操作系统笔记整理11——文件和文件系统
点此链接可跳转到:操作系统笔记整理——目录索引页
参考书籍:《计算机操作系统》第四版 汤小丹等编著
文章目录
- 点此链接可跳转到:操作系统笔记整理——目录索引页
- 数据项、记录和文件
- 数据项
- 记录
- 文件
- 文件系统
- 对象及其属性
- 对对象操纵和管理的软件集合
- 文件的逻辑结构
- 顺序文件
- 索引文件
- 索引顺序文件
- 一级索引顺序文件
- 两级索引顺序文件
- 直接文件和哈希文件
- 直接文件
- 哈希文件
- 文件目录
- 文件控制块
- 索引结点
- 目录的结构
- 单级文件目录
- 两级文件目录
- 树型结构目录
- 目录查询技术
- 线性检索法
- Hash方法
- 文件共享
- 基于索引结点的共享方式
- 利用符号链接实现文件共享
- 文件保护
- 访问矩阵
- 基本的访问矩阵
- 具有域切换权的访问矩阵
- 访问矩阵的修改
- 拷贝权
- 所有权
- 控制权
- 访问矩阵的实现
- 访问控制表(Access Control List)
- 访问权限表(Capabilities List)
所有的计算机应用程序都需要存储和检索信息。 长期存储信息有三个基本要求:
能够存储大量信息.
使用信息的进程终止时,信息仍旧存在。
必须能使多个进程并发存取有关信息。
解决所有这些问题的通常做法是把信息以文件的形式,存储在磁盘或其他外部介质上。
存储在文件中的信息必须是永久性的,不会因为创建和终止进程而受到影响。只有在文件的所有者显式地删除文件时,文件才会消失。
数据项、记录和文件
数据项
基本数据项:用于描述一个对象的某种属性的字符集,是数据组织中可 以命名的最小逻辑数据单位即原子数据,又称为数据元素或字段。如描述一个学生的基本数据项有学号、姓名等。
组合数据项:由若干个基本数据项组成的,简称组项。如工资是组合数据项,包括基本工资,奖金等。
数据项的名字和类型两者共同定义了一个数据项的“型”(Type)。而表征一个实体在数据项上的数据则称为“值”(Value)。如:学生是一个实体,“成绩”是实体的“型”描述,具体的分数是实体的“值”。
记录
记录是一组相关数据项的集合,用于描述一个对象在某方面的属性。 一个记录应包含哪些数据项,取决于需要描述对象的哪个方面。为了描述对象的不同属性,一个记录可以选取不同的数据项。
例如一个人
当把他作为一个学生:可选取学号、姓名、成绩等数据项。
当把他作为一个病人:可选取病历号、姓名、病史等数据项。
关键字:能唯一地标识出记录的一个或几个基本/组合数据项。
文件
文件是由创建者所定义的、具有符号名的相关信息集合。
文件可分为有结构文件和无结构文件两种。有结构文件是由若干个相关记录组成,无结构文件被看成一个字符流。
文件是文件系统中最大的一个数据单位,它描述了一个对象集。
例如,可将一个班的学生记录作为一个文件
文件属性包括:
1.文件类型:如源文件、目标文件、可执行文件等
2.文件长度
3.文件的物理位置
4.文件的建立时间:指最后一次修改的时间

文件类型:

文件系统
文件系统模型

对象及其属性
- 文件
- 目录:为了方便用户对文件的存取和检索,在文件系统中必须配置目录,在目录的每个目录项中,必须含有文件名、对文件属性的说明,以及该文件所在的物理地址。
- 磁盘存储空间:文件和目录必定占用存储空间,对这部分空间的有效管理,不仅能提高外存的利用率,而且能提高对文件的存取速度
对对象操纵和管理的软件集合
文件系统的功能大多在这一层实现,其中包括
- 对文件存储空间的管理
- 对文件目录的管理
- 用于将文件的逻辑地址转换为物理地址的机制
- 对文件读和写的管理
- 对文件的共享与保护等功能
为实现这些功能,OS通常都采取了层次组织结构,即在每一层都包含了一定的功能,处于某个层次的软件,只能调用同层或更低层次中的功能模块
一般地,把与文件系统有关的软件分为四个层次:

- I/O控制层:由设备驱动程序和中断处理程序组成,启动I/O操作及处理设备发来的中断信号
- 基本文件系统层:处理内存与磁盘间的数据块交换
- 基本I/O管理程序:用于完成与磁盘I/O有关的事务,如将文件逻辑块号转换为物理块号
- 逻辑文件系统:处理与记录和文件有关的操作,如允许用户和应用程序使用符号文件名访问文件及记录
文件的逻辑结构
文件的逻辑结构:从用户观点出发所观察到的文件组织形式,是用户可以直接处理的数据及其结构,它独立于物理特性。
文件的物理结构:是指文件在外存上的存储组织形式,用户是看不见的,文件的物理结构 不但与存储介质的存储性能有关,而且还与所采取的外存分配方式有关。
逻辑结构的类型:
按是否有结构分类
- 有结构文件(记录式文件),如数据库文件
定长记录:文件中所有记录的长度都是相同的
变长记录:文件中各记录的长度不相同,产生变长记录的原因可能是由于一个记录中所包含的数据项数目不同,也可能是数据项本身的长度不定 - 无结构文件(流文件),如程序、文本文件

按文件的组织方式分类
- 顺序文件
一系列记录按某种顺序排列所形成的文件,其中的记录可以是定长记录或可变长记录 - 索引文件
指为可变长记录文件建立一张索引表,为每个记录设置一个表项,以加速对记录的检索速度 - 顺序索引文件
在为每个文件建立一张索引表时,并不是为每一个记录建立一个索引表项,而是为一组记录中的第一个记录建立一个索引表项
顺序文件
顺序文件的排序
- 串结构:记录顺序与关键字无关,按存入时间的先后排列
- 顺序结构:记录顺序按用户指定的关键字排列
顺序文件的优缺点
优点:
顺序存取速度快,批处理时效率是所有逻辑文件中最高的。
缺点:
建立文件前需要能预先确定文件长度,以便分配存储空间。
交互应用时“效率低”(如要查找单个记录),尤其是对变长记录的顺序文件。
增加、删除记录涉及到排序问题,开销大。解决方法:为顺序文件配置一个事务文件 (log),把试图增加、删除或修改的信息记录于其中,规定每隔一定时间(如4小时),将运行记录文件与原来的主文件合并,产生一个按关键字排序的新文件。
对顺序文件的续写操作
定长记录:
读写完一个记录(定长 L)后:读指针 Rptr:= Rptr + L;写指针 Wptr:= Wptr + L
第 i 个记录相对于第一个记录首址的地址:Ai=i× L
变长记录:
读写完一个记录后:Rptr:=Rptr+Li+1;Wptr:=Wptr+Li+1。Li 是刚读完或写完记录的长度。变长记录中每个记录前用一个字节指明该记录的长度。 第 i 个记录的首址:须顺序地查找每个记录,获得记录长度 Li,然后才能 计算出第 i 个记录的首址:Ai= ∑ i = 0 i − 1 ( L i + 1 ) { \sum_{i=0}^{i-1} (L~i~+1)} ∑i=0i−1(L i +1)

索引文件
定长记录的文件可以通过简单的计算,很容易地实现随机查找,但变长记录文件查找一个记录必须从第一个记录查起,耗时很长。
索引文件为变长记录文件建立一张索引表,每个记录在索引表中占一个表项,记录指向记录的指针(即记录在逻辑地址空间的首址)以及记录的长度L,索引表按关键字排序,其本身也是一个定长记录的顺序文件,这样就把对变长记录顺序文件的顺序检索转变为对定长记录索引文件的随机检索,从而加快对记录检索的速度
索引文件可以有多个索引表,即为每一种可能成为检索条件的域(属性或关键字)都配置一张索引表,如学号索引表、姓名索引表
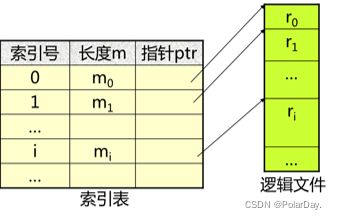
优点:
通过索引表可方便地实现直接存取,具有较快的检索速度。(索引表本身就 是一个定长记录的顺序文件)
易于进行文件的增删。
缺点
索引表的使用增加了存储费用。
索引顺序文件
顺序文件+索引文件
在顺序文件的基础上(记录是按关键字的顺序组织),另外建立了文件索引表(实现对索引顺序文件的随机访问)和溢出文件(记录新增加的、删除的和修改的记录)
一级索引顺序文件
首先将变长记录顺序文件中的所有记录分为若干个组,如50个记录一组,然后为顺序文件建立一张索引表,并为每组中的第一个记录在索引表中建立一个索引项,其中含有该记录的关键字和指向该记录的指针
在检索时首先利用关键字检索索引表,找到该记录所在组的第一个记录的地址,然后再用顺序查找法去查找主文件

