C语言篇 + 指针进阶练习 + qsort模拟实现(回调函数思想) + 指针和数组笔试题

目录
- 前言
- 冒泡排序
- 了解qsort
- c语言库qsort的使用
- qsort模拟实现
- 指针和数组笔试题解析
-
- 一维数组
- 字符数组
- 二维数组
- 总结: 数组名的意义
前言
qsort(quicksort)根据你给的比较函数给一个数组快速排序,是通过指针移动实现排序功能,关于qsort的模拟实现,本次在底层的使用的排序算法是使用的冒泡排序,那么就先来了解一下冒泡排序吧,另外作为C/C++程序员我们更应该透彻地去理解指针和数组,这里我准备了几道大题,内容会很精彩,期待你的点赞
冒泡排序
1、比较相邻的元素。如果第一个比第二个大,就交换他们两个。
2、对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
3、针对所有的元素重复以上的步骤,除了最后一个。
4、持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
/* 打印 */
void print(int arr[],int sz)
{
for (int i = 0; i < sz; i++)
{
printf("%d ",arr[i]);
}
printf("\n");
}
/* 交换 */
void Swap(int *n1,int *n2)
{
int tmp = *n1;
*n1 = *n2;
*n2 = tmp;
}
/* 冒泡算法 */
void bubble_sort(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz - 1; i++)
{
int j = 0;
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
Swap(&arr[j],&arr[j + 1]);
}
}
}
}
int main()
{
int arr[10] = {9,8,7,6,5,4,3,2,1,0};
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr,sz);
print(arr,sz);
return 0;
}
以上的讲解大家对冒泡排序应该有了一个清晰的认知了,接下来进入我们的主题
了解qsort

