java经典算法实现_经典分布式算法 —— 浅显易懂的 Raft 算法实现
一、Raft概念
copy一下其他小伙伴写的文章: Raft算法详解
不同于Paxos算法直接从分布式一致性问题出发推导出来,Raft算法则是从多副本状态机的角度提出,用于管理多副本状态机的日志复制。Raft实现了和Paxos相同的功能,它将一致性分解为多个子问题:Leader选举(Leader election)、日志同步(Log replication)、安全性(Safety)、日志压缩(Log compaction)、成员变更(Membership change)等。同时,Raft算法使用了更强的假设来减少了需要考虑的状态,使之变的易于理解和实现。
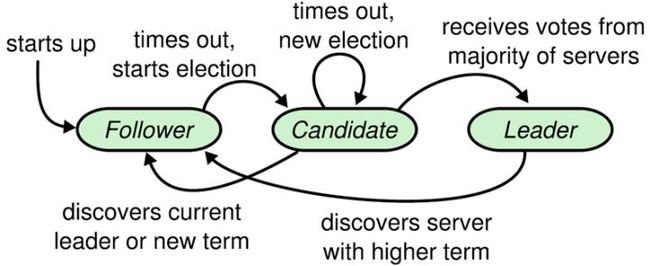
Raft将系统中的角色分为领导者(Leader)、跟从者(Follower)和候选人(Candidate):
Leader:接受客户端请求,并向Follower同步请求日志,当日志同步到大多数节点上后告诉Follower提交日志。
Follower:接受并持久化Leader同步的日志,在Leader告之日志可以提交之后,提交日志。
Candidate:Leader选举过程中的临时角色。
本文不过多赘述 raft 算法是个什么东西... 这里再贴一个十分好理解的文章:The Raft Consensus Algorithm
二、系统初步设计
在对raft有一定理解后,我们简单梳理一下在raft选举过程中,我们需要的一些角色,以及角色的司职。
首先我们需要一个选举控制类,单例实现即可,节点的选举全权交给此选举控制类的实现,我们称其为 ElectOperator。
先讲一个 raft 中重要的概念:世代,也称为 epoch,但在这篇文章,将其称为 generation(不要纠结这个 = =)。 世代可以认为是一个标记当前发送的操作是否有效的标识,如果收到了小于本节点世代的请求,则可无视其内容,如果收到了大于本世代的请求,则需要更新本节点世代,并重置自己的身份,变为 Follower,类似于乐观锁的设计理念。
我们知道,raft中一共有三种角色:Follower、Candidate、Leader
(1)Follower
Follower 需要做什么呢:
接收心跳
Follower 在 ELECTION_TIMEOUT_MS 时间内,若没有收到来自 Leader的心跳,则转变为 Candidate
接收拉票请求,并返回自己的投票
好的,Follower非常简单,只需要做三件事即可。
(2)Candidate
Candidate 扮演什么样的职能呢:
接收心跳
Candidate 在 ELECTION_TIMEOUT_MS 时间内,若没有收到来自 Leader的心跳,则转变为 Candidate
接收拉票请求,并返回自己的投票
向集群中的其他节点发起拉票请求
当收到的投票大于半数( n/2 + 1, n为集群内的节点数量),转变为 Leader
Candidate 比起 Follower 稍微复杂一些,但前三件事情都是一样的。
(3)Leader
Leader 在选举过程中扮演的角色最为简单:
接收心跳
向集群内所有节点发送心跳
Leader 也是可以接收心跳的,当收到大于当前世代的心跳或请求后,Leader 需要转变为 Follower。Leader 不可能收到同世代的心跳请求,因为 (1) 在 raft 算法中,同一世代中,节点仅对同一个节点进行投票。(2) 需要收到过半投票才可以转变为 Leader。
三、系统初步实现
简单贴一下选举控制器需要的一些属性代码,下面的注释都说的很清楚了,其中需要补充的一点是定时任务使用了时间轮来实现,不理解没有关系...就是个定时任务,定时任务的一个引用放在 Map taskMap; 中,便于取消任务。
public class ElectOperator extends ReentrantLocker implements Runnable {
// 成为 Candidate 的退避时间(真实退避时间需要 randomized to be between 150ms and 300ms )
private static final long ELECTION_TIMEOUT_MS = ElectConfigHelper.getElectionTimeoutMs();
// 心跳间隔
private static final long HEART_BEAT_MS = ElectConfigHelper.getHeartBeatMs();
/**
* 该投票箱的世代信息,如果一直进行选举,一直能达到 {@link #ELECTION_TIMEOUT_MS},而选不出 Leader ,也需要15年,generation才会不够用,如果
* generation 的初始值设置为 Long.Min (现在是0,则可以撑30年,所以完全呆胶布)
*/
private long generation;
/**
* 当前节点的角色
*/
