spark学习5:spark-shell
1.spark提供了交互式接口 spark-shell
spark-shell 实现了用户可以逐行输入代码,进行操作的功能。 即可以不像Java一样,编写完所有代码,然后编译才能运行
spark-shell 支持 Scala交互环境 和 python交互环境
在学习测试中可以使用spark-shell 进行API学习
2.进入Scala交互环境
在spark安装目录的根目录下,有个bin目录中有个 spark-shell
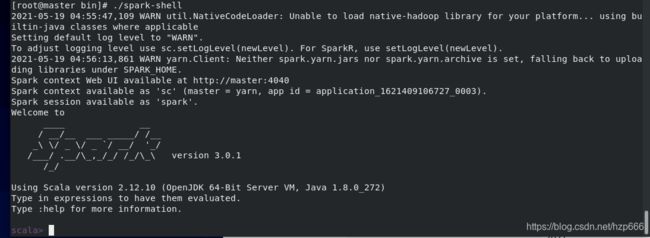
在bin 目录中执行 ./spark-shell 回车键
即可进入 spark-shell 环境
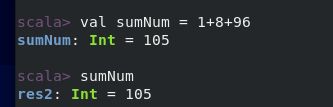
可以进行操作
2.1 添加参数 --master
指定Driver 生成在哪个节点
在本机生成Driver ,spark指挥所,创建sparkContext指挥官
在 spark安装根目录中 执行,

eg:根目录下执行
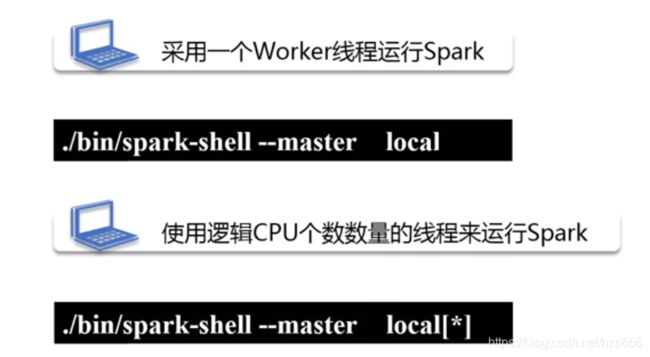
./bin/spark-shell --master local
标识用一个worker 线程运行spark, 即单线程
也可以指定线程数
./bin/spark-shell --master local[2]
标识用两个线程执行
./bin/spark-shell --master local[*]
用 * 表示用当前物理机最大 线程数, 比如 说当前机器 物理CPU是 2个,然后每个物理CPU是2个核, 那就是4个逻辑核,所以 【*】 最大线程是4
,所以说 如果当前物理机 最大逻辑核是 4, 如果 参数写个【8】 也是没有用的,8个线程中只有4个线程执行,然后另外4个线程等待
退出 :quit
即可退出
ps: 在根目录中执行 ./bin/spark-shell, 什么参数都不加,默认执行的是 ./bin/spark-shell --master local[*]
在集群中生成spark指挥所,生成sparkContext
一般有3中 集群模式 standalone 、yarn 、 mesos ,分别对应不同的集群管理模式
其中standalone 是spark 自带的集群资源管理,效果不是特别好。
yarn是 hadoop的集群资源管理,当spark 与 hadoop 集成场景,多使用该模式。
mesos是 单独一个专门做 集群资源管理的,与spark兼容性 比较好。
1) spark-shell的 独立集群模式,即standalone 模式
在spark根目录中执行
spark-shell --master spark://master:7077
或者 spark-shell --master spark://192.168.43.100:7077
即启用standalone 模式
2) yarn 集群模式的 spark-shell
yarn 有两种模式:yarn-client 和 yarn-cluster
首先要启动 hadoop 和yarn
第一种:yarn-client 模式
在spark 根目录上
./bin/spark-shell --master yarn
或者
./bin/spark-shell --master yarn --deploy-mode client
这两个命令是一样的都是进入yarn-client 模式

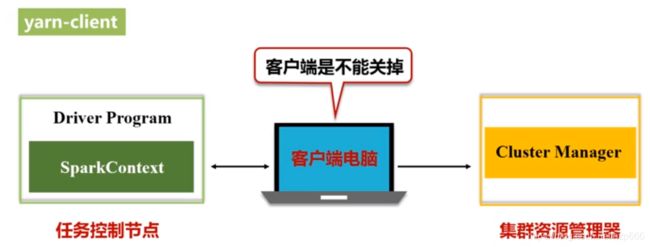
相当于把 Driver节点 (指挥所) 建在了 客户端上,在客户端中生成 sparkContext(指挥官),
所以该模式下 客户端在提交程序后,是不能关闭的,应为指挥所在客户端中
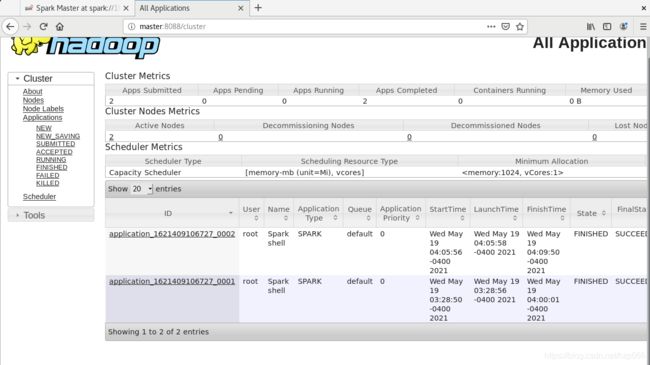
可以再yarn上看到
master:8088
第二种:yarn-cluster
在spark 根目录上
./bin/spark-shell --master yarn --deploy-mode cluster
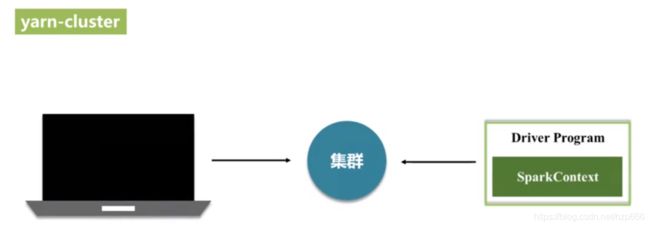
该模式下 客户端提交的程序会被 提交到 集群中,在集群中找一个节点作为 Driver端,生成指挥所和指挥官sparkContext
该模式下 客户端提交完代码后,可以关闭
3)mesos集群模式的spark-shell
在spark 根目录上
./bin/spark-shell --master mesos://***.**.*.*:端口号
2.2 添加 --jar 参数
--jar 参数指定一些需要用到的jar包

2.3添加 --executor-memory 参数
指定程序占用内存大小
--executor-memory 1G
2.4 添加 --total-executor-cores 参数
指定程序开启几个逻辑核
--total-executor-cores 2
# 保存计算结果
https://blog.csdn.net/hzp666/article/details/117122559