compare使用文档

void qsort(void *base, //待排序的对象,写成void*的形式便于排序任意类型的数据
size_t num, //待排序的元素个数
size_t width,//一个元素的大小,单位是字节
int(__cdecl *compare)
(const void *elem1, const void *elem2))
{
}
>compare指向排序时用来比较两个元素的函数
> void *无具体类型的指针,能够接受任意类型的地址
> 缺点:不能进行运算,不能解引用
> 举例:void *p3;
> p3++ //err
报错信息
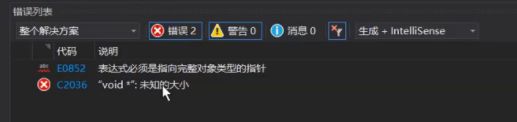
c语言库qsort的使用
整形类型数据的排序
void print(int arr[],int sz)
{
for (int i = 0; i < sz; i++)
{
printf("%d ",arr[i]);
}
printf("\n");
}
int compare_int(const void *elem1, const void *elem2)
{
/* 升序 */
return *(int*)elem1 - *(int*)elem2;
/* 降序 */
//return *(int*)elem2 - *(int*)elem1;
}
int main()
{
int arr[10] = {9,8,7,6,5,4,3,2,1,0};
int n = sizeof(arr) / sizeof(arr[0]);
/* 排序 */
qsort(arr,n,sizeof(arr[0]), compare_int);
/* 打印 */
print(arr, n);
return 0;
}
浮点型型数据的排序
这里要提一句,浮点型数据类型会有精度的丢失,不能直接通过两个形参值相减后直接返回结果,通过关系比较返回合适的整形
int cmp_double(const void* elem1, const void* elem2)
{
return ((*(double*)elem1- *(double*)elem2) > 0)? 1:-1;
}
int main()
{
double a[] = { 1.2,56.4,0.56,456.89,32.4 };
int sz = sizeof(a) / sizeof(a[0]);
qsort(a, sz, sizeof(a[0]), cmp_double);
for (int i = 0; i < sz; i++)
{
printf("%.2f ", a[i]);
}
return 0;
}
结构体类型数据的排序
typedef struct Student
{
int age;
char name[20];
float score;
}Stu;
void print(Stu arr[], int sz)
{
for (int i = 0; i < sz; i++)
{
printf("%.1f ", arr[i].score);
}
printf("\n");
}
int compare_name(const void *elem1, const void *elem2)
{
/* 升序,这里比较的是字符串的长度*/
return strcmp(((Stu*)elem1)->name, ((Stu*)elem2)->name);
}
int compare_age(const void *elem1, const void *elem2)
{
/* 升序 */
return ((Stu*)elem1)->age - ((Stu*)elem2)->age;
}
float compare_score(const void *elem1, const void *elem2)
{
/* 升序 */
return ((Stu*)elem1)->score - ((Stu*)elem2)->score;
}
int main()
{
Stu s[3] = { {18,"zhangsan",99.5},{20,"lisi",66.5},{21,"wangwu",76} };
int n = sizeof(s) / sizeof(s[0]);
qsort(s,n,sizeof(s[0]), compare_score);
print(s, n);
return 0;
}
qsort模拟实现
typedef struct Student
{
int age;
char name[20];
float score;
}Stu;
int compare_name(const void *elem1, const void *elem2)
{
/* 升序,这里比较的是字符串的长度*/
return strcmp(((Stu*)elem1)->name, ((Stu*)elem2)->name);
}
/* 输出整形数据 */
void print1(int arr[], int sz)
{
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
/* 输出结构体成员数据 */
void print2(Stu arr[], int sz)
{
for (int i = 0; i < sz; i++)
{
printf("%s ", arr[i].name);
}
printf("\n");
}
void Swap(char *buf1,char *buf2, size_t width)
{
size_t i = 0;
/* 交换宽度次 */
for (i = 0; i < width; i++)
{
int tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
/* 指针往后迭代 */
buf1++;
buf2++;
}
}
int BubbleSrot_cmp(const void *elem1, const void *elem2)
{
return *(char*)elem1 - *(char*)elem2;
}
/* 使用回调函数实现一个通用的冒泡排序函数 */
void BubbleSrot(void *base, size_t num, size_t width, int (*BubbleSrot_cmp)(const void *elem1, const void *elem2))
{
//趟数
size_t i = 0;
for (i = 0; i < num - 1; i++)
{
//比较的对数
size_t j = 0;
for (j = 0; j < num - 1 - i; j++)
{
//判断
if (BubbleSrot_cmp((char*)base + j * width, (char*)base + (j + 1) * width) > 0)
{
//交换
Swap((char*)base + j * width, (char*)base + (j + 1) * width,width);
}
}
}
}
/* 整形数据排序*/
void test3()
{
int arr[10] = { 9,8,66,47,65,77,2,1,0 ,4};
int n = sizeof(arr) / sizeof(arr[0]);
BubbleSrot(arr, n, sizeof(arr[0]), BubbleSrot_cmp);
print1(arr, n);
}
/* 结构体类型数据排序 */
void test4()
{
Stu s[3] = { {18,"zhangsan",99.5},{20,"lisi",66.5},{21,"wangwu",76} };
int n = sizeof(s) / sizeof(s[0]);
qsort(s, n, sizeof(s[0]), compare_name);
print2(s, n);
}
int main()
{
test3();
test4();
return 0;
}
int BubbleSrot_cmp(const void elem1, const void elem2)
{
return * (char * )elem1 - * (char * )elem2;
}
BubbleSrot_cmp是比较函数,这次的模拟实现是基于对compar函数的理解和运用,所以功能在本质上是一样的
指向比较两个元素的函数的指针。
qsort会反复调用这个函数来比较两个元素。它将遵循以下原型:
接受两个指针作为实参(都转换为const void)。该函数通过返回(以稳定和可传递的方式)来定义元素的顺序:
(char * )base写成这种形式主要是因为最合适,粒度更细,指针的步长跟类型是有关的,char的指针步长是1,p + 1跳过的是一个字节长度根据,这样一来(char * )base参与加减运算的时候步长就是1了,再通过(j * width)和(j + 1 ) * width 拿到相邻的 两个元素的地址,传递过去的实参大小取决于width的宽度,传递过去的指针比较指针所指向地址标识的那块空间存储数据的大小,确定是否执行交换,这里的排序是一个升序

