ElasticSearcho从入门到放弃:(二)操作, 编程, 架构原理, ES SQL
文章目录
- 一、操作:
-
- 1. 创建索引
-
- 1.1 创建带有映射的索引:
- 1.2 字段类型
- 1.3 创建保存"职位"信息的索引
- 1.4 查看索引映射
- 1.5 查看ES中素有索引
- 1.6 删除索引
- 1.7 指定使用IK分词器
- 2. 使用PUT添加一条数据
-
- 2.1 添加一条职位信息
- 3 修改数据
-
- 3.1 执行update操作
- 4. 删除操作
- 5. 批量导入json数据
-
- 5.1 bulk导入:
- 6. 查看索引状态
- 7. 检索:
-
- 7.1 根据ID检索数据
- 7.2 根据关键字搜索
- 7.3 根据关键分页搜索
-
- 7.3.1 使用from和size来进行分页
- 7.3.2 使用scroll方式进行分页
- 二、编程:
- 三、架构原理:
-
- 1. 节点类型
-
- 1.1 Master节点:
- 1.2 DataNode节点
- 2. 分片和副本机制
-
- 2.1 分片(shard)
- 2.2 副本:
- 2.3 创建带有分片的索引
- 3. 重要工作流程
-
- 3.1 es文档写入原理
- 3.2 es检索原理
- 4. 准实时索引实现:
-
- 4.1 溢写到文件系统缓存
- 4.2 写translog保障容错
- 4.3 flush到磁盘
- 4.4 segment合并
- 四、ES SQL:
-
- 1. sql与es对应关系
- 2. ES SQL语法:
- 3. 职位查询案例
-
- 3.1 查询职位索引库的一条记录
- 3.2 将sql转换成DSL
- 3.3 职位scroll分页查询
-
- 3.3.1 第一次查询
- 3.3.2 第二次查询
- 3.3.3 清楚游标:
- 3.4 职位全文检索
-
- 3.4.1 MATCH函数
- 3.4.2 实现
- 4 订单统计分析案例:
-
- 4.1 案例介绍
- 4.2 创建索引
- 4.3 添加数据
- 4.4 统计不同支付方式的订单数量
-
- 4.4.1 使用JSON DSL的方式来实现
- 4.4.2 基于es SQL方式实现
- 4.5 统计不同支付方式订单数, 并按照订单数量倒序排序
- 4.6 统计不同用户的订单数量, 总订单金额
- 5. ES SQL目前的一些限制
一、操作:
1. 创建索引
为了能够搜索数据, 需要提前在ES中创建索引, 然后才能进行关键字的检索;
在ES中, 也可以使用mysql中创建一个表, 指定表名, 列, 列属性的方式;
1.1 创建带有映射的索引:
ES中, 可以使用RESTful APi来进行索引的各种操作;
创建mysql表时, 使用DDL来描述表结构, 字段, 字段类型,约束等; 在ES中, 使用DSL来定义
PUT /mysql-index
{
"mappings": {
"properties" {
"employee-id": {
"type": "keyword",
"index": false
}
}
}
}

1.2 字段类型
| 分类 | 类型名称 | 说明 |
|---|---|---|
| 简单类型 | text | 需要进行全文检索的字段; 通常使用text类型来对应邮件正文、产品描述或短文等非结构化文本数据; 分词器先会将文本进行分词转换为词条列表; 将来就可以基于词条进行检索了; 文本字段不能用户排序, 也很少聚合计算; |
| keyword | 使用keyword来对应结构化的数据, 如ID,、电子邮件地址、主机名、状态码、标签等; 可以使用keyword来进行排序和聚合计算; 注意: keyword是不能进行分词的; |
|
| long/integer/short/byte | 64位整数/32位整数/16位整数/8位整数 | |
| double | float | |
| boolean | true / false | |
| ip | Ipv4 / ipv6 | |
| json分层嵌套类型 | object | 用于保存json对象 |
| nested | 用于保存json数组 | |
| 特殊类型 | geo_point | 用于保存经纬度坐标 |
| geo_shape | 用于保存地图上多边形坐标 |
1.3 创建保存"职位"信息的索引
ps: 判断使用text还是keyword, 主要看是否需要分词
| 字段 | 说明 | 类型 |
|---|---|---|
| doc_id | 唯一标识(作为文档ID) | keyword |
| area | 职位所在区域 | keyword |
| exp | 岗位要求的工作经验 | text |
| edu | 学历要求 | keyword |
| salary | 薪资范围 | keyword |
| job_type | 职位类型(全职/兼职/实习) | keyword |
| cmp | 公司名 | text |
| pv | 浏览量 | keyword |
| title | 岗位名称 | text |
| jd | 职位描述 | text |
PUT /job_idx
{
"mappings": {
"properties": {
"area": { "type": "text", "store": true },
"exp": { "type": "text", "store": true },
"edu": { "type": "keyword", "store": true },
"salary": { "type": "keyword", "store": true },
