ISLR读书笔记十九:主成分分析(PCA)
前面写的一些统计学习方法都是属于监督学习(supervised learning),这篇主成分分析(principal components analysis,简称 PCA )和下一篇聚类分析(clustering)都是属于非监督学习(unsupervised learning)。
之前 ISLR读书笔记十二 中已经提到过主成分这一概念。其主要目的是利用一小部分数据组合,尽可能多地体现 全部数据的特征,从而实现降维的作用。
这里的 尽可能多地体现 可以有两种解读:
-
将数据投影到方差最大的方向上,尽可能保留方差信息

-
低维空间下的最佳近似。

从第一种解读出发,计算第一主成分:
令
Z 1 = ϕ 11 X 1 + ϕ 21 X 2 + ⋯ + ϕ p 1 X p Z_1=\phi_{11}X_1+\phi_{21}X_2+\cdots+\phi_{p1}X_p Z1=ϕ11X1+ϕ21X2+⋯+ϕp1Xp
这里要求 ∑ j = 1 p ϕ j 1 2 = 1 \sum_{j=1}^p\phi_{j1}^2=1 ∑j=1pϕj12=1, ϕ 11 , ϕ 21 , ⋯ , ϕ p 1 \phi_{11},\phi_{21},\cdots,\phi_{p1} ϕ11,ϕ21,⋯,ϕp1 称作加载(loadings), ϕ 1 = ( ϕ 11 ϕ 21 ⋯ ϕ p 1 ) \phi_1=(\phi_{11}\quad\phi_{21}\cdots\phi_{p1}) ϕ1=(ϕ11ϕ21⋯ϕp1) 称作加载向量(loading vector)
由于只关心数据的方差,所以可以对数据进行中心化,即要求 E ( X i ) = 0 E(X_i)=0 E(Xi)=0
对于每一个分量
z i 1 = ϕ 11 x i 1 + ϕ 21 x i 2 + ⋯ + ϕ p 1 x i p z_{i1}=\phi_{11}x_{i1}+\phi_{21}x_{i2}+\cdots+\phi_{p1}x_{ip} zi1=ϕ11xi1+ϕ21xi2+⋯+ϕp1xip
第一主成分使得样本方差最大。即
maximize ϕ 11 , … , ϕ p 1 { 1 n ∑ i = 1 n ( ∑ j = 1 p ϕ j 1 x i j ) 2 } subject to ∑ j = 1 p ϕ j 1 2 = 1 \underset{\phi_{11}, \ldots, \phi_{p 1}}{\operatorname{maximize}}\left\{\frac{1}{n} \sum_{i=1}^{n}\left(\sum_{j=1}^{p} \phi_{j 1} x_{i j}\right)^{2}\right\} \text { subject to } \sum_{j=1}^{p} \phi_{j 1}^{2}=1 ϕ11,…,ϕp1maximize⎩⎨⎧n1i=1∑n(j=1∑pϕj1xij)2⎭⎬⎫ subject to j=1∑pϕj12=1
由于 1 n ∑ i = 1 n x i j = 0 \frac{1}{n}\sum_{i=1}^nx_{ij}=0 n1∑i=1nxij=0,所以即,使得 1 n ∑ i = 1 n z i 1 2 \frac{1} {n}\sum_{i=1}^nz_{i1}^2 n1∑i=1nzi12 最大。这里, z 11 , ⋯ , z n 1 z_{11},\cdots,z_{n1} z11,⋯,zn1 称作分数(scores)
该优化问题,可以用奇异值分解(SVD)的方法解得。