private NodeRole nodeRole;
/**
* 所有正在跑的定时任务
*/
private Map taskMap;
/**
* 投票箱
*/
private Map box;
/**
* 投票给了谁的投票记录
*/
private Votes voteRecord;
/**
* 缓存一份集群信息,因为集群信息是可能变化的,我们要保证在一次选举中,集群信息是不变的
*/
private List clusters;
/**
* 心跳内容
*/
private HeartBeat heartBeat;
/**
* 现在集群的leader是哪个节点
*/
private String leaderServerName;
private volatile static ElectOperator INSTANCE;
public static ElectOperator getInstance() {
if (INSTANCE == null) {
synchronized (ElectOperator.class) {
if (INSTANCE == null) {
INSTANCE = new ElectOperator();
ElectControllerPool.execute(INSTANCE);
}
}
}
return INSTANCE;
}
另外,上面罗列的这些值大都是需要在更新世代时重置的,我们先拟定一下更新世代的逻辑,通用的来讲,就是清除投票记录,清除自己的投票箱,更新自己的世代,身份变更为 Follower 等等,我们将这个方法称为 init。
/**
* 初始化
*
* 1、成为follower
* 2、先取消所有的定时任务
* 3、重置本地变量
* 4、新增成为Candidate的定时任务
*/
private boolean init(long generation, String reason) {
return this.lockSupplier(() -> {
if (generation > this.generation) {// 如果有选票的世代已经大于当前世代,那么重置投票箱
logger.debug("初始化投票箱,原因:{}", reason);
// 1、成为follower
this.becomeFollower();
// 2、先取消所有的定时任务
this.cancelAllTask();
// 3、重置本地变量
logger.debug("更新世代:旧世代 {} => 新世代 {}", this.generation, generation);
this.generation = generation;
this.voteRecord = null;
this.box = new HashMap<>();
this.leaderServerName = null;
// 4、新增成为Candidate的定时任务
this.becomeCandidateAndBeginElectTask(this.generation);
return true;
} else {
return false;
}
});
}
(1) Follower的实现
基于上面的分析,我们可以归纳一下 Follower 需要一些什么样的方法:
1、转变为 Candidate 的定时任务
实际上就是 ELECTION_TIMEOUT_MS (randomized to be between 150ms and 300ms) 后,如果没收到 Leader 的心跳,或者自己变为 Candidate 后,在这个时间内没有成功上位,则继续转变为 Candidate。
为什么我们成为 Candidate 的退避时间需要随机 150ms - 300ms呢?这是为了避免所有节点的选举发起发生碰撞,如果说都是相同的退避时间,每个节点又会优先投自己一票,那么这个集群系统就会陷入无限发起投票,但又无法成为 Leader 的局面。
简而言之就是我们需要提供一个可刷新的定时任务,如果在一定时间内没刷新这个任务,则节点转变为 Candidate,并发起选举,代码如下。首先取消之前的 becomeCandidate 定时定时任务,然后设定在 electionTimeout 后调用 beginElect(generation) 方法。
/**
* 成为候选者的任务,(重复调用则会取消之前的任务,收到来自leader的心跳包,就可以重置一下这个任务)
*
* 没加锁,因为这个任务需要频繁被调用,只要收到leader来的消息就可以调用一下
*/
private void becomeCandidateAndBeginElectTask(long generation) {
this.lockSupplier(() -> {
this.cancelCandidateAndBeginElectTask("正在重置发起下一轮选举的退避时间");
// The election timeout is randomized to be between 150ms and 300ms.
