论文阅读-2022.1.7-Don’t be Contradicted with Anything CI-ToD: Towards Benchmarking Consistency for Task
Title:Don’t be Contradicted with Anything! CI-ToD: Towards Benchmarking Consistency for Task-oriented Dialogue System
题目:不要与任何事物相矛盾!CI-ToD:面向任务的对话系统的基准一致性
Abstract
Consistency Identification has obtained remarkable success on open-domain dialogue, which can be used for preventing inconsis tent response generation. However, in con trast to the rapid development in open-domain dialogue, few efforts have been made to the task-oriented dialogue direction. In this pa per, we argue that consistency problem is more urgent in task-oriented domain. To facilitate the research, we introduce CI-ToD, a novel dataset for Consistency Identification in Task oriented Dialog system. In addition, we not only annotate the single label to enable the model to judge whether the system response is contradictory, but also provide more fine grained labels (i.e., Dialogue History Inconsis tency, User Query Inconsistency and Knowl edge Base Inconsistency) to encourage model to know what inconsistent sources lead to it. Empirical results show that state-of-the-art methods only achieve 51.3%, which is far be hind the human performance of 93.2%, indi cating that there is ample room for improv ing consistency identification ability. Finally, we conduct exhaustive experiments and qual itative analysis to comprehend key challenges and provide guidance for future directions. All datasets and models are publicly available at https://github.com/yizhen20133868/CI-ToD.
一致性识别在开放域对话上取得了显著的成功,可用于防止产生不一致的响应。然而,与开放域对话的快速发展相比,面向任务的对话方向的努力却很少。在本文中,我们认为一致性问题在面向任务的领域中更为紧迫。为了促进研究,我们引入了 CI-ToD,这是一个新的数据集,用于面向任务的对话系统中的一致性识别。此外,我们不仅对单个标签进行标注,使模型能够判断系统响应是否矛盾,还提供了更细粒度的标签(即对话历史不一致、用户查询不一致和知识库不一致)来鼓励模型了解导致它的不一致来源。实证结果表明,最先进的方法仅达到 51.3%,远远落后于人类 93.2% 的表现,表明一致性识别能力有足够的提升空间。最后,我们进行了详尽的实验和定性分析,以理解关键挑战并为未来的方向提供指导。所有数据集和模型均可在以下网址公开获得https://github.com/yizhen20133868/CI-ToD.
1 Introduction
Task-oriented dialogue systems (ToDs) (Young et al., 2013) aim to achieve user goals such as ho[1]tel booking and restaurant reservation, has gained more attention recently in both academia and in[1]dustries. Over the last few years, two promising research directions in ToDs have emerged. The first focuses on a pipeline approach, which consists of modularly connected components (Wu et al., 2019a; Takanobu et al., 2020; Peng et al., 2020; Li et al., 2020). The second direction employs an end-to-end model, which directly takes the sequence-to[1]sequence (Seq2Seq) model to generate a response from a dialogue history and a corresponding knowl[1]edge base (KB) (Eric et al., 2017; Madotto et al., 2018; Wen et al., 2018; Qin et al., 2019b; Wu et al., 2019b; Qin et al., 2020b)
面向任务的对话系统 (ToD)(Young 等人,2013 年)旨在实现酒店预订和餐厅预订等用户目标,最近在学术界和工业界都获得了更多关注。 在过去的几年里,ToDs 出现了两个有前景的研究方向。 第一个侧重于管道方法,它由模块化连接的组件组成(Wu 等人,2019a;Takanobu 等人,2020 年;Peng 等人,2020 年;Li 等人,2020 年)。 第二个方向采用端到端模型,它直接采用序列到序列 (Seq2Seq) 模型从对话历史和相应的知识库 (KB) 生成响应(Eric 等人,2017 年;Madotto 等,2018;Wen 等,2018;Qin 等,2019b;Wu 等,2019b;Qin 等,2020b)
In recent years, with the burst of deep neural networks and the evolution of pre-trained language models, the research of ToDs has obtained great success. While the success is indisputable, previ[1]ous work have shown that it’s inevitable to gen[1]erate inconsistent response with the neural-based model, resulting in a contradiction (Welleck et al., 2019; Song et al., 2020; Nie et al., 2021). Such contradictions caused by these bots are often jar[1]ring, immediately disrupt the conversational flow. To address the above issue, some work try to im[1]prove consistency in dialogue by posing a consis[1]tency identification into dialogue. Welleck et al. (2019) made an early step towards performing con[1]sistency identification in dialogue agent. Nie et al. (2021) proposed dialogue contradiction detection task to prevent the system response from being inconsistent with dialogue history. Song et al. (2020) further proposed a profile consistency identifica[1]tion to consider whether response is consistent with the corresponding profile.
