数据结构之实现单链表(Java实现)
前言
在之前我们已经对顺序表进行了学习分析总结,可以知道顺序表最大的缺点就是往中间位置插入或删除某个元素需要挪动大量元素,效率不高,所以我们接下来对单链表(不带头单向非循环)进行分析和学习。
目录
1. 单链表定义+图例
2. 单链表基本操作
2.1 创建单链表
2.2 显示链表
2.3 查看单链表中是否含有值为key的结点
2.4 得到链表长度
2.5 头插
2.6 尾插
2.7 在pos位置插入值为key的结点
2.8 删除第一个值为key的结点
2.9 删除所有值为key的结点
2.10 清空单链表
3. 单链表优缺点
1. 单链表定义+图例
● 单链表定义:是一种链式存取的数据结构,用一组地址任意存放线性表中的数据元素。
● 图例:
2. 单链表基本操作
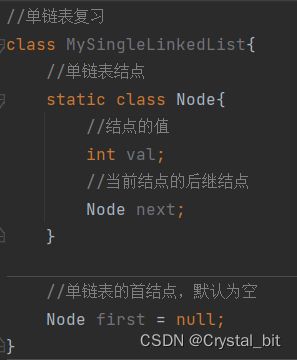
单链表类及属性定义:
2.1 创建单链表
这个逻辑很简单,因为单链表的结点都有next域,所以我们只需要将其的next域赋值到对应的结点,这样就可以把它们这些散乱的结点链接起来了,实现逻辑上的连续。
//创建单链表
public void create(){
//1.首结点的实例化
first = new Node(33);
//2.准备单链表的默认结点
Node node2 = new Node(11);
Node node3 = new Node(55);
Node node4 = new Node(502);
//3.将它们链接起来
first.next = node2;
node2.next = node3;
node3.next = node4;
node4.next = null;
}注:也可以使用循环来创建。
2.2 显示链表
为了防止首结点丢失,我们需要建立游标结点遍历整个单链表,直到游标结点为空,则遍历完毕,在遍历链表过程中输出每个链表结点的值。
//显示单链表
public void display(){
//设置游标结点遍历单链表
Node cur = first;
while(cur != null) {
System.out.print(cur.val+" ");
cur = cur.next; //指向下一个结点
}
}2.3 查看单链表中是否含有值为key的结点
和2.2类似一样遍历单链表,只不过多加了个步骤判断结点值是否等key。
//查看单链表中是否含有值为key的结点
public boolean contains(int key){
//游标结点
Node cur = first;
while(cur != null) {
if(cur.val == key) return true;
cur = cur.next; //指向下一个结点
}
return false;//遍历完整个链表都没返回,则没找到
}2.4 得到链表长度
定义整型变量计数,在遍历链表时,进行链表结点的计数,当链表遍历完毕后直接返回该变量的值。
//得到链表的长度
public int getLength(){
//游标结点
Node cur = first;
//用于计数的变量
int count = 0;
while(cur != null) {
count++;
cur = cur.next; //指向下一个结点
}
return count; //计数完毕,返回count的值
}2.5 头插
这个逻辑会导致首结点不断的变化,也就是将当前新插入的结点作为新的链表首结点,而原本的首结点作为其当前新插入结点的后继结点。如图例:
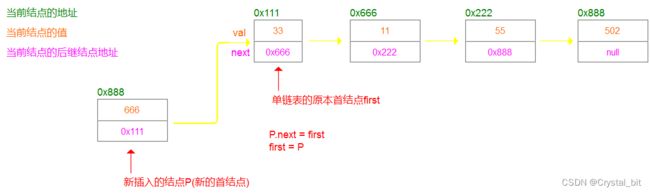
//头插
public void addFirst(Node newNode){
//将新插入结点的next指向原本链表的首结点
newNode.next = first;
//新插入的结点为新的首结点
first = newNode;
}2.6 尾插
首先我们需要找到单链表的最后一个结点,才可以在最后一个结点的后面插入新的结点,所以我们需要通过遍历链表找到单链表的最后一个结点,然后再插入新的结点。又因为单链表的最后一个结点的next域为null,所以我们可以通过在遍历过程中判断游标结点的next域是否为空来确定当前结点是否为当前链表的最后一个结点。如图例:
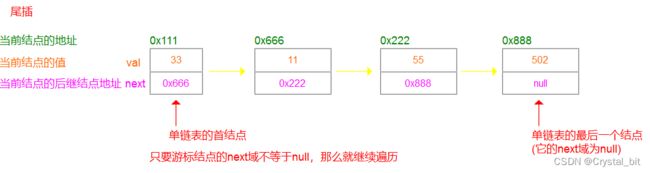
插入逻辑很简单:1.直接将链表的最后一个结点的next域赋值给新的结点就好了
//尾插
public void addLast(Node newNode) {
//如果是空的链表,那么新插入的结点就是链表首结点
if(first == null) {
first = newNode;
return;
}
//遍历找到链表的最后一个结点
Node cur = first;
while(cur.next != null){ //只要游标结点的next域不等于空则继续遍历