long electionTimeout = ELECTION_TIMEOUT_MS + (int) (ELECTION_TIMEOUT_MS * RANDOM.nextFloat());
TimedTask timedTask = new TimedTask(electionTimeout, () -> this.beginElect(generation));
Timer.getInstance()
.addTask(timedTask);
taskMap.put(TaskEnum.BECOME_CANDIDATE, timedTask);
return null;
});
}
2、接收心跳与心跳回复
接收心跳十分简单,如果当前心跳大于等于当前世代,且还未认定某个节点为 Leader,则取消所有定时任务,成为Follower,并记录心跳包中 Leader 节点的信息,最后重置一下成为候选者的任务。
如果已经成为某个 Leader 的 Follower,则直接成为候选者的任务即可。
另外一个要注意的是,needToSendHeartBeatInfection,是否需要发送心跳感染包,当收到低世代 Leader 的心跳时,如果当前集群已经选出 Leader ,则回复此心跳包,告诉旧 Leader,现在已经是新世代了!(代码中没有展现,其实就是再次封装一个心跳包,带上世代信息和 Leader 节点信息,回复给 Leader 即可)
public void receiveHeatBeat(String leaderServerName, long generation, String msg) {
return this.lockSupplier(() -> {
boolean needToSendHeartBeatInfection = true;
// 世代大于当前世代
if (generation >= this.generation) {
needToSendHeartBeatInfection = false;
if (this.leaderServerName == null) {
logger.info("集群中,节点 {} 已经成功在世代 {} 上位成为 Leader,本节点将成为 Follower,直到与 Leader 的网络通讯出现问题", leaderServerName, generation);
// 取消所有任务
this.cancelAllTask();
// 成为follower
this.becomeFollower();
// 将那个节点设为leader节点
this.leaderServerName = leaderServerName;
}
// 重置成为候选者任务
this.becomeCandidateAndBeginElectTask(this.generation);
}
return null;
});
}
3、接收拉票请求与回复投票
我们知道,raft 在一个世代只能投票给一个节点,且发起投票者会首先投票给自己。所以逻辑就很简单了,只有当世代大于等于当前,且还未投票时,则拉票请求成功,返回true即可,否则都视为失败,返回false。
/**
* 某个节点来请求本节点给他投票了,只有当世代大于当前世代,才有投票一说,其他情况都是失败的
*
* 返回结果
*
* 为true代表接受投票成功。
* 为false代表已经给其他节点投过票了,
*/
public VotesResponse receiveVotes(Votes votes) {
return this.lockSupplier(() -> {
logger.debug("收到节点 {} 的投票请求,其世代为 {}", votes.getServerName(), votes.getGeneration());
String cause = "";
if (votes.getGeneration() < this.generation) {
cause = String.format("投票请求 %s 世代小于当前世代 %s", votes.getGeneration(), this.generation);
} else if (this.voteRecord != null) {
cause = String.format("在世代 %s,本节点已投票给 => %s 节点", this.generation, this.voteRecord.getServerName());
} else {
this.voteRecord = votes; // 代表投票成功了
}
boolean result = votes.equals(this.voteRecord);
if (result) {
logger.debug("投票记录更新成功:在世代 {},本节点投票给 => {} 节点", this.generation, this.voteRecord.getServerName());
} else {
logger.debug("投票记录更新失败:原因:{}", cause);
}
String serverName = InetSocketAddressConfigHelper.getServerName();
return new VotesResponse(this.generation, serverName, result, serverName.equals(this.leaderServerName), votes.getGeneration());
});
}
(2) Candidate的实现
可以看出 Follower 十分简单, Candidate 在 Follower 的基础上增加了发起选举的拉票请求,与接收投票,并上位成为Leader两个功能,实际上也十分简单。
