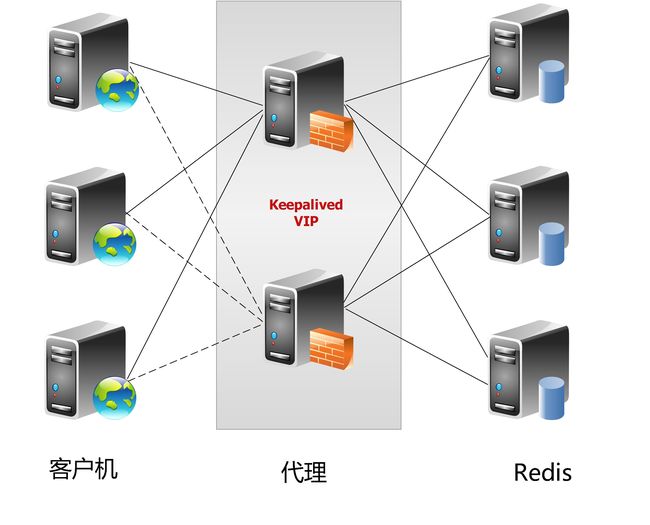
Redis的架构模式
单机版
特点:简单
问题:
1、内存容量有限 2、处理能力有限 3、无法高可用。
主从复制
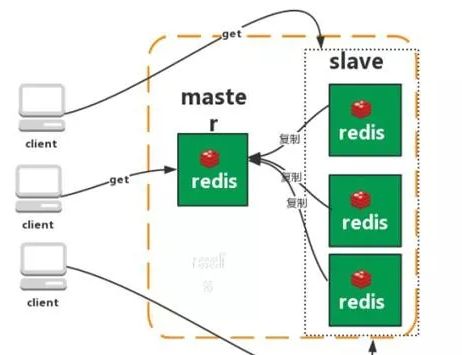
Redis 的复制(replication)功能允许用户根据一个 Redis 服务器来创建任意多个该服务器的复制品,其中被复制的服务器为主服务器(master),而通过复制创建出来的服务器复制品则为从服务器(slave)。 只要主从服务器之间的网络连接正常,主从服务器两者会具有相同的数据,主服务器就会一直将发生在自己身上的数据更新同步 给从服务器,从而一直保证主从服务器的数据相同。
特点:
1、master/slave 角色
2、master/slave 数据相同
3、降低 master 读压力在转交从库
问题:
无法保证高可用
没有解决 master 写的压力
哨兵
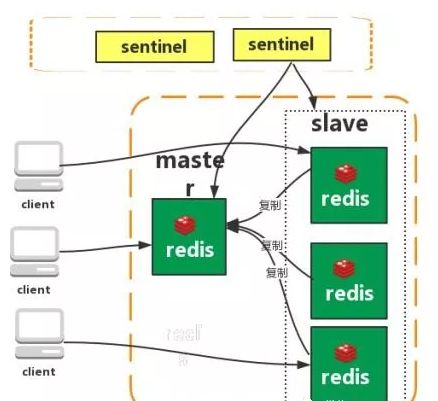
Redis sentinel 是一个分布式系统中监控 redis 主从服务器,并在主服务器下线时自动进行故障转移。其中三个特性:
监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作。
特点:
1、保证高可用
2、监控各个节点
3、自动故障迁移
缺点:主从模式,切换需要时间丢数据
没有解决 master 写的压力
集群模式:
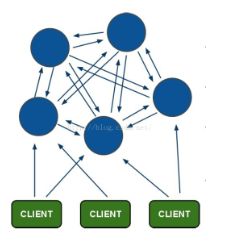
业界主流的Redis集群化方案主要包括以下几个:
- 客户端分片
- 代理分片
- 服务端分片
代理分片包括:
-
Codis
-
Twemproxy
服务端分片包括:
- Redis Cluster
它们还可以用是否中心化来划分,其中客户端分片、Redis Cluster属于无中心化的集群方案,Codis、Tweproxy属于中心化的集群方案。
是否中心化是指客户端访问多个Redis节点时,是直接访问还是通过一个中间层Proxy来进行操作,直接访问的就属于无中心化的方案,通过中间层Proxy访问的就属于中心化的方案,它们有各自的优劣,下面分别来介绍。
1 客户端分片
客户端分片主要是说,我们只需要部署多个Redis节点,具体如何使用这些节点,主要工作在客户端。
客户端通过固定的Hash算法,针对不同的key计算对应的Hash值,然后对不同的Redis节点进行读写。

客户端分片集群模式 需要业务开发人员事先评估业务的请求量和数据量,然后让DBA部署足够的节点交给开发人员使用即可。
这个方案的优点是部署非常方便,业务需要多少个节点DBA直接部署交付即可,剩下的事情就需要业务开发人员根据节点数量来编写key的请求路由逻辑,制定一个规则,一般采用固定的Hash算法,把不同的key写入到不同的节点上,然后再根据这个规则进行数据读取。
可见,它的缺点是业务开发人员使用Redis的成本较高,需要编写路由规则的代码来使用多个节点,而且如果事先对业务的数据量评估不准确,后期的扩容和迁移成本非常高,因为节点数量发生变更后,Hash算法对应的节点也就不再是之前的节点了。
所以后来又衍生出了一致性哈希算法,就是为了解决当节点数量变更时,尽量减少数据的迁移和性能问题。
这种客户端分片的方案一般用于业务数据量比较稳定,后期不会有大幅度增长的业务场景下使用,只需要前期评估好业务数据量即可。
客户端分片的特点
这实际上是一种静态分片技术。Redis 实例的增减,都得手工调整分片程序。基于此分片机制的开源产品,现在仍不多见。
这种分片机制的性能比代理式更好(少了一个中间分发环节)。但缺点是升级麻烦,对研发人员的个人依赖性强——需要有较强的程序开发能力做后盾。如果主力程序员离职,可能新的负责人,会选择重写一遍。
所以,这种方式下,可运维性较差。出现故障,定位和解决都得研发和运维配合着解决,故障时间变长。
这种方案,难以进行标准化运维,不太适合中小公司(除非有足够的 DevOPS)。
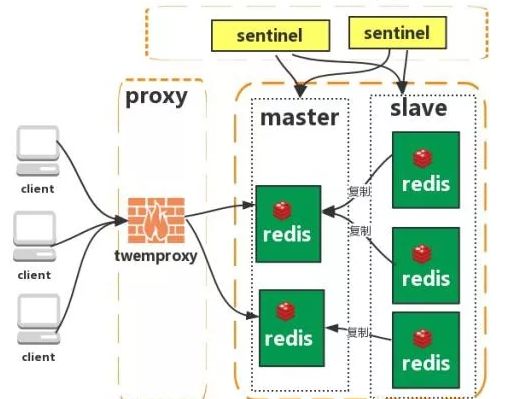
2 代理分片 (代理型集群)
这种方案,将分片工作交给专门的代理程序来做。代理程序接收到来自业务程序的数据请求,根据路由规则,将这些请求分发给正确的 Redis 实例并返回给业务程序。
这种机制下,一般会选用第三方代理程序(而不是自己研发),因为后端有多个 Redis 实例,所以这类程序又称为分布式中间件。
这样的好处是,业务程序不用关心后端 Redis 实例,运维起来也方便。虽然会因此带来些性能损耗,但对于 Redis 这种内存读写型应用,相对而言是能容忍的。
Codis
随着业务和技术的发展,人们越发觉得,当我需要使用Redis时,我们不想关心集群后面有多少个节点,我们希望我们使用的Redis是一个大集群,当我们的业务量增加时,这个大集群可以增加新的节点来解决容量不够用和性能问题。
这种方式就是服务端分片方案,客户端不需要关心集群后面有多少个Redis节点,只需要像使用一个Redis的方式去操作这个集群,这种方案将大大降低开发人员的使用成本,开发人员可以只需要关注业务逻辑即可,不需要关心Redis的资源问题。
多个节点组成的集群,如何让开发人员像操作一个Redis时那样来使用呢?这就涉及到多个节点是如何组织起来提供服务的,一般我们会在客户端和服务端中间增加一个代理层,客户端只需要操作这个代理层,代理层实现了具体的请求转发规则,然后转发请求到后面的多个节点上,因此这种方式也叫做中心化方式的集群方案,Codis就是以这种方式实现的集群化方案。
 Proxy集群模式