"job_type": { "type": "keyword", "store": true },
"cmp": { "type": "text", "store": true },
"pv": { "type": "keyword", "store": true },
"title": { "type": "text", "store": true },
"jd": { "type": "text", "store": true }
}
}
}
result:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "job_idx"
}
1.4 查看索引映射
使用Get请求查看索引映射
GET /job_idx/_mapping
result:
{
"job_idx": {
"mappings": {
"properties": {
"area": {
"type": "text",
"store": true
},
"cmp": {
"type": "text",
"store": true
},
"edu": {
"type": "keyword",
"store": true
},
"exp": {
"type": "text",
"store": true
},
"jd": {
"type": "text",
"store": true
},
"job_type": {
"type": "keyword",
"store": true
},
"pv": {
"type": "keyword",
"store": true
},
"salary": {
"type": "keyword",
"store": true
},
"title": {
"type": "text",
"store": true
}
}
}
}
}
1.5 查看ES中素有索引
GET _cat/indices
result:

1.6 删除索引
DELETE /job-idx
result:
{
"acknowledged": true
}
1.7 指定使用IK分词器
因为存放在索引库中的数据, 是以中文的形式存储的, 所以, 使用Ik分词器
PUT /job_idx
{
"mappings": {
"properties": {
"area": { "type": "text", "store": true, "analyzer": "ik_max_word" },
"exp": { "type": "text", "store": true, "analyzer": "ik_max_word" },
"edu": { "type": "keyword", "store": true },
"salary": { "type": "keyword", "store": true },
"job_type": { "type": "keyword", "store": true },
"cmp": { "type": "text", "store": true, "analyzer": "ik_max_word" },
"pv": { "type": "keyword", "store": true },
"title": { "type": "text", "store": true, "analyzer": "ik_max_word" },
"jd": { "type": "text", "store": true, "analyzer": "ik_max_word" }
}
}
}
2. 使用PUT添加一条数据
在es中, 每一个文档都有唯一的ID, 也是使用json格式来描述数据的;
PUT /customer/_doc/1
{
"name": "John"
}

- 如果在costomer中, 不存ID为1的文档, ES会自动创建
2.1 添加一条职位信息
PUT /job_idx/_doc/29097
{
"area": "深圳-南山区",
"exp": "一年经验",
"edu": "本科及以上",
"salary": "8-12K/月",
"job_type": "实习",
"cmp": "乐有家",
"pv": "618万人浏览过/14人评价/113人正在关注",
"title": "桃园 深大销售实习 岗前培训",
"jd": "这是一个 桃园 深大销售实习 岗前培训的职位描述, 一些乱七八在的说明, 我没有文档, 懒得手打了"
}
result:
{
"_index": "job_idx",
"_id": "29097",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
3 修改数据
3.1 执行update操作
POST /job_idx/29097
{
"doc": {
"salary": "80-120k/月"
}
}
result:
{
"_index": "job_idx",
"_id": "29097",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
4. 删除操作
DELETE /job_idx/_doc/29097
result:
{
"_index": "job_idx",
"_id": "29097",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
5. 批量导入json数据
5.1 bulk导入:
es提供了bulk接口, 用来批量导入json文件中的数据
