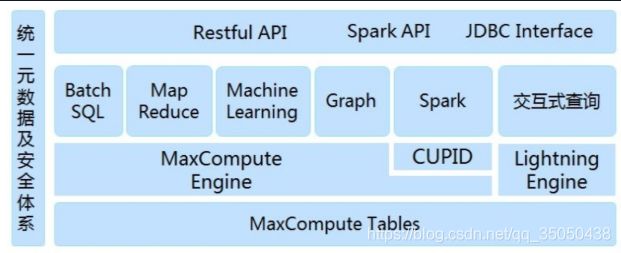
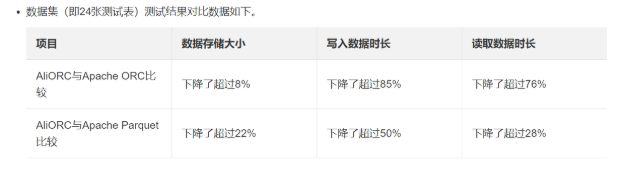
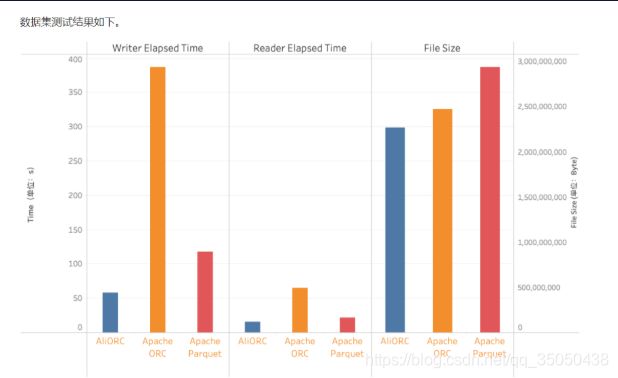
- 网盘搜索器 VIP 版:资源搜索与下载的高效利器
2501_90827335
电脑软件工程开源软件
在信息爆炸的时代,从网盘获取各类资源已经成为很多人的日常操作。今天要给大家介绍一款功能强大的工具——网盘搜索器VIP版,它为我们在海量的网盘资源中精准定位所需内容提供了极大便利。强大的核心功能多平台资源整合网盘搜索器VIP版堪称资源整合的“超级大师”。它打破了不同网盘之间的壁垒,支持阿里云盘、百度网盘、迅雷云盘等主流网盘资源的跨平台搜索。无论是热门影视、专业文档、实用软件,还是动听音乐,都能一网打
- 股神系列:蒋菲的量化投资中,如何利用大数据优化模型?她的数据来源有哪些?
云策量化
量化交易量化软件量化炒股量化炒股QMT量化交易入门教程PTrade股票投资deepseek
推荐阅读:《程序化炒股:如何申请官方交易接口权限?个人账户可以申请吗?》标题:股神系列:蒋菲的量化投资中,如何利用大数据优化模型?她的数据来源有哪些?正文:在金融投资的世界里,量化投资以其科学、系统和客观的特点,成为了众多投资者追求的“圣杯”。而在量化投资领域,蒋菲以其独特的大数据量化投资模型而闻名。本文将深入探讨蒋菲如何利用大数据优化其量化投资模型,以及她的数据来源有哪些。一、量化投资模型的优化
- 2024年第五届MathorCup数学应用挑战赛--大数据竞赛思路、代码更新中.....