近年来,随着深度神经网络的爆发和预训练语言模型的演进,ToDs的研究取得了巨大的成功。虽然成功是无可争议的,但之前的工作表明,不可避免地会产生与基于神经的模型不一致的响应,从而导致矛盾(Welleck 等,2019;Song 等,2020;Nie 等, 2021)。这种由这些机器人引起的矛盾往往会引起轰动,立即打乱会话流程。为了解决上述问题,一些工作试图通过在对话中提出一致性标识来提高对话的一致性。韦莱克等人。 (2019) 在对话代理中执行一致性识别迈出了早期的一步。聂等人。 (2021) 提出了对话矛盾检测任务,以防止系统响应与对话历史不一致。宋等人。 (2020) 进一步提出了一个配置文件一致性标识来考虑响应是否与相应的配置文件一致。
Though achieving the promising performance, the above work were limited to open-domain dialogue. In this paper, we highlight that inconsistent generation problems should also be considered in task-oriented dialogue. For example, as shown in Figure 1, the system ex presses about the POI whole foods in dialogue his tory. However, when we run the state-of-the-art model (DF-Net) (Qin et al., 2020b), the system generate response “mandarin roots is located at 271 springer street.”, which incorrectly generates irrelevant POI mandarin roots, resulting in contra diction. This is because neural-based models are a black-box and thus make us hard to explicitly con trol the neural-based dialogue systems to maintain a consistent response generation. From the user’s perspective, such inconsistent bots not only fail to meet the requirements of the user but also mislead users to get wrong feedback in the task-oriented domain. Therefore, it’s promising to consider con sistency problem and detect in advance whether the generated response is consistent in task-oriented di alogue direction. Unfortunately, there still has been relatively little research on considering consistency identification in task-oriented dialogue due to the the lacking of public benchmarks.
尽管取得了有希望的表现,但上述工作仅限于开放域对话。在本文中,我们强调在面向任务的对话中也应该考虑不一致的生成问题。例如,如图 1 所示,系统在对话历史中表达关于 POI 全食的信息。然而,当我们运行最先进的模型 (DF-Net) (Qin et al., 2020b) 时,系统会生成响应“mandarin root is located at 271 springer street.”,它错误地生成了不相关的 POI mandarin根源,导致矛盾。这是因为基于神经的模型是一个黑匣子,因此我们很难明确控制基于神经的对话系统以保持一致的响应生成。从用户的角度来看,这种不一致的机器人不仅不能满足用户的要求,而且会误导用户在面向任务的领域中得到错误的反馈。因此,考虑一致性问题并提前检测生成的响应在面向任务的对话方向上是否一致是很有希望的。不幸的是,由于缺乏公共基准,在面向任务的对话中考虑一致性识别的研究仍然相对较少。

表 1:我们的数据集和其他数据集之间的比较。 HI 表示对话历史不一致; QI表示用户查询不一致; KBI 代表知识库不一致。
Fine-grained Labels:细粒度标签
To fill this research gap, we introduce a novel human-annotated dataset CI-ToD: Consistency Identification in Task-oriented Dialog system. Di alogue data for CI-ToD is collected from the public dialogue corpora KVRET (Eric et al., 2017). For each final system response in KVRET, we re-write the utterance by crowdsourcing where we delib erately contradict the dialogue history, user query or the corresponding knowledge base (KB). As shown in Table 1, compared to the existing consis tency identification for dialogue dataset, CI-ToD has the following characteristic: (1) Task-oriented Dialogue Domain. To the best of our knowledge, we are the first to consider dialog consistency in task-oriented dialogue system while the prior work mainly focuses on the open domain dialogue sys tem. We hope CI-ToD can fill the gap of consis tency identification in the task-oriented dialogue domain; (2) Fine-grained Annotations. We provide not only single annotations of whether each sen tence is consistent, but also more fine-grained annotations, which can be used for helping the model analyze what source is causing this inconsistency.
