rocksdb设计架构
rocksdb是什么
rocksdb是一个kv(key和value作为一条数据,一般key用于查询,value存储数据)存储引擎,常用于数据库存储数据。rocksdb的编译产物是动态库,无法直接使用,没有提供sql命令,一般需要在程序中调用rocksdb提供的api进行对数据库的读写等操作。
rocksdb是以leveldb为基础开发的,都使用了LSM Tree来存储数据。rocksdb的主要设计目标是满足使用需求的同时,提供高性能的存储,相比leveldb提供了很多额外的特性,优化性能。
rocksdb提供了很多的参数配置,所以非常灵活,调整参数后可以适用于不同的硬件平台、软件需求。但也对参数的设置要求比较高,使用默认的配置可能比较使用常见的硬件配置,特殊的需求(例如要求使用很低的内存/需要更高的写入性能/需要更高的读取性能/较低的硬盘空间占用)需要进一步调整配置。
想对rocksdb的性能有个初步的了解的,可以参考rocksdb官方的benchmark:https://github.com/facebook/rocksdb/wiki/performance-benchmarks。
一些特性的详细介绍参考:https://github.com/facebook/rocksdb/wiki
LSM Tree
rocksdb基本可以认为就是对LSM Tree的实现,因此LSM Tree对于rocksdb是非常重要的。
LSM Tree的设计可以参考论文:
- 1996, The Log-Structured Merge-Tree (LSM-Tree)
- 2014, A Comparison of Fractal Trees to Log-Structured Merge (LSM) Trees
- 2017, WiscKey: Separating Keys from Values in SSD-conscious Storage, TOS
- 2019, LSM-based Storage Techniques: A Survey
这里简单介绍一下。
in-place/out-of-place
数据的存储方式,可以分为两种:in-place update和out-of-place update,LSM Tree是out-of-place update的方式,而in-place update的典型代表是B+树。
in-place update的方式,进行数据的写入/修改/删除操作时,是会对硬盘上的已有数据进行修改的,例如写入新数据时,为了维护B+树的结构,可能需要进行节点的分裂,另外,为了维护B+树的结构,写入的数据可能分布在不同的位置,会有比较多的随机io。
out-of-place update的意思,就是说进行数据的写入/修改/删除操作时,并不对硬盘上的已有数据进行修改,而是先在内存中进行记录(写入/修改就记录数据内容,删除就记录需要删除的key),在达到一定的数据量后,生成一个新的文件,所以硬盘中可能同时存在新的和旧的数据(一般kv存储要求key是唯一的,新写入key0 value1后,旧的key0 value0应当失效,删除掉旧的数据,或者使其无法被读取出来)。为了避免占用的硬盘空间不停上升,以及存在重复数据导致的搜索效率下降,需要定期/不定期的处理重复数据,LSM Tree的处理方法是执行compaction,即选择一些文件进行合并,删除重复的数据后,生成新的不包含重复内容的文件。由于写入和compaction时,写入的都是完整的文件,所以随机io很少,都HDD和SSD来说是比较友好的。但是由于存在compaction操作,一个数据可能被重复读写多次,所以会造成执行io的数据量比实际写入的数据量要大几倍甚至几十倍,也就是写放大问题。
compaction
compaction是LSM Tree进行数据维护的核心工作,compaction的执行主要分为两种策略:Leveling Merge Policy和Tiering Merge Policy,"LSM-based Storage Techniques: A Survey"中对这两种方法进行了理论分析以及对比:

大致就是Leveling策略长于读取和空间,短于写入。
说明一下图中的符号:T表示Ln+1的数据量是Ln的T倍,L表示level的数量,B表示page size,大概是指读写数据的单位。
T的常见值是10,那么Leveling的读放大、空间放大大致是Tiering的1/10,写放大则是Tiering的10倍。
而L的大小则与数据量有关,数据量越大,则需要的L越大。
对于leveling compaction的执行过程简单介绍一下,图片来自"LSM-based Storage Techniques: A Survey":

leveling策略下,数据将会被拆分成多个level,level越高,其中包含的数据量就越大。数据量之间的关系都不是固定的,可以调整。
