SpringBoot中使用flyway进行数据库版本管理
SpringBoot中使用flyway进行数据库版本管理
- 1 简介
- 2 flyway是什么
- 3 为什么要使用flyway
- 4 能帮助我们解决什么问题
- 5 FlyWay的工作原理
- 6 flyway是如何工作的
- 6 springboot环境下使用flyway
-
- 6.1 依赖
- 6.2 在application.yml
- 6.3 根据配置文件中填写的脚本存放路径,创建文件夹
- 7 启动项目, 通过flyway执行定义好的脚本
- 8 maven插件的使用
- 9 插件命令说明
- 10 flyway知识补充
- 11 flyway配置清单
- 12 总结
1 简介
Flyway 是一款开源的数据库版本管理工具。它可以很方便的在命令行中使用,或者在Java应用程序中引入,用于管理我们的数据库版本。
在项目或产品中,很难一开始就把业务理清楚,把数据库表设计好,因此数据表也会在迭代周期不断迭代。在Java应用程序中使用Flyway,能快速有效地用于迭代数据库表结构,并保证部署到测试环境或生产环境时,数据表都是保持一致的。
2 flyway是什么
Flyway是一个开源的数据库版本管理工具,并且极力主张“约定大于配置”,简单、专注、强大。可以使用SQL完成数据同步,或者基于特定数据库的语法(例如PL / SQL,T-SQL等)或Java代码(适用于高级数据转换或处理LOB)的方式编写。并且数据库支持非常广泛:
在SpringBoot中使用flyway进行数据库版本管理
3 为什么要使用flyway
在多人开发的项目中,我们都习惯了使用SVN或者Git来对代码做版本控制,主要的目的就是为了解决多人开发代码冲突和版本回退的问题。
其实,数据库的变更也需要版本控制,在日常开发中,我们经常会遇到下面的问题:
自己写的SQL忘了在所有环境执行。
别人写的SQL我们不能确定是否都在所有环境执行过了。
有人修改了已经执行过的SQL,期望再次执行。
需要新增环境做数据迁移。
每次发版需要手动控制先发DB版本,再发布应用版本。
其它场景。
有了flyway,这些问题都能得到很好的解决。
4 能帮助我们解决什么问题
那么,我们首先解释一下什么是数据库版本管理?
大家都知道git是帮助软件项目进行代码版本的管理,方便程序员协同开发 那么FlyWay就是数据库版本管理的工具,目标是保证多环境下数据库的状态一致性,方便程序员协同开发
举个简单的例子:
开发人员通常使用同一个数据库或者自建库进行开发工作,这个数据库通常叫做开发库。 测试人员为了保障测试数据的有效性,通常自建一个库进行测试,这个数据库叫做测试库。 销售人员为了保证演示数据的效果,通常也需要一个单独的数据库,这个数据库叫做演示库。 正式生产上线的库,供给用户使用,这个数据库叫做生产库。
那么问题就来了:我们如何保证数据库schema的状态一致?某一个开发人员修改了开发库,新增了一个字段,如何能够有效的同步到测试库,测试通过之后如何有效的同步到演示库和生产库?在没有Flyway之前,这个动作通常是由上线程序员自己去执行SQL来完成的,或者比较正规的公司专门有版本管理人员去操作。这种方式通常存在几个问题:
开发团队内部的沟通成本增加,比如某一个成员修改了一个数据库字段,其他人可能都不知道。 开发团队和测试团队和其他团队之间的沟通成本增加 无法完成自动化的持续集成,持续集成的过程代码可以通过git、maven、docker、k8s等工具来实现自动化的代码打包、部署。但是数据库的状态变化没有得到有效的自动变更,持续集成的过程的自动化就无法实现。
