计算机系统结构 第七章
目录
- 1.简述伪相联的基本思想。
- 2.Cache不命中率先下降后上升导致Cache不命中率先下降后上升的原因是什么?
- 3.降低 Cache不命中率有哪几种方法?简述其基本思想。
- 4.简述减小 Cache 不命中开销的几种方法 。
- 5.简述采用容量小且结构简单的Cache所带来的好处 。
- 6.假定存储系统在延迟到30个时钟周期后 ,每2个时钟周期能送出16B。即:经过32个时钟周期,它可提供16B;经过34个时钟周期,可提供32 B;以此类推。命中时间与块大小无关 ,为1个时钟周期 ,分别计算下列各种容量的 Cache 的平均访存时间 。
- 7. 在三级 Cache 中,第一级 Cache 、第二级 Cache和第三级 Cache的局部不命中率分别为4%、30%和50% 。它们的全局不命中率各是多少?
- 8.考虑两种不同组织结构的Cache:直接映象Cache和两路组相联Cache,试问它们对CPU的性能有何影响?先求平均访存时间,然后再计算CPU性能。分析时请用以下假设:
1.简述伪相联的基本思想。
在逻辑上把直接映象Cache的空间上下平分为两个区。对于任何一次访问, 伪相联Cache先按直接映象Cache的方式去处理。若命中,则其访问过程与直接映象Cache的情况一样。若不命中,就与直接映像不同了, 而是再到另一区相应的位置去查找。若找到,则发生了伪命中,否则就只好访问下一级存储器。
2.Cache不命中率先下降后上升导致Cache不命中率先下降后上升的原因是什么?
一方面它减少了强制性不命中; 另一方面,由于增加块大小会减少Cache中块的数目, 所以有可能会增加冲突不命中。
3.降低 Cache不命中率有哪几种方法?简述其基本思想。
有8种方法
1.增加Cache块大小 :增加块大小增强了空间局部性,减少了强制性不命中(但是减少了Cache中块的数目,所以有可能会增加冲突不命中;)
2.增加Cache的容量 :在片外Cache中用的比较多
3.提高相联度:2:1Cache经验规则:容量为N的直接映像Cache的不命中率和容量为N/2的两路组相联Cache的不命中率差的不多
4.伪相联Cache:在逻辑上把直接映象Cache的空间上下平分为两个区。对于任何一次访问, 伪相联Cache先按直接映象Cache的方式去处理。若命中,则其访问过程与直接映象Cache的情况一样。若不命中,就与直接映像不同了, 而是再到另一区相应的位置去查找。若找到,则发生了伪命中,否则就只好访问下一级存储器。
5.硬件预取:预取内容既可放入Cache,也可放在外缓冲器中。
例如:指令流缓冲器(先把指令放在缓冲器中执行的时候从缓冲器中取不用从速度慢的内存中取)
6.编译器控制的预取:在编译时加入预取指令,在数据被用到之前发出预取请求。在预取数据的同时,处理器应该能继续执行,这样预取才有意义。
7.编译优化:通过软件的方法降低不命中率。编译优化技术包括:(1)数组合并:将本来相互独立的多个数组合并成为一个复合数组,以提高访问它们的局部性。(2)内外循环交换(3)循环融合: 将若干个独立的循环融合为单个的循环。这些循环访问同样的数组,对相同的数据作不同的运算。这样能使得读入Cache的数据在被替换出去之前,能得到反复的使用 。
8.牺牲Cache:这种方法是在Cache和其下一级存储的数据通路上增设一个全相联的小Cache,称为“牺牲Cache”牺牲Cache中存放因冲突而被替换出去的那些块。每当发生不命中时,在访问下一级存储器之前,先检查“牺牲Cache”中是否有所需要的块。若有,就将该块与Cache中某个块(按替换规则选择)交换,把所需要的块从“牺牲Cache”调入Cache。
4.简述减小 Cache 不命中开销的几种方法 。
1.采用两级Cache:第一级Cache小而快、第二级Cache容量大
2.让读不命中优先于写:Cache中的写缓冲器导致对存储器访问的复杂化,在读不命中时(在Cache中未找到 ),所读单元的最新值有可能还在写缓冲器中,尚未写入主存。解决读不命中的方法有两种:(1)推迟对读不命中的处理(2)在读没命中时,检查写缓冲器中的内容是不是所读单元的最新值。让读优先于写,最后在写入主存。