图中的是partitioned策略,也就是每个level中的文件会被拆分成多个文件,最初的设计中,一个level中是一个大文件。
执行compaction时,首先根据配置(level的最大数据量)以及优先级策略,选择需要执行compaction的文件(超出level数据量上限的level中选择一个文件),将该文件合并到下一个level。下一个level中需要合并的文件,是与触发compaction的文件有重叠的文件,例如图中选择了level1的0-30文件,level2中与0-30有重叠的文件是0-15和16-32,这三个文件执行compaction,去重后生成新的文件:0-10,11-19和20-32。
简单分析一下写放大。以上图为例,假设T设置的是10,也就是说,level2的数据量是level1的10倍,那么如果数据比较随机,且level1和level2的数据范围都是0-100,0-30执行compaction时,选择了level2中与0-30有重叠的数据,数据量应该大致是0-30这个文件的10倍,所以这里就有了10倍的写放大,当然同时还有有从level2中读取数据的开销,所以io资源的消耗是不止10倍的。而如果level的数量更多,从level2合并到level3时,还会有10倍的写放大。每个数据在一个level中,只会往更高的level进行compaction一次,所以放大倍数就是大致累加,最终的写放大,大致就是T*L。
另外,level0是比较特殊的,有几个不同点:1.是从内存中直接写入的,写入时生成一个新文件。多个文件之间,是允许数据存在重叠/重复的。其他level的不同文件是没有重叠的。2.进行compaction时,level0中的所有文件是一起进行compaction的,这样有利于降低写放大。
时序数据
上面说到,Leveling策略的写放大是T*L,这是对随机数据而言。对一些特殊的数据,例如时序数据,是不会有这么大的。
原因是进行compaction时,从低level合并到高level时,重叠的数据并不多,如果时序做的好,甚至一点也没有重叠,需要合并的数据量自然就少了。
Bloom Filter
Bloom Filter是对查询的优化,可以通过少量的数据来初步判断一个key是否存在于当前文件中,可以准确判断出不存在,但存在可能有误判(即Bloom Filter判断出可能存在,但实际不存在),作为初步的筛选,减少需要读取的文件数量。
基本软件架构
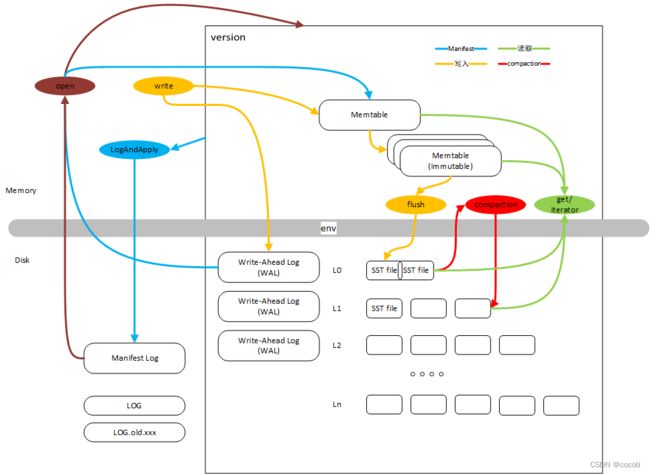
主要的文件
- Memtable 数据写入时,先在内存中进行缓存,不直接写入到硬盘,等到数据量达到一定大小后,再进行写入。
- Write-Ahead Log(WAL) 由于数据写入时先写入Memtable,可能没有落盘,所以断电可能造成数据丢失。为了避免数据丢失,写入时先写到WAL中进行记录再写入Memtable,断电后,重启时通过WAL进行恢复。
- Manifest Log 记录当前的文件列表,可以认为是一个版本,记录该版本中有效数据所存储的文件列表。另外还记录一些必要的信息。
- SST file 存储数据的文件
- LOG 存储调试打印
主要的操作
open 用户触发
读取Manifest Log,获取到文件列表。
读取WAL文件,恢复尚未执行flush的数据。是否已经flush可以通过Manifest Log中存储的信息判断。
加载SST Log的一些信息,例如文件存储的数据范围,Bloom Filter。
put/write 用户触发
写入数据,如果存在多个在执行写入操作的线程,可能会将数据进行合并后一起写入。
首先写入到WAL中,写入完成后,再更新Memtable。
Memtable达到一定大小后,会转换成Immutable Metable,起始就是挂到一个链表上。同时创建一个新的Memtable存储新写入的数据。
flush 后台任务
将Immutable Memtable写入到硬盘中,通过table factory进行格式转换,生成新的level 0中的SST file。
get 用户触发
读取某个特定key的数据。
首先从Memtable和Immutable Memtable中读取,如果能读取到数据则直接返回。
再从L0中读取,这里需要从新到旧遍历所有文件,用Bloom Filter,Index等进行过滤,存在就直接读取返回。
再从L1即以上读取,先通过二分找到可能有该key的文件,再用Bloom Filter,Index等进行过滤,存在则读取返回。
iterator 用户触发
用于范围读取,使用Memtable、所有level的SST构造一个iterator,可以执行seek,找到特定key的位置,然后再进行next操作,顺序读取后续的数据内容。
compaction 后台任务
按照一定的策略,选择需要执行compaction的文件。将这些文件制作成iterator,用于compaction执行过程中的读取。