宇哥预测优化代码学习
1024程序员节
欢迎来到本博客❤️❤️博主优势:博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。⛳️座右铭:行百里者,半于九十。本文目录如下:目录⛳️研赛及概况一、竞赛背景与目的二、组织机构与参赛对象三、竞赛时间与流程四、竞赛要求与规则五、奖项设置与奖励六、研究文档撰写建议七、参考资料与资源1找程序网站推荐2公式编辑器、流程图、论文排版324年研赛资源下载4思路、Python、Matlab代码分享......⛳
- AI人工智能软件开发方案:开启智能时代的创新钥匙
广州硅基技术官方
人工智能
一、引言:AI浪潮下的软件开发新机遇近年来,人工智能(AI)技术的迅猛发展如同一股汹涌澎湃的浪潮,席卷了全球各个领域。从最初的概念提出到如今的广泛应用,AI历经了漫长的发展历程,终于迎来了属于它的黄金时代。回首过去,AI的发展并非一帆风顺,早期由于计算能力和算法的限制,经历了多次起伏。但随着大数据、云计算、机器学习、深度学习等技术的不断突破,AI迎来了爆发式增长。如今,AI已经深入到人们生活和工作
- 阿里云在使用 Docker 过程中踩过的坑
weixin_34293059
运维
昨天下午朋友在微信上丢给我一条新闻,看看,我们阿里云支持Docker企业版了。我打开一看,果然,阿里云发布了飞天敏捷版,开始支持企业级的Docker容器。美国中部时间4月19日,阿里云在容器技术大会DockerCon2017上正式推出了ApsaraStackAgility,也就是飞天的敏捷版。Docker公司首席执行官BenGolub在大会上宣布了ApsaraStackAgility的正式发布,这
- Angular中`trackBy`函数的独特性与性能优化
t0_54program
编程问题解决手册angular.js前端javascript个人开发
在Angular项目中,优化性能是每一个开发者都需要考虑的问题。特别是在处理大数据量或动态变化的列表时,Angular的trackBy函数成为了我们手中的利器。然而,当我们面对多个列表使用相同trackBy函数时,可能会产生一些疑问:如果这些列表中的项有相同的ID,是否会影响Angular的变更检测?本文将详细探讨trackBy函数在这种情境下的表现及其带来的性能优化。trackBy函数简介tra
- 石油储运生产 2D 可视化,组态应用赋能工业智慧发展
智慧园区
智慧城市bigdata人工智能大数据物联网网络
当前,国际油价低位徘徊导致各国石油化工行业投资大幅缩减,石油化工建设行业竞争环境日趋严峻,施工企业的利润空间也被不断压缩。内外交困的环境下,促使企业采取更有效的管理手段来提高效率和降低成本。石油工业大数据具有无限潜力与价值,将大数据与数据挖掘技术应用其中,不仅可以提升石油行业工业化水平,而且对其智慧化发展起到强有力的推动作用。图扑软件-构建先进2D和3D可视化所需要的一切图扑软件采用自主研发的HT
- 人民日报报道,华为云赋能智能制造助力图扑软件构造数字孪生场景
智慧园区
华为人工智能物联网
2021年12月22日,《人民日报》头版头条刊登了《华为云赋能智能制造,助力图扑软件构造数字孪生场景》一文,聚焦数据可视化建设发展。报道指出,数字经济发展的背后,是大数据时趋势下各地区积极贯彻国家数字经济发展战略的时代精神;高效便捷管控的背后,是云端平台各大企业的互助共赢;高质精准2D、3D数据可视图的背后,是专注于数据可视化Web组态开发的厦门图扑软件科技有限公司。并对厦门图扑软件科技有限公司进
- 华为云赋能智能制造,助力图扑软件构造数字孪生场景
36Kr网
科技华为云制造bigdata
出行手机查看交通方案、物业管理的智能可视勘察管控、疫情地图提前预知危害……这些曾经存在于科幻片中的高科技场景一一在现代生活得到了应用与普及,其背后的数据可视化应用,正贯穿于当今大数据时代的各行各业,成为人们洞察数据内涵的有力工具,推动数字经济发展驶入“快车道”。数字经济发展的背后,是大数据时趋势下各地区积极贯彻国家数字经济发展战略的时代精神;高效便捷管控的背后,是云端平台各大企业的互助共赢;高质精
- Python基于深度学习的动物图片识别技术的研究与实现
Java老徐
Python毕业设计python深度学习开发语言深度学习的动物图片识别技术Python动物图片识别技术
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w+、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌文末获取源码联系精彩专栏推荐订阅不然下次找不到哟2022-2024年最全的计算机软件毕业设计选题大全:1000个热门选题推荐✅Java项目精品实战案例《100套》Java微信小程序项目实战《100套》感兴趣的可以先收藏起来,还有大家
- 【Spark】查询优化中分区(Partitioning)和分桶(Bucketing)是什么关系?什么时候应当分区,什么时候应当分桶?
