Fluid — 云原生环境下的高效“数据物流系统”
-
第一:云平台计算存储分离架构导致数据访问延时高。为了监控资源灵活性满足本地无依赖的要求,云原生应用大多采用计算存储分离架构。但是从访问效率的角度来看,要求用云网络传输带宽,当数据密集型应用在云上运行时,会造成数据访问瓶颈、性能下降。
-
第二:混合云场景下跨存储系统的联合分析困难。大多公司/组织通常基于不同存储管理数据支撑多样化应用,具备其各自的特点。Ceph、GlusterFS、HDFS 都会被广泛使用,数据也通常会散落在这些异构存储当中。然而,当需要联合数据进行综合性分析时,会增加数据移动成本,必然导致在云原生环境下需要面对网络费用、等待延时、人工操作等比较复杂的问题。
-
第三:云环境中数据安全治理与多维度管理复杂。数据是很多公司的生命线,数据泄露、误操作、生命周期管理不当都会造成巨大损失。如何在云原生环境中保障数据的隔离,保护好用户的数据生命周期,都存在较大挑战。
5. Kubernetes 生态中缺失的一块抽象
综上所述,我们可以总结出一种现象:Kubernetes 生态中目前缺少数据密集型应用高效支撑的这块拼图。现有 Kubernetes 环境能对很多资源进行很好的抽象,包括将资源对象计算抽象成 Pod、将存储抽象成了 PV/PVC、将网络抽象成了 Service。云原生领域还有一些存储抽象主要面向数据持久化进行工作,提供对象和文件的持久化存储管理。但这些软件的功能缺乏以应用为中心的数据抽象及相关生命周期管理。
6. 商店购物模式演变的联想
为了更好地理解这些问题,我们可以做一些联想性的思考。如下图所示,引入商品购物模式,我们将商品、超市、客户类比为数据、存储、应用。

-
商品和数据都会被消费,商品会被消费者购买掉,数据会被应用读走,两者有一定类似性。
-
超市和存储类似,都起到贮藏与供应的功能。商品平时会贮藏在超市的货架上,当购买时扮演到供应的角色;对于存储而言,我们平时贮藏的数据都会被持久化到存储设备里,当应用需要时提供给用户。
-
客户和应用类似,客户会到商店消费购买商品。类似的,应用会到存储读取数据。
商品、超市(商铺) 、客户模式,在过去几千年里发展得非常成熟,非常稳定。直到 2000 年之后发生了颠覆性的变化,这就是电商的产生。电商发明了线上购物模式,其特点体现在不再以店铺为中心而是以客户为中心,商品贮藏在仓库,客户可以在线上虚拟商铺挑选商品,最后由现代化物流将商品交付到客户,交易过程高效便捷、交易量更大。商品直接放在仓库里,仓库可以进行规范化、独立化管理,之后客户到电商平台上购买货物,会非常便捷、方便。客户不需要到店铺,在地铁上、车上、办公室、家里都可以用手机、电脑进行购物,而且不会存在商品寻找低效的情况,因为客户是在互联网上购物,都可以通过检索方式查找海量商品;线上购物的另一个优势是交易频次变得更高,交易量变得更大;客户也不需要必须去店里提货,快递可以直接送货上门,非常方便。

电商模式的成功有很多因素,其中有两大因素非常关键,一是如支付宝这样的第三方数字化支付工具的出现,二是如菜鸟这样专业化的物流系统产生,构建起四通八达的物流网络,使快速的商品寄送模式得以实现。反观回到现在计算机系统中,在现代云架构下,数据贮存在云存储系统中,数据密集型应用也以pod等各种各样资源描述符的方式在云原生环境下运行,但中间却缺乏一个高效的数据交付、数据递送的方式。也就是说,在云原生架构下面,数据贮藏在云存储系统当中,应用还是根据需要去访问数据,但由于类似的数据**“物流系统”的缺失,导致数据密集型应用消费访问数据在云平台上比较低效**。

Fluid 核心理念
===============================================================================
基于以上的分析,以及从观察中得到的联想,下面来介绍 Fluid 的核心理念。
1. Fluid 扮演云原生的“数据物流系统”角色