3.写缓冲合并:依靠写缓冲来减少对下一级存储器写操作和时间。如果写缓冲器为空,就把数据和相应地址写入该缓冲器。如果写缓冲器中已经有了待写入的数据,就要把这次的写入地址与写缓冲器中已有的所有地址进行比较,看是否有匹配的项。如果有地址匹配而对应的位置又是空闲的,就把这次要写入的数据与该项合并。这就叫写缓冲合并。如果写缓冲器满且又没有能进行写合并的项,就必须等待。
4.请求字处理技术:当CPU所请求的字到达后,不等整个块都调入Cache, 就可把该字发送给CPU,让等待的CPU尽早重启动。两种方案: (1)尽早重启动:一旦请求字到达,就立即发送给CPU,让CPU继续执行。(2)请求字优先:调块时,从请求字所在的位置读起。这样,第一个读出的字便是请求字。将之立即发送给CPU。
5.非阻塞Cache技术:Cache不命中时仍允许CPU进行其它的命中访问。即允许“不命中下命中”。
5.简述采用容量小且结构简单的Cache所带来的好处 。
- 硬件越简单,速度就越快;
- 应使Cache足够小,以便可以与CPU一起放在同一块芯片上。
6.假定存储系统在延迟到30个时钟周期后 ,每2个时钟周期能送出16B。即:经过32个时钟周期,它可提供16B;经过34个时钟周期,可提供32 B;以此类推。命中时间与块大小无关 ,为1个时钟周期 ,分别计算下列各种容量的 Cache 的平均访存时间 。
① 块大小为 32 B , Cache 容量为 1KB ,不命中率为13. 34% 。
② 块大小为 32 B , Cache 容量为 4KB ,不命中率为7. 24% 。
③ 块大小为 64 B , Cache 容量为 16KB ,不命中率为2. 64% 。
④ 块大小为 128 B , Cache 容量为 16 KB ,不命中率为2. 779% 。
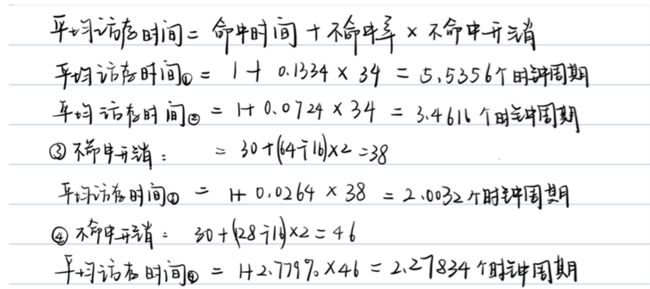
7. 在三级 Cache 中,第一级 Cache 、第二级 Cache和第三级 Cache的局部不命中率分别为4%、30%和50% 。它们的全局不命中率各是多少?
第一级Cache的全局不命中率=它的局部不命中率=4%
第二级Cache的全局不命中率=第一级Cache的全局不命中率×第二级Cache局部不命中率=4%×30%=1.2% 第三级Cache的、全局不命中率 =第一级cache的全局不命中率×第二级cache局部不命中率×第三级cache局部不命中率=4%×30%×50%=0.6%。
8.考虑两种不同组织结构的Cache:直接映象Cache和两路组相联Cache,试问它们对CPU的性能有何影响?先求平均访存时间,然后再计算CPU性能。分析时请用以下假设:
(1)理想Cache(命中率为100%)情况下的CPI为2.0,时钟周期为2ns,平均每条指令访存1.3次。
(2)两种Cache容量均为64KB,块大小都是32字节。
(3)在组相联Cache中,由于多路选择器的存在而使CPU的时钟周期增加到原来的1.10倍。这是因为对Cache的访问总是处于关键路径上,对CPU的时钟周期有直接的影响。
(4) 这两种结构Cache的不命中开销都是70ns。(在实际应用中,应取整为整数个时钟周期)
(5) 命中时间为1个时钟周期,64KB直接映象Cache的不命中率为1.4%,相同容量的两路组相联Cache的不命中率为1.0%。


解: 平均访问时间=命中时间+失效率×失效开销
平均访问时间1-路=2.0+1.4% 80=3.12ns
平均访问时间2-路=2.0(1+10%)+1.0% 80=3.0ns
两路组相联的平均访问时间比较低
CPUtime=(CPU执行+存储等待周期)时钟周期
CPU time=IC(CPI执行+总失效次数/指令总数失效开销) 时钟周期
=IC((CPI执行时钟周期)+(每条指令的访存次数失效率失效开销时钟周期))
CPU time 1-way=IC(2.02+1.20.01480)=5.344IC
CPU time 2-way=IC(2.22+1.20.0180)=5.36IC
相对性能比: 5.36/5.344=1.003
直接映象cache的访问速度比两路组相联cache要快1.04倍,而两路组相联Cache的平均性能比直接映象cache要高1.003倍。因此这里选择两路组相联。