高可用设计简述-SinoDB
1.概述
星瑞格云数据库的高可用为实例级高可用,每个实例创建时会部署一些高可用节点,用于数据库各个节点的检测和故障处理,高可用节点的数量可以在instmgr服务的配置文件中进行配置。高可用服务依赖Zookeeper组件,用于记录高可用组件运行期间产生的元信息,如数据库节点的判决状态,每个高可用进程连续HaCheckCount(在配置文件中配置,默认为3)次检测到同一个状态(如节点不可用N),会将该状态写入Zookeeper,如果有超过半数的高可用进程认为一个数据库节点不可用(N),那么这些高可用进程会争抢处理的锁,抢到锁的高可用进程会调用instmgr服务,发起新建数据库节点、主备切换等请求,进行高可用的故障处理,最多处理HaHandleMaxCount(最大处理次数,默认为3)次,如果处理HaHandleMaxCount次依然没有成功,则触发消息告警。高可用服务的一些重要参数都是可配置的,如每轮检测间隔、状态确认次数(连续n次检测到一个状态,才将该状态标记到Zookeeper)、最大处理次数等。
2. 设计方案
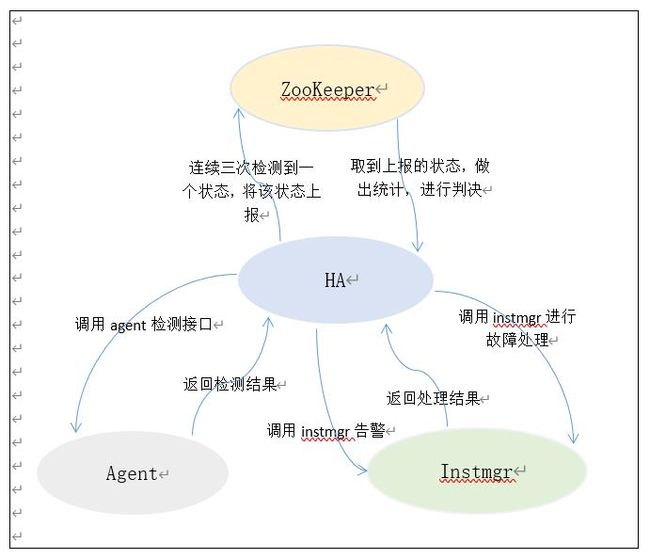
如上图所示,每个实例创建成功后,instmgr服务会往Zookeepr写入一份该实例的拓扑信息,HA服务会从Zookeeper中取到拓扑信息同步到自己的内存中,并遍历拓扑中存储的节点进行检测和故障处理。HA服务首先会调用Agent接口进行检测,如果连续三次检测到同一个状态,那么就将该状态上报至Zookeeper。另外还会有一个协程从Zookeeper中取到所有HA服务上报的信息进行统计和判决,即超过一半的HA服务认为某一个节点故障,则认为该节点故障。如果判定了某一个节点故障就会调用instmgr进行故障处理,如果多次处理后仍未成功,则会调用instmgr的告警接口,进行告警。此外,还有高可用集群健康状态的监控在上图没有体现,即还会有一个单独的协程监听各个实例在Zookeeper上创建的代表自身服务是否存活的临时节点是否存在,以及存活的节点数量,以确定高可用集群的健康状态,从而进行相应的告警。

上图是高可用思路简图,instmgr服务创建实例时会创建出高可用节点,并将该实例的拓扑信息写入Zookeeper,如果一个实例的拓扑信息发生变化,instmgr会将该实例变化后的拓扑信息更新至Zookeeper。每个高可用节点有四个协程c1、c2、c3、c4;下面具体介绍每个协程的作用。
c1协程:
c1负责监听Zookeeper中存储的拓扑信息,如果拓扑信息发生变化则同步到高可用进程的内存中;
c2协程:
c2会遍历内存中的拓扑信息,对拓扑中的每一个数据库节点调用agent提供的接口进行检测,如果连续HaCheckCount(在配置文件中配置,默认为3)次检测到同一个状态,就将这个状态写入Zookeeper,并且c2协程每一次上报状态后,会判断该次上报的状态与上一次上报的状态是否一致,如果不一致会主动执行一次c3的逻辑;
c3协程:
c3遍历内存中存储的拓扑信息,对拓扑中的每一个数据库节点,都要从Zookeeper上取到所有高可用进程对该节点标记的状态,如果有超过半数的高可用进程认为一个数据库节点故障,则所有的高可用进程都会去争抢处理故障的锁,抢到锁的高可用进程会调用instmgr服务,发起新建数据库节点、主备切换等请求,进行高可用的故障处理,如果多次处理仍然失败,则会触发相应的告警;
c4协程:
c4负责监控Ha集群的健康状态,既监听各个Ha服务在Zookeeper上创建的临时节点是否存在以及存活数量等,如果健康状态异常会触发告警。
2.1.1 proxy检测
1.Ha服务调用agent接口进行检测。
2.查看proxy端口是否存在(netstat命令)。
3.如果端口存在则正常,否则异常。
4.如果连续三次检测到同一个状态,则将该状态上报至Zookeeper。
2.1.2 proxy故障处理
1.Ha服务调用instmgr服务进行故障处理。
2.新建一个proxy。
3.销毁旧的proxy。
4.如果新建HaMaxHandleCount次失败,会触发告警。
2.2.1 主节点检测
1.Ha服务调用agent接口进行检测。
2.查看主节点的端口是否存在。
3.连接数据库节点。
4.插入一条数据。
5.更新这条数据。
6.查询该条数据。
7.删除该条数据。
8.上述步骤都正常,则返回正常状态,否则返回异常状态。
9.如果连续三次检测到同一个状态,则将该状态上报至Zookeeper。
2.2.2 主节点故障处理
1.根据该实例配置的业务高可用或者数据高可用进行选主。
2.数据高可用时超过十分钟未选出主,会触发告警。
3.Ha服务调用instmgr服务进行故障处理。
4.instmgr调用agent接口进行主备切换。
2.3.1 只读节点检测
1.Ha服务调用agent接口进行检测。
2.查看只读节点的端口是否存在,如果异常,直接标记N。
3.连接数据库节点,如果异常,直接标记N。
4.检测复制状态Slave_IO_Running和Slave_SQL_Running,都是YES,复制状态OK,跳转步骤7。
5.Slave_IO_Running = Connecting && Slave_SQL_Running = Yes,主库故障,备库复制正常,直接标记n。