void Swap(char *buf1,char *buf2, size_t width)
{
size_t i = 0;
/* 交换宽度次 */
for (i = 0; i < width; i++)
{
int tmp = *buf1;
*buf1 = *buf2;
*buf2 = tmp;
/* 指针往后迭代 */
buf1++;
buf2++;
}
}
Swap函数交换的是指针指向的地址的宽度个字节
此时我们可以看到e1指向了数组的首地址,而这3个元素的值都是9、8、66,
执行第一次循环8和9换了,执行次数的条件限制是 i < width,也就是会循环 width - 1 次,而恰好int类型的数据占4字节,所以循环结束了这两个值也交换完了
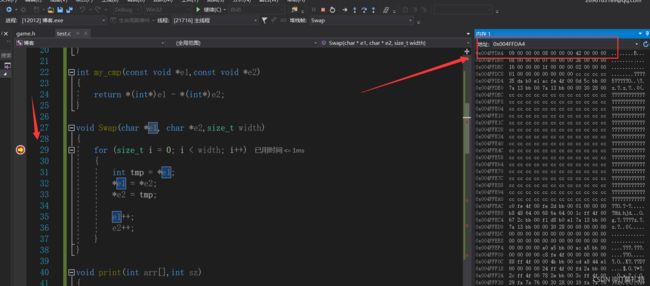
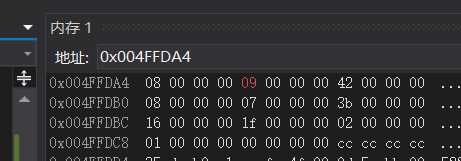

指针和数组笔试题解析
一维数组
了解sizeof和strlen
sizeof是一个操作符,求的是变量所占空间的大小,求类型创建的变量所占空间的大小,单位是字节
strlen是一个库函数,功能是求字符串长度,从起始位置开始向后计数直到遇见‘\0’结束标记,中间统计的字符个数就是字符串的长度

//一维数组
1、int a[4] = {1,2,3,4};
//这是一个一维数组,数组的长度是4、数组的每个元素类型是int,数组的大小是16
2、printf("%d\n",sizeof(a));
//sizeof操作符与数组名单独放在一起,计算的是数组的大小,16
3、printf("%d\n",sizeof(a+0));
//a是数组首元素的地址,a + 0依旧是首元素的地址,计算地址的大小具体跟操作系统相关,4/8
4、printf("%d\n",sizeof(*a));
//a是首元素的地址,对地址解引用找到的是数组下标为0的整形元素,int占4个字节,4
5、printf("%d\n",sizeof(a+1));
//a是首元素的地址,a + 1跳过一个整形,但他还是一个地址,计算地址的大小具体跟操作系统相关,4/8
6、printf("%d\n",sizeof(a[1]));
//下标为1的整形元素,类型是int占4个字节
7、printf("%d\n",sizeof(&a));
//&a取出整个数组的地址,地址 + 1跳过一个数组的大小,但是a还是一个地址,计算地址的大小具体跟操作系统相关,4/8
8、printf("%d\n",sizeof(*&a));
//&a取出整个数组的地址(int(*)[4]),整个数组的大小是16,对数组的地址解引用,计算的是数组的大小,16
9、printf("%d\n",sizeof(&a+1));
//&a是数组的地址,&a + 1跳过整个数组,但是此时的&a + 1还是一个地址,计算地址的大小具体跟操作系统相关,4/8
10、printf("%d\n",sizeof(&a[0]));
//首元素的地址 int*, 4/8
11、printf("%d\n",sizeof(&a[0]+1));
//首元素的地址 int*, 首元素的地址+ 1 得到的是下标为1的元素地址,地址的大小跟操作系统相关,4/8
字符数组

