Docker中搭建mysql主从复制+Springboot读写分离
- MySQL 主从复制概念
MySQL 主从复制是指数据可以从一个MySQL数据库服务器主节点复制到一个或多个从节点。MySQL 默认采用异步复制方式,这样从节点不用一直访问主服务器来更新自己的数据,数据的更新可以在远程连接上进行,从节点可以复制主数据库中的所有数据库或者特定的数据库,或者特定的表。
- MySQL 主从复制主要用途
- 读写分离
- 在开发工作中,有时候会遇见某个sql 语句需要锁表,导致暂时不能使用读的服务,这样就会影响现有业务,使用主从复制,让主库负责写,从库负责读,这样,即使主库出现了锁表的情景,通过读从库也可以保证业务的正常运作。
- 数据实时备份,当系统中某个节点出现故障的时候,方便切换
- 高可用HA
- 架构扩展
- 随着系统中业务访问量的增大,如果是单机部署数据库,就会导致I/O访问频率过高。有了主从复制,增加多个数据存储节点,将负载分布
-
MySQL主从形式
1.一主一从
2.一主多从,提高系统的读性能
一主一从和一主多从是最常见的主从架构,实施起来简单并且有效,不仅可以实现HA,而且还能读写分离,进而提升集群的并发能力。
3.多主一从 (从5.7开始支持)
多主一从可以将多个mysql数据库备份到一台存储性能比较好的服务器上。
4.双主复制
双主复制,也就是互做主从复制,每个master既是master,又是另外一台服务器的slave。这样任何一方所做的变更,都会通过复制应用到另外一方的数据库中。
5.级联复制
级联复制模式下,部分slave的数据同步不连接主节点,而是连接从节点。因为如果主节点有太多的从节点,就会损耗一部分性能用于replication,那么我们可以让3~5个从节点连接主节点,其它从节点作为二级或者三级与从节点连接,这样不仅可以缓解主节点的压力,并且对数据一致性没有负面影响。 -
Docker下主从复制搭建
docker下安装mysql请参见
本文使用一主一从的形式
搭建主服务器容器实例3307
1.运行mysql实例3307
docker run -p 3307:3306
--name mysql-master
-v /mysqldata/mysql-master/log:/var/log/mysql
-v /mysqldata/mysql-master/data:/var/lib/mysql
-v /mysqldata/mysql-master/conf:/etc/mysql
-e MYSQL_ROOT_PASSWORD=root
-d mysql:5.7
上述命令的含义,可参见此处
2.进入/mysqldata/mysql-master/conf目录下,新建my.cnf,使用vim命令进行编辑如下内容
## 解决mysql字符集编码问题
[client]
default_character_set=utf8
[mysqld]
collation_server = utf8_general_ci
character_set_server = utf8
## 主从复制的配置
[mysqld]
## 设置server_id,同一局域网中需要唯一
server_id=101
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能
log-bin=mall-mysql-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理。此处设置为7天自动清理
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
3.按esc按键,输入:wq! 保存退出
4.重启master实例
docker restart mysql-master
5.进入mysql-master容器
docker exec -it mysql-master /bin/bash
5.输入用户密码登录mysql
## 此处的-u后面跟的是root用户,-p后面跟的是mysql密码
mysql -uroot -proot
6.进入mysql-master容器实例内创建数据同步用户,后续从机将通过此用户进行连接
创建用户
##创建一个slave用户,密码为123456
CREATE USER 'slave'@'%' IDENTIFIED BY '123456';
对当前用户进行授权
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave'@'%';
8.自此,主服务器配置结束,保留当前shell窗口,不退出mysql控制台,重新开启一个shell窗口

搭建从服务器容器实例3308
1.运行mysql实例3308
docker run -p 3308:3306 --name mysql-slave
-v /mysqldata/mysql-slave/log:/var/log/mysql
-v /mysqldata/mysql-slave/data:/var/lib/mysql
-v /mysqldata/mysql-slave/conf:/etc/mysql
-e MYSQL_ROOT_PASSWORD=root
-d mysql:5.7
2.进入/mysqldata/mysql-master/conf目录下,新建my.cnf,使用vim命令进行编辑如下内容
## 解决mysql字符集编码问题
[client]
default_character_set=utf8
[mysqld]
collation_server = utf8_general_ci
character_set_server = utf8
## 主从复制的配置
[mysqld]
## 设置server_id,同一局域网中需要唯一
server_id=102
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能,以备Slave作为其它数据库实例的Master时使用
log-bin=mall-mysql-slave1-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
## relay_log配置中继日志
relay_log=mall-mysql-relay-bin
## log_slave_updates表示slave将复制事件写进自己的二进制日志
log_slave_updates=1
## 从机slave设置为只读(具有super权限的用户除外)
read_only=1
3.按esc按键,输入:wq! 保存退出
4.重启slave实例
docker restart mysql-slave
5.在主数据库中(上图中的 1.阿里云 )查看主从同步状态
show master status;

6.在从容器中(2.阿里云)执行,进入mysql-slave容器
docker exec -it mysql-slave /bin/bash
7.输入用户密码
mysql -uroot -proot
8.在从数据库(2.阿里云)中配置主从复制
change master to
master_host='123.56.103.93',
master_user='slave',
master_password='123456',
master_port=3307,
master_log_file='mall-mysql-bin.000002',
master_log_pos=617,
master_connect_retry=30;
参数说明:
master_host:主数据库的IP地址;
master_port:主数据库的运行端口;
master_user:在主数据库创建的用于同步数据的用户账号 (搭建主服务器容器实例3307下的步骤6);
master_password:在主数据库创建的用于同步数据的用户密码(搭建主服务器容器实例3307下的步骤6);
master_log_file:指定从数据库要复制数据的日志文件,(搭建从服务器容器实例3308下的步骤5,结果中的File参数)
master_log_pos:指定从数据库从哪个位置开始复制数据,(搭建从服务器容器实例3308下的步骤5,结果中的Position参数)
master_connect_retry:连接失败重试的时间间隔,单位为秒。
***注:此处需要防火墙开放3307端口,否则将会导致开启同步失败***
9.在从数据库(2.阿里云)中查看主从同步状态
show slave status \G;