Proxy集群模式

Codis是由国人前豌豆荚大神开发的,采用中心化方式的集群方案。因为需要代理层Proxy来进行所有请求的转发,所以对Proxy的性能要求很高,Codis采用Go语言开发,兼容了开发效率和性能。
Codis包含了多个组件:
- codis-proxy:主要负责对请求的读写进行转发
- codis-dashbaord:统一的控制中心,整合了数据转发规则、故障自动恢复、数据在线迁移、节点扩容缩容、自动化运维API等功能
- codis-group:基于Redis 3.2.8版本二次开发的Redis Server,增加了异步数据迁移功能
- codis-fe:管理多个集群的UI界面
可见Codis的组件还是挺多的,它的功能非常全,除了请求转发功能之外,还实现了在线数据迁移、节点扩容缩容、故障自动恢复等功能。
Codis的Proxy就是负责请求转发的组件,它内部维护了请求转发的具体规则,Codis把整个集群划分为1024个槽位,在处理读写请求时,采用crc32Hash算法计算key的Hash值,然后再根据Hash值对1024个槽位取模,最终找到具体的Redis节点。
Codis最大的特点就是可以在线扩容,在扩容期间不影响客户端的访问,也就是不需要停机。这对业务使用方是极大的便利,当集群性能不够时,就可以动态增加节点来提升集群的性能。
为了实现在线扩容,保证数据在迁移过程中还有可靠的性能,Codis针对Redis进行了修改,增加了针对异步迁移数据相关命令,它基于Redis 3.2.8进行开发,上层配合Dashboard和Proxy组件,完成对业务无损的数据迁移和扩容功能。
因此,要想使用Codis,必须使用它内置的Redis,这也就意味着Codis中的Redis是否能跟上官方最新版的功能特性,可能无法得到保障,这取决于Codis的维护方,目前Codis已经不再维护,所以使用Codis时只能使用3.2.8版的Redis,这是一个痛点。
另外,由于集群化都需要部署多个节点,因此操作集群并不能完全像操作单个Redis一样实现所有功能,主要是对于操作多个节点可能产生问题的命令进行了禁用或限制,具体可参考Codis不支持的命令列表。
但这不影响它是一个优秀的集群化方案,由于我司使用Redis集群方案较早,那时Redis Cluster还不够成熟,所以我司使用的Redis集群方案就是Codis。目前我的工作主要是围绕Codis展开的,我们公司对Codis进行了定制开发,还对Redis进行了一些改造,让Codis支持了跨多个数据中心的数据同步,因此我对Codis的代码比较熟悉,后面会专门写一些文章来剖析Codis的实现原理,学习它的原理,这对我们理解分布式存储有很大的帮助!
Twemproxy
Twemproxy是由Twitter开源的集群化方案,它既可以做Redis Proxy,还可以做Memcached Proxy。
它的功能比较单一,只实现了请求路由转发,没有像Codis那么全面有在线扩容的功能,它解决的重点就是把客户端分片的逻辑统一放到了Proxy层而已,其他功能没有做任何处理。

Tweproxy推出的时间最久,在早期没有好的服务端分片集群方案时,应用范围很广,而且性能也极其稳定。
但它的痛点就是无法在线扩容、缩容,这就导致运维非常不方便,而且也没有友好的运维UI可以使用。
Twemproxy 是一个 Twitter 开源的一个 redis 和 memcache 快速/轻量级代理服务器; Twemproxy 是一个快速的单线程代理程序,支持 Memcached ASCII 协议和 redis 协议。
特点:
1、多种 hash 算法:MD5、CRC16、CRC32、CRC32a、hsieh、murmur、Jenkins
2、支持失败节点自动删除
3、后端 Sharding 分片逻辑对业务透明,业务方的读写方式和操作单个 Redis 一致
缺点:
增加了新的 proxy,需要维护其高可用。failover 逻辑需要自己实现,其本身不能支持故障的自动转移可扩展性差,进行扩缩容都需要手动干预
Codis就是因为在这种背景下才衍生出来的。
3 服务端分片(直连型集群)
采用中间加一层Proxy的中心化模式时,这就对Proxy的要求很高,因为它一旦出现故障,那么操作这个Proxy的所有客户端都无法处理,要想实现Proxy的高可用,还需要另外的机制来实现,例如Keepalive。
而且增加一层Proxy进行转发,必然会有一定的性能损耗,那么除了客户端分片和上面提到的中心化的方案之外,还有比较好的解决方案么?
直连型集群。从redis 3.0之后版本支持redis-cluster集群,Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。
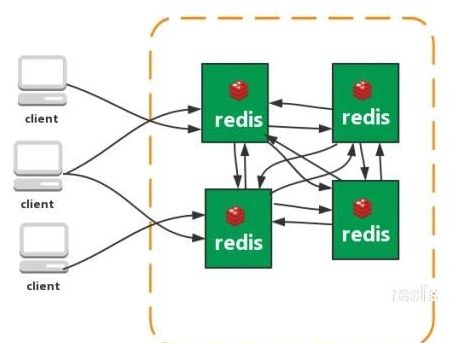
Redis Cluster
Redis官方推出的Redis Cluster另辟蹊径,它没有采用中心化模式的Proxy方案,而是把请求转发逻辑一部分放在客户端,一部分放在了服务端,它们之间互相配合完成请求的处理。
Redis Cluster是在Redis 3.0推出的,早起的Redis Cluster由于没有经过严格的测试和生产验证,所以并没有广泛推广开来。也正是在这样的背景下,业界衍生了出了上面所说的中心化集群方案:Codis和Tweproxy。
但随着Redis的版本迭代,Redis官方的Cluster也越来越稳定,更多人开始采用官方的集群化方案。也正是因为它是官方推出的,所以它的持续维护性可以得到保障,这就比那些第三方的开源方案更有优势。
Redis Cluster没有了中间的Proxy代理层,那么是如何进行请求的转发呢?