petrel2015
spark大数据分布式数据库
在学习Spark的过程中,分区和分桶乍一看很像,都能为了计算加速,但是仔细一想,一查还是有些差异的,甚至说差异很大。那么具体有什么差异点,有什么相同点。我做出了如下的整理,供大家参考,欢迎指正。相同点分区(Partitioning)和分桶(Bucketing)在很多方面具有相似性,它们都是用于优化大数据查询性能的技术数据划分的目的:优化查询性能分区和分桶的核心目标是通过将数据分割成更小的逻辑单元来
- 国内 npm 镜像源推荐
PyAIGCMaster
我的学习笔记npm前端node.js
国内npm镜像源推荐除了常用的淘宝镜像(https://registry.npmmirror.com),还有以下国内npm镜像源可供选择:1.CNPM(阿里云)地址:https://r.cnpmjs.org/特点:由cnpm提供,支持同步npm官方仓库。提供更快的下载速度和稳定性。使用方法:npmconfigsetregistryhttps://r.cnpmjs.org/2.京东镜像(JFrogA
- 基于 MySQL 和 Spring Boot 的在线论坛管理系统设计与实现
城南|阿洋-计算机从小白到大神
mysqlspringboot数据库
markdownCopy✌全网粉丝20W+,csdn特邀作者、博客专家、CSDN[新星计划]导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java、pyhton、机器学习技术领域和毕业项目实战✌哈喽兄弟们,好久不见哦~最近整理了一下之前写过的一些小项目/毕业设计。发现还是有很多存货的,想一想既然放在电脑里面也吃灰,那么还不如分享出去,没准还可以帮助到
- 【最低2万搞定!】10万双枪充电桩平台神级配置:服务器成本直降80%+日志/数据库存储全拆解!慧知开源充电桩平台!!!必看攻略
文慧的科技江湖
更新日志-(慧哥)慧知充电桩平台服务器数据库开源直流充电桩充电桩springcloud架构
10万台充电桩设备双枪,需要最小的服务器配置?服务器费用控制2-3万,服务器日志产生多少g,数据库订单数据产生多少g!-慧知开源充电桩平台一、服务器配置方案及逻辑(阿里云)1.需求分析设备规模:10万台双枪充电桩,理论最大并发连接数为20万(每个枪独立通信)。请求类型:心跳包(高频)、充电启停、支付、状态上报等,假设平均每秒请求量约5,000QPS。费用目标:总成本控制在2-3万元/月(按包年包月
- OCR识别常见开源库
yxfamyself
计算机视觉opencv
OCR(OpticalCharacterRecognition,光学字符识别)技术是一种将印刷体或手写文字转化为可编辑文本的技术。亦即将图像中的文字进行识别,并以文本的形式返回。做OCR有很多库可以使用。免费开源库有:Tesseract,PaddleOCR。商业付费OCR有:腾讯云OCR,阿里云OCR。下面分别介绍。准确识别的前提是找到正确的字体进行训练,字体很重要,要覆盖所有识别的场景。Tess
- 大数据技术实战---项目中遇到的问题及项目经验
一个“不专业”的阿凡
大数据
问题导读:1、项目中遇到过哪些问题?2、Kafka消息数据积压,Kafka消费能力不足怎么处理?3、Sqoop数据导出一致性问题?4、整体项目框架如何设计?项目中遇到过哪些问题7.1Hadoop宕机(1)如果MR造成系统宕机。此时要控制Yarn同时运行的任务数,和每个任务申请的最大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存
- springBoot 和springCloud 版本对应关系
m0_74824894
面试学习路线阿里巴巴springbootspringcloud后端
请求下面链接:拿到的json数据,格式化https://start.spring.io/actuator/info[这里是图片001]https://start.spring.io/actuator/info云原生脚手架CloudNativeAppInitializer(aliyun.com)[这里是图片002]https://start.aliyun.com/idea阿里云脚手架插件:Aliba