curl -H "Content-Type:application/json" -XPOST "localhost:9200/job_idx/bulk?pretty&refresh" --data-binary "@job_info.json"
6. 查看索引状态
GET /_cat/indices?index=job_idx

7. 检索:
7.1 根据ID检索数据

GET /job_idx/_search
{
"query": {
"ids": {
"values": ["29097"]
}
}
}
result:
{
"took": 47,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "job_idx",
"_id": "29097",
"_score": 1.0,
"_source": {
"area": "深圳-南山区",
"exp": "一年经验",
"edu": "本科及以上",
"salary": "80-120k/月",
"job_type": "实习",
"cmp": "乐有家",
"pv": "618万人浏览过/14人评价/113人正在关注",
"title": "桃园 深大销售实习 岗前培训",
"jd": "这是一个 桃园 深大销售实习 岗前培训的职位描述, 一些乱七八在的说明, 我没有文档, 懒得手打了"
}
}
]
}
}
7.2 根据关键字搜索
检索jd中"销售"相关的岗位
GET /job_idx/_search
{
"query": {
"match": {
"jd": "销售"
}
}
}
result:
{
"took": 49,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "job_idx",
"_id": "29097",
"_score": 0.2876821,
"_source": {
"area": "深圳-南山区",
"exp": "一年经验",
"edu": "本科及以上",
"salary": "80-120k/月",
"job_type": "实习",
"cmp": "乐有家",
"pv": "618万人浏览过/14人评价/113人正在关注",
"title": "桃园 深大销售实习 岗前培训",
"jd": "这是一个 桃园 深大销售实习 岗前培训的职位描述, 一些乱七八在的说明, 我没有文档, 懒得手打了"
}
}
]
}
}
官方网站视频课: https://www.elastic.co/cn/webinars/getting-started-elasticsearch?baymax=rtp&elektra=doc&storm-top-video&iesrc=ctr
7.3 根据关键分页搜索
在存在大量数据时, 一般进行查询都需要进行分页查询;
7.3.1 使用from和size来进行分页
在执行查询时, 可以指定from(从第n个开始)和size(每页返回多少条)来完成分页
GET /job_idx/_search
{
"from": 0,
"size": 5,
"query": {
"multi_match": {
"query": "销售",
"fields": ["title", "jd"]
}
}
}
ps:
- from = (page-1) *size
7.3.2 使用scroll方式进行分页
使用from和size方式, 查询1w-5w条数据以内是ok的, 但是, 如果数据比较多的时候, 会出现性能问题; ES做了一个限制, 不允许查询超过1w条以后的数据, 如果要查询, 需要使用ES中提供的scoll(游标)来查询;
在进行大量分页时, 每次分页都需要将要查询的数据进行重新排序, 这样非常浪费性能;
使用scoll是将要用的数据一次性排序好, 然后分批取出; 性能要比from+size好很多;
使用scroll查询后, 排序后数据会保持一段时间, 后续分页查询都从该快照取数据;
使用scoll是为了解决深分页的性能问题
第一次使用scroll分页查询
此处, 让排序数据保持1分钟
GET /job_idx/_search?scroll=1m
{
"size": 100,
"query": {
"multi_match": { // 检索多个字段
"query": "销售",
"fields": ["title", "jd"]
}
}
}
result:
{
"_scroll_id": "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFk9TSmltZ2kxU1hlbHVJcHd3dEphUXcAAAAAAAAAWBY1Ymo4VGlzclI4V0dzc0x6aXZsczNR",
"took": 29,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821,
"hits": [
{
"_index": "job_idx",
"_id": "29097",
"_score": 0.2876821,
"_source": {
"area": "深圳-南山区",
"exp": "一年经验",
"edu": "本科及以上",
"salary": "80-120k/月",
"job_type": "实习",
"cmp": "乐有家",
"pv": "618万人浏览过/14人评价/113人正在关注",
"title": "桃园 深大销售实习 岗前培训",
"jd": "这是一个 桃园 深大销售实习 岗前培训的职位描述, 一些乱七八在的说明, 我没有文档, 懒得手打了"
}
}
]
}
}