6.其他,复制状态异常,检测不通过,直接标记N。
7.检测复制延迟Seconds_Behind_Master,如果当前状态为Y,Seconds_Behind_Master > 最大允许复制延迟,标记n,否则,标记Y;如果当前状态为n,Seconds_Behind_Master < 最小允许复制延迟,则返回Y,否则,标记n。
8.如果连续三次检测到同一个状态,则将该状态上报至Zookeeper。
2.3.2 只读节点故障处理
如果统计的判决结果是n:
1.Ha服务调用instmgr服务进行故障处理。
2.将该只读节点在数据库的状态标记为不可用。
3.更新拓扑,将该只读节点隔离。
如果统计的判决结果是N:
1.Ha服务调用instmgr服务进行故障处理。
2.新建只读节点。
3.销毁旧的只读节点。
4.如果新建HaMaxHandleCount次失败,会触发告警。
如果统计的判决结果是Y:
1.查看拓扑中该节点的状态是否是abnormal。
2.如果是abnormal,调用instmgr将该节点恢复。
2.4.1 高可用节点检测
1.一个高可用进程启动时会在Zookeeper上创建一个代表自己进程的临时节点,如果该高可用进程挂掉,则Zookeeper会删掉相应的临时节点。
2.每一个Ha服务都会有一个单独的协程监听Zookeeper上代表该高可用进程的临时节点是否存在。
3.如果连续三次检测到同一个状态,则将该状态上报至Zookeeper。
2.4.2 高可用节点故障处理
1.Ha服务调用instmgr服务进行故障处理。
2.新建高可用节点。
3.销毁旧的高可用节点。
4.如果新建HaMaxHandleCount次失败,会触发告警。
3. Zookeeper目录说明
- upcloud
|- instmgr
|- ha
|- ab4vm3i6nwao # 实例 id
|- topology_info # 存放实例拓扑信息
|- ha_health # ha 健康信息
|- notify_time # 上次告警时间
|- notify_count # 告警次数
|- ha_nodes # 子节点代表Ha进程的临时节点
|- ab4vm3jklv7o # 临时节点ha_node_id,代表一个ha进程
|- shardings # 分片信息
|- ab4vm3jfm2ip # 分片id
|- notify_time # 上次告警时间
|- notify_count # 告警次数
|- ab4vm3jfm2iq # 节点id
|- handle_count # 故障处理次数
|- err_msg # 错误信息
|- notify_time #上次告警时间
|- notify_count # 告警次数
|- status
|- ab4vm3jklv7o # ha_node_id,存放值:(Y/N/n),见说明
说明:
节点的状态有Y(代表节点状态良好),N(代表节点故障),对于只读节点还会有一个n(节点存活,但复制延迟较高)的状态。所有的高可用进程都会将自己对于每一个节点的检测状态写入Zookeeper,以供高可用服务统计一个节点的状态,最终结果采用多数派原则,即超过半数的高可用进程认为一个节点故障,则认为该节点故障。
4. 关于高可用的重要配置说明
4.1 hadrmgr 服务重要配置说明
checkDuration:每轮检测间隔,默认5秒。
decideDuration: 每轮故障处理间隔,默认10秒。
haCheckout:一个连续检测多少次,就将该状态标记至Zookeeper,默认3次。
haHandleCount:最大处理次数,默认3次。
haFailNotifyCount: Ha处理失败后的最大消息通知次数,小于0代表无限次,默认为 -1
haFailNotifyDuration:Ha处理失败后的消息通知间隔,单位:分,默认为 5
electMasterMaxSecond:数据高可用的最大选主时间,超过该时间会触发告警,单位:秒
4.2 inst-mgr 服务重要配置说明
haCount:高可用节点数量,默认3个。
zkLockTimeout:zookeeper 锁超时时间,超时会自动释放锁。
haHandleCount:最大处理次数,默认3次。
5. 可能遇到的问题
1.新建proxy失败
高可用进程新建三次proxy仍然失败,会触发消息通知的告警,告知管理人员故障的实例和节点,管理人员可以登录运营端点击删除按钮删除掉有问题的节点后,点击新建按钮进行新建。
2.新建只读节点失败
高可用进程新建三次只读节点仍然失败,会触发消息通知的告警,告知管理人员故障的实例和节点,管理人员可以登录运营端点击删除按钮删除掉有问题的节点后,点击新建按钮进行新建。
3.新建高可用节点失败
高可用进程新建三次高可用节点仍然失败,会触发消息通知的告警,告知管理人员故障的实例和节点,管理人员可以登录运营端点击删除按钮删除掉有问题的节点后,点击新建按钮进行新建。
4.主备切换时,原主降为备,先备份原主再销毁
主备切换成功(switch_log表有一条记录);原主降为备该备触发高可用(克隆只读节点),流程为新创建新的只读节点,判断出问题的节点是否为“原主降为备节点”是进行备份,再删除该节点,否则不进行备份直接删除节点。