Linux 内核内存管理架构二(虚拟内存管理之页表)
目录
1.虚拟地址和MMU工作原理
1.1 虚拟地址 物理地址 转换
1.2 MMU工作原理
1.2 页表的改进--二级页表
2.页表
2.1 section段映射
2.2 页表项格式
2.3 页表的初始化过程
2.3.1 一级页表进行段映射
2.3.2 内核页表初始化代码
1.虚拟地址和MMU工作原理
1.1 虚拟地址 物理地址 转换
无限的软件程序需求和有限的物理内存空间冲突导致虚拟地址的出现。
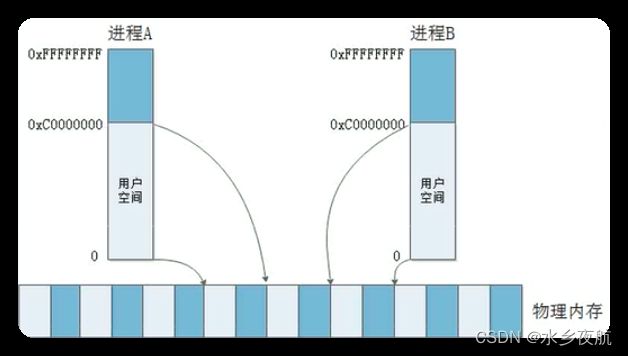
MMU就是进行虚拟地址和物理地址映射的模块。mmu以页地址为单位进行转换,在得到了虚拟地址后,其低12位表示的是页内偏移,高20位表示虚拟页号,结合内存中的页表,得到了实际的物理页号,再加上页内偏移就得到了要访问的物理地址。

1.2 MMU工作原理
每次ARM去寻址先经过MMU模块,MMU模块先在内部的页表缓中匹配,命中失败则通过Table Walk Unit模块去物理内存中查找相应的页表表项。

1.2 页表的改进--二级页表
32位的平台 管理4G的虚拟地址空间,就有4G/4k=1M个页面,假设每个页面我们需要4个字节来记录映射关系,那总共就需要4M空间;每个进程映射表都不一样,假设又有100个进程,那么就需要400M空间来存储地址映射关系。这是不可接受的,因此在上面直接映射的一级页表基础上,产生了二级页表。
二级页表在一级页表基础上,把虚拟地址的高20位划分成了12+8位,分别表示一级页表的偏移地址first_offset和二级页表的偏移地址second_offset,这样就能表示4096*256=1M个页面。转换的时候,先找到一级页表的首地址,加上first_offset得到二级页表的首地址,再加上second_offset就得到了真正的页映射entry,加上低12位的页面内偏移,最终得到了虚拟地址。
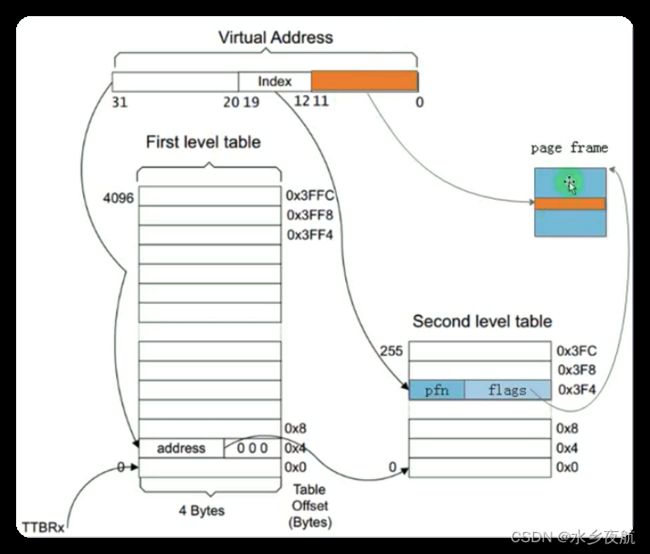
但是,到这里为止,我们似乎并没有解决页表占用物理空间过大的问题,4096*4+4096*256*4=16K+1M,比原来还更大了!
理论上确实如此,但是实际上因为进程不会映射所有的虚拟地址空间,实际使用过程中进程不会用到这么大的物理内存;同时使用二级页表支持不连续的创建,随用随建;一级页表必须连续映射,否则就会因为地址缺失而寻址失败。这就是二级页表省物理内存的关键。

2.页表
2.1 section段映射
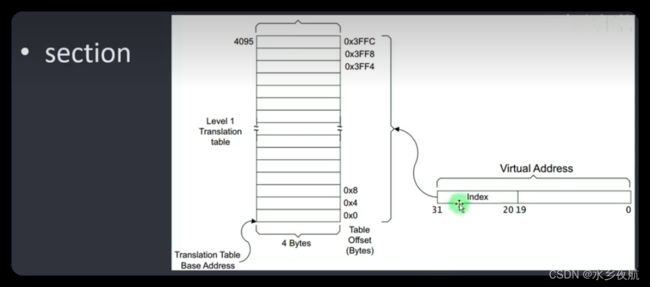
页表的存在目的是实现实虚转换,二级页表是为了减少物理内存消耗。除了以页为单位的二级页表,ARM架构的Linux内核还支持以1M为单位的段(section)映射,此时一级页表也能够实现节省空间的目的,每条映射假设4字节,4G空间需要 4G/1M*4=16k ,100个进程也只需要2M不到的物理空间!
如下,段映射使用了32位地址的前12位作为一级页表偏移,后20位作为段内偏移:

arm甚至能够支持配置16M的super section映射:

