06 哈希表
哈希表
- 对应题目类型
- 哈希表基础介绍
-
- 散列表查找步骤
- 散列函数构造方法
- 解题思想
- 题目汇总
-
- 判断两个字符串是否存在包含关系
-
-
- [242. 有效的字母异位词](https://leetcode.cn/problems/valid-anagram/)
- [383. 赎金信](https://leetcode.cn/problems/ransom-note/)
- [438. 找到字符串中所有字母异位词](https://leetcode.cn/problems/find-all-anagrams-in-a-string/)
-
- 合理选择Hash表的key和value
-
-
- [49. 字母异位词分组](https://leetcode.cn/problems/group-anagrams/)
-
- 判断一个数是否之前出现过
-
-
- [202. 快乐数](https://leetcode.cn/problems/happy-number/)
- 例1:第一个只出现一次的字符
-
- 找出数组中和为目标值的两个加数
-
-
- [1. 两数之和](https://leetcode.cn/problems/two-sum/)
- [454. 四数相加 II](https://leetcode.cn/problems/4sum-ii/)
-
- 自行构造hash函数
-
-
- [572. 另一棵树的子树](https://leetcode.cn/problems/subtree-of-another-tree/)
-
- 其他题目
-
-
-
- [1624. 两个相同字符之间的最长子字符串](https://leetcode.cn/problems/largest-substring-between-two-equal-characters/)
-
-
对应题目类型
以空间换时间的查找。
- 当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法。
- 需要判断一个元素是否出现过的场景也应该第一时间想到哈希法
Hash table的构造:
- 如果题目中给定的字符串是有限个数的,可以考虑直接使用数组实现hash table,字符的ASCII码作为数组下标
- ①直接定义一个256大小的数组:ASCII码作为数组下标
- ②字符串中只有小写字母,只需定义一个26大小的数组:
ASCII码-"a"的ASCII码作为数组下标
- 如果题目中给定的字符的数目比较多,可以考虑使用更高级的数据结构实现hash table
- C++:unordered_map、map
- JAVA:Map
- Python:dict、collections.Counter、collections.defaultdict
哈希表基础介绍
哈希表又称散列表,其基础知识脉络如下: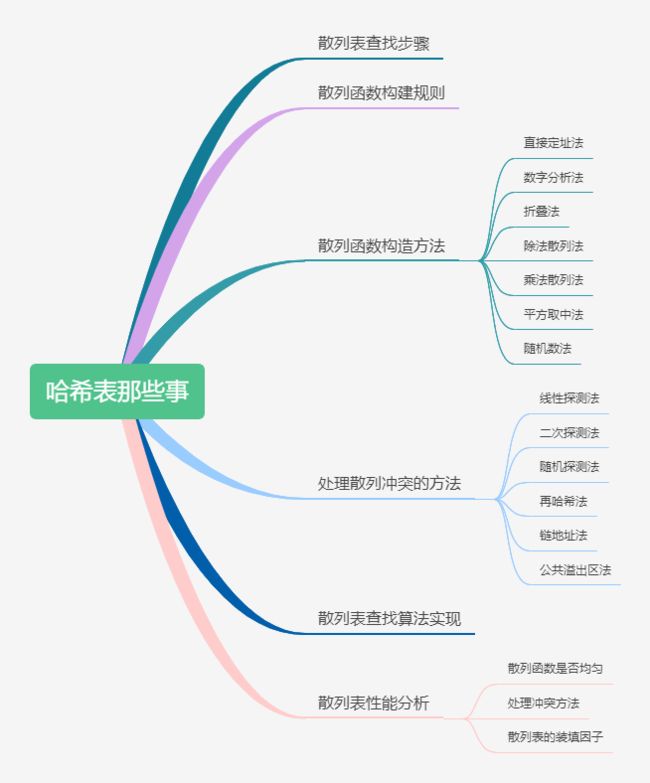
参考链接-代码随想录:哈希表
散列表查找步骤
根据关键码的值直接进行访问的数据结构,散列表的实现常常叫做散列(hasing)。散列是一种用于以常数平均时间执行插入、删除和查找的技术。
整个散列过程主要分为两步:
(1)通过散列函数计算记录的散列地址,并按此散列地址存储该记录。
(2) 查找时,我们通过同样的散列函数计算记录的散列地址,按此散列地址访问该记录。
散列函数:
存储位置 = f (关键字)
输入:关键字 输出:存储位置(散列地址)
散列技术是在通过记录的存储位置和它的关键字之间建立一个确定的对应关系 f ,使得每个关键字 key 都对应一个存储位置 f(key)。
散列函数的设计规则:
- 计算简单
- key的每次计算结果应该是一致的
- 尽量结果均匀分布
散列函数构造方法
- 直接定址法
- 数字分析法
- 折叠法
- 除法散列法
- 乘法散列法
- 平方取中法
- 随机数法
解题思想
构建hash table,根据元素信息求解对应的Hash table的下标对应下标处存储需要的相关信息,以空间换时间。
题目汇总
判断两个字符串是否存在包含关系
242. 有效的字母异位词
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
383. 赎金信
题目:
给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。
如果可以,返回 true ;否则返回 false 。
magazine 中的每个字符只能在 ransomNote 中使用一次。
利用hash table的解题思想:
(题目中给定字符串中只包含小写字母)
因此定义一个大小为26的数组,存储的是26个小写字母在字符串中出现的次数,
首先对第一个字符串进行遍历,将数组中的对应字符的个数++
然后对第二个字符串进行遍历,将数组中的对应字符的个数–
如果,数组中存在-1的元素,则返回False。
只需要定义一个数组,即可。
class Solution {
public boolean canConstruct(String ransomNote, String magazine) {
//类比242.有效的字母异位词一题,该题目则是需要magazine的字母可以涵盖sansomNote
int len1=ransomNote.length();
int len2=magazine.length();
if(len1>len2) return false;
