DNN硬件加速器设计4 -- Co-Design and Benchmarking Metrics(MIT)
4. Network and Hardware Co-Design
4.1 Network Optimization
对于网络算法的优化主要采用以下两种思路:
(1)减小计算精度和对参数进行低位宽量化:参数类型为定点数与浮点数的比较,数据位宽对精度的影响
(2)减少计算量和参数存储量:参数压缩(Compression),网络裁剪(Pruning)
下图1所示为FP32, FP16, INT32, INT16, INT8五种数据类型,位宽表示含义,取值范围以及精度的表示。

图 1
下图2所示为操作数用不同位宽表示的情况下,进行单次不同类型的计算后,在能耗与运算硬件单元占用面积两个方面的对比。

图 2
4.2 Methods to Reduce Bits
(1)Quantization:对训练好的参数直接进行量化处理,用定点数来表示原浮点数参数,采用这种方法,会产生不可避免精度丢失的情况。

图 3
图3所示为在对原浮点参数进行量化时,对参数数据进行可视化处理,用定点数去尽可能的表示更多的浮点数。
(2)Dynamic Fixed Point: 在直接将浮点数量化处理成单一定点数的基础上,采用动态定点数的方式可以在一定程度上减小精度丢失。
(3)Fine-tuning(Retrain Weights):直接再训练的过程中,对参数进行量化处理,这样在对算法进行硬件平台移植时,不需要进行额外的量化操作,可以保证在训练后的精度不变的情况下,提高算法的执行速度。这里在训练过程中,使得权值参数值保持围绕在一个中心范围,需要加入Batch Normalization Layer,这里,从另一个角度理解了Batch Normalization Layer的重要性了。
(4)Impact on Accuracy

图 4
图4所示为采用静态定点数和动态定点数对权值参数进行量化处理后,Top-1 accuracy的变化折线图。可以直观的看出,采用动态定点数量化的方法能够保证更小的准确率的损失。
(5)Precision Varies from Layer to Layer

图 5
在采用动态定点数对权值参数进行量化处理策略的基础上,为进一步减小量化处理带来的准确率丢失的情况,可以采用更细粒度的优化策略,即对每一层运算层采用对应层最合适的数据位宽进行量化处理。如图5所示。
(6)Binary Nets

图 6
图 6所示为网络参数分别在不进行二值化,权值参数二值化,权值参数和特征数据二值化三种情况下,在计算方式,数据存储,前向计算时间,计算精度上的对比。可以看到,在对数据依次递增进行二值化处理后,数据存储在变小,单次前向计算时间有明显增加,但代价就是计算精度的损失。
(7)Reduce Number of Ops and Weights
1) Network Compression: Low Rank Approximation, Weight sharing and Vector Quantization
2) Pruning: Weights, Activations
3) Network Architectures
[PS:这部分的优化主要是针对算法设计,我目前知识有限,也是一知半解,可以参考相关的资料]
5. Benchmarking Metrics for DNN Hardware
基本的评价指标参数有:Accuracy, Power, Throughput, Cost;
额外的评价指标参数有:External memory bandwidth, Required on-chip storage, Utilization of cores(实际算力和理论算力的比较)
(1)DNN Algorithm的评价参数指标
1)计算准确度(Accuracy)
2)网络结构(网络层数,卷积核大小,卷积核层数,特征数据通道数)
3)权值参数存储大小
4)完成一次前向传播运算所需要进行的乘加(MAC)操作次数
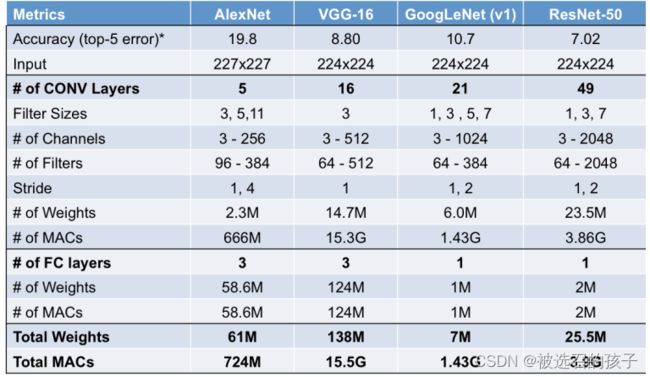
表 1

表 2
表1和表2所示为AlexNet, VGG-16, GoogLeNet(v1), ResNet-50的评价参数指标的具体表示。
(2)DNN Hardware的评价参数指标
1)能耗参数指标,系统能耗比(单运算量下的能耗)
2)访存带宽,从片外DRAM中存取数据的速度
3)硬件理论算力,MAC运算单元的操作数的数据位宽和硬件运算单元的数目
4)面积(硬件资源的使用情况)
(3)ASIC Benchmark (Eyeriss)
表3和表4所示为基于ASIC硬件平台设计的硬件加速器的评价参数指标的具体表示。

表 3

表 4
(4)FPGA Benchmark
表5所示为基于ASIC硬件平台设计的硬件加速器的评价参数指标的具体表示。

表 5