- Apache大数据旭哥优选大数据选题
Apache大数据旭
大数据定制选题javahadoopspark开发语言ideahive数据库架构
定制旭哥服务,一对一,无中介包安装+答疑+售后态度和技术都很重要定制按需求做要求不高就实惠一点定制需提前沟通好怎么做,这样才能避免不必要的麻烦python、flask、Django、mapreduce、mysqljava、springboot、vue、echarts、hadoop、spark、hive、hbase、flink、SparkStreaming、kafka、flume、sqoop分析+推
- Java后端开发技术详解
小二爱编程·
java开发语言
Java作为一门成熟的编程语言,已广泛应用于后端开发领域。其强大的生态系统和广泛的支持库使得Java成为许多企业和开发者的首选后端开发语言。随着云计算、微服务架构和大数据技术的兴起,Java后端开发的技术栈也不断演进。本文将详细介绍Java后端开发的核心技术,包括Java基础、常见框架、数据库操作、缓存技术、异步编程等。1.Java基础:理解面向对象的编程Java是一种面向对象的编程语言,面向对象
- IDC权威认证!永洪科技入选 IDC「GBI图谱」,点亮生成式 BI 价值灯塔
永洪科技
科技人工智能BI大数据数据分析
大数据市场正在稳步前进,生成式AI已成为厂商服务的重点方向,其发展离不开数据底座建设和数据工程管理,反过来AI也会帮助开发运维人员、业务人员和管理层更好地使用、查询数据。IDC调研数据显示,在生成式AI的驱动下,未来5年企业在数据管理和数据分析基础设施建设的投资增长率将分别达到8.7%和9.2%。近日,国际咨询机构IDC发布了《中国数据智能市场生态图谱V5.0》,在这一领域,永洪科技以其创新前沿的
- 打造金融数据新引擎,看永洪科技助力头部农信社搭建一站式分析平台
永洪科技
金融数据可视化BI数据分析大数据
在数字化转型的浪潮中,金融行业作为经济发展的核心引擎,正加速探索数字化、智能化的新路径。永洪科技,近日成功助力某省农村信用社联合社(简称:Z企业)完成了其数字化转型的重要一步,通过部署先进的商业智能解决方案,为Z企业的业务升级与效能提升注入了强劲动力。随着智能金融时代的来临,以大数据、人工智能、移动互联等新兴技术为核心的金融科技持续赋能银行金融业务数字化、智能化、开放化的发展,为金融机构营销体系的
- 读书笔记五 ---大数据之路--数仓分层
qq_38215991
bigdata大数据
数据分层在流式数据模型中,数据模型整体上分为五层。ODS层跟离线系统的定义一样,ODS层属于操作数据层,是直接从业务系统采集过来的最原始数据(进行了数据清洗),包含了所有业务的变更过程,数据粒度也是最细的。在这一层,实时和离线在源头上是统一的,这样的好处是用同一份数据加工出来的指标,口径基本是统一的,可以更方便进行实时和离线问数据比对。例如:原始的订单变更记录数据、服务器引擎的访同日志。(原始数据
- 阿里云+华为云双活架构:头部企业的云端生存法则
云上的阿七
阿里云华为云架构
如何在云端构建高可用、高可靠的业务架构,依然是企业IT决策者面临的挑战。面对单一云厂商可能带来的故障风险,越来越多的头部企业开始采用“阿里云+华为云”双活架构,以提升业务连续性,实现跨云容灾,打造更稳健的云端生存法则。什么是双活架构?双活架构(Active-ActiveArchitecture)指的是企业在两个云平台(如阿里云和华为云)上同时运行核心业务,实现数据同步和业务负载均衡。一旦某一云平台
- python pip及常用国内镜像源
sunny05296
pythonpythonpip开发语言
pip常用国内镜像源pip默认从国外的python下载会很慢,建议使用一些国内的镜像源,常用的国内镜像源如下:#清华镜像源https://pypi.tuna.tsinghua.edu.cn/simple#中科大镜像源https://pypi.mirrors.ustc.edu.cn/simple#阿里云镜像源https://mirrors.aliyun.com/pypi/simplepip安装组件时
- 使用LangGraph迁移MapReduceDocumentsChain进行长文档的摘要
dgay_hua
python