为了填补这一研究空白,我们引入了一个新的人工注释数据集 CI-ToD:面向任务的对话系统中的一致性识别。 CI-ToD 的对话数据是从公共对话语料库 KVRET 中收集的(Eric 等,2017)。对于 KVRET 中的每个最终系统响应,我们通过众包重写话语,我们故意与对话历史、用户查询或相应的知识库 (KB) 相矛盾。如表 1 所示,与现有的对话数据集一致性识别相比,CI-ToD 具有以下特点: (1) 面向任务的对话域。据我们所知,我们是第一个在面向任务的对话系统中考虑对话一致性的,而先前的工作主要集中在开放域对话系统上。我们希望 CI-ToD 能够填补面向任务对话领域一致性识别的空白; (2) 细粒度注解。我们不仅提供每个句子是否一致的单一注释,还提供更细粒度的注释,可用于帮助模型分析导致这种不一致的来源。
To establish baseline performances on CI-ToD, we evaluate the state-of-the-art pre-trained and non pre-trained models for consistency identification. Experimental results demonstrate a significant gap between machine and human performance, indicat[1]ing there is ample room for improving consistency identification ability. In addition, we show that our best consistency identification detector correlates well with human judgements, demonstrating that it can be suitable for use as an automatic metric for checking task-oriented dialogue consistency. Finally, we perform exhaustive experiments and qualitative analysis to shed light on the challenges that current approaches faced with CI-ToD.
为了在 CI-ToD 上建立基线性能,我们评估了最先进的预训练和非预训练模型以进行一致性识别。 实验结果表明机器和人的表现之间存在显着差距,表明一致性识别能力有足够的提升空间。 此外,我们展示了我们最好的一致性识别检测器与人类判断的相关性很好,证明它可以适合用作检查面向任务的对话一致性的自动度量。 最后,我们进行了详尽的实验和定性分析,以阐明当前方法在 CI-ToD 中面临的挑战。
In summary, our contributions are three-fold:
• We make the first attempt to consider consis tency identification in task-oriented dialog and introduce a novel human-annotated dataset CI ToD to facilitate the research.
• We establish various baselines for future work and show well-trained consistency identifica tion model can be served as an automatic met ric for checking dialogue consistency.
• We conduct exhaustive experiments and qual itative analysis to comprehend key challenges and provide guidance for future CI-ToD work.