Redis把请求转发的逻辑放在了Smart Client中,要想使用Redis Cluster,必须升级Client SDK,这个SDK中内置了请求转发的逻辑,所以业务开发人员同样不需要自己编写转发规则,Redis Cluster采用16384个槽位进行路由规则的转发。

没有了Proxy层进行转发,客户端可以直接操作对应的Redis节点,这样就少了Proxy层转发的性能损耗。
Redis Cluster也提供了在线数据迁移、节点扩容缩容等功能,内部还内置了哨兵完成故障自动恢复功能,可见它是一个集成所有功能于一体的Cluster。因此它在部署时非常简单,不需要部署过多的组件,对于运维极其友好。
Redis Cluster在节点数据迁移、扩容缩容时,对于客户端的请求处理也做了相应的处理。当客户端访问的数据正好在迁移过程中时,服务端与客户端制定了一些协议,来告知客户端去正确的节点上访问,帮助客户端订正自己的路由规则。
虽然Redis Cluster提供了在线数据迁移的功能,但它的迁移性能并不高,迁移过程中遇到大key时还有可能长时间阻塞迁移的两个节点,这个功能相较于Codis来说,Codis数据迁移性能更好。关注公众号Java技术栈可以阅读一些集群搭建实战的文章。
现在越来越多的公司开始采用Redis Cluster,有能力的公司还在它的基础上进行了二次开发和定制,来解决Redis Cluster存在的一些问题,我们期待Redis Cluster未来有更好的发展。
特点:
1、无中心架构(不存在哪个节点影响性能瓶颈),少了 proxy 层。
2、数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布。
3、可扩展性,可线性扩展到 1000 个节点,节点可动态添加或删除。
4、高可用性,部分节点不可用时,集群仍可用。通过增加 Slave 做备份数据副本
5、实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave到 Master 的角色提升。
缺点:
1、资源隔离性较差,容易出现相互影响的情况。
2、数据通过异步复制,不保证数据的强一致性
集群的必要性
所谓的集群,就是通过添加服务器的数量,提供相同的服务,从而让服务器达到一个稳定、高效的状态。
1.1.1 使用 redis 集群的必要性
问题:我们已经部署好了redis,并且能启动一个redis,实现数据的读写,为什么还要学习redis集群?
答:(1)单个redis存在不稳定性。当redis服务宕机了,就没有可用的服务了。
(2)单个redis的读写能力是有限的。
总结:redis集群是为了强化redis的读写能力。
1.1.2 如何学习redis集群
说明:(1)redis集群中,每一个redis称之为一个节点。
(2)redis集群中,有两种类型的节点:主节点(master)、从节点(slave)。
(3)redis集群,是基于redis主从复制实现。
所以,学习redis集群,就是从学习redis主从复制模型开始的。
redis主从复制
1.1 概念
主从复制模型中,有多个redis节点。
其中,有且仅有一个为主节点Master。从节点Slave可以有多个。
只要网络连接正常,Master会一直将自己的数据更新同步给Slaves,保持主从同步。
1.1 特点
(1)主节点Master可读、可写.
(2)从节点Slave只读。(read-only)
因此,主从模型可以提高读的能力,在一定程度上缓解了写的能力。因为能写仍然只有Master节点一个,可以将读的操作全部移交到从节点上,变相提高了写能力。
1.1 基于配置实现
1.1.1 需求
| 主节点 | 6380 |
|---|---|
| 从节点(两个) | 6381、6382 |
1.1.2 配置步骤
(1)在/usr/local目录下,创建一个/redis/master-slave目录
[root@node0719 local]# mkdir -p redis/master-slave
(2)在master-slave目录下,创建三个子目录6380、6381、6382
[root@node0719 master-slave]# mkdir 6380 6381 6382
(3)依次拷贝redis解压目录下的redis.conf配置文件,到这三个子目录中。
[root@node0719 master-slave]# cp /root/redis-3.2.9/redis.conf ./6380/ [root@node0719 master-slave]# cp /root/redis-3.2.9/redis.conf ./6381/ [root@node0719 master-slave]# cp /root/redis-3.2.9/redis.conf ./6382/
(4)进入6380目录,修改redis.conf,将port端口修改成6380即可。
[root@node0719 master-slave]# cd ./6380 [root@node0719 6380]# vim redis.conf
(5)进入6381目录,修改redis.conf,将port端口改成6381,同时指定开启主从复制。
[root@node0719 6380]# cd ../6381 [root@node0719 6381]# vim redis.conf
(6)进入6382目录,修改redis.conf,将port端口改成6382,同时指定开启主从复制。
[root@node0719 6380]# cd ../6382 [root@node0719 6381]# vim redis.conf
1.1.1 测试
(1)打开三个xshell窗口,在每一个窗口中,启动一个redis节点。查看日志输出。(不要改成后台模式启动,看不到日志,不直观)
[root@node0719 master-slave]# cd 6380 && redis-server ./redis.conf [root@node0719 master-slave]# cd 6381 && redis-server ./redis.conf [root@node0719 master-slave]# cd 6382 && redis-server ./redis.conf
(2)另外再打开三个xshell窗口,在每一个窗口中,登陆一个redis节点
[root@node0719 ~]# redis-cli -p 6380 [root@node0719 ~]# redis-cli -p 6381 [root@node0719 ~]# redis-cli -p 6382
(3)在主节点6380上,进行读写操作,操作成功
[root@node0719 ~]# redis-cli -p 6380 127.0.0.1:6380> set user:name zs OK 127.0.0.1:6380> get user:name "zs" 127.0.0.1:6380>
(4)在从节点6381上
读操作执行成功,并且成功从6380上同步了数据
[root@node0719 ~]# redis-cli -p 6381 127.0.0.1:6381> get user:name "zs"
写操作执行失败。(从节点,只能读,不能写)
127.0.0.1:6381> set user:age 18 (error) READONLY You can't write against a read only slave.
Sentinel哨兵模式
1.1 主从模式的缺陷
当主节点宕机了,整个集群就没有可写的节点了。
由于从节点上备份了主节点的所有数据,那在主节点宕机的情况下,如果能够将从节点变成一个主节点,是不是就可以解决这个问题了呢?
答:是的,这个就是Sentinel哨兵的作用。
1.2 哨兵的任务
Redis 的 Sentinel 系统用于管理多个 Redis 服务器(instance), 该系统执行以下三个任务:
监控(Monitoring****): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
提醒(Notification****): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
自动故障迁移(Automatic failover****): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会进行选举,将其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
1.2.1 监控(Monitoring)
(1)Sentinel可以监控任意多个Master和该Master下的Slaves。(即多个主从模式)
(2)同一个哨兵下的、不同主从模型,彼此之间相互独立。
(3)Sentinel会不断检查Master和Slaves是否正常。
1.2.2 自动故障切换(Automatic failover)
1.2.2.1 Sentinel网络
监控同一个Master的Sentinel会自动连接,组成一个分布式的Sentinel网络,互相通信并交换彼此关于被监视服务器的信息。下图中,三个监控s1的Sentinel,自动组成Sentinel网络结构。
疑问:为什么要使用sentinel网络呢?
