k8s scheduler 调度与 kubelet 启动 Pod 流程总结(四)
文章目录
-
- scheduler
-
- predicate 和 priority
- 资源需求
- 把 Pod 调度到指定 Node 上
-
- nodeSelector
- 亲和性和反亲和性
-
- 节点亲和性
- Pod 亲和性
- 污点和容忍度
- Controller Manager
-
- 控制器的工作流程
- 控制器的协同工作原理
- 通用Controller
- Kubelet
-
- kubelet 架构
- kubelet 管理 Pod 的核心流程
- Pod 启动流程
- kubelet 启动 Pod 的流程
- CRI
- CNI
-
- CNI 插件运行机制
- CNI 插件
scheduler
kube-scheduler 负责分配Pod到集群内的节点上,它监听kube-apiserver, 查询还未分配 Node 的 Pod, 然后根据调度策略为这些 Pod 分配节点 (更新 Pod 的 NodeName 字段)
调度器需要充分考虑的因素:
-
公平调度
当资源充分的时候,大家可以公平的一期调度,但是当资源不是那么充分的时候,就需要考虑优先级的问题,高优先级的先调度。
-
资源高效利用
有的任务需要指定资源消耗,比如说必须最少2个 CPU,就必须调度到剩余 CPU 2个或以上的节点.
有的节点内存消耗多,有的节点CPU消耗多,调度系统在各个节点间调度任务如何能够权衡各种因素,充分利用资源是一个难点。 -
Qos
任务申请过多的资源是浪费的,此时就需要资源限制来保证任务申请的资源既充分又不会浪费。
-
affinity 和 anti-affinity
亲和性和反亲和性,有时候有的作业希望跟某些节点相关,比如说计算密集型作业希望被调度到计算密集型节点上。
有的作业在部署时可能希望和已有的应用部署在同一个节点上。 -
数据本地化
镜像本地缓存
-
内部负载干扰
https://kubernetes.io/zh-cn/docs/concepts/workloads/pods/disruptions/
-
deadlines
predicate 和 priority
scheduler 调度分为两个阶段,predicate 和 priority:
- predicate: 过滤不符合条件的节点
- priority:优先级排序,选择优先级最高的节点
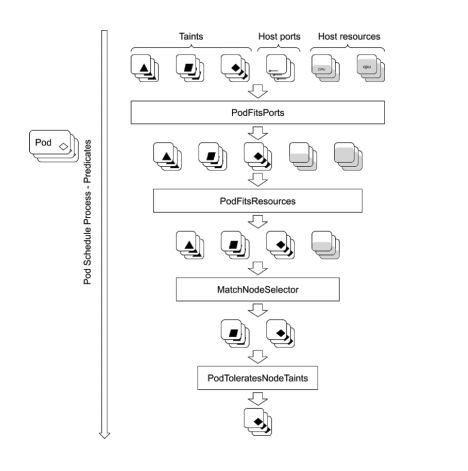
Predicates 策略


Predicates plugin 工作原理
Priorities 策略


资源需求
k8s 资源分配主要由 request 和 limit 来进行限制,request 表示 Pod 在正常运行之外申请的额外资源, limit 表示 Pod 最多能够使用的资源, limit 是由 linux 的cgroup 来做限制的,当超出 limit 之后,Pod 运行的程序将异常。
k8s 的资源分为可压缩资源和不可压缩资源,像 CPU 这种属于可压缩资源, 内存这种资源属于不可压缩资源。
在同一个节点中,当不可压缩资源出现抢占时,将会按照 Pod 配置的 request 和 limit 限制按照一定的策略进行驱逐。
具体的详细信息可以看这篇文章:
Kubernetes 资源分配之 Request 和 Limit 解析
磁盘资源需求
- 容器临时存储(ephemeral storage)包含日志和可写层数据,可以通过定义 Pod Spec 中的 limits.ephemeral-storage 和 requests.ephemeral-storage.