2.2 页表项格式
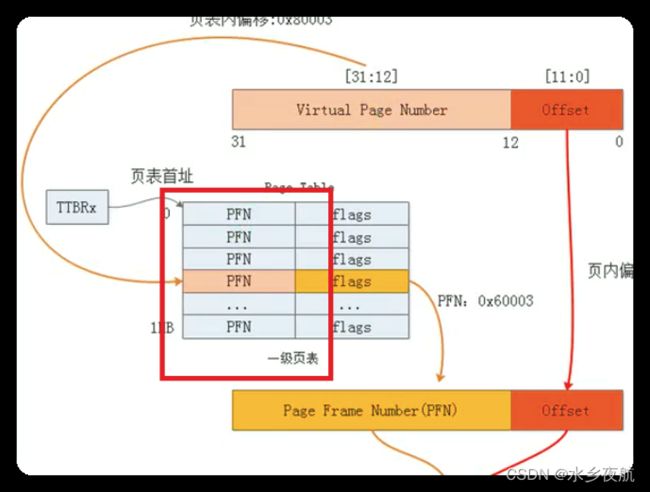
前面说的都是页表映射机制,现在深入的看一下ARM的二级页表的页表项的格式(也就是页表里每一项数据的存放格式) ,以4k的小页为例:
一级页表的后10bit是无效的,前面22bit放的是二级页表描述符的基地址,因为我们希望二级页表的基地址是1k(2^10)对齐的,这样二级页表就不会发生跨页面或者地址不对齐的情况,避免了不必要的寻址时间。
二级页表的低12位无效,这个我们都好理解,因为每个小页4K;对于大页64k,其低16位都是无效的。

ARM32 页表映射过程 - 走看看
实际上,arm linux是将一级页表段映射和二级页表页映射混合起来用的,启动之初就是一级页表段映射。
2.3 页表的初始化过程
内核启动之初,MMU还未开启,因为此时页表还未建立,没有映射关系。因此要先等内核建立了页表,才能开启MMU,使用虚拟地址。内核启动之初使用的是以1M段为单位的一级页表,其实现在arch/arm/kernel/head.s汇编文件中。
2.3.1 一级页表进行段映射
如图,内核启动时将自身虚拟空间划分成了不同的部分,高地址是内核镜像,依次下来手BSS段,数据段,初始化代码段,代码段,页表段(swapper_page_dir, 这是汇编文件标识的一个全局变量名)以及低位地址的用户空间段。
页表段从0x80004000 到 0x80008000,正好16k放下4096个一级页表项。假设我们的虚拟地址是0x80108000, 按照段页表规则,其高12位是页表的偏移项index,每个项4字节,则其偏移地址是0x801*4=0x2004, 加上页表的基地址0x80004000 得到0x80006004,对应的页表项内容是0x601+Flags(无效值),它指向了物理内存一个段地址0x60100000,此时再加上虚拟地址0x80108000的低20bit 段内偏移,就得到了我们在物理内存中的真实物理地址0x60108000。这样,内核就创建好了一级页表的段映射,可以准备开启MMU了。(问题:一级页表使用的是虚拟地址,那么一级页表本身到底放在了内存的哪个物理地址?MMU是怎么找到它的?)