答:当只有一个sentinel的时候,如果这个sentinel挂掉了,那么就无法实现自动故障切换了。
在sentinel网络中,只要还有一个sentinel活着,就可以实现故障切换。
1.1.1.1 故障切换的过程
(1)投票(半数原则)
当任何一个Sentinel发现被监控的Master下线时,会通知其它的Sentinel开会,投票确定该Master是否下线(半数以上,所以sentinel通常配奇数个)。
(2)选举
当Sentinel确定Master下线后,会在所有的Slaves中,选举一个新的节点,升级成Master节点。
其它Slaves节点,转为该节点的从节点。
(3)原Master重新上线
当原Master节点重新上线后,自动转为当前Master节点的从节点。
1.1 哨兵模式部署
1.1.1 需求
前提:已经存在一个正在运行的主从模式。
另外,配置三个Sentinel实例,监控同一个Master节点。
1.1.2 配置Sentinel
(1)在/usr/local目录下,创建/redis/sentinels/目录
[root@node0719 local]# mkdir -p redis/sentinels
(2)在/sentinels目录下,以次创建s1、s2、s3三个子目录中
[root@node0719 sentinels]# mkdir s1 s2 s3
(3)依次拷贝redis解压目录下的sentinel.conf文件,到这三个子目录中
[root@node0719 sentinels]# cp /root/redis-3.2.9/sentinel.conf ./s1/ [root@node0719 sentinels]# cp /root/redis-3.2.9/sentinel.conf ./s2/ [root@node0719 sentinels]# cp /root/redis-3.2.9/sentinel.conf ./s3/
(4)依次修改s1、s2、s3子目录中的sentinel.conf文件,修改端口,并指定要监控的主节点。(从节点不需要指定,sentinel会自动识别)
S1哨兵配置如下:
S2哨兵配置如下:
S3哨兵配置如下:
(5)再打开三个xshell窗口,在每一个窗口中,启动一个哨兵实例,并观察日志输出
[root@node0719 sentinels]# redis-sentinel ./s1/sentinel.conf [root@node0719 sentinels]# redis-sentinel ./s2/sentinel.conf [root@node0719 sentinels]# redis-sentinel ./s3/sentinel.conf
对于用redis-server启动哨兵的方式如下:
[root@node0719 sentinels]# redis-server ./s1/sentinel.conf --sentinel
1.1.3 测试
(1)先关闭6380节点(kill掉)。发现,确实重新指定了一个主节点
(2)再次上线6380节点。发现,6380节点成为了新的主节点的从节点。
1.2 结论
Sentinel哨兵模式,确实能实现自动故障切换。提供稳定的服务
redis集群搭建
Redis Cluster属于无中心化的集群方案,
一、Redis Cluster(Redis集群)简介
RedisCluster 是 Redis 的亲儿子,它是 Redis 作者自己提供的 Redis 集群化方案。 相对于 Codis 的不同,它是去中心化的,如图所示,该集群有三个 Redis 节点组成, 每个节点负责整个集群的一部分数据,每个节点负责的数据多少可能不一样。这三个节点相 互连接组成一个对等的集群,它们之间通过一种特殊的二进制协议相互交互集群信息。
Redis Cluster 将所有数据划分为 16384 的 slots,它比 Codis 的 1024 个槽划分得更为精细,每个节点负责其中一部分槽位。槽位的信息存储于每个节点中,它不像 Codis,它不 需要另外的分布式存储来存储节点槽位信息。
当 Redis Cluster 的客户端来连接集群时,它也会得到一份集群的槽位配置信息。这样当客户端要查找某个 key 时,可以直接定位到目标节点。
这点不同于 Codis,Codis 需要通过 Proxy 来定位目标节点,RedisCluster 是直接定 位。客户端为了可以直接定位某个具体的 key 所在的节点,它就需要缓存槽位相关信息,这样才可以准确快速地定位到相应的节点。同时因为槽位的信息可能会存在客户端与服务器不一致的情况,还需要纠正机制来实现槽位信息的校验调整。 另外,RedisCluster 的每个节点会将集群的配置信息持久化到配置文件中,所以必须确保配置文件是可写的,而且尽量不要依靠人工修改配置文件。
- redis是一个开源的key value存储系统,受到了广大互联网公司的青睐。redis3.0版本之前只支持单例模式,在3.0版本及以后才支持集群,我这里用的是redis3.0.0版本;
- redis集群采用P2P模式,是完全去中心化的,不存在中心节点或者代理节点;
- redis集群是没有统一的入口的,客户端(client)连接集群的时候连接集群中的任意节点(node)即可,集群内部的节点是相互通信的(PING-PONG机制),每个节点都是一个redis实例;
- 为了实现集群的高可用,即判断节点是否健康(能否正常使用),redis-cluster有这么一个投票容错机制:如果集群中超过半数的节点投票认为某个节点挂了,那么这个节点就挂了(fail)。这是判断节点是否挂了的方法;
- 那么如何判断集群是否挂了呢? -> 如果集群中任意一个节点挂了,而且该节点没有从节点(备份节点),那么这个集群就挂了。这是判断集群是否挂了的方法;
- 那么为什么任意一个节点挂了(没有从节点)这个集群就挂了呢? -> 因为集群内置了16384个slot(哈希槽),并且把所有的物理节点映射到了这16384[0-16383]个slot上,或者说把这些slot均等的分配给了各个节点。当需要在Redis集群存放一个数据(key-value)时,redis会先对这个key进行crc16算法,然后得到一个结果。再把这个结果对16384进行求余,这个余数会对应[0-16383]其中一个槽,进而决定key-value存储到哪个节点中。所以一旦某个节点挂了,该节点对应的slot就无法使用,那么就会导致集群无法正常工作。
- 综上所述,每个Redis集群理论上最多可以有16384个节点。
二、集群搭建需要的环境
防火墙设置
redis集群中的每个节点都需要建立2个tcp连接,监听这2个端口:一个端口称之为“客户端端口”,用于接受客户端指令,与客户端交互,比如6379;另一个端口称之为“集群总线端口”,是在客户端端口号上加10000,比如16379,用于节点之间通过二进制协议通讯。各节点通过集群总线检测宕机节点、更新配置、故障转移验证等。客户端只能使用客户端端口,不能使用集群总线端口。请确保你的防火墙允许打开这两个端口,否则redis集群没法工作。客户端端口和集群总线端口之间的差值是固定的,集群总线端口比客户端端口高10000。
注意,关于集群的2个端口:
- 客户端端口(一般是6379)需要对所有客户端和集群节点开放,因为集群节点需要通过该端口转移数据。
- 集群总线端口(一般是16379)只需对集群中的所有节点开放
这2个端口必须打开,否则集群没法正常工作。
集群节点之间通过集群总线端口交互数据,使用的协议不同于客户端的协议,是二进制协议,这可以减少带宽和处理时间。
Redis集群数据的分片
Redis集群不是使用一致性哈希,而是使用哈希槽。整个redis集群有16384个哈希槽,决定一个key应该分配到那个槽的算法是:计算该key的CRC16结果再模16834。
集群中的每个节点负责一部分哈希槽,比如集群中有3个节点,则:
- 节点A存储的哈希槽范围是:0 – 5500
- 节点B存储的哈希槽范围是:5501 – 11000
- 节点C存储的哈希槽范围是:11001 – 16384
这样的分布方式方便节点的添加和删除。比如,需要新增一个节点D,只需要把A、B、C中的部分哈希槽数据移到D节点。同样,如果希望在集群中删除A节点,只需要把A节点的哈希槽的数据移到B和C节点,当A节点的数据全部被移走后,A节点就可以完全从集群中删除。
因为把哈希槽从一个节点移到另一个节点是不需要停机的,所以,增加或删除节点,或更改节点上的哈希槽,也是不需要停机的。
如果多个key都属于一个哈希槽,集群支持通过一个命令(或事务, 或lua脚本)同时操作这些key。通过“哈希标签”的概念,用户可以让多个key分配到同一个哈希槽。哈希标签在集群详细文档中有描述,这里做个简单介绍:如果key含有大括号”{}”,则只有大括号中的字符串会参与哈希,比如”this{foo}”和”another{foo}”这2个key会分配到同一个哈希槽,所以可以在一个命令中同时操作他们。