两级索引顺序文件
为索引文件在建立一张索引表,从而形成两级索引表
例 1:10000 个记录 (N)
顺序文件:5000 次查找。(平均 N/2 次)
索引顺序文件:设 100 个记录一组,索引表查找方法设为顺序法的情况 下,则查找次数为 50+50=100。
例 2:1000000 个纪录
索引顺序文件:采用多级索引表
低级索引:(100 个纪录一组):10000。
高级索引:100
查找次数:50+50+50=150
直接文件和哈希文件
直接文件
传统转换:记录键值 → 线性表或链表 → 物理地址
直接文件:根据给定的记录键值,直接获得指定记录的物理地址。即记录键值本身就决定了记录的物理地址。
键值转换(Key to address transformation):由记录键值直接到记录物理 地址的转换。
哈希文件
K 为记录键值,A 为通过 Hash 函数转换所形成的该记录在目录表中对应表目的位置,则:A=H(k)。该表目的内容指向相应记录的物理块。
文件目录
用于检索文件的目录称为文件目录,它是由目录项所构成的有序序列。
对文件目录的管理要求
实现“按名存取”
提高对目录的检索速度
文件共享(多个用户共享一个文件,只需要在外存保留一个文件)
允许文件重名(不同文件使用同一个名字)
文件控制块
文件控制块是操作系统为管理文件而设置的数据结构,存放了文件的有关 说明信息,是文件存在的标志。
文件控制块中,通常应含有三类信息,即基本信息、存取控制信息及使用信息
- 基本信息
文件名
文件物理位置
文件逻辑结构(指示文件时流式文件还是记录式文件、记录数,文件是定长记录还是变长记录)
文件物理结构(指示文件是顺序文件还是链接式文件或索引文件) - 存取控制信息
文件的存取权限等 - 使用信息类
包括文件的建立日期和时间、文件上一次修改的日期和时间,以及当前使用信息等
存取文件的过程:
文件控制块 FCB→ 块链
文件控制块 FCB→FAT/MFT→ 块链
FCB保存在外存空间中,当访问一个文件时,应当能够根据文件名字找到它所对应的 FCB。那么 FCB 是如何保存于外存的呢?
它是作为目录项存储于目录文件中的。FCB 也被称作目录项。
文件目录:文件目录是一种数据结构,用于标识系统中的文件及其物理地址,将文件名映射到外存物理位置,供检索使用。
目录项:构成文件目录的项目(目录项就是 FCB)
目录文件:为了实现对文件目录的管理,通常将文件目录以文件的形式保存在外存,这个文件就叫目录文件。
文件目录和目录文件是同一事物的两种称谓。从用途角度来看称其为文件目录,从实现角度来看称其为目录文件。
索引结点
文件目录通常是存放在磁盘上的,当文件很多时,文件目录可能要占用大量的盘块。在查找目录的过程中,先将存放目录文件的第一个盘块中的目录调入内存,然后把用户所给定的文件名与目录项中的文件名逐一比较。若未找 到指定文件,便再将下一个盘块中的目录项调入内存。设目录文件所占用的盘块数为 N,按此方法查找,则查找一个目录项平均需要调入盘块 (N+1)/2 次。
检索目录文件的过程中,只用到了文件名,仅当文件名与指定要查找的文件名相匹配时,才需从该目录项中读出该文件的物理地址,而其它信息在检索目录时不需调入内存。为此,便可以采用文件名与文件描述分开的办法,使文件描述单独形成一个称为索引结点的数据结构,简称i结点,在文件目录的每个目录项仅由文件名和指向该文件所对应的i结点的指针组成,这样在有限的盘块空间内可以存放更多的目录项,减少了调入盘块的次数,大大节省了系统开销
索引结点分为磁盘索引结点和内存索引结点
磁盘索引结点:存放在磁盘上的索引结点,主要包括以下内容
- 文件主标识符,即拥有该文件的个人或小组的标识符
- 文件类型,包括正规文件、目录文件或特别文件
- 文件存取权限,指各类用户对该文件的存取权限
- 文件物理地址,每一个索引结点中含有13个地址项,给出数据文件所在盘块的编号
- 文件长度,指出以字节为单位的文件长度
- 文件连接计数,表明在本文件系统中所有指向该文件名的指针计数
- 文件存取时间,指出本文件最近被进程存取的时间,最近被修改的时间及索引结点最近被修改的时间
内存索引结点:存放在内存中的结点。当文件被打开时,要将磁盘索引结点拷贝到内存的索引结点中,便于以后使用,并增加以下内容
- 索引结点编号,用于标识内存索引结点
- 状态,指示i结点是否上所或被修改
- 访问计数,每当有一进程要访问此i结点时,将该访问计数加1,访问完再减1
- 文件所属文件系统的逻辑设备号
- 链接指针,设置有分别指向空闲链表和散列队列的指针
例:在某个文件系统中,每个盘块为 512 字节,文件控制块占 64 个字节,其中文件名占 8 个字节。如果索引结点编号占 2 个字节,对一个存放在磁盘上的 256 个目录项的目录,试比较引入索引结点前后,为找到其中一个文件的FCB,平均启动磁盘的次数。
解:引入索引节点前,每个目录项中存放的是对应文件的 FCB,故 256 个目 录项的目录总共需要占用 256×64/512=32 个盘块。故在该目录中检索到一个 文件平均启动磁盘次数为 (1+32)/2=16.5。
引入索引节点后,每个目录项中只需存放文件名和索引节点的编号,因 此 256 个目录项的目录总共需要占用 256×(8+2)/512=5 个盘块。因此,找到 匹配的目录项平均需要启动 3 次磁盘;而得到索引结点编号后还需启动磁盘将对应文件的索引结点读入内存,故平均需要启动磁盘 4 次。
目录的结构
单级文件目录
在整个系统中只建立一张目录表,每个文件占一个目录项,为表明每个目录项是否空闲,还设置有一个状态位。