//字符数组
char arr[] = {'a','b','c','d','e','f'};
printf("%d\n", sizeof(arr));
//sizeof(数组名)计算的是整个数组的大小,数组的大小跟元素类型和元素个数有关,6
printf("%d\n", sizeof(arr+0));
//sizeof并未与数组名单独放在一起,所以数组名表示的是数组首元素的地址,数组首地址+1跳过一个整形,可是他还是一个地址,地址的大小就是4/8
printf("%d\n", sizeof(*arr));
//sizeof并未与数组名单独放在一起,那他表示的就是数组首元素的地址,元素类型是char,首元素的地址就是char*,对char*指针解引用访问一个字节,1
printf("%d\n", sizeof(arr[1]));
//数组的元素类型是char,char类型所占用的空间是1个字节
.
printf("%d\n", sizeof(&arr));
//&数组名是取出整个数组的地址,数组的地址是类型是char(*)[6],是一个数组指针,既然是指针那么指针大小就跟操作系统有关,4/8
printf("%d\n", sizeof(&arr+1));
//&arr取出的是数组的地址,类型是 char(*)[6],数组的地址+1跳过的就是一个数组,即使是这样,但他还是一个地址,地址就是4/8
printf("%d\n", sizeof(&arr[0]+1));
//arr[0]表示的是数组首元素,&arr[0]取出数组首元素的地址,char*,字符指针 + 1 还是一个指针,4/8,但是此时的指针指向的是数组的第二个元素,因为char*的步长是1个字节


假设这是字符串在内存中存储时的内存布局,arr这个数组名是一个地址arr[ ]并不是给电脑看的,而是给程序员看的,在编译的时候就已经将机器指令转化为二进制指令了,而机器能看懂的只是指令,arr只是语法上方便程序员理解
而当这个数组被创建了伴随着这块这块空间被分配了,但是字符串前面的这一段空间和后面的这一段空间都是不确定的

char arr[] = {'a','b','c','d','e','f'};
printf("%d\n", strlen(arr));
//arr数组首地址会作为参数传递给strlen,strlen会从数组首地址开始往后找,直到运到‘\0’,而中间的字符计数就是字符
//串的长度,但是这个数组中并未包含‘\0’,strlen还会继续往后查找,至于‘\0’的出现时机决定了strlen求出字符串的长度,而这个‘\0’的出现时机又是不确定的,通过前面的画图我们知道这块空间仅仅我们知道的只,有'a','b','c','d','e','f',这里值得注意的是strlen往后访问的时候其实他已经越界了
printf("%d\n", strlen(arr+0));
//随机值,本质同上
printf("%d\n", strlen(*arr));
// arr是首元素的地址,*arr是对首元素的
//地址解引用,取出来的值是‘a’,'a'的ascii码值就是97,那么strlen就会将'a'的ascii码值是97看成是一个地址,他是一个非法的地址,野指针,那么程序就会崩溃
printf("%d\n", strlen(arr[1]));
//arr[1]取出的值是‘b’,'b'的ascii码是98,将b'的ascii码值98看成一个地址,也会引发程序错误 err
printf("%d\n", strlen(&arr));
//&arr 的类型是char(*)[6],strlen这个库函数的参数类型是 char *,当&arr作为实参传递过去,指向的还是数组首地址,strlen的功能实现是从起始地址向后查找直到遇见‘\0’终止,所以最后的结果也是随机值,因为‘\0’的出现时机不确定嘛
printf("%d\n", strlen(&arr+1));
//&arr取出的是整个数组的地址,&arr + 1跳过一个数组,从之后的地址开始往后查找直到遇见‘\0’结束,但是‘\0’的出现时机并不确定,所以还是一个随机值
printf("%d\n", strlen(&arr[0]+1));
//&arr[0] + 1跳过一个字符,来到第二个值的地址处,接着往后查找直到遇到‘\0’,而‘\0’的出现时机又不确定,所以还是一个随机值,只不过他的计数比从strlen从首元素地址往后查找计数少一个