Redis集群的一致性保证
Redis集群不能保证强一致性。一些已经向客户端确认写成功的操作,会在某些不确定的情况下丢失。
产生写操作丢失的第一个原因,是因为主从节点之间使用了异步的方式来同步数据。
一个写操作是这样一个流程:
-
1)客户端向主节点B发起写的操作
-
2)主节点B回应客户端写操作成功
-
3)主节点B向它的从节点B1,B2,B3同步该写操作
从上面的流程可以看出来,主节点B并没有等从节点B1,B2,B3写完之后再回复客户端这次操作的结果。所以,如果主节点B在通知客户端写操作成功之后,但同步给从节点之前,主节点B故障了,其中一个没有收到该写操作的从节点会晋升成主节点,该写操作就这样永远丢失了。
就像传统的数据库,在不涉及到分布式的情况下,它每秒写回磁盘。为了提高一致性,可以在写盘完成之后再回复客户端,但这样就要损失性能。这种方式就等于Redis集群使用同步复制的方式。
基本上,在性能和一致性之间,需要一个权衡。
如果真的需要,Redis集群支持同步复制的方式,通过WAIT指令来实现,这可以让丢失写操作的可能性降到很低。但就算使用了同步复制的方式,Redis集群依然不是强一致性的,在某些复杂的情况下,比如从节点在与主节点失去连接之后被选为主节点,不一致性还是会发生。
这种不一致性发生的情况是这样的,当客户端与少数的节点(至少含有一个主节点)网络联通,但他们与其他大多数节点网络不通。比如6个节点,A,B,C是主节点,A1,B1,C1分别是他们的从节点,一个客户端称之为Z1。
当网络出问题时,他们被分成2组网络,组内网络联通,但2组之间的网络不通,假设A,C,A1,B1,C1彼此之间是联通的,另一边,B和Z1的网络是联通的。Z1可以继续往B发起写操作,B也接受Z1的写操作。当网络恢复时,如果这个时间间隔足够短,集群仍然能继续正常工作。如果时间比较长,以致B1在大多数的这边被选为主节点,那刚才Z1发给B的写操作都将丢失。
注意,Z1给B发送写操作是有一个限制的,如果时间长度达到了大多数节点那边可以选出一个新的主节点时,少数这边的所有主节点都不接受写操作。
这个时间的配置,称之为节点超时(node timeout),对集群来说非常重要,当达到了这个节点超时的时间之后,主节点被认为已经宕机,可以用它
Redis集群参数配置
我们后面会部署一个Redis集群作为例子,在那之前,先介绍一下集群在redis.conf中的参数。
- cluster-enabled
- cluster-config-file
- cluster-node-timeout
- cluster-slave-validity-factor
- cluster-migration-barrier
- cluster-require-full-coverage
:在部分key所在的节点不可用时,如果此参数设置为”yes”(默认值), 则整个集群停止接受操作;如果此参数设置为”no”,则集群依然为可达节点上的key提供读操作。
port 7000 cluster-enabled yes cluster-config-file nodes.conf cluster-node-timeout 5000 appendonly yes
开启集群模式只需打开cluster-enabled配置项即可。每一个redis实例都包含一个配置文件,默认是nodes.conf,用于存储此节点的一些配置信息。这个配置文件由redis集群的节点自行创建和更新,不能由人手动地去修改。
一个最小的集群需要最少3个主节点。第一次测试,强烈建议你配置6个节点:3个主节点和3个从节点
搭建准备
2.1 Redis集群至少需要3个节点,因为投票容错机制要求超过半数节点认为某个节点挂了该节点才是挂了,所以2个节点无法构成集群。
2.2 要保证集群的高可用,需要每个节点都有从节点,也就是备份节点,所以Redis集群至少需要6台服务器。因为我没有那么多服务器,也启动不了那么多虚拟机,所在这里搭建的是伪分布式集群,即一台服务器虚拟运行6个redis实例,修改端口号为(7001-7006),当然实际生产环境的Redis集群搭建和这里是一样的。
将redis-cluster/redis01文件复制5份到redis-cluster目录下(redis02-redis06),创建6个redis实例,模拟Redis集群的6个节点。然后将其余5个文件下的redis.conf里面的端口号分别修改为7002-7006。分别如下图所示:
创建redis02-06目录
接着启动所有redis节点,由于一个一个启动太麻烦了,所以在这里创建一个批量启动redis节点的脚本文件,命令为start-all.sh,文件内容如下:
cd redis01 ./redis-server redis.conf cd .. cd redis02 ./redis-server redis.conf cd .. cd redis03 ./redis-server redis.conf cd .. cd redis04 ./redis-server redis.conf cd .. cd redis05 ./redis-server redis.conf cd .. cd redis06 ./redis-server redis.conf cd ..
创建好启动脚本文件之后,需要修改该脚本的权限,使之能够执行,指令如下:
chmod +x start-all.sh
执行start-all.sh脚本,启动6个redis节点
至此6个redis节点启动成功,接下来正式开启搭建集群,
三:实战:搭建集群
Redis 官方提供了 redis-trib.rb 这个工具,作为搭建集群的专门工具。
Redis的实例全部运行之后,还需要redis-trib.rb工具来完成集群的创建,redis-trib.rb二进制文件在Redis包主目录下的src目录中,运行该工具依赖Ruby环境和gem,因此需要提前安装Ruby。
因为这个工具是一个ruby脚本文件,所以这个工具的运行需要ruby的运行环境,该环境相当于JVM虚拟机环境,是的ruby脚本运行时,就相当于java语言的运行需要在jvm上。
安装ruby,指令如下:
yum install ruby
/usr/local/redis/redis-4.0.9/src/redis-trib.rb create --replicas 1 \ 10.10.1.129:7001 10.10.1.129:7002 10.10.1.129:7003 \ 10.10.1.130:7004 10.10.1.130:7005 10.10.1.130:7006 \ 10.10.1.131:7007 10.10.1.131:7008 10.10.1.131:7009
--replicas 1 表示主从复制比例为 1:1,即一个主节点对应一个从节点;然后,默认给我们分配好了每个主节点和对应从节点服务,以及 solt 的大小,因为在 Redis 集群中有且仅有 16383 个 solt ,默认情况会给我们平均分配,当然你可以指定,后续的增减节点也可以重新分配。
/usr/local/redis/redis-4.0.9/src/redis-trib.rb create --replicas 1 \ > 10.10.1.129:7001 10.10.1.129:7002 10.10.1.129:7003 \ > 10.10.1.130:7004 10.10.1.130:7005 10.10.1.130:7006 \ > 10.10.1.131:7007 10.10.1.131:7008 10.10.1.131:7009 >>> Creating cluster >>> Performing hash slots allocation on 9 nodes... Using 4 masters: 10.10.1.129:7001 10.10.1.130:7004 10.10.1.131:7007 10.10.1.129:7002 Adding replica 10.10.1.131:7008 to 10.10.1.129:7001 Adding replica 10.10.1.129:7003 to 10.10.1.130:7004 Adding replica 10.10.1.130:7006 to 10.10.1.131:7007 Adding replica 10.10.1.131:7009 to 10.10.1.129:7002 Adding replica 10.10.1.130:7005 to 