返回值中有
"_scroll_id": "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFk9TSmltZ2kxU1hlbHVJcHd3dEphUXcAAAAAAAAAWBY1Ymo4VGlzclI4V0dzc0x6aXZsczNR",
后续, 需要根据这个_scroll_id来进行查询
第二次查询
GET /job_idx/_search?scroll=1m
{
"scroll_id": "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFk9TSmltZ2kxU1hlbHVJcHd3dEphUXcAAAAAAAAAWBY1Ymo4VGlzclI4V0dzc0x6aXZsczNR"
}
二、编程:
三、架构原理:
1. 节点类型
在ES中有两类节点, 一类是Master, 一类是DataNode
1.1 Master节点:
在es启动时, 会选举出来一个master节点;
当某个节点启动后, 使用Zen Discovery机制找到集群中的其他节点, 并建立连接;
discovery.seed_hosts: [ "node1", "node2", "node3" ]
并从候选主节点中选举出一个主节点:
cluster.initial_master_nodes: [ "node1", "node2" ]
Master节点主要责任:
- 管理索引(创建索引, 删除索引), 分配分片;
- 维护元数据
- 管理集群节点状态;
- 不负责数据写入和查询, 比较轻量级;
一个ES集群中, 只有一个Master节点; 在生产环境中, 内存可以相对小一点, 但机器要稳定;
1.2 DataNode节点
在ES集群中, 会有N个DataNode节点; DataNode节点主要负责:
- 数据写入, 数据检索表, 大部分ES的压力都在DataNode节点上;
- 在生产环境中, 内存最好配置大一些;
2. 分片和副本机制
2.1 分片(shard)
- ES是一个分布式的搜索引擎, 索引的数据也是分成若干部分, 分布在不同的服务器节点中;
- 分布在不同服务器节点中的索引数据, 就是分片(shard); ES会自动管理分片, 如果发现分片不均衡, 会自动迁移;
- 一个索引(index)由多个分片(shard)组成, 而分片是分布在不同的服务器上的;
2.2 副本:
为了对ES的分片进行管理, 假设某个节点不可用, 会导致整个索引库都将不可用; 所以, 需要对分片进行副本容错;
每一个分片都会有对应的副本;
在ES中, 默认创建的索引为1个分片, 每个分片有1个主分片和1个副本分片;
- 每个分片都会有一个Primary Shard(主分片), 也会有若干个Replica Shard(副本分片);
- Primary Shard和Replica Shard不在同一个节点上;
2.3 创建带有分片的索引
PUT /job_idx_shard
{
"mappings": {
"properties": {
"area": { "type": "text", "store": true },
"exp": { "type": "text", "store": true },
"edu": { "type": "keyword", "store": true },
"salary": { "type": "keyword", "store": true },
"job_type": { "type": "keyword", "store": true },
"cmp": { "type": "text", "store": true },
"pv": { "type": "keyword", "store": true },
"title": { "type": "text", "store": true },
"jd": { "type": "text", "store": true }
}
},
"settings": {
"number_of_shards": 3, // 有三个分片
"number_of_replicas": 2 // 每个分片还有2个副本分片
}
}

3. 重要工作流程
3.1 es文档写入原理

- 选择任意一个DataNode发送请求, 例如: node2; 此时, node2就成为一个coordinate node(协调节点);
- 计算得到文档要写入的分片:
shard = hash(routing) % number_of_primary_shards- routing是一个可变值, 默认是文档的
_id
- coordinate node 会警醒路由, 经请求转发给对应的parimary shard所在的DataNode(假设primary shard在node1, replica shard在node2);
- node1节点上的primary shard处理请求, 写入数据到索引中, 并将数据同步到replica shard;
- primary shard 和 Replica Shard都保存好了文档, 返回client
3.2 es检索原理
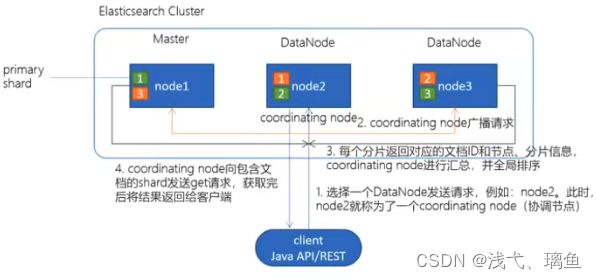
- client发起查询请求, 某个DataNode接收到请求, 该DataNode就会成为协调节点;
- 协调节点将查询请求广播到每个数据节点, 这些数据节点的分片会处理该查询请求; 协调节点会轮询所有的分片来自动进行负载均衡;
- 每个分片进行数据查询, 将符合条件的数据放在一个优先队列中, 并将这些数据的文档ID, 节点信息, 分片信息返回给协调节点;