遍历这个iterator,按顺序读取key value,并生成新的SST Table文件。
delete 后台任务
执行compaction操作时,并不会直接删除旧的文件。有专门的后台任务来进行删除操作。
version的维护 后台任务
文件发生变化时,例如新Memtable、Flush、Compaction操作,都会导致version变化。此时需要在内存中更新version,同时更新硬盘中的Manifest Log。
配置
rocksdb提供了很多的配置,便于对不同的硬件平台、软件需求进行参数调优。
这里对配置进行了一些简单的分类,如下图,配置很多:

从配置中可以引出很多的设计,下面对一些配置做一下简单的介绍,想到哪写到哪,能写多少写多少,不会系统讲解。
写入相关配置
allow_concurrent_memtable_write
讲这个配置之前,有必要先介绍一下memtable的设计。
memtable的生成使用memtable_factory,可以根据需求使用不同的factory,默认是SkipListFactory。
从名字中就可以看出,使用的是skiplist。skiplist的作用类似平衡树,构造了一个有较高插入、搜索效率(单点查询及范围查询)的数据结构,实现上相对平衡树来说简单一些,且设计上能够实现lock free,有利于多线程执行。skiplist的原理可以参考https://zhuanlan.zhihu.com/p/505622643。rocksdb中的实现在skiplist.h文件中。
再说allow_concurrent_memtable_write,使用skiplist并支持多线程并行写入skiplist之后,多线程写入数据时,就可以并行写入memtable,是否允许并行就是通过这个配置设置的。
使用到的地方,就是DBImpl::WriteImpl函数,如果allow_concurrent_memtable_write设置为了true,并且满足了其他一些条件,就会并行写入memtable。设置并行是在LaunchParallelMemTableWriters中,由一起写入的线程中的leader线程调用,将其他follower线程的状态置为了WriteThread::STATE_PARALLEL_MEMTABLE_WRITER,后续就会多线程并行写入memtable了。而如果不允许并行写入的,就会全部由leader负责写入memtable。
enable_write_thread_adaptive_yield
这个配置是一个写入性能的优化。
首先说明一下yield,指的是std::this_thread::yield()函数,作用是将cpu让出给其他线程使用。rocksdb的使用场景是等待一个条件变为true,有几种处理方法:
- 简单的循环判断,占用较高cpu,适用于条件短期内会变成true,且cpu富裕的情况。(short-uncontended)
- 循环判断,每次判断为false后,调用yield释放cpu给其他线程,适用于条件短期内会变成true,但cpu比较紧张的情况。(short-contended)
- 等待条件变量,适用于长时间的等待
rocksdb选择了先1方法处理一段时间,再2方法处理一段时间,再3方法处理的测了。
enable_write_thread_adaptive_yield就是对第二种处理方法的配置,设置为true后才会进行第二种处理。相关的配置还有write_thread_max_yield_usec和write_thread_slow_yield_usec。
代码中对yield的注释说明:
// If we're only going to end up waiting a short period of time,
// it can be a lot more efficient to call std::this_thread::yield()
// in a loop than to block in StateMutex(). For reference, on my 4.0
// SELinux test server with support for syscall auditing enabled, the
// minimum latency between FUTEX_WAKE to returning from FUTEX_WAIT is
// 2.7 usec, and the average is more like 10 usec. That can be a big
// drag on RockDB's single-writer design. Of course, spinning is a
// bad idea if other threads are waiting to run or if we're going to
// wait for a long time. How do we decide?