10.10.1.129:7001 M: 7a047cfaae70c30d0d7e1a5d9854eb7f11afe957 10.10.1.129:7001 slots:0-4095 (4096 slots) master M: 924d61969343b5cc2200bd3a2277e815dc76048c 10.10.1.129:7002 slots:12288-16383 (4096 slots) master S: b9ba251f575b5396da4bea307e25a98d85b3c504 10.10.1.129:7003 replicates a4a5de0be9bb5704eec17cbe0223076eb38fc4a4 M: a4a5de0be9bb5704eec17cbe0223076eb38fc4a4 10.10.1.130:7004 slots:4096-8191 (4096 slots) master S: bdc2f6b254459a6a6d038d93e5a3d3a67fe3e936 10.10.1.130:7005 replicates 7a047cfaae70c30d0d7e1a5d9854eb7f11afe957 S: 4ae20400d02e57e274f9b9f29d4ba120aa2b574c 10.10.1.130:7006 replicates 2b0f974e151cd798f474107ac68a47e188cc88a2 M: 2b0f974e151cd798f474107ac68a47e188cc88a2 10.10.1.131:7007 slots:8192-12287 (4096 slots) master S: b240d86fdf6abc73df059baf64b930387664da15 10.10.1.131:7008 replicates 7a047cfaae70c30d0d7e1a5d9854eb7f11afe957 S: 5b7989d5370aef41679e92a6bd34c30ac3be3581 10.10.1.131:7009 replicates 924d61969343b5cc2200bd3a2277e815dc76048c Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join........ >>> Performing Cluster Check (using node 10.10.1.129:7001) M: 7a047cfaae70c30d0d7e1a5d9854eb7f11afe957 10.10.1.129:7001 slots:0-4095 (4096 slots) master 2 additional replica(s) S: 4ae20400d02e57e274f9b9f29d4ba120aa2b574c 10.10.1.130:7006 slots: (0 slots) slave replicates 2b0f974e151cd798f474107ac68a47e188cc88a2 M: 924d61969343b5cc2200bd3a2277e815dc76048c 10.10.1.129:7002 slots:12288-16383 (4096 slots) master 1 additional replica(s) M: 2b0f974e151cd798f474107ac68a47e188cc88a2 10.10.1.131:7007 slots:8192-12287 (4096 slots) master 1 additional replica(s) S: 5b7989d5370aef41679e92a6bd34c30ac3be3581 10.10.1.131:7009 slots: (0 slots) slave replicates 924d61969343b5cc2200bd3a2277e815dc76048c S: b9ba251f575b5396da4bea307e25a98d85b3c504 10.10.1.129:7003 slots: (0 slots) slave replicates a4a5de0be9bb5704eec17cbe0223076eb38fc4a4 S: b240d86fdf6abc73df059baf64b930387664da15 10.10.1.131:7008 slots: (0 slots) slave replicates 7a047cfaae70c30d0d7e1a5d9854eb7f11afe957 S: bdc2f6b254459a6a6d038d93e5a3d3a67fe3e936 10.10.1.130:7005 slots: (0 slots) slave replicates 7a047cfaae70c30d0d7e1a5d9854eb7f11afe957 M: a4a5de0be9bb5704eec17cbe0223076eb38fc4a4 10.10.1.130:7004 slots:4096-8191 (4096 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
出现上述的输出则代表集群搭建成功啦!!!
说明:
M: 7a047cfaae70c30d0d7e1a5d9854eb7f11afe957 为主节点id S: b240d86fdf6abc73df059baf64b930387664da15 为从节点的id
目前来看,7001、7002、7004、7007 为主节点,7003、7005、7008、7009 为从节点,并向你确认是否同意这么配置。输入 yes 后,会开始集群创建。
四:redis cluster小结
redis cluster在设计的时候,就考虑到了去中心化、去中间件,也就是说,集群中的每个节点都是平等关系,都是对等的,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
Redis 集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。redis cluster 默认分配了 16384 个 slot,当我们 set 一个 key 时,会用CRC16算法来取模得到所属的 slot,然后将这个 key 分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。所以我们在测试的时候看到 set 和 get 的时候,直接跳转到了7000端口的节点。
Redis 集群会把数据存在一个 master 节点,然后在这个 master 和其对应的 salve 之间进行数据同步。当读取数据时,也根据一致性哈希算法到对应的 master 节点获取数据。只有当一个 master 挂掉之后,才会启动一个对应的 salve 节点,充当 master 。
需要注意的是:必须要3个或以上的主节点,否则在创建集群时会失败,并且当存活的主节点数小于总节点数的一半时,整个集群就无法提供服务了。
Codis
Codis 是一个分布式 Redis 解决方案, 对于上层的应用来说, 连接到 Codis Proxy 和连接原生的 Redis Server 没有明显的区别 (有一些命令不支持), 上层应用可以像使用单机的 Redis 一样使用, Codis 底层会处理请求的转发, 不停机的数据迁移等工作, 所有后边的一切事情, 对于前面的客户端来说是透明的, 可以简单的认为后边连接的是一个内存无限大的 Redis 服务,当然,前段时间redis官方的3.0出了稳定版,3.0支持集群功能,codis的实现原理和3.0的集群功能差不多,我了解的现在美团、阿里已经用了3.0的集群功能了,
1.什么是Codis?
Codis 是一个分布式 Redis 解决方案, 对于上层的应用来说, 连接到 Codis Proxy 和连接原生的 Redis Server 没有明显的区别
(不支持的命令列表), 上层应用可以像使用单机的 Redis 一样使用, Codis 底层会处理请求的转发, 不停机的数据迁移等工作,
所有后边的一切事情, 对于前面的客户端来说是透明的, 可以简单的认为后边连接的是一个内存无限大的 Redis 服务。
2.codis介绍
Codis是一个分布式Redis解决方案,对于上层的应用来说,连接到Codis Proxy和连接原生的RedisServer没有明显的区别,有部分命令不支持。
Codis底层会处理请求的转发,不停机的数据迁移等工作,所有后边的一切事情,
对于前面的客户端来说是透明的,可以简单的认为后边连接的是一个内存无限大的Redis服务.