- 协调节点将所有的结果进行汇总, 并进行全局排序;
- 协调节点向包含这些文档id的分片发送get请求, 对应分片将文档数据返回给协调节点, 最后协调节点将数据返回给客户端;
es有一个协调器节点, 负责对应的请求路由;
es集群的节点都是互相连接的;
4. 准实时索引实现:
4.1 溢写到文件系统缓存
- 当数据写入到ES分片时, 会首先写入到内存中, 然后通过内存的buffer生成一个segment, 并刷到文件系统缓存中, 数据可以被检索(ps: 不是直接刷到磁盘);
- ES中默认1秒refresh一次;
- 数据格式就是基于Lucence的segment;
4.2 写translog保障容错
- 在写入到内存中的同时, 也会记录translog日志, 在refresh期间出现异常, 会根据translog来进行数据恢复;
- 等到文件系统缓存中的segment数据都刷到磁盘中, 清空translog文件;
4.3 flush到磁盘
- es默认每隔30分钟会将文件系统缓存的数据刷入到磁盘;
4.4 segment合并
- segment太多时, ES定期会将多个segment合并成大的segment, 减少索引查询时IO开销, 此阶段ES会真正的物理删除(之 前执行过的delete的数据)
四、ES SQL:
Elasticsearch SQL允许执行类SQL的查询, 可以使用REST接口, 命令行或者JDBC, 都可以使用SQL来进行数据的检索和数据的聚合;
Elasticsearch SQL特点:
- 本地集成:
- Es SQL是专门为ES构建的; 每个查询都是根据底层存储对相关节点有效执行;
- 没有额外的要求:
- 不依赖其他的硬件, 进程, 运行时库, ES SQL可以直接运行在ES集群上;
- 轻量高效:
- 像SQL那样简洁, 高效地完成查询;
1. sql与es对应关系
| SQL | ES |
|---|---|
| column(列) | field(字段) |
| row(行) | document(文档) |
| table(表) | index(索引) |
| schema(模式) | N/A |
| database(数据库) | ES集群实例 |
2. ES SQL语法:
SELECT select_expr [, ...]
[ FROM table_name ]
[ WHERE condition ]
[ GROUP BY grouping_element [, ...] ]
[ HAVING condition ]
[ ORDER BY expression [ ASC | DESC ] [, ...]]
[ LIMIT [ count ] ]
[ PIVOT (aggregation_expr FOR column IN ( value [ [ AS ] alias ] [, ...] )) ]
FROM只支持单表;
3. 职位查询案例
3.1 查询职位索引库的一条记录
GET /_sql?format=txt
{
"query": "SELECT * FROM job_idx limit 1"
}
format: 表示指定返回的数据类型
除了txt, 还支持
| 格式 | 描述符 |
|---|---|
| csv | 逗号分隔 |
| json | json格式 |
| tsv | 制表符分隔 |
| txt | |
| yaml | yaml格式 |
area | cmp | edu | exp | jd | job_type | pv | salary | title
---------------+---------------+---------------+---------------+-------------------------------------------------+---------------+-----------------------+---------------+---------------
深圳-南山区 |乐有家 |本科及以上 |一年经验 |这是一个 桃园 深大销售实习 岗前培训的职位描述, 一些乱七八在的说明, 我没有文档, 懒得手打了|实习 |618万人浏览过/14人评价/113人正在关注|80-120k/月 |桃园 深大销售实习 岗前培训
3.2 将sql转换成DSL
GET /_sql/translate
{
"query": "SELECT * FROM job_idx limit 1"
}
{
"size": 1,
"_source": false,
"fields": [
{
"field": "area"
},
{
"field": "cmp"
},
{
"field": "edu"
},
{
"field": "exp"
},
{
"field": "jd"
},
{
"field": "job_type"
},
{
"field": "pv"
},
{
"field": "salary"
},
{
"field": "title"
}
],
"sort": [
{
"_doc": {
"order": "asc"
}
}
]
}
3.3 职位scroll分页查询
3.3.1 第一次查询
GET /_sql?format=json
{
"query": "SELECT * FROM job_idx",
"fetch_size": 10
}
fetch_size: 表示每页显示多少数据, 而且指定format为JSON时, 会返回一个cursor ID
{
"columns": [
......