1、发起拉票请求
回顾一下前面的转变成 Candidate 的定时任务,定时任务实际上就是调用一个方法
TimedTask timedTask = new TimedTask(electionTimeout, () -> this.beginElect(generation));
这个 beginElect 就是转变为 Candidate 并发起选举的实现。让我们先想想需要做什么,首先肯定是
更新一下自己的世代,因为已经长时间没收到 Leader 的心跳包了,我们需要自立门户。
给自己投一票
要求其他节点给自己投票
分析到这里就很明了了。下面首先执行 updateGeneration 方法,实际上就是执行前面所说的 init 方法,传入 generation + 1 的世代,重置一下上个世代各种保存的状态;然后调用 becomeCandidate,实际上就是切换一下身份,将 Follower 或者 Candidate 切换为 Candidate;给自己的 voteRecord 投一票,最后带上自己的节点标识和世代信息,去拉票。
/**
* 开始进行选举
*
* 1、首先更新一下世代信息,重置投票箱和投票记录
* 2、成为候选者
* 3、给自己投一票
* 4、请求其他节点,要求其他节点给自己投票
*/
private void beginElect(long generation) {
this.lockSupplier(() -> {
if (this.generation != generation) {// 存在这么一种情况,虽然取消了选举任务,但是选举任务还是被执行了,所以这里要多做一重处理,避免上个周期的任务被执行
return null;
}
logger.info("Election Timeout 到期,可能期间内未收到来自 Leader 的心跳包或上一轮选举没有在期间内选出 Leader,故本节点即将发起选举");
updateGeneration("本节点发起了选举");// this.generation ++
// 成为候选者
logger.info("本节点正式开始世代 {} 的选举", this.generation);
if (this.becomeCandidate()) {
VotesResponse votes = new VotesResponse(this.generation, InetSocketAddressConfigHelper.getServerName(), true, false, this.generation);
// 给自己投票箱投票
this.receiveVotesResponse(votes);
// 记录一下,自己给自己投了票
this.voteRecord = votes;
// 让其他节点给自己投一票
this.askForVoteTask(new Votes(this.generation, InetSocketAddressConfigHelper.getServerName()), 0);
}
return null;
});
}
2、接收投票,并成为 Leader
如果说在 150ms and 300ms 之间,本节点收到了过半投票,则可上位成 Leader,否则定时任务会再次调用 beginElect,再次更新本节点世代,然后发起新一轮选举。
接收投票其实十分简单,回忆一下前面接收拉票请求与回复投票,实际上就是拉票成功,就返回true,否则返回flase。
我们每次都判断一下是否拿到过半的票数,如果拿到,则成为 Leader,另外有一个值得注意的是,为了加快集群恢复可用的进程,类似于心跳感染(如果心跳发到Leader那里去了,Leader会告诉本节点,它才是真正的Leader),投票也存在投票感染,下面的代码由 votesResponse.isFromLeaderNode() 来表示。
投票的记录也是十分简单,就是把每个投票记录扔到 Map box; 里,true 表示同意投给本节点,flase 则不同意,如果同意达到半数以上,则调用 becomeLeader 成为本世代 Leader。
/**
* 给当前节点的投票箱投票
*/
public void receiveVotesResponse(VotesResponse votesResponse) {
this.lockSupplier(() -> {
if (votesResponse.isFromLeaderNode()) {
logger.info("来自节点 {} 的投票应答表明其身份为 Leader,本轮拉票结束。", votesResponse.getServerName());
this.receiveHeatBeat(votesResponse.getServerName(), votesResponse.getGeneration(),
String.format("收到来自 Leader 节点的投票应答,自动将其视为来自 Leader %s 世代 %s 节点的心跳包", heartBeat.getServerName(), votesResponse.getGeneration()));
}
if (this.generation > votesResponse.getAskVoteGeneration()) {// 如果选票的世代小于当前世代,投票无效
logger.info("来自节点 {} 的投票应答世代是以前世代 {} 的选票,选票无效", votesResponse.getServerName(), votesResponse.getAskVoteGeneration());
return null;