我们可以将 Fluid 所扮演角色理解为云原生环境下“数据物流系统”。回顾一下,在早先的大数据平台中,数据的访问尽量都是通过本地化进行。当用户写一个 MapReduce Job,Job 里包含很多 Task, 其中关注比较多的就是 MapTask 处理数据时是尽量将 Task 调度到用户要处理的数据所在的节点上运行。这种情况下,当用户访问数据时,尽管该数据是在 HDFS 这个分布式系统中,但本质上相当于从分布式系统中的本地节点上获取,我们称之为 Data Fetch。
随着大数据生态系统的迅速发展,其上的应用框架变得越来越多,底层存储系统也变得越来越丰富,各种上层应用要访问不同种类、多样化系统的痛点越来越明显,于是出现了 Alluxio 这样一个优秀的开源项目,来统一管理底层不同存储系统,为上层提供统一化的标准接口,对上层应用屏蔽不同存储的差异。而且 Alluxio 提供内存缓存,加速数据访问。这个过程就解耦了本地化的情况,存储就可以实现分离。这种分离架构在部署好之后通常还是静态的,实现从 Data Fetch 变成 Data Access 的过程。
Fluid 是在 Alluxio 基础之上,在云原生环境的调度层面上进行进一步的研究和拓展,希望获取云原生环境下数据节点以及应用的动态变化信息,让这一类静态的缓存等中间件动态、灵活地调动起来,从而让应用灵活性变得更强,实现数据智能化递送到应用的效果,即动态弹性(Data Delivery) 。
在进行项目设计时,我们希望 Fluid 从视角、思路、理念三个层次带来一些革新:
-
新视角:从云原生资源调度结合与数据密集型处理两个方面,重新综合审视云原生场景的数据抽象与支撑访问。
-
新思路:针对容器编排缺乏数据感知,数据编排缺乏对云上架构变化的感知,提出了协同编排、多维管理、智能感知的一系列理念和创新方法;从而形成一套云原生环境下数据密集型应用的高效支撑平台。
-
新理念:通过 Fluid 这个项目,希望让数据可以像流体一样在云平台中、在资源编排层和数据处理层之间能够灵活高效地被访问、转换和管理。
2. 核心理念
简单来说,Fluid 的核心理念,可以分为“一个抽象”和“两个编排”。
首先在云原生环境里,抽象出了数据集的概念,它能够提供一个对底层存储的包装,对上层也能提供各种各样的支撑和访问能力,从而通过 API 的方式来简单地在 K8s 下实现对数据的操作。
在这个基础之上,Fluid 提供了两个编排的能力:
首先是对于数据集进行编排,具体是指基于容器调度管理的数据进行编排。传统的方式只对数据本身进行管理,而 Fluid 的数据集编排则转为对承载数据的引擎进行编排和管理。通过对数据引擎进行合理的扩容、缩容和调度操作,和数据引擎的交互,从而实现对数据的迁移、缓存以及数据在 K8s 平台下灵活调度的管理和变化。
第二个编排是对使用和消费这类数据集的应用进行编排。我们需要处理这些应用的调度,在调度时尽量使其感知缓存数据集,这样就可以在这调度应用的时候合理选择节点,从而高效地进行相关计算。
总结来讲,Fluid 具有以下三大功能:
1)提供云平台数据集抽象的原生支持
数据密集型应用所需基础支撑能力功能化,实现数据高效访问并降低多维成本。
2)基于容器调度管理的数据集编排
通过数据集缓存引擎与 Kubernetes 容器调度和扩缩容能力的相互配合,实现数据集可迁移性。
3)面向云上数据本地化的应用调度
Kubernetes 调度器通过与缓存引擎交互获得节点的数据缓存信息,将使用该数据的应用以透明的方式调度到包含数据缓存的节点,最大化缓存本地性的优势。
Fluid 架构功能
===============================================================================
1. Fluid 系统架构