2.3.2 内核页表初始化代码
arch/arm/kernel/head.s:
/*
* swapper_pg_dir is the virtual address of the initial page table.
* We place the page tables 16K below KERNEL_RAM_VADDR. Therefore, we must
* make sure that KERNEL_RAM_VADDR is correctly set. Currently, we expect
* the least significant 16 bits to be 0x8000, but we could probably
* relax this restriction to KERNEL_RAM_VADDR >= PAGE_OFFSET + 0x4000.
*/
#define KERNEL_RAM_VADDR (PAGE_OFFSET + TEXT_OFFSET)
#if (KERNEL_RAM_VADDR & 0xffff) != 0x8000
#error KERNEL_RAM_VADDR must start at 0xXXXX8000
#endif
#define PG_DIR_SIZE 0x4000
#define PMD_ORDER 2
.globl swapper_pg_dir
.equ swapper_pg_dir, KERNEL_RAM_VADDR - PG_DIR_SIZE
.macro pgtbl, rd, phys
add \rd, \phys, #TEXT_OFFSET - PG_DIR_SIZE
.endm
#define KERNEL_START KERNEL_RAM_VADDR
#define KERNEL_END _end
/* 汇编入口 */
.arm
__HEAD
ENTRY(text)
/* ... ... ... ... */
mov r8, r4 /*set TTBR1 to swapper_pg_dir将内核页表物理地址存放到TTBR1寄存器R8中*/
/*
* Setup the initial page tables. We only setup the barest
* amount which are required to get the kernel running, which
* generally means mapping in the kernel code.
*
* r8 = phys_offset, r9 = cpuid, r10 = procinfo
*
* Returns:
* r0, r3, r5-r7 corrupted
* r4 = physical page table address
*/
__create_page_tables:
/* page table address pgtbl是一个用于获得启动页表物理地址的宏,它将stext减去16K给reg */
pgtbl r4, r8
/*Clear the swapper page table 下面这这段先对页表进行清零,清零后跳转代码段1 ! */
mov r0, r4
mov r3, #0
add r6, r0, #PG_DIR_SIZE r6 保存页表的结束地址
1: str r3, [r0], #4
str r3, [r0], #4
str r3, [r0], #4
str r3, [r0], #4
teq r0, r6
bne 1b
/* ... ... ... ... */
ldr r7, [r10, #PROCINFO_MM_MMUFLAGS] @ mm_mmuflags
/*
* Create identity mapping to cater for __enable_mmu.
* This identity mapping will be removed by paging_init().
*/
adr r0, __turn_mmu_on_loc //对等映射,在开启MMU这段代码中,虚拟地址=物理地址,防止开启MMU后代码跑飞
ldmia r0, {r3, r5, r6}
sub r0, r0, r3 @ virt->phys offset
add r5, r5, r0 @ phys __turn_mmu_on
add r6, r6, r0 @ phys __turn_mmu_on_end
mov r5, r5, lsr #SECTION_SHIFT
mov r6, r6, lsr #SECTION_SHIFT
/* 跳转 继续初始化页表 */
1: orr r3, r7, r5, lsl #SECTION_SHIFT @ flags + kernel base
str r3, [r4, r5, lsl #PMD_ORDER] @ identity mapping
cmp r5, r6
addlo r5, r5, #1 @ next section
blo 1b
/*
* Now setup the pagetables for our kernel direct
* mapped region.设置内核代码段 数据段 bss段等
*/
mov r3, pc
mov r3, r3, lsr #SECTION_SHIFT
orr r3, r7, r3, lsl #SECTION_SHIFT
add r0, r4, #(KERNEL_START & 0xff000000) >> (SECTION_SHIFT - PMD_ORDER)
str r3, [r0, #((KERNEL_START & 0x00f00000) >> SECTION_SHIFT) << PMD_ORDER]!
ldr r6, =(KERNEL_END - 1)
add r0, r0, #1 << PMD_ORDER
add r6, r4, r6, lsr #(SECTION_SHIFT - PMD_ORDER)
1: cmp r0, r6
add r3, r3, #1 << SECTION_SHIFT
strls r3, [r0], #1 << PMD_ORDER
bls 1b
/*
* Then map boot params address in r2 or the first 1MB (2MB with LPAE)
* of ram if boot params address is not specified.
*/
mov r0, r2, lsr #SECTION_SHIFT
movs r0, r0, lsl #SECTION_SHIFT
moveq r0, r8
sub r3, r0, r8
add r3, r3, #PAGE_OFFSET
add r3, r4, r3, lsr #(SECTION_SHIFT - PMD_ORDER)
orr r6, r7, r0
str r6, [r3]
mov pc, lr /* 最后PC指针跳转到lr 执行*/
ENDPROC(__create_page_tables)看完汇编, 我们就可以回答上面关于页表的存放和查找的问题了,页表基地址在内存中存放的物理地址会被专门储存在TTBR1寄存器中,这样每次进行寻址就省去了查找页表的消耗。老版本的ARM架构和内核只支持TTBR0,这是用户态和内核态共用的一级页表基值寄存器;后面新版的ARM架构才支持了TTRB1,实现了内核态和用户态页表基址的分离。具体描述可以参考这两篇博文:ARM TTBR0,TTBR1寄存器与ARM32页表复制_a372048518的博客-CSDN博客_arm ttbr0 ttbr1一,ARM TTBR0,TTBR1寄存器;从ARMV6开始增加了TTBR1寄存器,但是在ARM32的时候,TTBR1寄存器未使用,原因如下:TTBR0和TTBR1寄存器只支持2G,1G,512M等,但是ARM32虚拟地址空间的划分比例为1:3,用户空间是3G,内核空间是1G,所以上述寄存器硬件限制无法满足这种通用配置,所以ARM32未使用TTBR1寄存器;二,ARM32页表复制ARM32...https://blog.csdn.net/a372048518/article/details/103865898
TTBR0与TTBR1 - DF11G - 博客园ARMv7-A架构中有两个协处理器寄存器用来存放一级页表基地址(PGD),TTBR0和TTBR1(Translation table base register: 页表基地址寄存器)。其中,TTBR0https://www.cnblogs.com/DF11G/p/14486558.html