字符串的末尾会自动增加一个‘\0’
char arr[] = "abcdef";
printf("%d\n", sizeof(arr));
//sizeof(数组名)计算整个数组的大小,7
printf("%d\n", sizeof(arr+0));
//arr并未单独放在sizeof中,所以计算的是数组首元素的地址,地址的大小就是4/8
printf("%d\n", sizeof(*arr));
//arr是数组首元素的地址,对数组首元素的地址解引用访问的就是首字符,char类型所占大小就是1,*arr是1
printf("%d\n", sizeof(arr[1]));
//通过下标访问数组的第二个元素,char类型的字符所占空间还是1
printf("%d\n", sizeof(&arr));
//&arr取出整个数组的地址,数组的地址还是4/8
printf("%d\n", sizeof(&arr+1));
//&arr取出整个数组的地址,&arr + 1跳过整个数组,但他还是一个地址,地址还是4/8
printf("%d\n", sizeof(&arr[0]+1));
//&arr[0]取出的是数组首元素地址,数组首元素地址 + 1,访问第二个字符地址,但是还是一个地址,地址大小就是4/8

char arr[] = "abcdef";
printf("%d\n", strlen(arr));
//strlen从起始位置开始往后查找,直到遇见‘\0’结束,而中间的字符计数都是字符串的长度,6
printf("%d\n", strlen(arr+0));
//6,本质同上
printf("%d\n", strlen(*arr));
//将'a'的ascii码值97看成一个地址,也会引发程序错误 err
printf("%d\n", strlen(arr[1]));
//将'b'的ascii码值98看成一个地址,也会引发程序错误 err
printf("%d\n", strlen(&arr));
//&arr取出数组的地址类型是char(*)[6],将数组的地址传递给strlen会发生隐士类型转换,此时的指着指向的还是数组首元素的地址,从数组首元素的地址查找遇到‘\0’终止,中间的字符计数就是数组的大小
printf("%d\n", strlen(&arr+1));//随机值
printf("%d\n", strlen(&arr[0]+1));
//从第二个元素开始向后数,遇到‘\0’停止5

const char *p = "abcdef";
printf("%d\n", sizeof(p));//p是指针变量,4/8
printf("%d\n", sizeof(p+1));
//p + 1是指针变量跳过一个字符指向后一个字符的地址,4/8
printf("%d\n", sizeof(*p));
//指针p指向的是字符串的首地址,指针解引用访问的是第一个字符,字符占用1字节空间
printf("%d\n", sizeof(p[0]));
//等价于*(p + 0),还是首字符,1
printf("%d\n", sizeof(&p));
//指针变量所占用的大小就是 4/8
printf("%d\n", sizeof(&p+1));
// p是char *类型,&p是char**类型 ,
// &p + 1跳过的是4字节因为char *类型所占空间是4字节,指针变量所占用的空间就是 4/8
printf("%d\n", sizeof(&p[0]+1));
//指针跳过一个字节指向后一个字符,但是它还是一个地址,地址就是4/8

const char *p = "abcdef";
printf("%d\n", strlen(p));//6
printf("%d\n", strlen(p+1));//5
printf("%d\n", strlen(*p));//*p取出来的字符是a,a的ascii码值是97,将字符a,ascii值为97的字符放到strlen中会出错,因为这是不合法的,err
printf("%d\n", strlen(p[0]));//,同上,err
printf("%d\n", strlen(&p));
//&p取出的是指针变量的地址,不是字符串首元素的地址, strlen去求指针变量的地址什么时候遇到结束标记('\0')又是未知的,所以是随机值
printf("%d\n", strlen(&p+1));
//随机值,本质同上,但是&p + 1与 &p之间的差值却并没有关联关系,因为strlen去求指针变量的地址什么时候遇到结束标记('\0')又是未知的
printf("%d\n", strlen(&p[0]+1));//5
二维数组