第二主成分是所有与第一主成分 Z 1 Z_1 Z1 不相关(uncorrelated)的,关于 X 1 , ⋯ , X p X_1,\cdots,X_p X1,⋯,Xp 的线性组合中,方差最大的线性组合。令
z i 2 = ϕ 12 x i 1 + ϕ 22 x i 2 + ⋯ + ϕ p 2 x i p z_{i2}=\phi_{12}x_{i1}+\phi_{22}x_{i2}+\cdots+\phi_{p2}x_{ip} zi2=ϕ12xi1+ϕ22xi2+⋯+ϕp2xip
可以证明 Z 2 Z_2 Z2 与 Z 1 Z_1 Z1 不相关,等价于加载向量 ϕ 2 \phi_2 ϕ2 与 ϕ 1 \phi_1 ϕ1 正交。
第三主成分是所有与 Z 1 Z_1 Z1 、 Z 2 Z_2 Z2 不相关(uncorrelated)的,关于 X 1 , ⋯ , X p X_1,\cdots,X_p X1,⋯,Xp 的线性组合中,方差最大的线性组合。以此类推。
从第二种解读出发,第一主成分加载向量是 p p p 维空间中,最接近 n n n 个观测数据的直线(在欧式距离平方的均值下最接近)。
更一般地,前 M M M 个主成分的分数向量和加载向量,构成了原始 p p p 维数据在 M M M 维空间的最佳近似,即
x i j ≈ ∑ m = 1 M z i m ϕ j m x_{ij}\approx\sum_{m=1}^Mz_{im}\phi_{jm} xij≈m=1∑Mzimϕjm
另外 PCA 还有其他一些需要注意的点:
规模化:
数据通常需要提前进行规模化(scaled)(每个变量乘以不同的常数),使得每个自变量的标准差为1。否则如果有部分变量方差特别大,那么PCA 的结果会受很大影响。
唯一性
每一个主成分在相差一个正负号的意义下式唯一的
被解释方差比例
我们通常关心前几个主成分反映了多少方差
数据总方差定义如下
∑ j = 1 p Var ( X j ) = ∑ j = 1 p 1 n ∑ i = 1 n x i j 2 \sum_{j=1}^p\text{Var}(X_j)=\sum_{j=1}^p\frac{1}{n}\sum_{i=1}^nx_{ij}^2 j=1∑pVar(Xj)=j=1∑pn1i=1∑nxij2
第 m m m 个主成分的被解释方差定义如下:
1 n ∑ i = 1 n z i m 2 = 1 n ∑ i = 1 n ( ∑ j = 1 p ϕ j m x i j ) 2 \frac{1}{n} \sum_{i=1}^{n} z_{i m}^{2}=\frac{1}{n} \sum_{i=1}^{n}\left(\sum_{j=1}^{p} \phi_{j m} x_{i j}\right)^{2} n1i=1∑nzim2=n1i=1∑n(j=1∑pϕjmxij)2
第 m m m 个主成分被解释方差的比例(proportion of variance explained)
即为
∑ i = 1 n ( ∑ j = 1 p ϕ j m x i j ) 2 ∑ j = 1 p ∑ i = 1 n x i j 2 \frac{\sum_{i=1}^{n}\left(\sum_{j=1}^{p} \phi_{j m} x_{i j}\right)^{2}}{\sum_{j=1}^{p} \sum_{i=1}^{n} x_{i j}^{2}} ∑j=1p∑i=1nxij2∑i=1n(∑j=1pϕjmxij)2
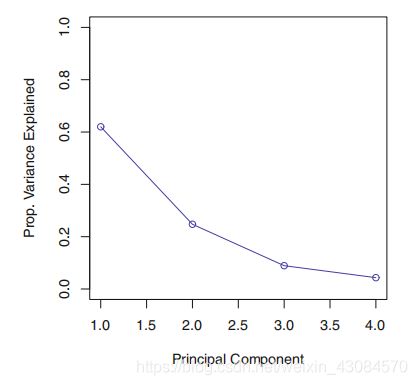
决定主成分的个数
可以通过碎石图(scree plot),来决定主成分的个数
方法是寻找一个点,在这个点之后的点,主成分被解释方差比例很小