Codis由四部分组成
| Codis-proxy | 实现redis协议,由于本身是无状态的,因此可以部署很多个节点 |
|---|---|
| Codis-config | 是codis的管理工具,包括添加/删除redis节点添加/删除proxy节点,发起数据迁移等操作,自带httpserver,支持管理后台方式管理配置 |
| Codis-server | 是codis维护的redis分支,基于2.8.21分支,加入了slot的支持和原子的数据迁移指令; codis-proxy和codis-config只能和这个版本的redis交互才能正常运行 |
| Zookeeper | 用于codis集群元数据的存储,维护codis集群节点 |
3.Codis的架构
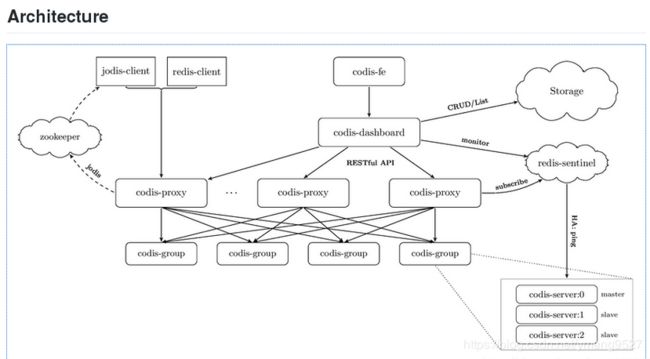
4.Codis的优缺点
(1)优点
对客户端透明,与codis交互方式和redis本身交互一样
支持在线数据迁移,迁移过程对客户端透明有简单的管理和监控界面
支持高可用,无论是redis数据存储还是代理节点
自动进行数据的均衡分配
最大支持1024个redis实例,存储容量海量
高性能
(2)缺点
采用自有的redis分支,不能与原版的redis保持同步
如果codis的proxy只有一个的情况下, redis的性能会下降20%左右
某些命令不支持,比如事务命令muti
国内开源产品,活跃度相对弱一些
常见问题
1 如何解决缓存穿透与缓存雪崩
如何解决缓存穿透与缓存雪崩。这是基本问题也是面试常问问题。
作为一个内存数据库,redis也总是免不了有各种各样的问题,这篇文章主要是针对其中两个问题进行讲解:缓存穿透和缓存雪崩。
一、缓存穿透
1、概念
缓存穿透的概念很简单,用户想要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
这里需要注意和缓存击穿的区别,缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
为了避免缓存穿透其实有很多种解决方案。下面介绍几种。
2、解决方案
(1)布隆过滤器
布隆过滤器是一种数据结构,垃圾网站和正常网站加起来全世界据统计也有几十亿个。网警要过滤这些垃圾网站,总不能到数据库里面一个一个去比较吧,这就可以使用布隆过滤器。假设我们存储一亿个垃圾网站地址。
可以先有一亿个二进制比特,然后网警用八个不同的随机数产生器(F1,F2, …,F8) 产生八个信息指纹(f1, f2, …, f8)。接下来用一个随机数产生器 G 把这八个信息指纹映射到 1 到1亿中的八个自然数 g1, g2, …,g8。最后把这八个位置的二进制全部设置为一。过程如下:
有一天网警查到了一个可疑的网站,想判断一下是否是XX网站,首先将可疑网站通过哈希映射到1亿个比特数组上的8个点。如果8个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。
那这个布隆过滤器是如何解决redis中的缓存穿透呢?很简单首先也是对所有可能查询的参数以hash形式存储,当用户想要查询的时候,使用布隆过滤器发现不在集合中,就直接丢弃,不再对持久层查询。
这个形式很简单。
2、缓存空对象
当存储层不命中后,即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护了后端数据源;
但是这种方法会存在两个问题:
如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多的空值的键;即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
如何避免?
1:对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert了之后清理缓存。
2:对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中,查询时通过该bitmap过滤。
二、缓存雪崩
1、概念
缓存雪崩是指,缓存层出现了错误,不能正常工作了。于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
2、解决方案
(1)redis高可用
这个思想的含义是,既然redis有可能挂掉,那我多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群。
(2)限流降级
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
(3)数据预热
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,会给后端系统带来很大压力。导致系统崩溃。
如何避免?
1:在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
2:做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期
3:不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
2 什么是Redis持久化?Redis有哪几种持久化方式?优缺点是什么?
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失。
Redis 提供了两种持久化方式:RDB(默认) 和AOF
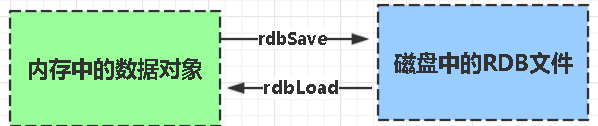
RDB:
rdb是Redis DataBase缩写
功能核心函数rdbSave(生成RDB文件)和rdbLoad(从文件加载内存)两个函数
AOF:
Aof是Append-only file缩写
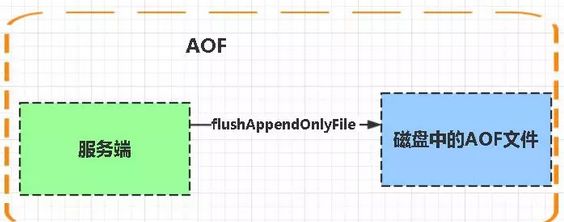
每当执行服务器(定时)任务或者函数时flushAppendOnlyFile 函数都会被调用, 这个函数执行以下两个工作
aof写入保存:
WRITE:根据条件,将 aof_buf 中的缓存写入到 AOF 文件
SAVE:根据条件,调用 fsync 或 fdatasync 函数,将 AOF 文件保存到磁盘中。
存储结构:
内容是redis通讯协议(RESP )格式的命令文本存储。
比较:
1、aof文件比rdb更新频率高,优先使用aof还原数据。
2、aof比rdb更安全也更大
3、rdb性能比aof好
4、如果两个都配了优先加载AOF
3 什么是一致性哈希算法
Redis 集群会把数据存在一个 master 节点,然后在这个 master 和其对应的 salve 之间进行数据同步。当读取数据时,也根据一致性哈希算法到对应的 master 节点获取数据。只有当一个 master 挂掉之后,才会启动一个对应的 salve 节点,充当 master 。什么是一致性哈希算法?
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对 K/n 个关键字重新映射,其中K是关键字的数量, n是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
简单的说,一致性哈希是将整个哈希值空间组织成一个虚拟的圆环,如假设哈希函数H的值空间为0-2^32-1(哈希值是32位无符号整形),整个哈希空间环如下:
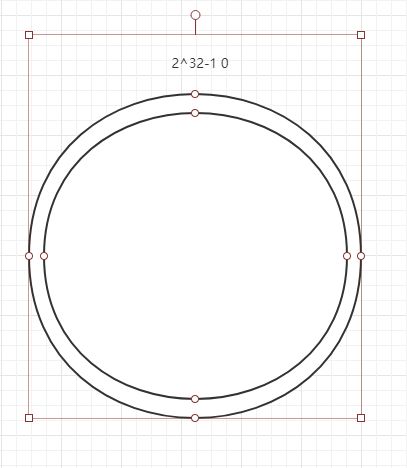
整个空间按顺时针方向组织,0和2^32-1在零点中方向重合。
接下来,把服务器按照IP或主机名作为关键字进行哈希,这样就能确定其在哈希环的位置。
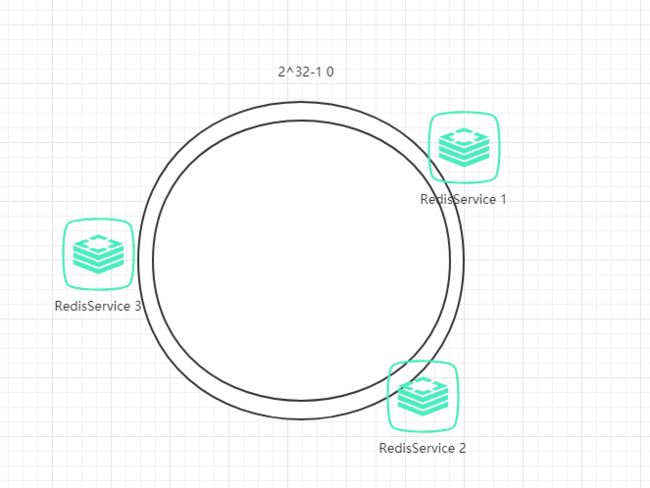
然后,我们就可以使用哈希函数H计算值为key的数据在哈希环的具体位置h,根据h确定在环中的具体位置,从此位置沿顺时针滚动,遇到的第一台服务器就是其应该定位到的服务器。
例如我们有A、B、C、D四个数据对象,经过哈希计算后,在环空间上的位置如下:
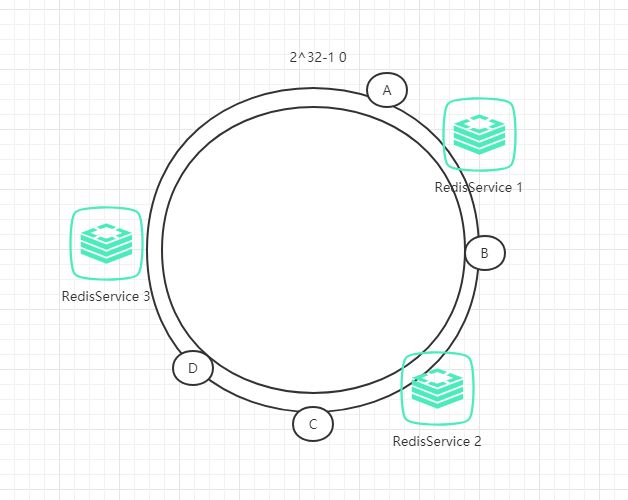
根据一致性哈希算法,数据A会被定为到Server 1上,数据B被定为到Server 2上,而C、D被定为到Server 3上。
3.1 容错性和扩展性
那么使用一致性哈希算法的容错性和扩展性如何呢?