Map<Character,Integer> map=new HashMap<>();
for(int i=0;i<len2;i++){
char c=magazine.charAt(i);
map.put(c,map.getOrDefault(c,0)+1);
}
for(int i=0;i<len1;i++){
char c=ransomNote.charAt(i);
if(!map.containsKey(c)) return false;
if(map.get(c)==1){
map.remove(c);
}else{
map.put(c,map.get(c)-1);
}
}
return true;
}
}
Python中可以使用collections包中的Counter类和defaultdict类实现。这两个类都是dict类的子类但是相比dict使用起来更加方便。
- collections.Counter
- collections.defaultdict
class Solution(object):
def isAnagram(self, s, t):
"""
:type s: str
:type t: str
:rtype: bool
"""
# 使用Counter
# from collections import Counter
# scount=Counter(s)
# tcount=Counter(t)
# return scount==tcount:
# 使用defaultdict
from collections import defaultdict
sdict=defaultdict(int)
tdict=defaultdict(int)
for i in s:
sdict[i]+=1
for j in t:
tdict[j]+=1
return sdict==tdict
438. 找到字符串中所有字母异位词
题目描述:
给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
异位词 指由相同字母重排列形成的字符串(包括相同的字符串)。
解题思想:
- 首先,在字符串s中找满足某一条件的所有子串——滑动窗口法
- 需要注意的是,与以往的找子串的题目不同,这个滑动窗口有一个限制条件:窗口大小恒定不变。因此解决起来会简单很多
- 其次,寻找异位词——hash table解决
- 分别定义s和p的defaultdict用于存储两个字符串字符对应的字符出现次数哈希表
class Solution {
public List<Integer> findAnagrams(String s, String p) {
List<Integer> res=new ArrayList<>();
if(s.length()<p.length()) return res;
Map<Character,Integer> map=new HashMap<>();
Map<Character,Integer> temp=new HashMap<>();
for(int i=0;i<p.length();i++){
char c=p.charAt(i);
map.put(c,map.getOrDefault(c,0)+1);
}
int r=p.length()-1;
int l=0;
//初始化temp
for(int i=0;i<=r;i++){
char c=s.charAt(i);
temp.put(c,temp.getOrDefault(c,0)+1);
}
while(r<s.length()){
if(temp.equals(map)){
res.add(l);
}
r++;
if(r==s.length()) break;
temp.put(s.charAt(r),temp.getOrDefault(s.charAt(r),0)+1);
char lc=s.charAt(l);
if(temp.get(s.charAt(l))==1){
temp.remove(s.charAt(l));
}else{
temp.put(s.charAt(l),temp.getOrDefault(s.charAt(l),0)-1);
}
l++;
}
return res;
}
}
合理选择Hash表的key和value
49. 字母异位词分组
题目描述:
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的字母得到的一个新单词,所有源单词中的字母通常恰好只用一次。
解题思想:
构造Hash table:
- key:一个字符串中每个字符及其出现的次数
- value:列表,存储对应key的字符串
最终返回hash table的values即可。
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
//Map判断一个数是否之前出现过
202. 快乐数
题目描述:
编写一个算法来判断一个数 n 是不是快乐数。
「快乐数」 定义为:
对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。
然后重复这个过程直到这个数变为 1,也可能是** 无限循环** 但始终变不到 1。
如果这个过程 结果为 1,那么这个数就是快乐数。
如果 n 是 快乐数 就返回 true ;不是,则返回 false 。
解题思想:
可以直观感觉这个题就是一个循环求解的数学问题,但是题目中说,可能存在“无限循环”。那么对于循环的情况如何跳出循环结束计算呢?
