深入代码优化 (三) 数据结构布局优化
存储器简介
1980 年之前,cpu 访问内存和访问寄存器的速度是差不多的,但自 1980 年以来,cpu 和内存的性能差距一直在扩大,1980 年 -- 2000 年,cpu 的性能提升了 600 倍,而内存的访问时间只提升了 6 倍。在 cpu 从内存中读取数据的这段时间内,cpu 都是处于无事可做的等待状态。所以缓存 cache 的出现,在很大程度上能够弥补 cpu 和内存速度之间的巨大鸿沟。在高性能系统中,缓存命中率是决定性能好坏的重要因素。
存储器包含了磁盘,硬盘,内存,缓存,寄存器等能存储数据的设备。存储器的整体思想是,对于每个 k,位于 k 层的更快更小的存储设备,作为位于 k+1 层的更大更慢的存储设备的缓存。实际上,L1, L2, L3 分别缓存下一级存储单元的数据,而寄存器可能会缓存着 L1 cache 中的数据。要去访问内存中的数据时,首先会在寄存器中查找,寄存器中找不到再到 L1 cache 中查找,L1 cache 中找不到再到 L2 cache 中查找,L2 cache 中找不到再到 L3 cache 中查找,L3 中也找不到,最后才会到内存中去读取。
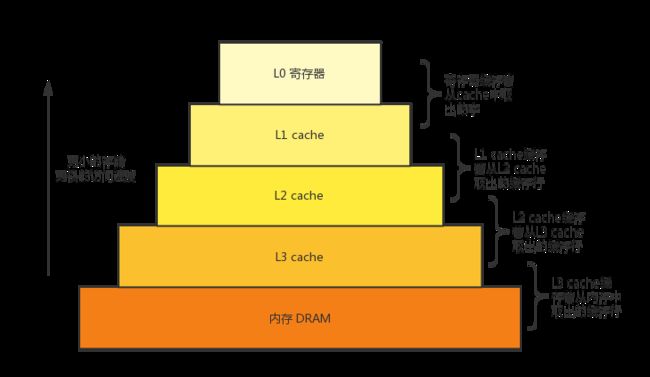 存储器中的数据总是以块大小为传送单元在第 k 层和第 k + 1 层之间来回拷贝的。L1 和寄存器之间的传送块大小为 1 个字,1 个字在 32 位系统上是 4 字节,在 64 位系统上是 8 字节。而 L2 和 L1 之间,以及 L3 和 L2 之间,传送的通常是 8 个字的块,通常称为一个 cache line,64 位系统上是 64 字节。而内存与 L3 之间的传送大小通常是几百或几千字节的块。层次结构中较低的存储器 (离cpu较远) 的访问时间较长,为了补偿这些较长的访问时间,倾向于使用更大的块。
存储器中的数据总是以块大小为传送单元在第 k 层和第 k + 1 层之间来回拷贝的。L1 和寄存器之间的传送块大小为 1 个字,1 个字在 32 位系统上是 4 字节,在 64 位系统上是 8 字节。而 L2 和 L1 之间,以及 L3 和 L2 之间,传送的通常是 8 个字的块,通常称为一个 cache line,64 位系统上是 64 字节。而内存与 L3 之间的传送大小通常是几百或几千字节的块。层次结构中较低的存储器 (离cpu较远) 的访问时间较长,为了补偿这些较长的访问时间,倾向于使用更大的块。

CPU 中有两个硬件用来将数据从内存预取到 L2 和 L3 中的。一个是空间预取器 (Spatial Prefetcher),这个部件每次预取一对 cache line,到 L2 的高速缓存行当中。另一个是 Streamer,用来监视来自 L1 高速缓存的读取请求,以获得地址的升序或者降序序列。当检测到请求的地址是当前地址的前向或者后向流时,会将数据预取到最后一级缓存 L3,通常数据也会被带到 L2,除非 L2 缓存的需求过重。Streamer 可以检测和维护最多 32 个数据访问流,对于每个 4K 页,可以维护一个前向地址流和一个后向地址流。
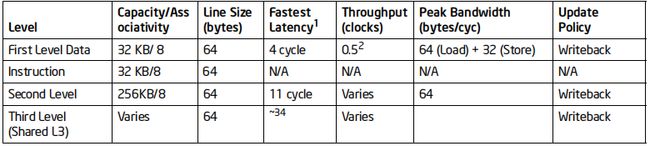
访问越高层次的部件,所需要的时间就越少。下图为 Haswell process 中 cpu 访问各级缓存所需要的时间。访问 L1 需要大约 4 个时钟周期,L2 需要 11 个时钟周期,L3 需要约 34 个时钟周期。如果 cpu 直接从寄存器中读取数据,则只需要 1 个时钟周期。
下图是 Intel Xeon Processor 5500 这款处理器发生了 L2 cache miss 之后从 L3 或者内存中获取数据所需要的时间。假设 cpu 主频为 2Ghz,那么 1 个时钟周期约为 0.5ns,50 ~ 90 ns 约为 100 ~ 180 cycles。

对齐数据结构,优化内存布局
当需要访问的数据不存在于寄存器中,我们就需要从 L1 cache 中去寻找,并加载到寄存器中,cpu 访问一次 L1 cache 获取到的数据只有 1 个字。 在 64 位机器上,字大小为 8 个字节。
在很早以前,内存是按字节寻址并按顺序排列的。 如果内存被安排为一个字节宽度,处理器需要 1个内存读取周期来获取 1 个 char 类型的数据,需要 4 个内存读取周期来获取一个 int 类型的整数。 不过显然,int 类型或者更大的 int64 类型,在现代的计算机系统中更常见。所以,如果能在一个内存周期内一次读取 4 个字节的 int 整数会显得更加经济有效。为了保证 4 字节或者 8 字节的数据能在 1 次内存读取周期内获取,即 cpu 访问 1 次 L1 cache 便能获取全部的数据,而不是访问两次再进行数据拼接,所有的数据类型都会有对齐的要求。4 字节的数据类型 (int 或 float),总是 4 字节地址对齐的,8 字节的数据类型 (long int 或 double),总是 8 字节地址对齐的。
#include
int main()
{
char a = 0;
int b = 0;
char c = 0;
double d = 0;
printf("a:%p\n", &a);
printf("b:%p\n", &b);