每当建立一个新文件时,必须先检索所有的目录项,以保证新文件名在目录中是唯一的,然后再从目录表中找出一个空白目录项,填入新文件,并置状态位为1。删除文件时,先从目录中找到该目录项,回收该文件所占用的存储空间,然后再清除该目录项。
优点:单级文件目录管理比较简单,易于实现按名存取。
缺点:
限制了用户对文件的命名(不允许重名)。
文件平均检索时间长 (平均 N/2)。
不便于实现文件共享,通常每个用户都有自己的名字空间,因此,应当允许不同用户使用不同的文件名来访问同一个文件。
两级文件目录
为每个用户建立一个单独的用户文件目录(UFD)。
系统中为所有用户建立一个主文件目录(MFD),每个用户目录文件都占有一个目录项。

优点:
两级文件目录提高了检索目录的速度。例如:如果有 n 个用户,每用户最 多 m 个文件,则最多检索 n+m 个目录项而非单级目录结构的 n×m 项。
不同用户目录中可重名。
不同用户可用不同文件名来访问系统中一共享文件。
缺点
对文件的共享不方便(用户隔离)。
增加了系统开销,缺乏灵活性,无法反映真实世界复杂的文件结构形式。
树型结构目录
树型结构目录只有一个根目录,而且除根目录外,其余每个目录或者文 件都有唯一的一个上级目录。
每一级目录可以包含文件,也可以包含下一级目录。