cur = cur.next;
}
//插入新的结点
cur.next = newNode;
}2.7 在pos位置插入值为key的结点
因为单链表是单向的,我们往pos(0<=pos<=length)位置插入新的结点,不能直接找到pos位置的结点,这样就找不到pos的前驱结点了,所以最好的方式就是我们找到pos位置的前驱结点,然后在它的前驱结点后插入新的结点,这个逻辑就没什么问题了(就跟尾插也要找到链表的最后一个结点一样)。
如图例:
1).找到pos位置的前一个结点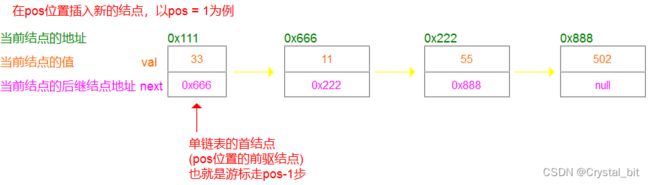
2).插入新的结点
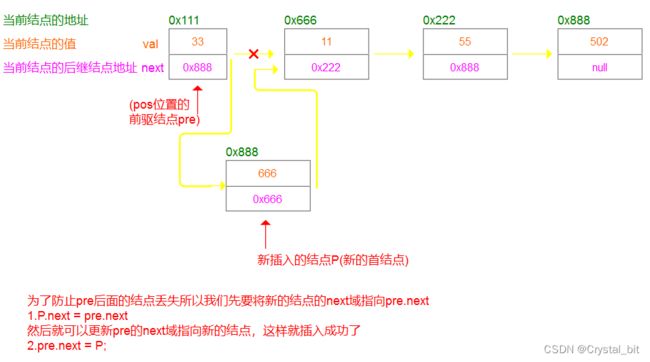
//在pos位置插入值为key的结点
public void addKey(int pos,int key){
//判断位置合法性
if(pos < 0 || pos > getLength()){
System.out.println("插入位置不合法");
return;
}
//链表为空则新插入的结点为首结点
if(first == null){
first = new Node(key);
return;
}
//头插
if(pos == 0) {
addFirst(new Node(key));
return;
}
//找到pos-1的位置
int i = 0;
Node cur = first; //游标结点
while(i != pos - 1){
cur = cur.next;
i++;
}
//插入新结点
Node newNode = new Node(key);
newNode.next = cur.next;
cur.next = newNode;
}2.8 删除第一个值为key的结点
跟2.7类似,我们需要找到结点值为key的结点的前驱元素,才能对该结点进行删除。如图:
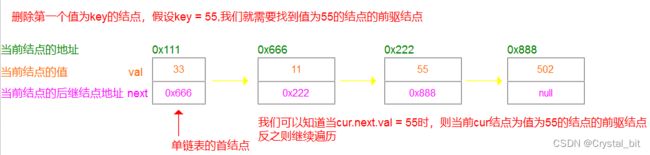
找到之后,我们直接将pre的next指向要删除结点的下一个就能成功删除了

//删除第一个值为key的结点
public void deleteKey(int key){
//链表为空,不进行任何操作
if(first == null){
return;
}
//首结点的值为key则更新首结点
if(first.val == key) {
first = first.next;
return;
}
//找到值为key的结点的前驱结点
Node pre = first;
while(pre.next.val != key){
pre = pre.next;
}
//删除pre的后继结点
pre.next = pre.next.next;
}2.9 删除所有值为key的结点
删除某个结点一定要找到该结点的前驱结点才可以对该结点进行删除操作,而删除什么样的结点呢?值为key的,而且链表中还可能不止一个值为key的结点,这里我们使用前后指针解决这个问题。前指针指向值为key的结点的前驱结点,而后指针用来标识是否某个结点的值为key。如图:
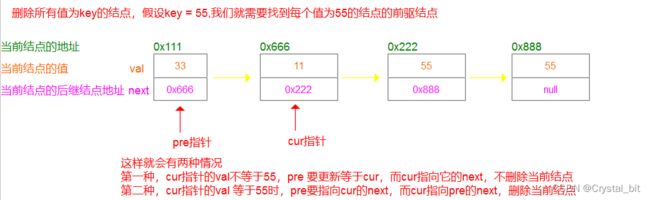
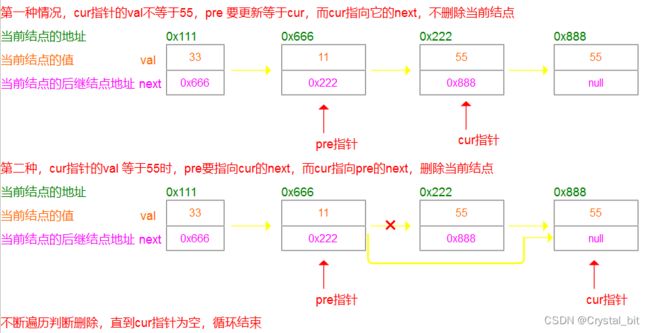
//删除所有值为key的结点
public void deleteKey(int key){
//特殊情况,首结点的值为key的处理情况(这里我们选择处理方式二)
//处理方式一,直接将位于链表前面所有值为key的结点删除,更新头结点
// while(first.val == key) {
// first = first.next;
// }
if(first == null) {
return;
}
Node pre = first;//前指针
Node cur = first.next;//游标
while(cur != null) {
if(cur.val == key) {
//删除当前cur结点
pre.next = cur.next;
cur = pre.next;
}else{
//不删除当前cur结点
pre = cur;
cur = cur.next;
}
}
//处理方式二,在整个链表删除(结点值为key的)完毕后直接将首结点(值为key)更新
if(first.val == key) {
first = first.next;
}
}2.10 清空单链表
Java中不用像C语言需要手动循环free掉动态开辟的结点们,在Java中,我们直接将单链表首结点置空就可以了。
//清空单链表
public void clear(){
first = null;
}3. 单链表优缺点
优点:● 删除和插入元素无需移动其它元素时间复杂度为O(1) (注:不包含查找)
● 无需考虑增容问题
缺点: ● 不支持随机访问
总结完毕~欢迎大家评论区讨论一起学习哦