],
"rows": [
......
],
"cursor": "1/PoA0RGTABUjN9rgzAcxI1t9+Np/4oRHfi40ho2qFDXRpOXkZo4Vr+iaGyj/7wdA1m9t7vP3SGOWhMS6JhrMCc0Z27QSUI9GQZYJlBs0hDz9MPfJ34Rl9Rh7vc6BIlPJPIPpI6OwOHoUPF5YNcdbN0Etm+T0phhVlYeJTBk8O5RRw6ZY15FyttsiOLxVy/PKF+KRgm01Mpoy0L5IivrO6dkhx4L1V+rRv5hZe6wfZb/3adzdfrSfa1mA7u+zPxDK0A0/Sxb6R8NanqyR3QDAAD//wMA"
}
默认快照的失效时间为45s, 如果要延迟快照时间, 可以进行如下配置
GET /_sql?format=json
{
"query": "SELECT * FROM job_idx",
"fetch_size": 10,
"page_timeout": "10m"
}
3.3.2 第二次查询
GET /_sql?format=json
{
"cursor": "1/PoA0RGTABUjN9vgjAcxC26Hz7tX6EETHicUZotGcmcFtqXpdKigy+BQJmFf16XJUS4t7vP3SGOGhMQaJljMCc0ZY7fSkJdGfhYRpBv4gDz+N37jLx8V1CbOad1ABIfSejtSRUegMPBpuJrzy4fsHUi2L4Ois8Ms6J0KYE+gTeX2rJPbLMSMW+SPtxd//SyROlC1EqghVZGz2YonSdFNXJKtugpV92lrOU/VmaErUzeu89ZefzWXaUmA6v6nfjHRoCou0n2oH80qOHJuqIbAAAA//8DAA=="
}
{
"rows": [
......
],
"cursor": "1/PoA0RGTABUjN9vgjAcxC26Hz7tX6EETHicUZotGcmcFtqXpdKigy+BQJmFf16XJUS4t7vP3SGOGhMQaJljMCc0ZY7fSkJdGfhYRpBv4gDz+N37jLx8V1CbOad1ABIfSejtSRUegMPBpuJrzy4fsHUi2L4Ois8Ms6J0KYE+gTeX2rJPbLMSMW+SPtxd//SyROlC1EqghVZGz2YonSdFNXJKtugpV92lrOU/VmaErUzeu89ZefzWXaUmA6v6nfjHRoCou0n2oH80qOHJuqIbAAAA//8DAA=="
}
3.3.3 清楚游标:
POST /_sql/close
{
"cursor": "1/PoA0RGTABUjN9vgjAcxC26Hz7tX6EETHicUZotGcmcFtqXpdKigy+BQJmFf16XJUS4t7vP3SGOGhMQaJljMCc0ZY7fSkJdGfhYRpBv4gDz+N37jLx8V1CbOad1ABIfSejtSRUegMPBpuJrzy4fsHUi2L4Ois8Ms6J0KYE+gTeX2rJPbLMSMW+SPtxd//SyROlC1EqghVZGz2YonSdFNXJKtugpV92lrOU/VmaErUzeu89ZefzWXaUmA6v6nfjHRoCou0n2oH80qOHJuqIbAAAA//8DAA=="
}
{
"succeeded": true
}
3.4 职位全文检索
3.4.1 MATCH函数
在执行全文检索时, 需要使用到match函数
MATCH(
field_exp,
constant_exp,
[, options]
)
field_exp: 匹配字段;
constant_exp: 匹配常量表达式
3.4.2 实现
检索 title和jd中包含hadoop
GET /_sql?format=txt
{
"query": "select * from job_idx where MATCH(title, 'hadoop') or MATCH(jd, 'hadoop') limit 10"
}

4 订单统计分析案例:
4.1 案例介绍
有以下数据集
| 订单ID | 订单状态 | 支付金额 | 支付方式 | 用户ID | 操作时间 | 商品分类 |
|---|---|---|---|---|---|---|
| id | status | pay_money | pay_way | userid | operation_date | category |
| 1 | 已提交 | 4070 | 1 | 4944 | 2020-04-25 12:09:16 | 手机 |
| 2 | 已提交 | 4350 | 1 | 1625 | 2020-04-25 12:09:37 | 家用电器;电脑 |
| 3 | 已提交 | 6370 | 3 | 3919 | 2020-04-25 12:09:39 | 男装;男鞋 |
| 4 | 已付款 | 6370 | 3 | 3919 | 2020-04-25 12:09:44 | 男装;男鞋 |
基于类似数据, 使用ES中聚合统计功能, 实现一些指标统计
4.2 创建索引
PUT /order_idx
{
"mappings": {
"properties": {
"id": {
"type": "keyword",
"store": true
},
"status": {
"type": "keyword",
"store": true
},
"pay_money": {