操作系统为每个目录建立一个目录文件,其内容就是该目录下包含的文件的 FCB 集合。

优点:
层次结构清晰,便于管理和保护。
解决重名问题。
查找速度加快,因为每个目录下的文件数目较少。
缺点:
查找一个文件,需要按路径名逐级访问中间节点,增加了磁盘访问次数。
路径名:
在树形目录结构中,从根目录到任何数据文件,都只有一条唯一的通路。 这一系列目录名和最后达到的文件名自身依次地用“/”连接起来组成了该文件的路径名。
多个文件可以同名,只要保证它们的路径名唯一即可。
当前目录:
为了提高文件检索速度,文件系统向用户提供了一个当前正在使用的目录,称为当前目录(工作目录)。
当前目录一般存放在内存。
绝对路径名:
绝对路径名是从根目录开始到达所要查找文件的路径名,以“/”打头。
/root/usr/m1/prog/f1.c
相对路径名:
相对路径名从当前目录(工作目录)的下级开始书写。
例如:当前目录是/usr/m1,则有相对于当前目录的相对路径名:prog/f1.c
. 当前目录:./prog/f1.c
… 上级目录:…/ml/prog/f2.c
创建目录:
用户可以为自己建立用户文件目录(UFD),并创建子目录。创建一个新文件时,只需查看 UFD 及其子目录中有无与新建文件相同的文件名。若无,便可在 UFD 或其某个子目录中增加一个新目录项。
删除目录:
不删除非空目录。必须先删除所有文件,变成空目录后才能删除。 可删除非空目录。
移动目录:
文件或子目录移动后(剪切、复制),文件的路径名将随之改 变。
链接操作:
对于树型结构目录,每个文件或子目录只允许一个父目录。 但是可以通过链接操作让指定文件有多个父目录,从而方便共享。(网状 结构)
目录查询:
操作系统支持多种目录查找方式。
目录查询技术
文件名 → 目录项(FCB)或索引结点 → 盘块号 → 驱动程序 → 启动磁盘 → 读数据文件至内存
目录查询方式:线性检索法(顺序检索法)、Hash方法
线性检索法
顺序查找(线性查找)
查找过程:从表的一端开始查找,顺序用各记录的关键字进行比较,若找 到与其值相等的元素,则查找成功;若直到最后一个记录仍未找到,则查 找失败。
线性表可以是顺序存储结构或链式存储结构,可以是有序表或无序表。
二分查找(折半查找)
线性表必须是顺序存储结构,并且是有序表。

Hash方法
Hash 表(散列表)的查找采用计算寻址的方式进行查找,查找效率与比较次数无关或关系较小,所以查找的效率较高。
Hash 方法目录查询
- 构造 Hash 表:以文件名 k 为自变量,通过一个确定的函数关系 f 计算出Hash 函数值 f(k),把这个值(Hash 地址)存储为一个线性表,称为散列表或哈希表。
- 查找 Hash 表:根据给定值 k(文件名),计算 Hash 函数值 f(k),若系统 中存在文件名与 k 相等的记录,则必定存储在哈希表中 f(k) 的位置上。因此不需比较便可直接在哈希表中取得所查目录项。然后在目录项中得文件的物理地址。
文件共享
文件共享:一个文件被多个用户或程序使用
共享的方法:基于索引结点的共享方式、利用符号链实现文件共享
基于索引结点的共享方式
有向无循环图目录结构(带链接的树形目录)。它允许目录含有共享子目录和文件,但不构成环路
同一个文件可以有多个路径名。有向无循环图目录结构不再是一颗树,而成为网状结构。
在有向无循环图目录结构中,如果有用户要共享一个文件或子目录,必须把共享文件或子目录拷贝或链接到用户的目录中。
存在的问题:新增内容不能被共享。
文件目录:由文件名和指向索引结点的指针组成
索引结点(i结点):存放除文件名以外的文件属性。包括文件的结构信息、物理块号、存取控制、管理信息等。
基于索引结点的共享方式:共享索引结点
在索引结点中增加链接计数 count,表示共享的用户数。
删除文件时必须 count=0 方可。当 count>1 时,文件主也不能删除文件,否则指针悬空。