}
if (votesResponse.isAgreed()) {
if (!voteSelf) {
logger.info("来自节点 {} 的投票应答有效,投票箱 + 1", votesResponse.getServerName());
}
// 记录一下投票结果
box.put(votesResponse.getServerName(), votesResponse.isAgreed());
List hanabiNodeList = this.clusters;
int clusterSize = hanabiNodeList.size();
int votesNeed = clusterSize / 2 + 1;
long voteCount = box.values()
.stream()
.filter(aBoolean -> aBoolean)
.count();
logger.info("集群中共 {} 个节点,本节点当前投票箱进度 {}/{}", hanabiNodeList.size(), voteCount, votesNeed);
// 如果获得的选票已经大于了集群数量的一半以上,则成为leader
if (voteCount == votesNeed) {
logger.info("选票过半,准备上位成为 leader 节点", votesResponse.getServerName());
this.becomeLeader();
}
} else {
logger.info("节点 {} 在世代 {} 的投票应答为:拒绝给本节点在世代 {} 的选举投票(当前世代 {})", votesResponse.getServerName(), votesResponse.getGeneration(), votesResponse.getAskVoteGeneration(), this.generation);
// 记录一下投票结果
box.put(votesResponse.getServerName(), votesResponse.isAgreed());
}
return null;
});
}
(3) Leader 的实现
作为 Leader,在 raft 中的实现却是最简单的,我们只需要给子节点发心跳包即可。然后如果收到大于自己世代的心跳感染,则成为新世代的 Follower,接收心跳的逻辑和 Follower 没有区别。
/**
* 当选票大于一半以上时调用这个方法,如何去成为一个leader
*/
private void becomeLeader() {
this.lockSupplier(() -> {
long becomeLeaderCostTime = TimeUtil.getTime() - this.beginElectTime;
this.beginElectTime = 0L;
logger.info("本节点 {} 在世代 {} 角色由 {} 变更为 {} 选举耗时 {} ms,并开始向其他节点发送心跳包 ......", InetSocketAddressConfigHelper.getServerName(), this.generation, this.nodeRole.name(), NodeRole.Leader.name(),
becomeLeaderCostTime);
this.nodeRole = NodeRole.Leader;
this.cancelAllTask();
this.heartBeatTask();
this.leaderServerName = InetSocketAddressConfigHelper.getServerName();
return null;
});
}
四、运行我们的 raft!
看到这里,不用怀疑.. 一个 raft 算法已经实现了。至于一些细枝末节的东西,我相信大家都能处理好的.. 比如如何给其他节点发送各种包,包怎么去定义之类的,都和 raft 本身没什么关系。
一般来说,在集群可用后,我们就可以让 Follower 连接 Leader 的业务端口,开始真正的业务了。 raft作为一个能快速选主的分布式算法,一次选主基本只需要一次 RTT(Round-Trip Time)时间即可,非常迅速。
运行一下我们的项目,简单测试,我们只用三台机子,想测试多台机子可以自己去玩玩...我们可以看到就像 zookeeper,我们需要配置两个端口,前一个作为选举端口,后一个则作为业务端口。
本文章只讲了怎么选举,后面的端口可以无视,但是必填...
依次启动 hanabi.1,hanabi.2,hanabi.3
很快,我们就能看到 hanabi.1 成为了世代28的 Leader,第一次选举耗时久是因为启动的时候有各种初始化 = =

此时,我们关闭 hanabi.1,因为集群还有2台机器,它们之间完全可以选出新的 Leader,我们关闭 hanabi.1 试试。观察 hanabi.3,我们发现,很快,hanabi.3 就发现 Leader 已经挂掉,并发起了世代 29 的选举。
在世代29中,仅存的 hanabi.2 拒绝为本节点投票,所以在 ELECTION_TIMEOUT_MS 到期后,hanabi.3 再次发起了选举,此次选举成功,因为 hanabi.2 还未到达 ELECTION_TIMEOUT_MS,所以还在世代 28,收到了世代 29 的拉票请求后,hanabi.2 节点将自己的票投给了 hanabi.3,hanabi.3 成功上位。

本项目github地址 : 基于raft算法实现的分布式kv存储框架 (项目实际上还有日志写入,日志提交,日志同步等功能,直接无视它...还没写完 = =)