- Pod 调度完成后,计算节点对临时存储的限制不是基于 cgroup 的,而是由 kubelet 定时获取容器的日志和容器可写层的磁盘使用情况,如果超过限制,则会对 Pod 进行驱逐。
Init Container 的资源需求
- 当 kube-scheduler 调度带有多个 init 容器的 Pod 时, 只计算 cpu.request 最多的 init 容器,而不是计算所有的 init 容器的总和。
- 多个容器的init 是按顺序执行的,执行完后立即退出,所以申请最多的资源 init 容器中的所需资源,即可满足所有 init 容器需求。
- kube-scheduler 在计算该节点被占用的资源时, init 容器的资源依然会被纳入计算。因为 init 容器在特定情况下可能会被再次执行,比如由于更换镜像而引起 Sandbox 重建时。
具体使用demo
-
启动 Pod 时指定资源限制:
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: replicas: 1 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx resources: limits: memory: 1Gi cpu: 1 requests: memory: 256Mi cpu: 100m -
使用默认资源限制:
定义 LimitRange 对象来对 Pod 进行默认资源限制,当定义了 LimitRange 即使在 Pod 定义中没有定义资源限制,也会进行默认的资源限制。
apiVersion: v1 kind: LimitRange metadata: name: mem-limit-range spec: limits: - default: memory: 512Mi defaultRequest: memory: 256Mi type: Container ################# apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: replicas: 1 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx
把 Pod 调度到指定 Node 上
官方文档地址
可以通过 nodeSelector、nodeAffinity、podAffinity 以及 Taints 和 tolerations 等来将 Pod 调度到需要的 Node 上。
也可以通过设置 nodeName 参数,将 Pod 调度到指定 Node 节点上。
nodeSelector
nodeSelector 直接指定Pod 部署在哪台节点上。
nodeSelector 实战步骤
https://kubernetes.io/zh-cn/docs/tasks/configure-pod-container/assign-pods-nodes/
亲和性和反亲和性
文档地址:https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/assign-pod-node/
亲和性分为硬亲和性和软亲和性,硬亲和性相当于 nodeSelector 的升级版,你可以定义更多的逻辑决定运行在哪个Node 上或者和哪些 Pod 运行在同一个 Node 上,软亲和是尽量满足对应的控制逻辑。
节点亲和性
节点亲和性主要由两种:
- requiredDuringSchedulingIgnoredDuringExecution: 调度器只有在规则被满足的时候才能执行调度。此功能类似于 nodeSelector, 但其语法表达能力更强。
- preferredDuringSchedulingIgnoredDuringExecution: 调度器会尝试寻找满足对应规则的节点。如果找不到匹配的节点,调度器仍然会调度该 Pod。
节点亲和性 yaml 说明:
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- antarctica-east1
- antarctica-west1
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: registry.k8s.io/pause:2.0
- 在
.spec.affinity.nodeAffinity字段中指定节点亲和性 - 在上边的yaml 的亲和性规则如下:
- 节点必须包含一个键名为
topology.kubernetes.io/zone的标签, 并且该标签的取值必须为antarctica-east1或antarctica-west1。 - 节点最好具有一个键名为
another-node-label-key且取值为another-node-label-value的标签。
- 节点必须包含一个键名为
Pod 亲和性
Pod 亲和性和节点亲和性一样也有两种类型的亲和性,与节点亲和性不同的是 Pod 亲和性中多了 topologyKey`标签来表达域的概念,是必填字段。
Pod 亲和性实战
部署一个带有 redis 缓存的 server, 该 server 需要在三个不同的节点上负载,redis 缓存要和 server 在同一个节点上,但是 三个 redis 也不能部署在一个几点上。
也就是说每个节点需要部署一个 server 和一个 redis:

-
将 redis 部署在三台不同节点上
apiVersion: apps/v1 kind: Deployment metadata: name: redis-cache spec: selector: matchLabels: app: store replicas: 3 template: metadata: labels: app: store spec: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - store topologyKey: "kubernetes.io/hostname" containers: - name: redis-server image: redis:3.2-alpine -
将 server 部署在不同节点上,并且和 redis 所在节点保持一致
apiVersion: apps/v1 kind: Deployment metadata: name: web-server spec: selector: matchLabels: app: web-store replicas: 3 template: metadata: labels: app: web-store spec: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - web-store topologyKey: "kubernetes.io/hostname" podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - store topologyKey: "kubernetes.io/hostname" containers: - name: web-app image: nginx:1.16-alpine
污点和容忍度
文档地址:https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/taint-and-toleration/
Taints 和 Tolerations 用于保证 Pod 不被调度到不合适的 Node 上,其中 Taint 应用于 Node 上,而 Toleration 则应用于 Pod 上。
目前支持的 Taint 类型:
- NoSchedule: 新的 Pod 不调度到该 Node 上, 不影响正在运行的 Pod;
- PreferNoSchedule: soft 版的 NoSchedule, 尽量不调度到该 Node 上
- NoExecute: 新的 Pod 不调度到该 Node 上,并且删除已在运行的 Pod。Pod 可以增加一个时间(tolerationSeconds),会在该时间之后才删除 Pod。
Controller Manager
控制器的工作流程
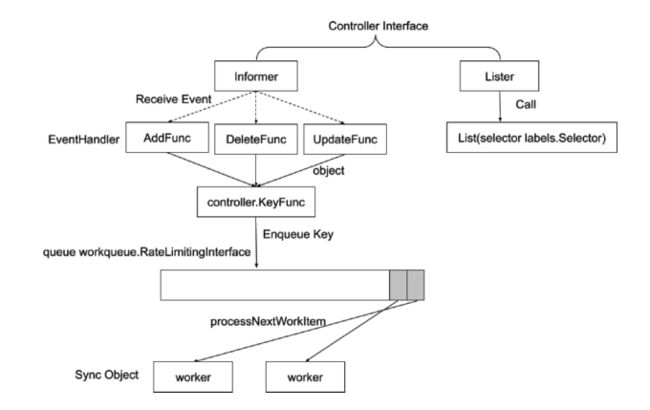
controller manager 是整个集群的大脑,它会监听所有的API资源对象,它主要分为 informer 和 Lister 两个对象,Lister 会获取当前资源对象的状况,informer 会监听资源对象,当资源对象变更时,会有对应的事件队列去处理,相当于一个消息通知机制的接口。
- Lister: Lister 会缓存一份所有资源对象的最新信息
- Informer: 一个消息通知机制的接口,当有资源对象进行变更的时候,通知对应的 eventhandler 进行处理。