当用户C创建一个文件时,他便是该文件的所有者,此时将count置1。当有用户B要共享此文件时,在用户B的目录中增加一目录项,并设置一指针指向该文件的索引结点,此时主文件仍然是C,count=2。如果用户C不再需要文件,它也不能删除该文件,若删除了该文件,也必然删除了该文件的索引结点,这样便会使B的指针悬空,而B则可能正在此文件上执行写操作,此时将因此半途而废,但如果C不删除,则C必须为B使用此文件而付账,直至B不再需要
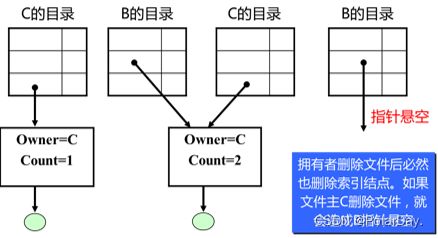
要解决基于索引结点的共享方式可能发生的指针悬空问题,可以利用符号链接实现文件共享。
利用符号链接实现文件共享
利用符号链接实现文件共享:允许一个文件或子目录有多个父目录,但其中仅有一个作为主父目录,其它的几个父目录都是通过符号链接方式与之相链接的(简称链接父目录)。为使链接父目录能共享文件,可以由系统创建一个LINK类型的新文件,并将之写入链接父目录中,该文件仅包含被链接/共享文件的路径名,当用户通过链接父目录访问共享文件时,此要求会被OS截获,OS根据新文件中的路径名去找到共享文件,然后对它进行读写。
符号链方式中,只有文件主才拥有指向其索引结点的指针,其它共享的 用户只有该文件的路径名,不拥有指向其索引结点的指针。
文件主可对原文件删除。其他用户试图通过符号链去访问一个已被删除的共享文件时,会因系统找不到该文件而使访问失败,于是将符号链删除,而不会发生指针悬空现象。
Windows 中的快捷方式就是符号链文件

优点:
当文件主删除一个共享文件时,其它共享文件的用户不会留下一个悬空指针。
利用符号链实现共享时,可以通过网络链接到分布在世界各地的计算机系统中的文件
缺点:
基于索引结点的共享方式可以直接从索引节点得到文件的物理地址,而利用符号链实现文件共享则需要根据给定的文件路径名去查找目录,启动磁盘的频率较高,使访问文件的开销增加。
符号链本身也是一个文件,虽然很简单,但也需要配索引结点,耗费磁盘空间。
文件保护
影响文件安全性的主要因素
- 人为因素
- 系统因素
- 自然因素,随着时间的推移,存放在磁盘上的数据会逐渐消失
确保文件系统安全性的措施
- 存取控制机制 ------人为因素
- 系统容错技术 ------系统因素
- 后备系统 ------自然因素
访问控制技术:现代操作系统中,几乎都配置了对系统资源进行保护的机制,引入了保护域和访问权的感念。
访问权:
一个进程能对某对象 (Object) 执行操作的权力称为访问权(Access Right)。每个访问权可以用一个有序对(对象名,权集)来表示。
例如,某进程有对文件 F1 执行读和写操作的权力,这时可将该进程的访问 权表示成 (F1,[R/W])。
保护域:
保护域是进程对一组对象的访问权的集合。
进程仅在保护域内执行操作,保护域规定了进程所能访问的对象和能执行的操作。

进程与域之间的联系:
- 静态联系:进程和域之间一一对应,即一个进程只联系着一个域,这意味着,在进程的整个生命期中,其可用资源是固定的,这种域称为“静态域”,这将会使赋予进程的访问权超过实际需要。
- 动态联系:动态联系是指进程的可用资源集在进程的整个生命中是变化的。进程和域是一对多的关系,即一个进程可联系着多个域。可将进程的运行分为若干个阶段,其每个阶段联系着一个域,这样便可根据运行的实际需要,来规定在进程运行的每个阶段中所能访问的对象。
访问矩阵
基本的访问矩阵
访问矩阵:用以描述系统存取控制的矩阵。
访问矩阵中的行代表同一域,列代表同一对象,矩阵中每一项由一组访问权组成。
R 读 W 写 E 执行
访问权 access(i,j) 定义了在域Di中执行的进程能对对象j施加的操作集。 访问权通常由资源的拥有者或管理者所决定。