//
// We break waiting into 3 categories: short-uncontended,
// short-contended, and long. If we had an oracle, then we would always
// spin for short-uncontended, always block for long, and our choice for
// short-contended might depend on whether we were trying to optimize
// RocksDB throughput or avoid being greedy with system resources.
//
// Bucketing into short or long is easy by measuring elapsed time.
// Differentiating short-uncontended from short-contended is a bit
// trickier, but not too bad. We could look for involuntary context
// switches using getrusage(RUSAGE_THREAD, ..), but it's less work
// (portability code and CPU) to just look for yield calls that take
// longer than we expect. sched_yield() doesn't actually result in any
// context switch overhead if there are no other runnable processes
// on the current core, in which case it usually takes less than
// a microsecond.
//
// There are two primary tunables here: the threshold between "short"
// and "long" waits, and the threshold at which we suspect that a yield
// is slow enough to indicate we should probably block. If these
// thresholds are chosen well then CPU-bound workloads that don't
// have more threads than cores will experience few context switches
// (voluntary or involuntary), and the total number of context switches
// (voluntary and involuntary) will not be dramatically larger (maybe
// 2x) than the number of voluntary context switches that occur when
// --max_yield_wait_micros=0.
//
// There's another constant, which is the number of slow yields we will
// tolerate before reversing our previous decision. Solitary slow
// yields are pretty common (low-priority small jobs ready to run),
// so this should be at least 2. We set this conservatively to 3 so
// that we can also immediately schedule a ctx adaptation, rather than
// waiting for the next update_ctx.
memtable相关
大小以及个数配置
这些配置是可以给每个column family单独配置的,每个column family根据这些配置单独管理memtable:
- write_buffer_size —— 单个memtable的大小上限,达到后会转变为immutable memtable,等待flush。
- max_write_buffer_number —— column family中,最多可以使用的memtable个数,包括正在使用的和immutable的,如果已经满了,会造成写stall。
这个是数据库全局的配置:
- db_write_buffer_size —— 这个值默认是0,不启用。设置为一个正数后,作用是限制整个数据库,也就是所有column family,memtable占用内存的大小总和。
整个是可以跨db的配置:
- write_buffer_manager —— 作用类似db_write_buffer_size,但是可以使用同一个write_buffer_manager传给多个db的option,限制的是所有使用了这个wrtie_buffer_manager的db,他们的memtable占用的空间总和。
LSM Tree结构
- num_levels —— 最大的level数量
level0相关配置:
- level0_file_num_compaction_trigger —— 触发compaction的最少文件个数
- level0_slowdown_writes_trigger —— 触发写入降速的文件个数
- level0_stop_writes_trigger —— 触发写入停止的文件个数。这三个配置大致限制了level0的文件数量。
- level0文件大小 —— 这个没有单独的配置,取决于memtable的配置,一个memtable会进行格式转换、压缩后存储为level0的文件。
level1及以上的配置:
- target_file_size_base —— level1的文件大小。这个是compaction后进行文件拆分的依据,并不是说一定会是这个大小,毕竟最终的数据量是不一定的。
- target_file_size_multiplier —— 系数,level2的文件大小是target_file_size_base*target_file_size_multiplier,以此类推
- max_bytes_for_level_base —— level1的文件大小总量,超过后会触发compaction以降低level1的文件总量。
- max_bytes_for_level_multiplier —— level2的文件大小总量限制是max_bytes_for_level_base * max_bytes_for_level_multiplier,更高的level以此类推。