总之,我们的贡献有三方面:
• 我们首次尝试在面向任务的对话中考虑一致性识别,并引入了新的人工注释数据集 CI ToD 以促进研究。
• 我们为未来的工作建立了各种基线,并表明训练有素的一致性识别模型可以作为检查对话一致性的自动指标。
• 我们进行详尽的实验和定性分析以理解关键挑战并为未来的 CI-ToD 工作提供指导。
2 Problem Formulation
In our paper, the consistency identification in task oriented dialogue is formulated as a supervised multi-label classification task, which aims to judge whether the generated system response is inconsis tent. To equip the model with the ability to ana lyze what the inconsistent sources lead to it, we require the model not only provide the final pre diction but also the fine-grained sources including dialogue history, knowledge base (KB) and user’s uery. More specifically, given a task-oriented di alogue between a user (u) and a system (s), the n-turned dialogue snippet consists of dialogue his tory H = {(u1, s1),(u2, s2), ...,(un−1, sn−1)}, the corresponding knowledge base KB, the user query un and system response sn. More specifically, the task can be defined as:
在我们的论文中,面向任务的对话中的一致性识别被制定为一个有监督的多标签分类任务,其目的是判断生成的系统响应是否不一致。 为了使模型能够分析不一致的来源导致的结果,我们要求模型不仅提供最终预测,而且还提供细粒度的来源,包括对话历史、知识库 (KB) 和用户的 query。 更具体地说,给定用户 (u) 和系统 (s) 之间面向任务的对话,n 轮对话片段由对话历史 H = {(u1, s1),(u2, s2), ... ..,(un-1, sn-1)}组成。对应的知识库KB,用户查询un和系统响应sn。 更具体地说,任务可以定义为:

其中 f 表示可训练模型; y 是一个输出的三维向量,表示最后一个话语 sn 是否与任何先前提到的对话历史 H、用户查询 un 或相应的知识库 KB 相矛盾。
3 Dataset
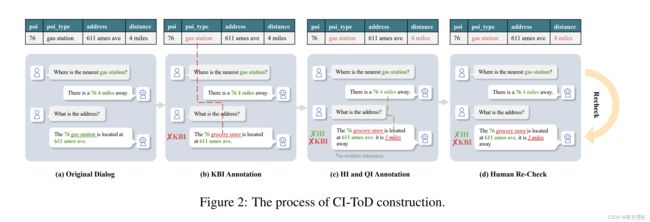
We construct the CI-ToD dataset based on the KVRET dataset and follow four steps: (a) Data Pre-Processing, (b) KBI Construction, (c) QI and HI Construction and (d) Human Annotation, which is illustrated in Figure 2. In the following, we first describe the definition of QI, HI and KBI, then illustrate the four construction steps in detail.
我们基于 KVRET 数据集构建 CI-ToD 数据集并遵循四个步骤:
(a)数据预处理,
(b)KBI 构建,
(c)QI 和 HI 构建
(d)人工注释,如图所示 2. 下面我们先对QI、HI和KBI的定义进行说明,然后详细说明四个构建步骤。
3.1 不一致类型
如图 3 所示,我们举一个例子来展示不同的不一致类型,说明如下:
用户查询不一致(QI) QI 表示对话系统响应与当前用户查询不一致。 以图 3 中的对话为例,在最后一轮对话中,用户的查询是询问 valero,而最终的系统响应不满足用户的要求,显示了到 willows_market 的路由,导致用户查询不一致。