- EventHandler: 不同执行动作会有不同的 handler 进行处理,handler 会将待处理的资源对象的 namespace + name 组成一个唯一的key 放在worker 的队列中。
- workerqueue: 存放资源对象唯一值的队列(namespace+name),worker 会从该队列中取出资源对象的key 进行处理。
- worker: 真正执行资源对象处理动作的对象,worker 会从 Lister 缓存中获取到对应资源对象期望的最新状态信息进行处理,而不是走 API Server 去获取资源对象信息。
Informer 的内部机制
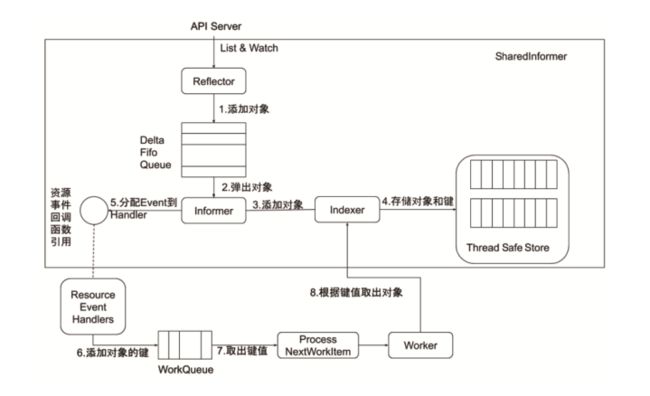
Informer 会和 API Server 产生一个长连接,去监听并获取所有资源对象的最新信息。
API Server 返回的是一个 json 字符串,Informer 在一开始 Reflector 需要利用 Go 的反射机制,根据tag 将字符串中转换为 Go 对象。
- 在转换完并获取到所有对象信息后,会添加对象到一个队列中。
- 然后 informer 会按顺序取出对象,生成对象的键,并将键值对信息存储在一个线程安全的内存中。
- 同时 informer 也会分配一个 event 到对应的 handler 进行处理。
- event handler 接收到需要处理的事件后,会添加对象的键至 worker 队列中。
- worker 取出键后需要先从前边存储的线程安全的内存中取出资源信息进行处理。
控制器的协同工作原理
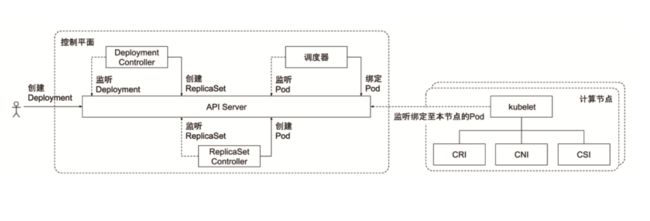
controller manager 是controller 的集合,每一种 controller 负责监听不同的对象,下边以部署一个 deployment 为例说明其中的不同 controller 的分工合作。
- 当用户执行一个部署动作的时候,也就是 apply 一个deployment yaml 时,会生成一个deployment 对象,Deployment Controller 会监听deployment 对象, 根据其中配置的部署回滚策略,以及副本集信息等,创建出 ReplicaSet 对象
- ReplicaSet Controller 对象会监听 ReplicaSet 对象,生成对应的 Pod 对象。
- kube-scheduler 调度器是一个特殊的 Controller 对象, 它会监听 Pod,将 Pod 绑定到符合调度策略的节点上。
- 绑定至对应节点后,节点上的 kubelet 对象就会根据CRI,CNI,CSI 创建对应的运行时,网络,存储设置。
同时 kubelet 也会监听节点上的 Pod 信息,并且不断上报信息至 API Server。
可以发现在对一个资源对象进行处理时,会经过许多的Controller 对象,这样解耦了整个冗长的部署流程,并且更加符合声明式的编程,每个Controller 监听对应对象的最新状态,当不符合期望时就发生变更,达到最终一致性的状态。
通用Controller


Kubelet
每个节点上都运行一个 kubelet 服务进程,默认监听 10250 端口。
- 接收并执行 master 发来的指令
- 管理 Pod 及 Pod 中的容器
- 每个 kubelet 进程会在 API Server 上注册节点自身信息,定期向 master 节点汇报节点的资源使用情况,并通过 cAdvisor 监控节点和容器的资源
节点管理
节点管理主要是节点自注册和节点状态更新:
- kubelet 可以通过设置启动参数
--register-node来确定是否向 API Server 注册自己 - 如果 kubelet 没有选择自注册模式,则需要用户自己配置Node 资源信息,同时需要告知 kubelet 集群上的API Server的位置
- kubelet 在启动时通过 API Server 注册节点信息,并定时向 API Server 发送节点新信息, API Server 在接收到新消息后,将信息写入 etcd
Pod 管理
- 文件:启动参数 --config 指定的配置目录下的文件(默认/etc/Kubernetes/manifests/)该文件每20秒重新检查一次(可配置)。
- HTTP endpoint(url): 启动参数 --manifest-url 设置。每20秒检查一次这个端点