循环——顾名思义就是出现了之前出现过得数字。
因此可以使用hash table。
class Solution {
public boolean isHappy(int n) {
//需要定义一个set用来存储历史值
Set<Integer> set=new HashSet<>();
while(n!=1){
//计算当前n的每个位置数字的平方和
int res=0;
while(n!=0){
int val=n%10;
res+=val*val;
n/=10;
}
if(set.contains(res)) return false;
set.add(res);
n=res;
}
return true;
}
}
例1:第一个只出现一次的字符
题目描述:
在字符串中找出第一个只出现一次的字符,
如,输入“abaccdeff”,则输出“b”
解题思想:
题目关键点在于:
- 第一个
- 只出现一次
如何解决?:
- 只出现一次:使用hash table,遍历字符串,记录字符串中元素出现的个数
- 第一个:再次遍历字符串,直接对每个元素查找hash table获取其出现次数
找出数组中和为目标值的两个加数
1. 两数之和
题目描述:
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
解题思想:
在数组中找出和为目标值的唯一一对元素。(注意一个元素不可在结果中重复使用)
- 首先,定义一个hash table,存储数组中的元素及其对应下标:
- key:元素;value:数组下标
- 存储的是:在列表中其前面的元素中没有找到其对应加数的元素(为什么这样呢?防止加法中一个元素重复使用)
- 对nums进行遍历,对每个元素x对应加数target-x进行判断:
- 如果,加数在hash table中,直接返回下标结果
- 如果,加数不在hash table,将该元素及其下标存储在hash table中
class Solution(object):
def twoSum(self, nums, target):
"""
:type nums: List[int]
:type target: int
:rtype: List[int]
"""
# 最直接的思想:两层循环,时间复杂度O(n^2)
# 优化:使用hash table,时间复杂度O(n)
# 实现:定义一个dict,对nums进行遍历,然后
adddict=dict()
for i,x in enumerate(nums):
if target-x in adddict:
return [adddict[target-x],i]
adddict[x]=i
return []
454. 四数相加 II
题目描述:
给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足:
0 <= i, j, k, l < n
nums1[i] + nums2[j] + nums3[k] + nums4[l] == 0
解题思想:
hash table可以解决寻找数组中对应加数的题目:给定一个数组,找出数组中和为目标值的两个元素。
其思想:对数组进行一次遍历,对每个元素寻找数组中是否存在其对应加数。
寻找加数,即定义一个dict存储未配对的元素以及其数组中的下标。
该题目变成了四个数相加:
因此采用:分组+Hash table 的思想
- 分组:将四个元素变成两个元素
- hash table:类比于两数之和
具体实现:
- 定义两个dict,分别存储,数组A数组B的元素和及其出现的次数,以及数组C数组D的元素和及其出现的次数。
- 对dict1进行遍历,对于其元素x,在dict2中寻找target-x是否存在,如果存在~~~
class Solution(object):
def fourSumCount(self, nums1, nums2, nums3, nums4):
"""
:type nums1: List[int]
:type nums2: List[int]
:type nums3: List[int]
:type nums4: List[int]
:rtype: int
"""
# 四数相加:分组+hash table
# 分组:先将四个元素转成两个元素,即两两分组,先求和。
# 和的存储不是简单的使用一个list,而是存储,和及其出现的次数
from collections import defaultdict
sums1,sums2=defaultdict(int),defaultdict(int)
for i in nums1:
for j in nums2:
sums1[i+j]+=1
for i in nums3:
for j in nums4:
sums2[i+j]+=1
adddict=dict()
res=0
for add,num in sums1.items():
if 0-add in sums2:
res+=sums2[0-add]*num
return res

自行构造hash函数
如何设计一个不会(概率尽可能小)冲突的hash函数?