Fluid 是构建在 K8s 上的系统,对原生 K8s 具备良好的兼容性,无需修改任意代码。如上图所示,用户需要定义两个 CRD,分别是 Dataset 和 Runtime。Dataset 是数据集的通用定义,这是我们提供的 K8s 资源对象,需要写 YAML 文件来定义数据集从哪儿来,以及想要放到哪儿去;Runtime 是存储这些数据集的缓存引擎,目前使用的是开源的分布式缓存系统 Alluxio。这里要注意的是 Dataset 和 Runtime 定义的时候,它通常是要具有相同 Namespace,从而实现很好的绑定。
Fluid Operator 是 Fluid 项目的核心,它分为两部分。第一部分是 Fluid-controller-manager,包含很多 Controller;另一部分为 Fluid-Scheduler。这两个组件完成了编排调度的操作。Fluid-controller-manager 做的工作就是对数据进行编排,包括三个 Controller。这三个 Controller 从逻辑上它们是独立的,可以去做单进程。但为了降低复杂性,很多 Controller 的功能编译时被合并成一个和多个可执行文件,所以在真正运行起来时,也是一个进程。
-
数据集的 Dataset Controller 负责整个数据集的生命周期管理,包括数据集的创建,以及要和哪个 Runtime 进行绑定。
-
Runtime Controller 负责数据集如何在云原生平台上被调度与缓存,应该放在哪些节点上,要有多少副本。
-
Volume Controller:由于 Fluid 是基于 K8s 运行,因此需要和 K8s 进行对接,这里我们使用的是 PVC(数据持久卷)协议,这是 K8s 本地存储栈的协议,使用非常广泛,Fluid 与 PVC 的对接非常流畅。
最下面为 Cache Runtime Engine,是真正完成缓存数据具体工作的地方。
图中右边部分的 Fluid-Scheduler 主要是基于定义好的 dataset、runtime controller 等具体信息,对 K8s 的调度器做一些扩展。这里面包含两个 Plugin:
-
Cache co-locality Plugin:Cache co-locality Plugin 做的事就是结合前面数据编排的信息,把应用调度到最合适的节点上,然后尽量能够让用户去读到缓存节点里面的信息。
-
Prefetch Plugin:当用户集群还没有缓存流入数据情况之下,且知道应用肯定是要读哪一类数据时,尤其在应用调度和编排运行之前,可以做 Prefetch 的调度,将这个数据从最底下的存储卷当中缓存到数据缓存里面,可以手动触发。
再往下就是标准 K8s。通过 K8s 可以对接底层不同的存储,具体的对接方式可通过 K8s 的 PVC 完成。由于通过 Alluxio 进行了抽象,可以直接支持 Alluxio 本身支持的存储类型。
2. Fluid 的功能概念
Fluid 不是全存储加速和管理,而是以应用为中心数据集加速和管理。
三个重要概念:
-
Dataset:数据集是逻辑上相关的一组数据的集合,不同数据集的特性和优化都是不一样的,所以对于数据集是要分开管理的,一致的文件特性,会被同一运算引擎使用。
-
Runtime:真正实现数据集安全性,版本管理和数据加速等能力的执行引擎的接口,包括如何创建、生命周期如何管理等等,定义了一系列生命周期的方法。
-
AlluxioRuntime:来自 Alluxio 社区,是支撑 Dataset 数据管理和缓存的执行引擎高效实现。
通过以上概念与架构,实现了以下功能:
1)加速
-
Observation: know the cache capacity easily.
-
Portableand Scalable: adjust the cache capacity on demand.
-
Co-locality: bring data close to compute, and bring compute close to data.
通过 K8s 提供了这个很好的可观测性,我们能够知道我们的缓存容量和当前状态,进一步地我们就可以很灵活的去迁移和扩展缓存,然后按需增加缓存容量。并且在扩展和迁移过程当中会充分考虑 co-locality,即本地性。将数据和计算在编排和调度时放在一起,从而实现加速目的。
2)数据卷接口,统一访问不同存储
从对接上面,支持数据卷接口,从而统一访问不同的存储,且 K8s 的任何数据卷都可以包装成 Fluid-Dataset 来进行使用加速。
3)隔离
隔离机制使得对数据集的访问可以在不同存储加速间进行隔离,并且实现权限控制管理。
3. 如何使用 Fluid
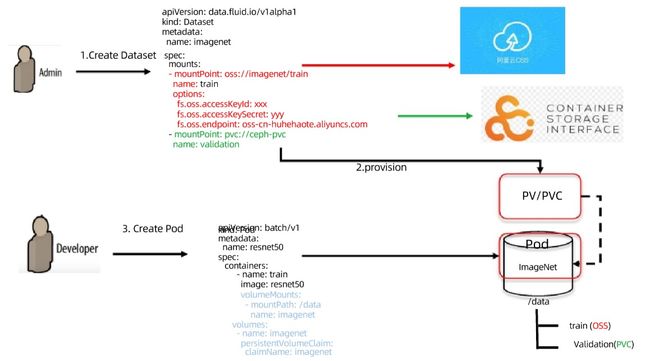
以上图为例,用户在使用场景中需要使用来自两个不同地方的数据,假设一个来自阿里云,另外一个是本地存储 Ceph。在 Fluid 里面我们可以很容易地描述这样的数据集,通过创建一个自定义 K8s 资源对象 Dataset,对应的 mountPoint 可以加载两个,分别是阿里云和 Ceph。
创建好就可以运行,这个过程中 Fluid 会创建一个 Dataset,并自动将它变成一个 PVC。当用户需要用这个数据时创建一个 Pod,以 PVC 挂载的方式,将 Dataset 关联到运行中的 Pod 中对数据进行访问。甚至 Pod 根本都不知道 PVC 后台运行的是 Fluid,而不是其他的存储,例如 NFS。整个过程和背后的原理对用户都是透明的,这使得对遗留程序的对接非常友好。
4. 如何检查和观测 dataset 状态