- max_bytes_for_level_multiplier_addtl[0~n] —— 每个level文件总量的额外系数,max_bytes_for_level_base * max_bytes_for_level_multiplier^(l-1)的基础上再*max_bytes_for_level_multiplier_addtl[l]
compaction策略:
- compaction_style
调试相关配置
statistics
默认的打印
有一些默认开启的stats,不需要设置statistic,但是编译时不能开启ROCKSDB_LITE配置。会统计DB Stats、Compaction Stats(例如么个level写入数据量、写放大、LSM Tree的状态等信息)。
** DB Stats **
Uptime(secs): 603.2 total, 600.0 interval
Cumulative writes: 902 writes, 118M keys, 902 commit groups, 1.0 writes per commit group, ingest: 2.30 GB, 3.91 MB/s
Cumulative WAL: 902 writes, 0 syncs, 902.00 writes per sync, written: 2.30 GB, 3.91 MB/s
Cumulative stall: 00:08:4.296 H:M:S, 80.3 percent
Interval writes: 902 writes, 118M keys, 902 commit groups, 1.0 writes per commit group, ingest: 2359.55 MB, 3.93 MB/s
Interval WAL: 902 writes, 0 syncs, 902.00 writes per sync, written: 2.30 MB, 3.93 MB/s
Interval stall: 00:08:4.296 H:M:S, 80.7 percent
** Compaction Stats [default] **
Level Files Size Score Read(GB) Rn(GB) Rnp1(GB) Write(GB) Wnew(GB) Moved(GB) W-Amp Rd(MB/s) Wr(MB/s) Comp(sec) CompMergeCPU(sec) Comp(cnt) Avg(sec) KeyIn KeyDrop
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
L0 21/12 1.30 GB 4.5 4.8 0.0 4.8 7.2 2.4 0.0 3.0 10.1 15.3 481.78 126.12 577 0.835 231M 0
L1 30/30 1.84 GB 0.0 4.9 1.3 3.7 4.9 1.3 0.0 3.9 10.8 10.8 467.46 111.12 4 116.865 239M 0
L3 112/0 6.29 GB 0.1 6.2 2.4 3.8 4.6 0.8 2.6 1.9 5.0 3.7 1275.72 416.93 36 35.437 983M 186M
Sum 163/42 9.43 GB 0.0 15.9 3.7 12.3 16.7 4.5 2.6 6.9 7.3 7.7 2224.95 654.18 617 3.606 1455M 186M
Int 0/0 0.00 KB 0.0 15.9 3.7 12.3 16.7 4.5 2.6 6.9 7.3 7.7 2224.85 654.18 616 3.612 1455M 186M
** Compaction Stats [default] **
Priority Files Size Score Read(GB) Rn(GB) Rnp1(GB) Write(GB) Wnew(GB) Moved(GB) W-Amp Rd(MB/s) Wr(MB/s) Comp(sec) CompMergeCPU(sec) Comp(cnt) Avg(sec) KeyIn KeyDrop
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Low 0/0 0.00 KB 0.0 15.9 3.7 12.3 14.3 2.0 0.0 0.0 8.2 7.4 1982.92 620.25 165 12.018 1455M 186M
High 0/0 0.00 KB 0.0 0.0 0.0 0.0 2.4 2.4 0.0 0.0 0.0 10.3 241.92 33.93 451 0.536 0 0
User 0/0 0.00 KB 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 26.9 0.10 0.00 1 0.103 0 0
Uptime(secs): 603.2 total, 600.0 interval
Flush(GB): cumulative 2.430, interval 2.428
AddFile(GB): cumulative 0.000, interval 0.000
AddFile(Total Files): cumulative 0, interval 0
AddFile(L0 Files): cumulative 0, interval 0
AddFile(Keys): cumulative 0, interval 0
Cumulative compaction: 16.74 GB write, 28.42 MB/s write, 15.93 GB read, 27.04 MB/s read, 2225.0 seconds
Interval compaction: 16.74 GB write, 28.57 MB/s write, 15.93 GB read, 27.19 MB/s read, 2224.8 seconds
Stalls(count): 380 level0_slowdown, 379 level0_slowdown_with_compaction, 0 level0_numfiles, 0 level0_numfiles_with_compaction, 0 stop for pending_compaction_bytes, 0 slowdown for pending_compaction_bytes, 26 memtable_compaction, 242 memtable_slowdown, interval 647 total count
执行打印的函数是DBImpl::DumpStats,在StartTimedTasks中起的线程,定期执行DBImpl::DumpStats函数,加载db后可以看到dump_st和pst_st两个线程,dump_st就是输出打印用的,而pst_st则是将信息持久化:
void DBImpl::StartTimedTasks() {
unsigned int stats_dump_period_sec = 0;
unsigned int stats_persist_period_sec = 0;