这也就是我们学习Flyway的目的:Flyway能够自动的帮助我们有效的同步各个发布数据库之间的状态,不管你是加了或者删了一个字段,还是新加了一张表,他都能自动化的跟随项目的发布同时发布。
5 FlyWay的工作原理
在SpringBoot中使用flyway进行数据库版本管理
首先项目启动flyway会去db/migration下面扫描文件,获取文件名,并解析版本号
然后去schema_version_history表里面找对应的版本执行信息,如果你的文件版本号大于数据库记录版本,就执行脚本。否则就忽略。
Flyway 需要在 DB 中先创建一个 metadata 表 (缺省表名为 flyway_schema_history), 在该表中保存着每次 migration (迁移)的记录, 记录包含 migration 脚本的版本号和 SQL 脚本的 checksum 值。下图表示了多个版本数据库变更。
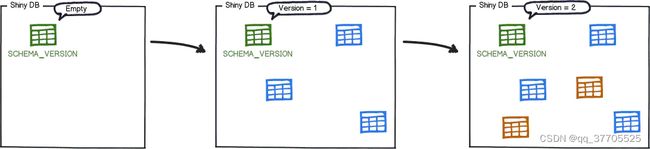
对应的 metadata 表记录
Flyway 扫描文件系统或应用程序的类路径读取 DDL 和 DML 以进行迁移。根据metadata 表进行检查迁移。如果脚本声明的版本号小于或等于标记为当前版本的版本号之一,将忽略它们。其余迁移是待处理迁移:可用,但未应用。最后按版本号对它们进行排序并按顺序执行 并将执行结果写入 metadata 表。

修改V1.0.0__Add_table_user.sql
修改sql脚本,一般int类型后面不加长度定义,将age int(3) NOT NULL ,改成age int NOT NULL 。再次启动 Spring Boot 应用 。
提示如下异常:
Flyway在升级数据库的时候,会检查已经执行过的版本对应的脚本是否发生变化,包括脚本文件名,以及脚本内容。如果flyway检测到发生了变化,则抛出错误,并终止升级。
上面抛出异常正因为我们开启了校验,所以对于checksum不一致的会抛出异常。
6 flyway是如何工作的
flyway工作流程如下:
项目启动,应用程序完成数据库连接池的建立后,Flyway自动运行。
初次使用时,flyway会创建一个 flyway_schema_history 表,用于记录sql执行记录。
Flyway会扫描项目指定路径下(默认是 classpath:db/migration )的所有sql脚本,与 flyway_schema_history 表脚本记录进行比对。如果数据库记录执行过的脚本记录,与项目中的sql脚本不一致,Flyway会报错并停止项目执行。
如果校验通过,则根据表中的sql记录最大版本号,忽略所有版本号不大于该版本的脚本。再按照版本号从小到大,逐个执行其余脚本。
6 springboot环境下使用flyway
6.1 依赖
org.springframework.boot
spring-boot-starter-web
mysql
mysql-connector-java
runtime
8.0.25
org.mybatis.spring.boot
mybatis-spring-boot-starter
2.2.1
org.flywaydb
flyway-core
6.1.0
然后我们要保证数据库里面有spring.datasource的数据源配置。并且在application.properties中添加如下的配置
6.2 在application.yml
spring:
# 数据库连接配置
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/flyway-demo?characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: root
flyway:
# 是否启用flyway
enabled: true
# flyway 的 clean 命令会删除指定 schema 下的所有 table, 生产务必禁掉。这个默认值是 false 理论上作为默认配置是不科学的。
clean-disabled: true
# 编码格式,默认UTF-8
encoding: UTF-8
# 迁移sql脚本文件存放路径,默认db/migration
locations: classpath:db/migration
# metadata 版本控制信息表 默认 flyway_schema_history
table: flyway_schema_history
# 迁移sql脚本文件名称的前缀,默认V
sql-migration-prefix: V
# 迁移sql脚本文件名称的分隔符,默认2个下划线__
sql-migration-separator: __
# 迁移sql脚本文件名称的后缀
sql-migration-suffixes: .sql
# 执行迁移时是否自动调用验证 当你的 版本不符合逻辑 比如 你先执行了 DML 而没有 对应的DDL 会抛出异常
# 迁移时是否进行校验,默认true
validate-on-migrate: true
# 如果没有 flyway_schema_history 这个 metadata 表, 在执行 flyway migrate 命令之前, 必须先执行 flyway baseline 命令
# 设置为 true 后 flyway 将在需要 baseline 的时候, 自动执行一次 baseline。
# 当迁移发现数据库非空且存在没有元数据的表时,自动执行基准迁移,新建schema_version表
baseline-on-migrate: true
# 指定 baseline 的版本号,默认值为 1, 低于该版本号的 SQL 文件, migrate 时会被忽略
baseline-version: 1
# 是否允许不按顺序迁移 开发建议 true 生产建议 false
out-of-order: false
# 需要 flyway 管控的 schema list,这里我们配置为flyway 缺省的话, 使用spring.datasource.url 配置的那个 schema,
# 可以指定多个schema, 但仅会在第一个schema下建立 metadata 表, 也仅在第一个schema应用migration sql 脚本.
# 但flyway Clean 命令会依次在这些schema下都执行一遍. 所以 确保生产 spring.flyway.clean-disabled 为 true
schemas: flyway
6.3 根据配置文件中填写的脚本存放路径,创建文件夹
根据上面配置文件中的脚本存放路径,我们需要在resource目录下建立文件夹 db/migration 。
添加需要运行的sql脚本。sql脚本的命名一定要规范,否则运行flyway会报错
命名规则主要有两种:
仅需要被执行一次的SQL命名以大写的"V"开头,V+版本号(版本号的数字间以”.“或”_“分隔开)+双下划线(用来分隔版本号和描述)+文件描述+后缀名。例如: V20201100__create_user.sql、V2.1.5__create_user_ddl.sql、V4.1_2__add_user_dml.sql 。
可重复运行的SQL,则以大写的“R”开头,后面再以两个下划线分割,其后跟文件名称,最后以.sql结尾。(不推荐使用)比如: R__truncate_user_dml.sql 。
其中,V开头的SQL执行优先级要比R开头的SQL优先级高。
创建完成后,目录应如下所示:

其中2.1.6、2.1.7和every的文件夹不会影响flyway对SQL的识别和运行,可以自行取名和分类。
大写V后面紧跟数据库脚本的版本号(递增形式、不能重复),然后两个下划线,之后是对脚本内容进行描述。如:V1.1__create_table.sql是用于创建表结构的数据库脚本,内容是create table之类的DDL。 第二个脚本是对数据库中person表进行了更新。总之脚本里面的内容,就是你希望对spring.datasource代表的数据库进行的操作,可以是表的创建、删除、修改,也可以是对数据的创建删除修改。
当然,我个人不建议将DML-SQL写入脚本,也就是不要在这个脚本里面写insert、update、delete。以免不注意的情况下,造成生产数据的误操作。如果你们公司在生产上线管理方面没有严格的审核程序,在生产环境下,就干脆不要使用flyway,方便开发是一方面,生产安全更为重要!