在大数据处理和文本分析领域,MapReduce是一种非常重要的策略,用于处理和分析大型数据集。具体到文本处理方面,MapReduceDocumentsChain구현了一种map-reduce策略,可以有效地处理长文本。本文将介绍如何从MapReduceDocumentsChain迁移到LangGraph,并探讨LangGraph在流处理、检查点恢复等方面的优势。技术背景介绍MapReduceDoc
- Deepseek API 调用
哦豁灬
LLM深度学习生产工具deepseekLLMAPI大模型
1获取APIKey目前比较知名的提供了DeepSeek的推理服务商包括硅基流动、阿里云、腾讯云等等。这些推理服务商一般是提供API接口,需要安装大模型客户端并配置API。获取API密钥,以硅基流动为例:前往硅基流动官方网站(https://cloud.siliconflow.cn)注册账号。在账户管理的API密钥中点击新建API密钥并复制。安装一个本地的第三方大模型客户并配置,常见的包括Chatb
- Python用Bokeh处理大规模数据可视化的最佳实践
一键难忘
Bokehpython开发语言
用Bokeh处理大规模数据可视化的最佳实践在大规模数据处理和分析中,数据可视化是一个至关重要的环节。Bokeh是一个在Python生态中广泛使用的交互式数据可视化库,它具有强大的可扩展性和灵活性。本文将介绍如何使用Bokeh处理大规模数据可视化,并提供一些最佳实践和代码实例,帮助你高效地展示大数据集中的重要信息。1.为什么选择Bokeh?Bokeh是一个专为浏览器呈现而设计的可视化库,它支持高效渲
- 分页优化之——游标分页
PhilipJ0303
Java面试java数据库优化游标分页分页查询
游标分页(Cursor-basedPagination)是一种高效的分页方式,特别适用于大数据集和无限滚动的场景。与传统的基于页码的分页(如page=1&size=10)不同,游标分页通过一个唯一的游标(通常是时间戳或唯一ID)来标记分页的位置,避免了传统分页在数据变动时的重复或遗漏问题。以下是游标分页在前后端的实现方式:1.游标分页的核心概念游标(Cursor):游标是一个唯一标识符,通常是数据
- 轻松入门Apache SeaTunnel:数据集成利器
窝窝和牛牛
SeaTunnelETL数据集成
文章目录轻松入门ApacheSeaTunnel:数据集成利器什么是SeaTunnel基本原理运行流程SeaTunnelvsDataX:两大数据集成工具对比实战场景:MySQL数据同步至ElasticsearchSeaTunnel实现方案DataX实现方案实现原理对比底层依赖环境方案优缺点分析快速上手环境准备简单示例总结轻松入门ApacheSeaTunnel:数据集成利器什么是SeaTunnelAp
- 记录:(error) NOAUTH Authentication required...【解决方案】
bug菌¹
全栈Bug调优(实战版)#CSDN问答解惑(全栈版)redis连接报错Authentication
作者:bug菌✏️博客:CSDN、掘金等公众号:猿圈奇妙屋特别声明:原创不易,转载请附上原文出处链接和本文声明,谢谢配合。版权声明:文章里可能部分文字或者图片来源于互联网或者百度百科,如有侵权请联系bug菌处理。一、前言环境版本:centos7.6+redis6.2.6+xshell5二、排错通过xshell5远程连接阿里云服务器,内核是cent
- Enum用法
不懂事的小屁孩
enum
以前的时候知道enum,但是真心不怎么用,在实际开发中,经常会用到以下代码:
protected final static String XJ = "XJ";
protected final static String YHK = "YHK";
protected final static String PQ = "PQ";
- 【Spark九十七】RDD API之aggregateByKey
bit1129
spark
1. aggregateByKey的运行机制
/**
* Aggregate the values of each key, using given combine functions and a neutral "zero value".
