = getLBStats();
if (stats == null) {
return true;
}
//判断是否满足条件
return !shouldSkipServer(stats.getSingleServerStat(input.getServer()));
}
private boolean shouldSkipServer(ServerStats stats) {
//niws.loadbalancer.availabilityFilteringRule.filterCircuitTripped是否为true
if ((CIRCUIT_BREAKER_FILTERING.get() &&
//该Server是否为断路状态
stats.isCircuitBreakerTripped())
//本机发往这个Server未处理完的请求个数是否大于Server实例最大的活跃连接数
|| stats.getActiveRequestsCount() >= activeConnectionsLimit.get()) {
return true;
}
return false;
}断路是通过时间判断实现的。每次失败记录上次失败时间。如果失败了触发判断是否断路的最小失败次数以上的次数,则判断:
计算断路持续时间: (2^失败次数)* 断路时间因子,如果大于最大断路时间,则取最大断路时间。
判断当前时间是否大于上次失败时间+断路持续时间,如果小于,则是断路状态
这里又涉及三个配置(这里需要将default替换成你调用的微服务名称):
- niws.loadbalancer.default.connectionFailureCountThreshold,默认为3, 触发判断是否断路的最小失败次数,也就是,默认如果失败三次,就会判断是否要断路了。
- niws.loadbalancer.default.circuitTripTimeoutFactorSeconds, 默认为10, 断路时间因子,
- niws.loadbalancer.default.circuitTripMaxTimeoutSeconds,默认为30,最大断路时间
ZoneAvoidanceRule
ZoneAvoidanceRule是PredicateBasedRule的一个实现类,有一个组合的过滤条件,ZoneAvoidanceRule中的过滤条件是以ZoneAvoidancePredicate为主过滤条件和以AvailabilityPredicate为次过滤条件组成的一个叫做CompositePredicate的组合过滤条件,过滤成功之后,继续采用线性轮询的方式从过滤结果中选择一个出来。
WeightedResponseTimeRule
该策略是对RoundRobinRule的扩展,增加了根据实例的响应时间来计算权重,并从权重中选择对应的实例。该策略实现主要有三个核心内容:
定时任务serverWeightTimer:在设置LoadBalancer时初始化这个定时任务,默认每隔30s计算实例的权重
权重计算:累计所有实例的平均响应时间,得到总的totalResponseTime,然后为实例列表中的每个实例逐个计算权重,计算公式为 weightSoFar = weightSoFar + (totalResponseTime - 该实例的平均响应时间),weightSoFar 起始为零
例子
有A,B,C,D四个实例,他们的平均响应时间是10,20,40,80,计算总的响应时间10+20+40+80+100 =150
计算各个实例的权重
A: 0+(150-10)=140
B:140+(150-20)=270
C:270+(150-40)=380
D:380+(150-80)=450;
计算各个实例的权重区间
A:[0,140]
B:(140,270]
C:(270,380]
D:(380,450)
实例选择:该策略会从[0,最大权重值]之间随机抽取一个值,这个值落在哪个区间之内,就会选择哪个对应下标的实例。
二、服务实例列表如何获取?并如何动态更新?
从上面几种的负载均衡的策略可以看到,执行策略之前都需要先获取服务的实例列表,那这些实例列表是从哪里读取的呢?
List reachableServers = lb.getReachableServers();
List allServers = lb.getAllServers(); 是从lb总获取的,lb为ILoadBalancer,类关系图如下:

在ribbon中,默认的实现为ZoneAwareLoadBalancer:
@Bean
@ConditionalOnMissingBean
public ILoadBalancer ribbonLoadBalancer(IClientConfig config,
ServerList serverList, ServerListFilter serverListFilter,
IRule rule, IPing ping, ServerListUpdater serverListUpdater) {
if (this.propertiesFactory.isSet(ILoadBalancer.class, name)) {
return this.propertiesFactory.get(ILoadBalancer.class, config, name);
}
return new ZoneAwareLoadBalancer<>(config, rule, ping, serverList,
serverListFilter, serverListUpdater);
} 在初始化ZoneAwareLoadBalancer时初始化实例列表,ServerListUpdater会启动一个scheduled定时任务,默认每隔30s获取一次服务列表,以ConfigurationBasedServerList为例,从配置文件读取相关属性并以逗号进行分割获取实例列表:
public List getUpdatedListOfServers() {
String listOfServers = clientConfig.get(CommonClientConfigKey.ListOfServers);
return derive(listOfServers);
}
protected List derive(String value) {
List list = Lists.newArrayList();
if (!Strings.isNullOrEmpty(value)) {
for (String s: value.split(",")) {
list.add(new Server(s.trim()));
}
}
return list;
} 若是从eureka中获取服务列表,可以查看DiscoveryEnabledNIWSServerList的实现。。。