3.1.1 容错性
假如RedisService2宕机了,那么会怎样呢?
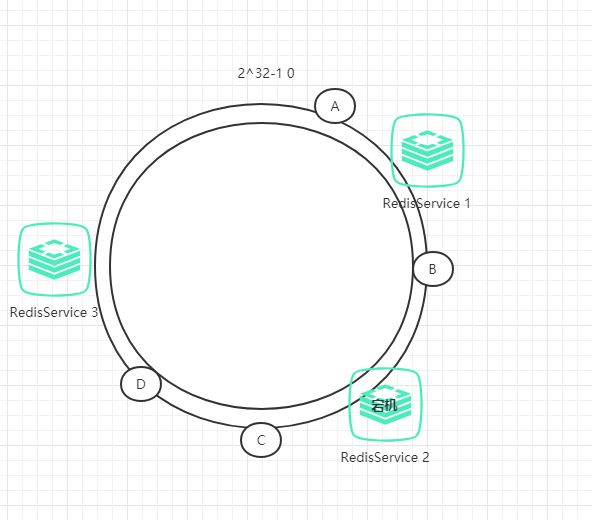
那么,数据B对应的节点保存到RedisService3中。因此,其中一台宕机后,干扰的只有前面的数据(原数据被保存到顺时针的下一个服务器),而不会干扰到其他的数据。
3.1.2 扩展性
下面考虑另一种情况,假如增加一台服务器Redis4,具体位置如下图所示:
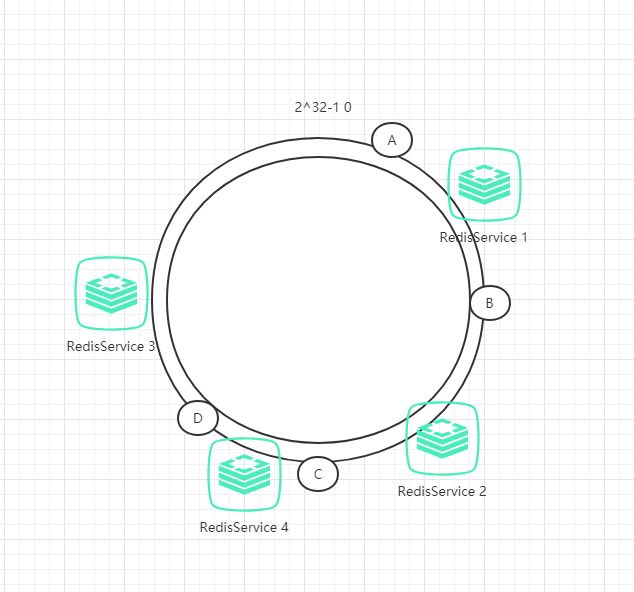
原本数据C是保存到Redis3中,但由于增加了Redis4,数据C被保存到Redis4中。干扰的也只有Redis3而已,其他数据不会受到影响。
因此,一致性哈希算法对于节点的增减都只需重定位换空间的一小部分即可,具有较好的容错性和可扩展性
3.2 虚拟节点
前面部分都是讲述到Redis节点较多和节点分布较为均衡的情况,如果节点较少就会出现节点分布不均衡造成数据倾斜问题。
例如,我们的的系统有两台Redis,分布的环位置如下图所示:
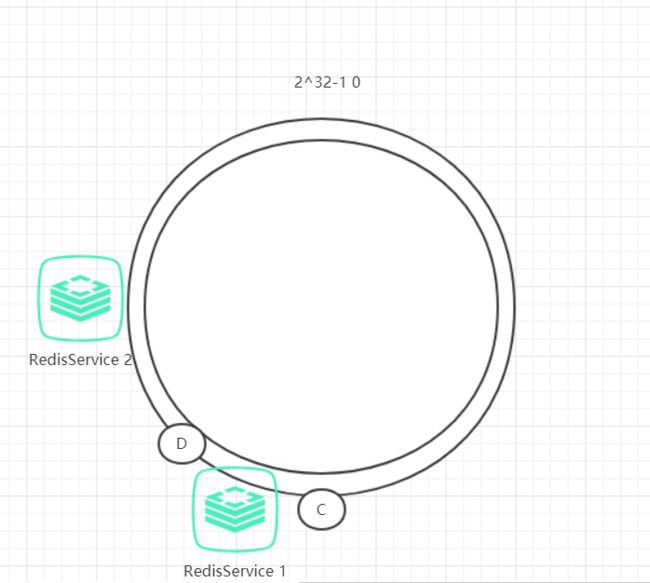
这会产生一种情况,Redis4的hash范围比Redis3的hash范围大,导致数据大部分都存储在Redis4中,数据存储不平衡。
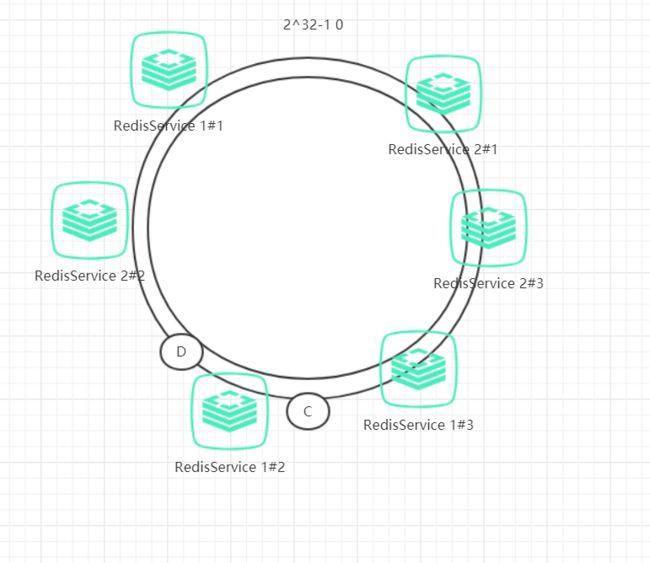
为了解决这种数据存储不平衡的问题,一致性哈希算法引入了虚拟节点机制,即对每个节点计算多个哈希值,每个计算结果位置都放置在对应节点中,这些节点称为虚拟节点。
具体做法可以在服务器IP或主机名的后面增加编号来实现,例如上面的情况,可以为每个服务节点增加三个虚拟节点,于是可以分为 RedisService1#1、 RedisService1#2、 RedisService1#3、 RedisService2#1、 RedisService2#2、 RedisService2#3,具体位置如下图所示:
对于数据定位的hash算法仍然不变,只是增加了虚拟节点到实际节点的映射。例如,数据C保存到虚拟节点Redis1#2,实际上数据保存到Redis1中。这样,就能解决服务节点少时数据不平均的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。