- API Server: 通过 API Server 监听 etcd 目录,同步 Pod 清单。
- HTTP Server: kubelet 侦听HTTP 请求,并响应简单的 API 以提交新的 Pod 清单。
kubelet 架构
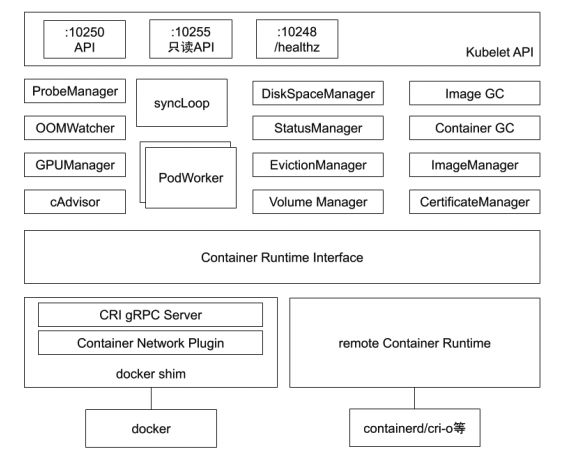
kubelet 的核心功能就是管理 Pod 的整个生命周期,然后上报节点与 Pod 信息至 API Server。
kubelet 的整体架构主要分为四层:
第一层是对外API
- 10250(kubelet API):kubelet server 与 apiserver 通信的端口,定期请求 apiserver 获取自己所应当处理的任务,通过该端口可以访问获取 node 资源以及状态。
- 10248(健康检查端口):通过访问该端口可以判断 kubelet 是否正常工作, 通过 kubelet 的启动参数 --healthz-port 和 --healthz-bind-address 来指定监听的地址和端口。
- 10255 (readonly API):提供了 pod 和 node 的信息,接口以只读形式暴露出去,访问该端口不需要认证和鉴权。
第二层是各种管理器
负责 Pod 在节点上的稳定运行以及资源使用状况的监控,其中最终要的就是 syncLoop 和 PodWorker, syncLoop 负责监听对 Pod 对象的各种操作,然后分配对应的 PodWorker 异步处理。
- ProbeManager:为节点上的Pod 做探活的管理器。
- OOMWatcher:监听内存溢出的进程。
- GPUManager: 管理节点上的GPU卡。
- cAdvisor: 封装了cgroup的第三方开源包,用于管理节点的资源使用状况,并且上报给kubelet,最新的k8s 重写了 cAdvisor 使其成为了内置的模块。
- DiskSpaceManager: 管理节点上进程使用的磁盘空间大小。
- StatusManager: 管理节点的状态。
- EvictionManager: 监听节点内存使用情况,当节点内存使用达到一定阈值后,会按照Pod 驱逐策略,按照优先级驱逐 Pod,释放内存,防止整个节点挂掉。
- Volume Manager: 负责挂载存储卷。
- Image GC: 扫描并清理不活跃的镜像。
- Container GC: 清理已 exit 的容器。
- ImageManager: 镜像管理。
- CertificateManager: 管理证书。
第三层是CRI 容器运行时接口
负责和节点上运行的容器进程交互,启动 Pod 容器进程。
第四层是容器运行层
节点上运行的容器进程,主要分为两大类,一类的是 docker 的进程一类是k8s 自身的 containerd 进程,k8s 所谓的废弃 docker 并不是说停止使用整个 docker 的进程,而是废弃 docker shim 的使用。
然后推出自己的容器运行时标准 containerd,不过后来 docker 也兼容了 k8s 提出的容器运行时标准,否则 docker 将被整个弃用。
kubelet 管理 Pod 的核心流程
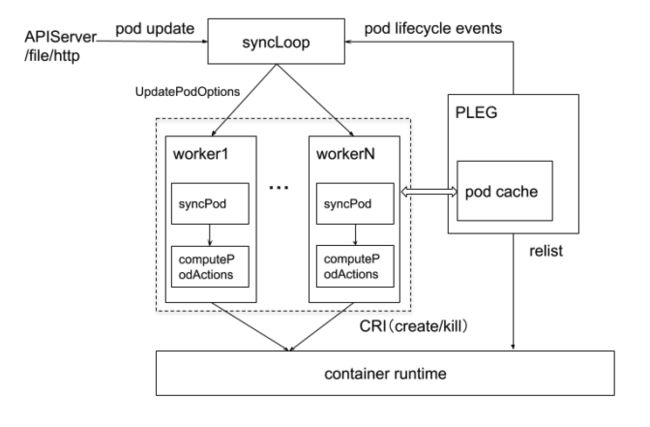
核心功能中最重要的是 syncLoop 和 PLEG 两大组件:
-
接收API Server 下发的 Pod 操作命令
syncLoop 接收到命令后,会分配对应的 worker 进行处理,在 worker 中会启动对应的 Pod, 并且执行 Pod 该有的 actions, 在一系列 manager 的配合下调用 CRI 执行容器操作。
PLEG(Pod Lifecycle Event Generator) PLEG 是 kubelet 的核心模块,PLEG 会一直调用 container runtime 获取本节点 containers/sandboxes 的信息,并与自身维护的 pods cache 信息进行对比,生成对应的 PodLifecycleEvent,然后输出到 eventChannel 中,通过 eventChannel 发送到 kubelet syncLoop 进行消费,然后由 kubelet syncPod 来触发 pod 同步处理过程,最终达到用户的期望状态。
-
不断上报 Pods 的信息至 API Server
同时 PLEG 也会不断上报 Pods 的最新信息至 syncLoop,然后 syncLoop 再上报至 API Server.