对话历史不一致(HI) HI表示对话系统响应与除了当前用户查询之外的对话历史不一致。 以图 3 中的对话为例,之前的系统响应是在谈论 valero 并且用户没有改变对话的主题。 然而,最终系统响应转向讨论 willows_market ,导致对话历史不一致。
知识库不一致(KBI) KBI 表示对话系统响应与相应的 KB 不一致,这是面向任务的对话领域的独特挑战。 以图3中的对话为例,最终系统响应表示willows_market的traffic_info为heavy_traffic,与对应的KB冲突(no_traffic for willows_market)
3.2 数据收集与统计
3.2.1 第一步数据预处理
我们在现有对话 KVRET 上构建 CI-ToD,而不是从头开始收集新对话更具体地说,给定 n 轮对话 {(u1, s1),(u2, s2), ...,(un, sn), KB} 对于 KVRET,我们首先将其拆分为一些子对话以生成各种样本,例如 {(u1, s1), KB}, . . . , {(u1, s1),(u2, s2), ...,(un−1, sn−1), KB} 和 {(u1, s1),(u2, s2), ...,(un , sn), KB}。 此外,为确保系统响应信息丰富,我们过滤了这些一般响应,例如“谢谢”和“不客气”。 最后,我们获得了预处理的对话。
3.2.2 Step 2 KBI 标注
给定预处理的对话,我们首先为每个对话构建 KBI。 KBI 表示最终系统响应与对应的 KB 不一致。 我们简单地替换知识实体值来自动构建KBI。 更具体地说,对于系统响应中的每个知识值,我们从整个 KB 中采样特定实体以替换所选槽,并确保采样的 KB 实体与所选值不同。 通过这种方式,构造的响应与相应的 KB 不一致。 例如,如图 2(b) 所示,我们将实体“gas station”替换为“grocery store”,得到 KBI(对应的 KB 为 (poi_type for gas station))。
3.2.3 步骤 3 QI 和 HI 注释
在本节中,我们将展示如何生成 QI 和 HI。 由于这需要我们对相应用户的查询和对话历史有深入的了解,因此构造一个带有 QI 或 HI 的系统响应并非易事,为了解决这个问题,我们通过人工来实现。 我们聘请了一个人工注释团队 1 来 (1) 随机分配一个具有 QI 或 HI 的样本,并重写每个响应以使其与用户查询或对话历史不一致,以及 (2) 检查每个书面响应是否流利通过三个额外的注释器。
3.2.4 第四步人工复查
在最后一步,我们将通过人工重新检查细粒度的不一致信息,包括 QI、HI 和 KBI。 为保证质量,每个样品由三个人注释,注释过程持续近三个月。 图 4 显示了注释用户界面。 CI-ToD 的详细统计数据总结在表 2 中。不一致的百分比已超过 50%,表明 CI-ToD 具有挑战性。
3.2.5 质量控制
为了控制注释数据集的质量,我们引入了不同的验证方法:
(1)入职测试:每个标注者都会有一个提前标注测试,每个标注者先标注100个样本,3位专家检查标注结果。 最后,只有达到 80% 标注性能的人才能进行以下标注工作; (2) 双重检查 我们从最终标注的数据集中随机抽取 1000 个样本,并要求两个新的标注者标注不一致的信息。 继 (Bowman et al., 2015) 之后,我们计算了之前标签和两个新标签之间的 Fleiss’ Kappa,得到了 0.812 的 kappa,这意味着几乎完全一致(Landis 和 Koch,1977)。
4 模型
在本节中,我们使用最先进的非预训练模型(§4.1)和预训练模型(§4.2)建立了几个强大的基线方法。 由于多任务框架在各种 NLP 任务上取得了显着的成功(Fan et al., 2021; Qin et al., 2019a, 2020a; Liang et al., 2020; Xu et al., 2021; Qin et al., 2021),我们采用vanilla多任务框架同时执行 QI、HI 和 KBI,其优点是跨三个任务提取共享知识。
对于预训练模型和非预训练模型,我们分别引入分隔符标记 [SOK]、[USR] 和 [SYS] 来表示 KB 的开始、用户话语和系统响应,旨在学会区分 知识库、用户和系统行为在多轮对话中的作用。 具体来说,KB 的输入表示为 KB^ = "[SOK] KB [EOK]",而 H 的输入定义为 H^ = "[USR] u1 [SYS] s1 ... [USR] un"。
4.1 非预训练模型