"type": "double",
"store": true
},
"payway": {
"type": "byte",
"store": true
},
"userid": {
"type": "keyword",
"store": true
},
"operation_date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss",
"store": true
},
"category": {
"type": "keyword",
"store": true
}
}
}
}
4.3 添加数据
{
"id": "1",
"status": "已提交",
"pay_money": 4070.0,
"payway":1,
"userid": "4944",
"operation_date": "2020-04-25 12:09:16",
"category": "手机"
}
{
"id": "2",
"status": "已提交",
"pay_money": 4350.0,
"payway":1,
"userid": "1625",
"operation_date": "2020-04-25 12:09:37",
"category": "家用电器;电脑"
}
{
"id": "3",
"status": "已提交",
"pay_money": 6370.0,
"payway":3,
"userid": "3919",
"operation_date": "2020-04-25 12:09:39",
"category": "男装;男鞋"
}
{
"id": "4",
"status": "已付款",
"pay_money": 6370.0,
"payway":3,
"userid": "3919",
"operation_date": "2020-04-25 12:09:44",
"category": "男装;男鞋"
}
4.4 统计不同支付方式的订单数量
4.4.1 使用JSON DSL的方式来实现
GET /order_idx/_search
{
"size": 0,
"aggs": {
"group_by_status": {
"terms": {
"field": "payway"
}
}
}
}
结果:
{
"took": 872,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"group_by_status": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 1,
"doc_count": 2
},
{
"key": 3,
"doc_count": 2
}
]
}
}
}
4.4.2 基于es SQL方式实现
GET _sql?format=txt
{
"query": "select payway, count(*) from order_idx group by payway"
}
结果:
payway | count(*)
---------------+---------------
1 |2
3 |2
GET _sql?format=json
{
"query": "select payway, count(*) cnt from order_idx group by payway"
}
结果
{
"columns": [
{
"name": "payway",
"type": "byte"
},
{
"name": "cnt",
"type": "long"
}
],
"rows": [
[
1,
2
],
[
3,
2
]
],
"cursor": "1/PoA0RGTABijGJMZuTML0pJLYrPTKkoZGTkTM7PLcgvzixJZU8vyi8tSKpkYPjPyMBhbmBhmJRqYsjIVpBYWZ4IFGVkYGB4wc7IxQiXYwKKgAAzAxNIEqgRCPihgmCKcQsjUBKmjoELooKJMRtuBlANgsPIAFQOAAAA//8DAA=="
}
4.5 统计不同支付方式订单数, 并按照订单数量倒序排序
GET /_sql?format=txt
{
"query": "select payway, count(*) as order_cnt from order_idx where status='已付款' group by payway order by order_cnt desc"
}
4.6 统计不同用户的订单数量, 总订单金额
GET /_sql?format=txt
{
"query": "select userid, count(1) as cnt, sum(pay_money) as total from order_idx group by userid"
}
结果
userid | cnt | total
---------------+---------------+---------------
1625 |1 |4350.0
3919 |2 |12740.0
4944 |1 |4070.0
5. ES SQL目前的一些限制
目前es sql还存在一些限制, 比如: 不支持join, 不支持较复杂的子查询; 所以, 一些相对复杂的功能, 还得借助DSL方式来实现;
其他使用: https://blog.csdn.net/zhenghongcs/article/details/110412594