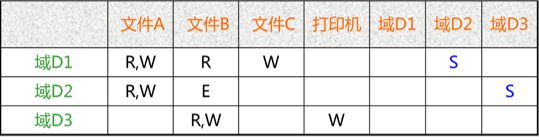
具有域切换权的访问矩阵
为了实现在进程和域之间的动态联系,应能够将进程从一个保护域切换到另一个保护域。为了能对进程进行控制,同样应将切换作为一种权利,仅当进程有切换权时,才能进行这种切换。
切换权 switch∈access(i,j) 时,表示允许进程从域 i切换到域 j。
如下图,由于域D1和域D2所对应的项目中有一个S即Switch,故而允许在域D1中的进程切换到域D2中
访问矩阵的修改
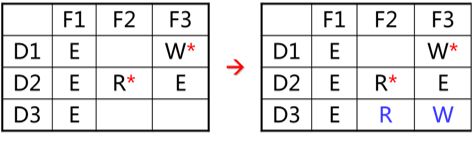
拷贝权
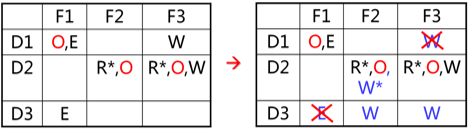
拷贝权指进程在某个域中对某对象拥有的访问权可通过拷贝将访问权扩展到同一列(即同一对象)的其它域中。亦即,为进程在其它的域中也赋予同一对象的访问权。
访问权access(i,j) 上加*者表示在域i运行的进程可以把对对象j的访问权复制到同一对象的任何域中。
限制拷贝:拷贝后的访问权不带*号,不能再将其拷贝
所有权
除了可以利用拷贝权把访问权进行有控制的扩散以外,系统还需要能增加或删除某些控制权,我们可以利用所有权实现这些操作。
如果在访问权access(i,j)中包含所有权(o),则在域Di上运行的进程,可以增加或删除其在j列上任何项中的访问权。换言之,进程可以增加或删除在任何其它域中运行的进程对对象j 的访问权。
控制权
拷贝权和所有权都是用于改变矩阵内同一列的访问权。控制权则可用于改变矩阵内同一行 (域)中的访问权,即用于改变在某个域中运行进程对不同对象的访问权。
如果在访问权access(i,j) 中包含了控制权 Control,则在域Di中运行的进程 可以删除在域Dj中运行进程对各对象的任何访问权。

访问矩阵的实现
在较大的系统中,访问矩阵将变得非常巨大,而且矩阵中的许多格可能 都为空(稀疏矩阵),造成很大的存储空间浪费,因此在实际应用中访问 控制很少利用访问矩阵的方式实现。
目前使用的访问控制实现技术不是保存整个访问矩阵,而是基于访问矩阵的列或者行来保存信息,分别形成访问控制表和访问权限表。
访问控制表(Access Control List)
把访问矩阵按列(对象)划分,为每一列建立一张访问控制表ACL。
在该表中,已把矩阵中属于该列的所有空项删除,此时的访问控制表是由一有序对(域,权集)所组成的
当对象为文件时,常把访问控制表 ACL 存放于该文件的 FCB 或索引结点中,作为存取控制信息。
域是一个抽象的概念,可用各种方式实现。最常见的一种情况是每一个用户就是一个域,而对象则是文件。此时,用户能够访问的文件集和访问权限取决于用户的身份。
另一种情况是每个进程是一个域,此时,能够访问的对象集中的各访问权取决于进程的身份。
访问权限表(Capabilities List)
把访问矩阵按行(域)划分,每行形成一张访问权限表。
表中的每一项为该域对某对象的访问权限。
访问权限表不允许直接被用户 (进程) 所访问。访问权限表被存储到专用系统区内,只允许专用于进行访问合法性检查的程序访问,以实现对访问权限表的保护。

大多数系统都同时采用访问控制表和访问权限表。
系统中为每个对象配置一张访问控制表。当一个进程第一次试图去访问一个对象时,必须先检查访问控制表,检查进程是否具有对该对象的访问权。若有权访问,根据访问权限表为该进程建立一个访问权限,以后该进程便可直接利用这一返回的权限去访问该对象。
利用访问控制表和访问权限表可以快速地验证访问的合法性。当进程不再需要对该对象进行访问时,便可撤消该访问权限。