10.在从数据库(2.阿里云)中开启主从同步
start slave;
11.再次在从数据库(2.阿里云)中查看主从同步状态
show slave status \G;

注:如果出现 Slave_IO_Running: No 的情况可参
参考此处
本文出现此问题后,是将auto.cnf删除后重启,重启之后,搭建从服务器容器实例3308下的步骤5,结果中的File参数,Position参数都会改变,需要从新获取
-测试是否搭建成功
1.在主数据库(1.阿里云)中创建数据库db01,新建表user
##创建数据库
create database dbo1;
## 使用数据库
use dbo1;
##创建user表
create table user (id int , name varchar(20));
##添加数据
insert into user values(1,'zs');
##查询数据
select * from user;
2.在从数据库(2.阿里云)中查看是否同步成功
## 使用数据库
use dbo1;
##查询数据
select * from user;

至此搭建成功!!!
- 结合SpringBoot实现读写分离
master负责写入数据,slave负责读取数据。怎么实现呢?
读写分离就可以使用ShardingSphere-JDBC实现。ShardingSphere-JDBC定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
此处以springBoot+myBatis+druid作为环境进行演示
- 导入依赖
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
4.1.1
- 编写配置(结合上文这里配置的是一主一从,一组多从,可参见下面)
# 这是使用druid连接池的配置,其他的连接池配置可能有所不同
spring:
shardingsphere:
datasource:
names: master,slave
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://123.56.103.93:3307/dbo1?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: root
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://123.56.103.93:3308/dbo1?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: root
props:
sql.show: true
sharding:
master-slave-rules:
master:
master-data-source-name: master##标明master为主库
slave-data-source-names: slave##标明slave为从库
一主两从的配置(可做参考):
# 这是使用druid连接池的配置,其他的连接池配置可能有所不同
spring:
shardingsphere:
datasource:
names: master,slave0,slave1
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://123.56.103.93:3307/dbo1?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: root
slave0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://123.56.103.93:3308/dbo1?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: root
slave1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://123.56.103.93:3309/dbo1?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: root
props:
sql.show: true
masterslave:
load-balance-algorithm-type: round_robin ##配置路由策略,round_robin表示轮询策略
sharding:
master-slave-rules:
master:
master-data-source-name: master ##标明master为主库
slave-data-source-names: slave0,slave1 ##标明slave0,slave1 为从库
3.编写TestMapper.xml
<!--将数据添加到主库-->
<insert id="addTest">
INSERT INTO user ( id, name )
VALUES
( 3, 'zs' );
</insert>
<!-- 在从库中读取数据-->
<select id="selectTest" resultType="map">
select * from user;
</select>
4.编写controller
@Autowired
TestMapper test;
@GetMapping("/addTest")
public void addTest() {
test.addTest();
}
@GetMapping("/selectTest")
public void selectTest() {
System.out.println("结果--》》"+test.selectTest());
}
5.测试结果
测试添加数据

测试读取数据
此处为了突出数据是从,从库中读取出来的,我们手动将从库的数据进行修改

查询语句
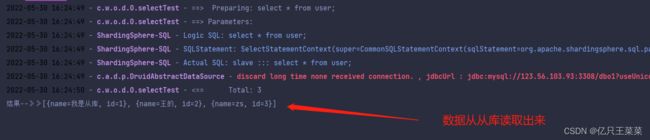
- 出现的问题
1.出现java.lang.IllegalArgumentException: Property 'sqlSessionFactory'异常
解决方案:
移除druid-spring-boot-starter依赖,即:
<!-- <dependency>-->
<!-- <groupId>com.alibaba</groupId>-->
<!-- <artifactId>druid-spring-boot-starter</artifactId>-->
<!-- <version>1.1.10</version>-->
<!-- </dependency>-->
添加如下依赖:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.10</version>
</dependency>
2.出现InvalidDataAccessApiUsageException: ConnectionCallback; isValid; nested exception is java.sql.SQLFeatureNotSupportedException: isValid异常
解决方案:
创建如下配置类
import org.springframework.beans.factory.ObjectProvider;
import org.springframework.boot.actuate.autoconfigure.jdbc.DataSourceHealthContributorAutoConfiguration;
import org.springframework.boot.actuate.health.AbstractHealthIndicator;
import org.springframework.boot.actuate.jdbc.DataSourceHealthIndicator;
import org.springframework.boot.jdbc.metadata.DataSourcePoolMetadataProvider;
import org.springframework.context.annotation.Configuration;
import org.springframework.util.StringUtils;
import javax.sql.DataSource;
import java.util.Map;
/**
* @Description: 数据源配置
*/
@Configuration
public class DataSourceHealthConfig extends DataSourceHealthContributorAutoConfiguration {
public DataSourceHealthConfig(Map<String, DataSource> dataSources, ObjectProvider<DataSourcePoolMetadataProvider> metadataProviders) {
super(dataSources, metadataProviders);
}
@Override
protected AbstractHealthIndicator createIndicator(DataSource source) {
DataSourceHealthIndicator indicator = (DataSourceHealthIndicator) super.createIndicator(source);
if (!StringUtils.hasText(indicator.getQuery())) {
indicator.setQuery("select 1");
}
return indicator;
}
}