* This function can return a different result type
- hive创建表是报错: Specified key was too long; max key length is 767 bytes
daizj
hive
今天在hive客户端创建表时报错,具体操作如下
hive> create table test2(id string);
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:javax.jdo.JDODataSto
- Map 与 JavaBean之间的转换
周凡杨
java自省转换反射
最近项目里需要一个工具类,它的功能是传入一个Map后可以返回一个JavaBean对象。很喜欢写这样的Java服务,首先我想到的是要通过Java 的反射去实现匿名类的方法调用,这样才可以把Map里的值set 到JavaBean里。其实这里用Java的自省会更方便,下面两个方法就是一个通过反射,一个通过自省来实现本功能。
1:JavaBean类
1 &nb
- java连接ftp下载
g21121
java
有的时候需要用到java连接ftp服务器下载,上传一些操作,下面写了一个小例子。
/** ftp服务器地址 */
private String ftpHost;
/** ftp服务器用户名 */
private String ftpName;
/** ftp服务器密码 */
private String ftpPass;
/** ftp根目录 */
private String f
- web报表工具FineReport使用中遇到的常见报错及解决办法(二)
老A不折腾
finereportweb报表java报表总结
抛砖引玉,希望大家能把自己整理的问题及解决方法晾出来,Mark一下,利人利己。
出现问题先搜一下文档上有没有,再看看度娘有没有,再看看论坛有没有。有报错要看日志。下面简单罗列下常见的问题,大多文档上都有提到的。
1、没有返回数据集:
在存储过程中的操作语句之前加上set nocount on 或者在数据集exec调用存储过程的前面加上这句。当S
- linux 系统cpu 内存等信息查看
墙头上一根草
cpu内存liunx
1 查看CPU
1.1 查看CPU个数
# cat /proc/cpuinfo | grep "physical id" | uniq | wc -l
2
**uniq命令:删除重复行;wc –l命令:统计行数**
1.2 查看CPU核数
# cat /proc/cpuinfo | grep "cpu cores" | u
- Spring中的AOP
aijuans
springAOP
Spring中的AOP
Written by Tony Jiang @ 2012-1-18 (转)何为AOP
AOP,面向切面编程。
在不改动代码的前提下,灵活的在现有代码的执行顺序前后,添加进新规机能。
来一个简单的Sample:
目标类:
[java]
view plain
copy
print
?
package&nb
- placeholder(HTML 5) IE 兼容插件
alxw4616
JavaScriptjquery jQuery插件
placeholder 这个属性被越来越频繁的使用.
但为做HTML 5 特性IE没能实现这东西.
以下的jQuery插件就是用来在IE上实现该属性的.
/**
* [placeholder(HTML 5) IE 实现.IE9以下通过测试.]