最后,启动SpringBoot项目,在该目标库范围内没有执行过的SQL脚本被执行。并将脚本执行信息保存在数据库的schema_version_history数据表里面。
7 启动项目, 通过flyway执行定义好的脚本
在控制台可以看到相关日志打印,并在数据库中查看到已经创建好的表和相关记录变更。


如果我们修改V2__add_user.sql中的内容,再次执行的话,就会报错,提示信息如下:
[ERROR] Migration checksum mismatch for migration version 2
如果我们修改了R__add_unknown_user.sql,再次执行的话,该脚本就会再次得到执行,并且flyway的历史记录表中也会增加本次执行的记录。
8 maven插件的使用

9 插件命令说明
此时,我们双击执行上图中的flyway:migrate的效果和启动整个工程执行migrate的效果是一样的。
其它命令的作用如下:
baseline
对已经存在数据库Schema结构的数据库一种解决方案。实现在非空数据库新建MetaData表,并把Migrations应用到该数据库;也可以在已有表结构的数据库中实现添加Metadata表。
clean
清除掉对应数据库Schema中所有的对象,包括表结构,视图,存储过程等,clean操作在dev 和 test阶段很好用,但在生产环境务必禁用。
info
用于打印所有的Migrations的详细和状态信息,也是通过MetaData和Migrations完成的,可以快速定位当前的数据库版本。
repair
repair操作能够修复metaData表,该操作在metadata出现错误时很有用。
undo
撤销操作,社区版不支持。
validate
验证已经apply的Migrations是否有变更,默认开启的,原理是对比MetaData表与本地Migrations的checkNum值,如果值相同则验证通过,否则失败。
10 flyway知识补充
flyway执行migrate必须在空白的数据库上进行,否则报错。
对于已经有数据的数据库,必须先baseline,然后才能migrate。
clean操作是删除数据库的所有内容,包括baseline之前的内容。
尽量不要修改已经执行过的SQL,即便是R开头的可反复执行的SQL,它们会不利于数据迁移。
当需要做数据迁移的时候,更换一个新的空白数据库,执行下migrate命令,所有的数据库更改都可以一步到位地迁移过去。
11 flyway配置清单
flyway.baseline-description对执行迁移时基准版本的描述.
flyway.baseline-on-migrate当迁移时发现目标schema非空,而且带有没有元数据的表时,是否自动执行基准迁移,默认false.
flyway.baseline-version开始执行基准迁移时对现有的schema的版本打标签,默认值为1.
flyway.check-location检查迁移脚本的位置是否存在,默认false.
flyway.clean-on-validation-error当发现校验错误时是否自动调用clean,默认false.
flyway.enabled是否开启flywary,默认true.
flyway.encoding设置迁移时的编码,默认UTF-8.
flyway.ignore-failed-future-migration当读取元数据表时是否忽略错误的迁移,默认false.
flyway.init-sqls当初始化好连接时要执行的SQL.
flyway.locations迁移脚本的位置,默认db/migration.
flyway.out-of-order是否允许无序的迁移,默认false.
flyway.password目标数据库的密码.
flyway.placeholder-prefix设置每个placeholder的前缀,默认${.
flyway.placeholder-replacementplaceholders是否要被替换,默认true.
flyway.placeholder-suffix设置每个placeholder的后缀,默认}.
flyway.placeholders.[placeholder name]设置placeholder的value
flyway.schemas设定需要flywary迁移的schema,大小写敏感,默认为连接默认的schema.
flyway.sql-migration-prefix迁移文件的前缀,默认为V.
flyway.sql-migration-separator迁移脚本的文件名分隔符,默认__
flyway.sql-migration-suffix迁移脚本的后缀,默认为.sql
flyway.tableflyway使用的元数据表名,默认为schema_version
flyway.target迁移时使用的目标版本,默认为latest version
flyway.url迁移时使用的JDBC URL,如果没有指定的话,将使用配置的主数据源
flyway.user迁移数据库的用户名
flyway.validate-on-migrate迁移时是否校验,默认为true
12 总结
总结
通过2个版本的SQL演示,如果有高版本的SQL文件存在于db/migration目录,当启动应用的时候就会自动执行SQL到数据库中,也就是我们的目标:使用 Flyway 进行数据库版本控制。
这里总结了一些在实际开发中的使用经验:
生产务必禁 spring.flyway.cleanDisabled=false 。
尽量避免使用 Undo 模式,使用Versioned模式新建高版本SQL文件。
开发版本号尽量根据团队来进行多层次的命名避免混乱。比如 V1.0.1__ProjectName_{Feature|Bugfix}_Developer_Description.sql ,这种命名同时也可以获取更多脚本的相关功能、开发者的信息。
spring.flyway.outOfOrder 取值 生产上使用 false,开发中使用 true。
多个系统公用一个 数据库 schema 时配置spring.flyway.table ,为不同的系统设置不同的 metadata 表名,而不使用缺省值 flyway_schema_history 。