{
InstrumentedMutexLock l(&mutex_);
stats_dump_period_sec = mutable_db_options_.stats_dump_period_sec;
if (stats_dump_period_sec > 0) {
if (!thread_dump_stats_) {
thread_dump_stats_.reset(new ROCKSDB_NAMESPACE::RepeatableThread(
[this]() { DBImpl::DumpStats(); }, "dump_st", env_,
static_cast(stats_dump_period_sec) * kMicrosInSecond));
}
}
stats_persist_period_sec = mutable_db_options_.stats_persist_period_sec;
if (stats_persist_period_sec > 0) {
if (!thread_persist_stats_) {
thread_persist_stats_.reset(new ROCKSDB_NAMESPACE::RepeatableThread(
[this]() { DBImpl::PersistStats(); }, "pst_st", env_,
static_cast(stats_persist_period_sec) * kMicrosInSecond));
}
}
}
}
option中的stats_dump_period_sec指定了信息dump的周期。
使用statistics
设置options.statistics后,会有额外的一些统计信息可以打印,同时也有一些接口可以主动去查询统计信息。开启后会对性能有一定的影响。
读取的latency:
** File Read Latency Histogram By Level [default] **
** Level 0 read latency histogram (micros):
Count: 1706181 Average: 57.7181 StdDev: 840.79
Min: 1 Median: 1.5588 Max: 1530878
Percentiles: P50: 1.56 P75: 1.88 P99: 15.68 P99.9: 10844.54 P99.99: 105193.99
------------------------------------------------------
[ 0, 1 ] 100829 5.910% 5.910% #
( 1, 2 ] 1346327 78.909% 84.818% ################
( 2, 3 ] 202691 11.880% 96.698% ##
( 3, 4 ] 19891 1.166% 97.864%
( 4, 6 ] 14133 0.828% 98.692%
( 6, 10 ] 3990 0.234% 98.926%
( 10, 15 ] 1191 0.070% 98.996%
( 15, 22 ] 690 0.040% 99.037%
( 22, 34 ] 250 0.015% 99.051%
( 34, 51 ] 4631 0.271% 99.323%
( 51, 76 ] 7685 0.450% 99.773%
( 76, 110 ] 702 0.041% 99.814%
( 110, 170 ] 161 0.009% 99.824%
( 170, 250 ] 30 0.002% 99.825%
( 250, 380 ] 46 0.003% 99.828%
( 380, 580 ] 52 0.003% 99.831%
( 580, 870 ] 66 0.004% 99.835%
( 870, 1300 ] 118 0.007% 99.842%
( 1300, 1900 ] 109 0.006% 99.848%
( 1900, 2900 ] 197 0.012% 99.860%
( 2900, 4400 ] 225 0.013% 99.873%
( 4400, 6600 ] 126 0.007% 99.880%
( 6600, 9900 ] 274 0.016% 99.896%
( 9900, 14000 ] 264 0.015% 99.912%
( 14000, 22000 ] 344 0.020% 99.932%
( 22000, 33000 ] 305 0.018% 99.950%
( 33000, 50000 ] 311 0.018% 99.968%
( 50000, 75000 ] 224 0.013% 99.981%
( 75000, 110000 ] 172 0.010% 99.991%
( 110000, 170000 ] 84 0.005% 99.996%
( 170000, 250000 ] 44 0.003% 99.999%
( 250000, 380000 ] 19 0.001% 100.000%
( 380000, 570000 ] 6 0.000% 100.000%
( 1200000, 1900000 ] 1 0.000% 100.000%
...... 后面还会对每个level分开统计
还有一些其他的统计:
2022/06/15-11:28:09.796066 7f11337ee700 [_impl/db_impl.cc:635] STATISTICS:
rocksdb.block.cache.miss COUNT : 8210898
rocksdb.block.cache.hit COUNT : 0
rocksdb.block.cache.add COUNT : 0
rocksdb.block.cache.add.failures COUNT : 0
rocksdb.block.cache.index.miss COUNT : 0
rocksdb.block.cache.index.hit COUNT : 0
rocksdb.block.cache.index.add COUNT : 0
rocksdb.block.cache.index.bytes.insert COUNT : 0
rocksdb.block.cache.index.bytes.evict COUNT : 0
rocksdb.block.cache.filter.miss COUNT : 0
rocksdb.block.cache.filter.hit COUNT : 0
rocksdb.block.cache.filter.add COUNT : 0
rocksdb.block.cache.filter.bytes.insert COUNT : 0
rocksdb.block.cache.filter.bytes.evict COUNT : 0
rocksdb.block.cache.data.miss COUNT : 8210898
rocksdb.block.cache.data.hit COUNT : 0
......
statistics我使用的不多,所以就粗略介绍一下,如何统计的、有哪些重要信息并不清楚,读者有兴趣的可以自行研究。