* v 1.0 by oTwo 2014年7月31日 11:45:29
*/
$.fn.placeholder = function
- Object类,值域,泛型等总结(适合有基础的人看)
百合不是茶
泛型的继承和通配符变量的值域Object类转换
java的作用域在编程的时候经常会遇到,而我经常会搞不清楚这个
问题,所以在家的这几天回忆一下过去不知道的每个小知识点
变量的值域;
package 基础;
/**
* 作用域的范围
*
* @author Administrator
*
*/
public class zuoyongyu {
public static vo
- JDK1.5 Condition接口
bijian1013
javathreadConditionjava多线程
Condition 将 Object 监视器方法(wait、notify和 notifyAll)分解成截然不同的对象,以便通过将这些对象与任意 Lock 实现组合使用,为每个对象提供多个等待 set (wait-set)。其中,Lock 替代了 synchronized 方法和语句的使用,Condition 替代了 Object 监视器方法的使用。
条件(也称为条件队列或条件变量)为线程提供了一
- 开源中国OSC源创会记录
bijian1013
hadoopsparkMemSQL
一.Strata+Hadoop World(SHW)大会
是全世界最大的大数据大会之一。SHW大会为各种技术提供了深度交流的机会,还会看到最领先的大数据技术、最广泛的应用场景、最有趣的用例教学以及最全面的大数据行业和趋势探讨。
二.Hadoop
&nbs
- 【Java范型七】范型消除
bit1129
java
范型是Java1.5引入的语言特性,它是编译时的一个语法现象,也就是说,对于一个类,不管是范型类还是非范型类,编译得到的字节码是一样的,差别仅在于通过范型这种语法来进行编译时的类型检查,在运行时是没有范型或者类型参数这个说法的。
范型跟反射刚好相反,反射是一种运行时行为,所以编译时不能访问的变量或者方法(比如private),在运行时通过反射是可以访问的,也就是说,可见性也是一种编译时的行为,在
- 【Spark九十四】spark-sql工具的使用
bit1129
spark
spark-sql是Spark bin目录下的一个可执行脚本,它的目的是通过这个脚本执行Hive的命令,即原来通过
hive>输入的指令可以通过spark-sql>输入的指令来完成。
spark-sql可以使用内置的Hive metadata-store,也可以使用已经独立安装的Hive的metadata store
关于Hive build into Spark
- js做的各种倒计时
ronin47
js 倒计时
第一种:精确到秒的javascript倒计时代码
HTML代码:
<form name="form1">
<div align="center" align="middle"
- java-37.有n 个长为m+1 的字符串,如果某个字符串的最后m 个字符与某个字符串的前m 个字符匹配,则两个字符串可以联接
bylijinnan
java
public class MaxCatenate {
/*
* Q.37 有n 个长为m+1 的字符串,如果某个字符串的最后m 个字符与某个字符串的前m 个字符匹配,则两个字符串可以联接,
* 问这n 个字符串最多可以连成一个多长的字符串,如果出现循环,则返回错误。
*/
public static void main(String[] args){
- mongoDB安装
开窍的石头
mongodb安装 基本操作
mongoDB的安装
1:mongoDB下载 https://www.mongodb.org/downloads
2:下载mongoDB下载后解压
- [开源项目]引擎的关键意义
comsci
开源项目
一个系统,最核心的东西就是引擎。。。。。
而要设计和制造出引擎,最关键的是要坚持。。。。。。
现在最先进的引擎技术,也是从莱特兄弟那里出现的,但是中间一直没有断过研发的
- 软件度量的一些方法
cuiyadll
方法
软件度量的一些方法http://cuiyingfeng.blog.51cto.com/43841/6775/在前面我们已介绍了组成软件度量的几个方面。在这里我们将先给出关于这几个方面的一个纲要介绍。在后面我们还会作进一步具体的阐述。当我们不从高层次的概念级来看软件度量及其目标的时候,我们很容易把这些活动看成是不同而且毫不相干的。我们现在希望表明他们是怎样恰如其分地嵌入我们的框架的。也就是我们度量的
- XSD中的targetNameSpace解释
darrenzhu
xmlnamespacexsdtargetnamespace
参考链接:
http://blog.csdn.net/colin1014/article/details/357694
xsd文件中定义了一个targetNameSpace后,其内部定义的元素,属性,类型等都属于该targetNameSpace,其自身或外部xsd文件使用这些元素,属性等都必须从定义的targetNameSpace中找:
例如:以下xsd文件,就出现了该错误,即便是在一
- 什么是RAID0、RAID1、RAID0+1、RAID5,等磁盘阵列模式?