printf("c:%p\n", &c);
printf("d:%p\n", &d);
return 0;
} 上面这段程序,根据数据类型对齐方法,我们期望得到的结果是 b 的地址是 4 字节对齐的,d 的地址是 8 字节对齐的。运行一下查看结果:
[root@wuhan struct]# gcc align1.c -o align1
[root@wuhan struct]# ./align1
a:0x7fff580c84df
b:0x7fff580c84d8
c:0x7fff580c84d7
d:0x7fff580c84c8b 的地址是 8 的倍数,肯定是 4 字节对齐的,d 的地址也是 8 的倍数,是 8 字节对齐的。
再用 O2 优化选项重新编译运行,再查看下结果。
[root@wuhan struct]# gcc align1.c -o align1 -O2
[root@wuhan struct]# ./align1
a:0x7ffc1a0c4c42
b:0x7ffc1a0c4c44
c:0x7ffc1a0c4c43
d:0x7ffc1a0c4c48可以看到,经过优化之后,b 的地址还是 4 字节对齐的,d 的地址也依然是 8 字节对齐的。a 和 c 的地址,经过编译器优化之后,在内存中的位置排布更加紧密。假设 a, b, c, d 已经缓存在 L1 cache 当中,我们要将这 4 个数据全部读到寄存器当中,那么从 4c40 开始,到 4c50 结束,在 64 位机器上,只需要 2 次内存访问周期就能获取全部数据。再看未经过 O2 优化的程序,从 84c8 开始,到 84e0 结束,中间有 24 个字节,那么最少需要 3 次内存访问周期才能获取全部数据。
编译器可以优化变量在程序内存中的位置排布,但是不能优化变量在数据结构中的排布。如果借鉴编译器的优化方法,我们自己就可以去优化数据结构,使内存排布更加紧密。
#include
typedef struct
{
int a;
char b;
int c;
char d;
int e;
} unpacked_t;
int main()
{
unpacked_t unpack = {0};
printf("sizeof(unpack):%d unpack:%p a:%p b:%p c:%p d:%p e:%p\n",
sizeof(unpack), &unpack, &unpack.a, &unpack.b, &unpack.c, &unpack.d, &unpack.e);
return 0;
} 在 unpacked_t 这个结构体当中,由于 int 类型需要 4 字节对齐,那么尽管 b 和 d 只有 1 个字节的大小,但是他们实际上需要消耗 4 字节的内存空间,剩下的 3 个字节作为数据结构对齐的填充部分。
[root@wuhan struct]# gcc align2.c -o align2
[root@wuhan struct]# ./align2
sizeof(unpack):20 unpack:0x7ffd9903cd60 a:0x7ffd9903cd60 b:0x7ffd9903cd64 c:0x7ffd9903cd68 d:0x7ffd9903cd6c e:0x7ffd9903cd70运行一下这个程序,可以知道,unpack 所占的内存大小为 5 x 4 = 20 字节,a, b, c, d, e 的地址都是 4 字节对齐的,其中 b 和 d 后面有 3 个字节的填充。
将数据结构调整一下,按如下方式进行调整,运行该程序,可以得到 pack 所占的内存大小为 16 字节,其中 a, c, e 都是 4 字节对齐,b 和 d 占据另外一个 4 字节的前两个字节的位置,后两个字节为填充。
#include
typedef struct
{
int a;
int c;
int e;
char b;
char d;
} packed_t;
int main()
{
packed_t pack = {0};
printf("sizeof(pack):%d pack:%p a:%p b:%p c:%p d:%p e:%p\n",
sizeof(pack), &pack, &pack.a, &pack.b, &pack.c, &pack.d, &pack.e);
return 0;
} [root@wuhan struct]# gcc align3.c -o align3
[root@wuhan struct]# ./align3
sizeof(pack):16 pack:0x7ffd3aa96a90 a:0x7ffd3aa96a90 b:0x7ffd3aa96a9c c:0x7ffd3aa96a94 d:0x7ffd3aa96a9d e:0x7ffd3aa96a98访问这两个数据结构,unpacked_t 可能需要 3 次内存访问才能获取全部元素,packed_t 只需要 2 次就够了。
分解结构体数组,提高 cache 利用率
64 字节的缓存行大小会对数据流相关的应用程序性能有较大的影响。大部分数据在丢弃之前,很有可能只会被使用一次。对 cache 中数据的稀疏访问,会导致系统内存带宽利用率较低。有种方法是,我们可以将结构体数组分解为多个数组,以实现更合理的封装方式及更有效的 cache 访问。