Pod 启动流程
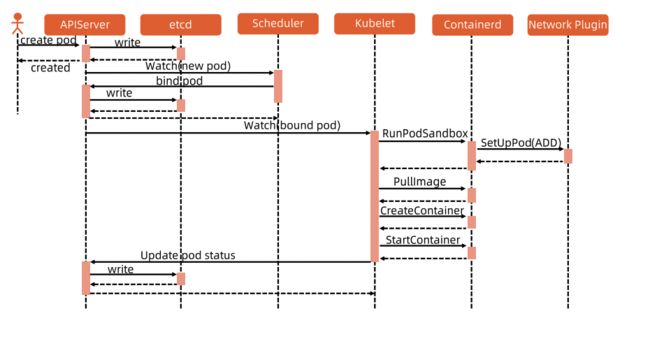
- APIServer将pod信息存入etcd,通知Scheduler。
- Scheduler根据调度算法,为pod选择一个节点,然后向APIServer发送更新spec.nodeName。
- APIServer更新完毕,通知对应节点的kubelet。
- kubelet发现pod调度到本节点,创建并运行pod的容器。
kubelet 启动 Pod 的流程
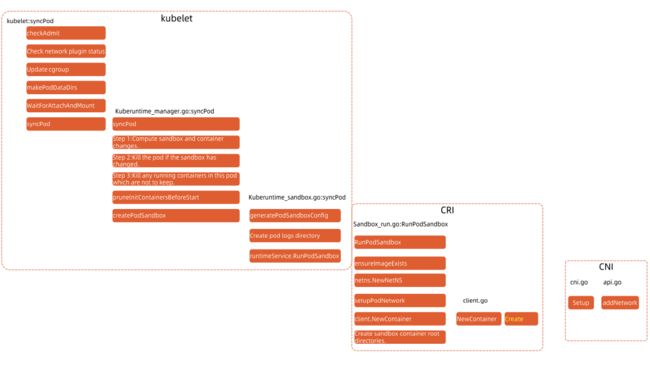
在 kubelet 启动Pod 的流程中有一个非常重要的环节就是和 CRI 的交互,CRI 会启动一个Sandbox 的容器,该容器将会打通与CNI的网络通信,为 Pod 在节点上提供一个稳定运行的环境,可以理解为给 Pod 在节点上的运行提供了一个沙箱环境。
K8s 与 CRI(Container Runtime Interface)、contaier 之间的关系,可以参考下这篇文章:
https://zhuanlan.zhihu.com/p/102897620
CRI
容器运行时(Container Runtime),运行于 k8s 集群的每个节点,负责容器的整个生命周期。
k8s 最开始的容器运行时是 Docker, 后来为了适用更多的容器运行时,k8s 提出了 CRI(Container Runtime Interface)容器运行时接口,kubelet 通过 CRI 来与容器运行时通信。
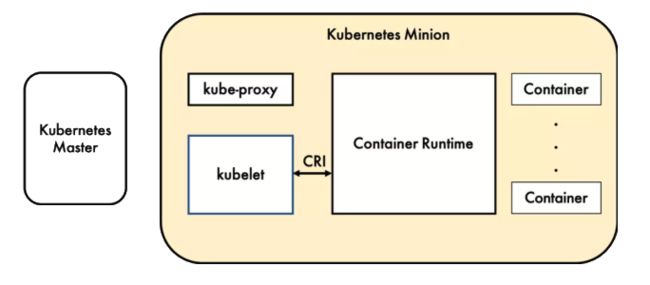
CRI 是 k8s 定义的一组gRPC 服务,kubelet 作为客户端,基于 gRPC 框架,通过Socket 和容器运行时通信。
它包括两类服务:
- 镜像服务: 提供下载、检查和删除镜像的远程程序调用。
- 运行时服务:包含用于管理容器生命周期,以及与容器交互的调用的远程程序调用。

Dockershim, containerd 和 CRI-O 都是遵循 CRI 的容器运行时,称为高层级运行时。
OCI (Open Container Initiative, 开放容器计划)定义了创建容器的格式和运行时的开源行业标准,包括镜像规范和运行时规范:
- 镜像规范定义了 OCI 镜像的标准。高层级运行时将会下载一个 OCI 镜像,并把它解压成 OCI 运行时文件系统。