- 加入所有可能的影响因素
- 设计“双哈希”、“三哈希”、“四哈希”等,“双哈希”意思就是使用两个hash函数进行组合,可以是相加也可以是相乘。
572. 另一棵树的子树
题目描述:
给你两棵二叉树 root 和 subRoot 。检验 root 中是否包含和 subRoot 具有相同结构和节点值的子树。如果存在,返回 true ;否则,返回 false 。
二叉树 tree 的一棵子树包括 tree 的某个节点和这个节点的所有后代节点。tree 也可以看做它自身的一棵子树。
解法一:构造节点的hash表,比较subRoot 节点的hash值是否与root所在树的某个节点的hash值一样
- 1、设计hash函数

在这个哈希函数中考虑到每个点的 val、子树哈希值、子树大小以及左右子树的不同权值,所以这些因素共同影响一个点的哈希值,所以出现冲突的几率较小,一般我们可以忽略。
- 2、该hash函数中需要的元素:
- 节点x的hash值
- 节点x对应的子树的大小
- 节点x对应的val
- 第n个素数
- 节点的hash值以及节点对应的子树的大小,都是由其下面的子节点影响的,因此可以采用后序遍历的方法:在遍历的过程中更新两个值。数据结构采用unordered_map
- 求素数:采用“埃氏筛法”。先获取MAX_N以内的所有素数。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
//首先要构造素数表
static constexpr int MAX_N=2000;
bool isPrime[MAX_N];
int prime[MAX_N];
void getPrime(){
isPrime[0]=true;
isPrime[1]= true;
int i=2;
int n=0;
prime[n++]=2;
while(i<MAX_N){
for(int j=1;j<MAX_N/i;j++){
isPrime[i*j]= true;
}
for(i=i+1;i<MAX_N;i++){
if(!isPrime[i]){
prime[n++]=i;
break;
}
}
}
}
//计算每个节点作为根对应的子树的大小以及每个节点的hash值
//pair->first:子树大小;pair->second:节点hash值
unordered_map<TreeNode*,pair<int,int>> subNode1;
unordered_map<TreeNode*,pair<int,int>> subNode2;
static constexpr int MOD = int(1E9) + 7;
void traverse(TreeNode* root,unordered_map<TreeNode*,pair<int,int>> &subNode){
if(root==NULL) return;
subNode[root].first=1;
subNode[root].second=root->val;
if(root->left==NULL && root->right==NULL) return;
if(root->left){
traverse(root->left,subNode);
subNode[root].first+=subNode[root->left].first;
subNode[root].second=(subNode[root].second+(31LL*subNode[root->left].second*prime[subNode[root->left].first])%MOD)%MOD;
}
if(root->right){
traverse(root->right,subNode);
subNode[root].first+=subNode[root->right].first;
subNode[root].second=(subNode[root].second+(79LL*subNode[root->right].second*prime[subNode[root->right].first])%MOD)%MOD;
}
}
bool isSubtree(TreeNode* root, TreeNode* subRoot) {
//深度优先遍历+KMP算法
getPrime();
traverse(root,subNode1);
traverse(subRoot,subNode2);
cout<<subNode2[subRoot].second<<endl;
cout<<subNode2[subRoot].first<<endl;
for(unordered_map<TreeNode*,pair<int,int>>::iterator it=subNode1.begin();it!=subNode1.end();it++){
if(it->second.second==subNode2[subRoot].second) return true;
}
return false;
}
};
解法二:普通做法
如果一个树是另一个树的子树,则进行先序遍历之后,得到的序列结果,应该是一个是另一个的子集。
因此:
- 首先对两棵树分别进行先序遍历,将遍历结果存在List中,注意空孩子节点也要存储
- 然后判断subRoot的先序遍历结果是否是root的先序遍历结果的子集即可
/**
* Definition for a binary tree node.n
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public boolean isSubtree(TreeNode root, TreeNode subRoot) {
//对两棵树进行先序遍历,将结果保存在数组中
//然后看arr1中是否存在arr2子集即可
List<String> arr1=new ArrayList<>();
List<String> arr2=new ArrayList<>();
preorder(root,arr1);
preorder(subRoot,arr2);
//判断arr2是否为arr1的子集
int i=0;
while(i<arr1.size()){
if(!arr1.get(i).equals(arr2.get(0))){
i++;
}else{
int j=1;
for(j=1;j<arr2.size();j++){
if(!arr1.get(i+j).equals(arr2.get(j))){
i++;
break;
}
}
if(j==arr2.size()) return true;
}
}
return false;
}
public void preorder(TreeNode root,List<String> arr){
if(root==null){
arr.add("null");
return;
}
arr.add(root.val+"");
preorder(root.left,arr);
preorder(root.right,arr);
}
}
其他题目
1624. 两个相同字符之间的最长子字符串
给你一个字符串 s,请你返回 两个相同字符之间的最长子字符串的长度 ,计算长度时不含这两个字符。如果不存在这样的子字符串,返回 -1 。
子字符串 是字符串中的一个连续字符序列。
示例:
**输入:**s = “abca” **输出:**2 **解释:**最优的子字符串是 “bc” 。
解题思想:
使用hash table。
对数组进行一次遍历,
- 对于没有遇见过得字母,首先在hash table中保存其下标;
- 如果遇见一个字母其在hash table已经存在了,那么这个时候可以更新maxLen
class Solution {
public:
int maxLengthBetweenEqualCharacters(string s) {
//hashtable方法
int maxlen=-1;
vector<int> hash(26,-1);
for(int i=0;i<s.size();i++){
if(hash[s[i]-'a']==-1){
hash[s[i]-'a']=i;
}
else{
maxlen=max(maxlen,i-hash[s[i]-'a']);
}
}
if(maxlen==-1) return -1;
return maxlen-1;
}
};