dcj3sjt126com
raid
RAID 1又称为Mirror或Mirroring,它的宗旨是最大限度的保证用户数据的可用性和可修复性。 RAID 1的操作方式是把用户写入硬盘的数据百分之百地自动复制到另外一个硬盘上。由于对存储的数据进行百分之百的备份,在所有RAID级别中,RAID 1提供最高的数据安全保障。同样,由于数据的百分之百备份,备份数据占了总存储空间的一半,因而,Mirror的磁盘空间利用率低,存储成本高。
Mir
- yii2 restful web服务快速入门
dcj3sjt126com
PHPyii2
快速入门
Yii 提供了一整套用来简化实现 RESTful 风格的 Web Service 服务的 API。 特别是,Yii 支持以下关于 RESTful 风格的 API:
支持 Active Record 类的通用API的快速原型
涉及的响应格式(在默认情况下支持 JSON 和 XML)
支持可选输出字段的定制对象序列化
适当的格式的数据采集和验证错误
- MongoDB查询(3)——内嵌文档查询(七)
eksliang
MongoDB查询内嵌文档MongoDB查询内嵌数组
MongoDB查询内嵌文档
转载请出自出处:http://eksliang.iteye.com/blog/2177301 一、概述
有两种方法可以查询内嵌文档:查询整个文档;针对键值对进行查询。这两种方式是不同的,下面我通过例子进行分别说明。
二、查询整个文档
例如:有如下文档
db.emp.insert({
&qu
- android4.4从系统图库无法加载图片的问题
gundumw100
android
典型的使用场景就是要设置一个头像,头像需要从系统图库或者拍照获得,在android4.4之前,我用的代码没问题,但是今天使用android4.4的时候突然发现不灵了。baidu了一圈,终于解决了。
下面是解决方案:
private String[] items = new String[] { "图库","拍照" };
/* 头像名称 */
- 网页特效大全 jQuery等
ini
JavaScriptjquerycsshtml5ini
HTML5和CSS3知识和特效
asp.net ajax jquery实例
分享一个下雪的特效
jQuery倾斜的动画导航菜单
选美大赛示例 你会选谁
jQuery实现HTML5时钟
功能强大的滚动播放插件JQ-Slide
万圣节快乐!!!
向上弹出菜单jQuery插件
htm5视差动画
jquery将列表倒转顺序
推荐一个jQuery分页插件
jquery animate
- swift objc_setAssociatedObject block(version1.2 xcode6.4)
啸笑天
version
import UIKit
class LSObjectWrapper: NSObject {
let value: ((barButton: UIButton?) -> Void)?
init(value: (barButton: UIButton?) -> Void) {
self.value = value
- Aegis 默认的 Xfire 绑定方式,将 XML 映射为 POJO
MagicMa_007
javaPOJOxmlAegisxfire
Aegis 是一个默认的 Xfire 绑定方式,它将 XML 映射为 POJO, 支持代码先行的开发.你开发服 务类与 POJO,它为你生成 XML schema/wsdl
XML 和 注解映射概览
默认情况下,你的 POJO 类被是基于他们的名字与命名空间被序列化。如果
- js get max value in (json) Array
qiaolevip
每天进步一点点学习永无止境max纵观千象
// Max value in Array
var arr = [1,2,3,5,3,2];Math.max.apply(null, arr); // 5
// Max value in Jaon Array
var arr = [{"x":"8/11/2009","y":0.026572007},{"x"
- XMLhttpRequest 请求 XML,JSON ,POJO 数据
Luob.
POJOjsonAjaxxmlXMLhttpREquest
在使用XMlhttpRequest对象发送请求和响应之前,必须首先使用javaScript对象创建一个XMLHttpRquest对象。
var xmlhttp;
function getXMLHttpRequest(){
if(window.ActiveXObject){
xmlhttp:new ActiveXObject("Microsoft.XMLHTTP
- jquery
wuai
jquery
以下防止文档在完全加载之前运行Jquery代码,否则会出现试图隐藏一个不存在的元素、获得未完全加载的图像的大小 等等
$(document).ready(function(){
jquery代码;
});
<script type="text/javascript" src="c:/scripts/jquery-1.4.2.min.js&quo