- 运行时规范描述了如何从OCI 运行时文件系统包运行容器程序,并且定义它的配置、运行环境和生命周期。
如何为新容器设置命名空间(namespaces)和控制组(cgroups),以及挂载根文件系统等等,被称为低层级运行时。
容器运行时是真正启删和管理容器的组件,分为高层级运行时和低层级运行时,高层级运行时主要包括 Docker, containerd 和 CRI-O,低层级运行时包括 runc, kata以及 gVisor。
目前底层级运行时尚未成熟,还在实验阶段,因此更多的是使用高层级运行时。
Docker 关于容器运行时操作的核心也是 containerd, 但是 Docker 在其之上又封装了多层,比如 dockershim, docker-cli,这些封装对于 k8s 来说是冗余的,导致其在可维护性上略逊一筹,增加了线上问题的定位难度,当容器运行时出现问题时,除了重启 Docker 别无他法,因此 k8s 定义了CRI 企图废弃 Docker ,让开源的容器运行时去遵守 k8s 的规范:

如上图中所示,如今的 k8s 只保留了containerd, 而废弃了 Docker。
下图是containerd 和 CRI-O 的方案,可以发现比 Docker 简洁了很多,越往下 k8s 废弃越多的冗余部分:

目前成熟的容器运行时是上边这些的高层级运行时,一旦低层级运行时的开源服务成熟,将会更加简洁。
CNI
k8s 网络模型设计的基础原则是:
- 所有的 Pod 能够不通过 NAT 就能相互访问。
- 所有的节点能够不通过 NAT 就能相互访问。
- 容器内看见的 IP 地址和外部组件看到的容器 IP 是一样的。
k8s 集群中的 IP 地址以 Pod 为单位分配,每个 Pod 拥有一个独立的 IP 地址, Pod 内的所有容器共享一个网络栈,可以通过 localhost:port 来连接对方。
CNI 插件分类和常见插件
- IPAM: IP 地址分配
- 主插件:网卡设置
- bridge: 创建一个网桥,并把主机端口和容器端口插入网桥
- ipvlan: 为容器添加 ipvlan 网口
- loopback: 设置 loopback 网口
- Meta: 附加功能
- portmap: 设置主机端口和容器端口映射
- bandwidth: 利用Linux Traffic Control 限流