在这种方法中,我们简单地将对话历史中的所有先前话语和相应的 KB 连接起来形成一个单一的文本上下文,如图 5 所示。对于 KB 表示,我们将每个知识实体格式化为 “列名,单元格值”对而不是“主题,关系,对象”三元组以节省长度空间。 ToDs 的 KB 表示实际上是我们挑战部分中提到的一个重要问题。 然后,我们将 fnon 作为非预训练模型来获得最终的预测,定义为:


在我们的工作中,我们探索了一些最先进的非预训练模型,包括:ESIM (Chen et al., 2017)、InferSent (Conneau et al., 2017) 和 RE2 (Yang et al., 2019)
4.2 预训练模型
我们研究了几种最先进的基于 BERT 和 BART 的模型,如图 5 所示。给定对话 {(u1, s1), . . . ,(un, sn), KB},对于基于 BERT 的模型,在 (Chen et al., 2020) 之后,输入可以表示为 ([CLS], KB^ , H^ , [SEP], sn, [SEP] ),其中 [CLS] 和 [SEP] 是分类记号和分隔记号的特殊符号。 在预训练模型编码后,使用 [CLS] token 中最后一层的隐藏表示 hCLS 进行分类,可以定义为:
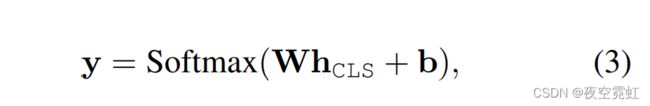
其中 W 和 b 是可训练的参数。
更具体地说,我们探索了 BERT (Devlin et al., 2019)、RoBERTa (Liu et al., 2019)、XLNet (Yang et al., 2020)、Longformer (Beltagy et al., 2020) 和 BART (Lewis et al., ., 2020)
4.3 训练目标
训练目标是二元交叉熵损失,定义为:

其中 yi 是 0 到 1 之间的预测分数,而 y^i 是第 i 个不一致类型的黄金标签。
5.7 Challenges
基于以上分析,我们总结了当前一致性检测任务面临的挑战:
知识库表示。 对应的知识库是关系型数据库,它具有原始知识图谱中呈现的高阶结构信息。 如何对关系知识库中的结构信息进行建模而不是简单地扁平化知识库是一个有趣的研究问题。 此外,由于 KB 的大小相对较大,如何有效地建模相关的 KB 信息而不是注入噪声是另一个需要探索的挑战。
有效的上下文建模。 由于某些对话具有极长的历史,并非所有的上下文信息都对最终表现产生积极影响。 如何有效地对远程对话历史进行建模并过滤无关信息是一个有趣的研究课题。
共指消解。 对话中存在多个共指消解,这将导致用户查询的歧义,使模型难以正确预测一致性标签。 因此,如何明确地进行共指消解以帮助一致性检测是一个重要的研究问题。
显式联合学习。 尽管基于多任务训练范式取得了可喜的性能,但先前的工作并没有“明确”地对不同任务(HI、QI 和 KBI 任务)之间的关系进行建模; 相反,它采用共享参数来“隐式”建模相关性。 然而,仅仅依靠一组共享参数并不能进行充分的交互以达到理想的结果(Qin et al., 2019a, 2020a)。 因此,如何明确地建模HI、QI和KBI之间的相关性来直接控制信息流仍然值得探索。
6 Related Work
这项工作与考虑开放域对话的一致性有关。 近年来,已经引入了一些个性化对话数据集,例如 PersonaChat (Zhang et al., 2018) 和 PersonalDialog (Zheng et al., 2020)。 这些数据集能够隐含地考虑对话生成的一致性,但无法明确地教模型判断生成的系统响应是否一致。
另一系列相关工作明确地提高了对话的一致性。为此,已经提出了一些基准来促进这项研究。韦莱克等人。 (2019)在将对话一致性识别减少到自然语言推理(NLI)方面迈出了第一步。 Dziri 等人。 (2019) 提出了一种新的范式,用于通过使用最先进的蕴涵技术来评估对话系统的连贯性,并构建了一个用于评估对话系统一致性的合成数据集 InferConvAI。聂等。 (2021)引入了对话冲突检测任务(DECODE)和一个包含矛盾对话的新对话数据集,旨在评估检测矛盾的能力。宋等人。 (2020)提出了开放域对话代理的KvPI数据集和配置文件一致性识别任务,以进一步评估系统响应是否与相应的配置文件信息不一致。与他们主要关注开放域对话方向的工作相比,我们的目标是填补面向任务的对话系统中一致性识别的空白。此外,我们为此引入了人工注释的数据集。此外,我们提供了一些关键挑战和未来方向,以促进进一步的研究。
7 结论
我们研究了面向任务的对话中的一致性识别,并引入了一个新的人工注释数据集 CI-ToD。 此外,我们通过广泛的实验分析了 CI-ToD 的问题,并强调了该任务的关键挑战。 我们希望 CI-ToD 能够促进未来在面向任务的对话中进行一致性识别的研究。