介于二维数组会复杂一点,先来看二维数组的内存布局再来做这道题吧,这样一来也会有一个细致的印象

//二维数组
int a[3][4] = {0};
printf("%d\n",sizeof(a));
//整个二维数组的大小:3*4*int
printf("%d\n",sizeof(a[0][0]));
//通过下标访问到首元素,int类型占4字节
printf("%d\n",sizeof(a[0]));
//a[0]表示的是二维数组的第0行的一维数组,a[0]是一维数组的数组名,
//同样也是一维数组的首元素地址,这个一维数组能能访问的元素也就是a[0][j],sizeof(数组名)计算的是整个数组的大小,,16
printf("%d\n",sizeof(a[0]+1));
// a[0]并没有单独放在sizeof内部,所以它表示的是一个二维数组第0行的一维
//数组,他是一个数组的首元素的地址a[0][0],类型是int *,a[0] + 1 跳过的是一个整形,现在指向的是第二个元素a[0][1],但是他还是一个地址,4/8
printf("%d\n",sizeof(*(a[0]+1)));
//a[0] + 1,是二维数组的第0行的一维数组的首元素地址,+ 1跳过的是一个整
//形,*(a[0] + 1)此时是访问二维数组的第0行的一维数组的第二个元素,下标为a[0][1]
printf("%d\n",sizeof(a+1));
//数组名并没有单独放在sizeof内部,也没有&,所以a表示【首元素】(第一行)
//的地址,a + 1表示的就是第二行的地址,(可以理解为数组名a表示的是二维
//数组的第一行一维数组的地址,他是一个数组的地址,数组的地址 + 1跳过的是一个一维数组的大小),但是它还是一个地址,4/8
printf("%d\n",sizeof(*(a+1)));
//数组名并没有单独放在sizeof内部,也没有&,所以a表示【首元素】(第一行)
//的地址,a + 1表示的就是第二行的地址,*(a + 1)访问的是二维数组中第二
//行的地址,相当于访问整个一维数组,占16个字节
printf("%d\n",sizeof(&a[0]+1));
//&a[0]取出的是二维数组的第一行的地址,他是一个数组的地址,
//数组的地址 + 1跳过的是一个数组的大小,现在表示的是二维数组的第二行的地址,他是一个数组的地址,地址还是4/8
printf("%d\n",sizeof(*(&a[0]+1)));
//&a[0]取出的是二维数组的第一行的地址(数组的地址),&a[0]+1跳过了一个一
//维数组的大小,*(&a[0]+1)访问的就是二维数组中的第二行的地址,对数组的
//地址解引用放到sizeof内部,计算的是整个数组的大小,16
//*(&a[0] + 1) --> *(&a[1]) --> a[1],
printf("%d\n",sizeof(*a));
//a表示二维数组首元素的地址,对首元素的地址解引用访问的就是首元素,类型
//是int占4字节
printf("%d\n",sizeof(a[3]));
//注意这里并不会越界,sizeof是一个计算类型大小的操作符,它并不会去检查这块空间存不存在,只
//是去计算这块空间应该会占用多少字节的大小,a[3]还是表示二维数组第4行的数组名,既然是
//数组名单独放在sizeof中计算的是数组的大小,16
总结: 数组名的意义
- sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小。
- &数组名,这里的数组名表示整个数组,取出的是整个数组的地址。
- 除此之外所有的数组名都表示首元素的地址。

程序的结果是什么?
答案:2 5
分析:*(a + 1),a + 1是从数组首地址偏移一个整形的大小,表示的是数组第二个元素的地址 * (a + 1),访问的是数组第二个元素,再来
看 * (ptr - 1),ptr指针的初始化的时候是指向&a + 1的地址处,ptr - 1不就又回到了数组的最后一个元素处的位置吗


答案:00100014、00100001、00100004
分析:指针 + 1会偏移多少个字节是取决于它自身的类型,已知结构体大小是20个字节,那么指针 + 1就会偏移20个字节,由于地址是以十六进制的形式表示的,十进制的20最终会变成十六进制的14,所以是0x100014,
(unsigned long)p + 0x1);会将指针变量强制类型转换成无符号整形,他是一个整数,整数+ 1 得到的结果就是0x100001
(unsigned int*)p + 0x1);,将结构体指针强制类型转换为无符号整形指针,指针的步长跟类型有关,那么 无符号整形指针 + 1就会跳过4字节得到的结果就是0x100004,
后期还会继续更新,谢谢大家