- firewall: 通过 iptables 或 firewalld 为容器设置防火墙规则
参考链接:https://github.com/containernetworking/plugins
CNI 插件运行机制
CRI 会从 CNI 配置目录中读取JSON 格式的配置文件,文件后缀为".conf", “.conflist”, “.json”。
如果配置目录中包含多个文件,一般情况下会以名字排序,读取第一个,获取其中指定的插件名称和配置参数。

CNI 的运行机制
关于容器网络管理,容器运行时一般需要配置两个参数 --cni-bin-dir 和 --cni-conf-dir。
- cni-bin-dir: 网络插件的可执行文件所在目录。
- cni-conf-dir: 网络插件的配置文件所在目录。
CNI 插件设计考量


CNI 插件
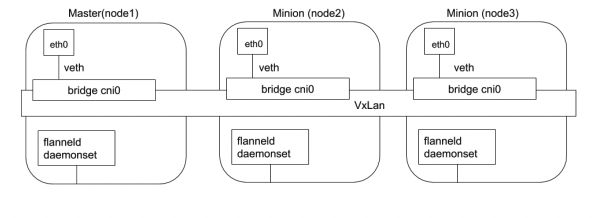
Flannel
- Flannel 是由 CoreOS 开发的项目,是CNI 插件早期的入门产品,简单易用。
- 使用k8s 的 etcd 作为存储,只需要在每个节点运行 flanneld 来守护进程。
- 每个节点都被分配一个子网,为该节点上的 Pod 分配 IP 地址。
- 同一主机内的 Pod 可以使用网桥进行通信,不同主机上的 Pod 将通过 flanneld 将其流量封装在 UDP 数据包中,以路由到适当的目的地。
- 封装方式默认和推荐的方法是使用VxLAN, 因为它具有良好的性能,并且比其他选项要少些人为干预,缺点就是该过程使流量跟踪变得困难。
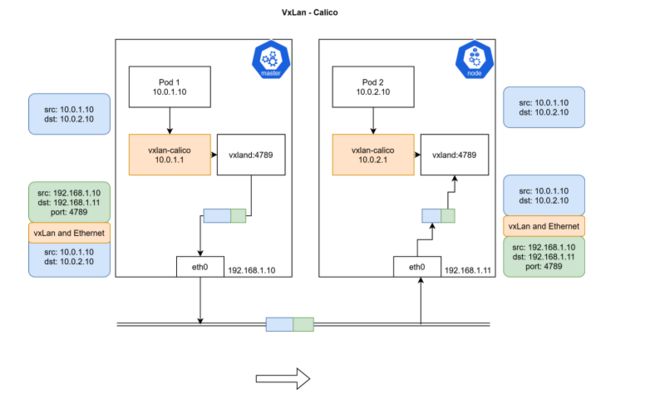
Calico
- Calico 以其性能、灵活性和网络策略而闻名,不仅涉及在主机和 Pod 之间提供网络连接,而且还涉及网络安全性和策略管理。
- Calico 还可以与服务网格 Istio 集成,在服务网格层和网络基础结构层上解释和实施集群中工作负载的策略。
- Calico 属于完全分布式的横向扩展结构,允许开发人员和管理员快速和平稳地扩展部署规模。对于性能和功能(如网络策略)要求高的环境,Calico 是一个不错的选择。
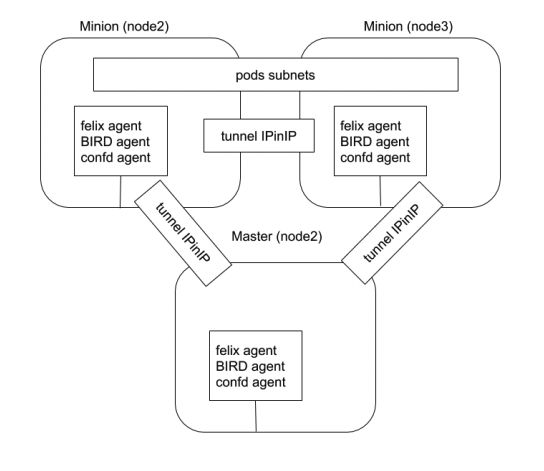
Calico VXLan
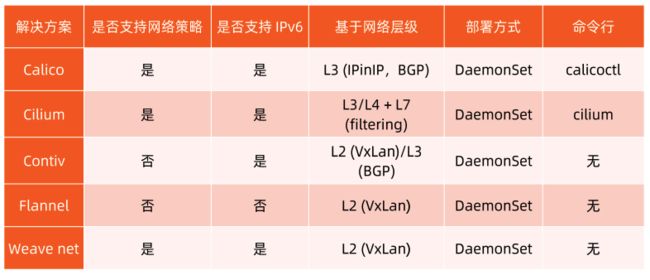
CNI plugin 的对比