typedef struct
{ /* 1600 bytes */
int a, c, e;
char b, d;
} array_of_struct_t;
array_of_struct_t array[100];
=>
typedef struct
{ /* 1400 bytes */
int a[100], c[100], e[100];
char b[100], d[100];
} struct_of_array_t;
struct_of_array_t array;这种优化是否合理取决于具体的使用模式。如果数据结构中元素都被一起访问,但对数组的访问是随机的,那么即使 array_of_struct_t 会浪费一些内存,但是也能避免一些不必要的 cache 预取。
然而,如果数组的访问出现局部性,例如,需要对数组的索引进行遍历访问,那么处理器将从struct_of_array_t 中每个数组里分别预取数据,即使是数据结构中的所有元素都被一起访问。如果数据结构中的元素不是以相同频率进行访问时,例如对 a 的访问频率是其他元素的十倍以上时,struct_of_array_t 不仅可以节约内存,还可以防止对不必要数据项 b, c, d, e 的 cache 预取。
下面的优化例子不算特别恰当,但是也能反映改优化的思想。
| #include int main() array_of_struct_t array[100]; for (int i = 0; i < 1000000; i ++) for (int i = 0; i < 100000; i ++) return 0; |
#include int main() struct_of_array_t array; for (int i = 0; i < 1000000; i ++) for (int i = 0; i < 100000; i ++) return 0; |
| [root@wuhan struct]# gcc align3.c -o align3 real 0m0.309s |
[root@wuhan struct]# gcc align4.c -o align4 real 0m0.297s |
另外使用 struct_of_array_t 还有一个好处,就是方便程序员或者编译器使用 SIMD 进行进一步的优化。关于 SIMD 的介绍请参考 深入代码优化 (二) 使用SIMD优化程序_天寒寒的博客-CSDN博客_simd优化
但是使用 struct_of_array_t 有个缺点,那就是可能需要更多的独立内存流访问,即 Streamer 会将多个数组的数据分别预取到 cache 当中。这就导致需要额外的 cache 预取和额外的地址生成计算。还可能会对内存页的访问效率造成影响。
于是产生另一种优化方法,就是使用混合数据结构,这种数据结构结合了 array_of_struct_t 以及 struct_of_array_t 两种方法。使用这个数据结构,仅生成和引用两个单独的地址流,一个用于 hybrid_struct_of_array_ace_t,另一个用于 hybrid_struct_of_array_bd_t。随之而来还可能会带有另外的好处,假设变量 a, c, e 总是在一起使用,变量 b, d 总是在一起使用,但不与变量 a, c, e 同时使用,那么这种方法也可以防止对其他数组不必要的 cache 预取。
typedef struct
{ /* 1200 bytes */
int a, c, e;
} hybrid_struct_of_array_ace_t;
hybrid_struct_of_array_ace_t array_ace[100];
typedef struct
{ /* 200 bytes */
char b, d;
} hybrid_struct_of_array_bd_t;
hybrid_struct_of_array_bd_t array_bd[100];混合数据结构的优势是:
比 struct_of_array_t 拥有更简单以及更少的地址生成。
更少的内存流,从而可以减少内存页访问未命中带来的开销。
由于更少的内存流带来更少的 cache 预取。
结构体元素在同时使用时,在同一 cache line 里可能会包含所有元素。
参考文献:
performance - What does 'Natural Size' really mean in C++? - Stack Overflow
Structure Member Alignment, Padding and Data Packing - GeeksforGeeks
https://www.cl.cam.ac.uk/research/srg/projects/fairisle/bluebook/12/scache/node2.html
https://en.wikipedia.org/wiki/CPU_cache
《Computer Architecture: A Quantitative Approach》
《深入理解计算机系统》
《64-ia-32-architectures-optimization-manual》