python爬虫(进阶)
目录:
一、MongoDB
1.mongodb介绍
(1)什么是mongodb
(2)SQL和NO-SQL的主要区别
(3)MongoDB作为非关系型数据库相较于关系型数据库的优点:
(3)mongodb安装
2.mongodb的使用
(1)简单使用
(2)mongodb的增删改查
(3)mongodb的聚合操作
(4)mongodb-索引
3. mongodb的权限管理
(1)mongodb的权限管理方案
(2)mongodb-超级管理员账号
(3)mongodb-普通用户
(4)查看创建的用户与删除用户
4. mongodb与python的交互
(1)mongodb和python的交互模块
(2)使用pymongo
二、scrapy-爬虫框架
1.学前应知:
(1) scrap的概念和流程:
(2) scrapy的三个内置对象:
(3)scrapy中的模块的具体作用:
(4)安装与项目开发流程介绍:
2. 项目流程(重点!!!)
(1)创建项目:以pycharm为例
(2)创建爬虫
(3)完善爬取
(4)保存数据
(5)爬虫运行:
(6)数据建模:
(7)翻页请求的思路:
3. 请求对象:
(1)构造requests对象,并发送请求
(2)scrapy.Requests的更多的参数
4. scrapy模拟登录
(1)回顾之前的模拟登陆的方法
(3)案例--网易招聘爬虫:
5. scrapy.Requests发送post请求:
6. scrapy管道的使用:
(1)pipeline中常用的方法:
(2)管道文件的修改:
(3)开启管道:
7.另外一种爬虫类--crawlspider
(1)创建crawlspider 爬虫
8. scrapy中间件的使用:
(1)scrapy中间件的分类和使用:
(2)下载中间件的使用方法:
(3)定义实现随机User-Agent的下载中间件---豆瓣实例
(4)代理ip的使用:
(5)动态加载selenium:
前言:
爬虫(基础):python爬虫(基础)_qwerdftgu的博客-CSDN博客
一、MongoDB
官方文档:https://docs.mongodb.com/
1.mongodb介绍
(1)什么是mongodb
- mongodb是一个功能最丰富的NoSQL非关系数据库。由C++语言编写。
- mongodb本身提供S端存储数据,即server;也提供C端操作处理〈如查询等)数据,即client。
(2)SQL和NO-SQL的主要区别
- 据库>集合>文档
数据的无关联性:
- SQL中如果需要增加外部关联的话,规范化做法是在原表中增加一个外键,关联外部数据表。
- NoSQL则可以把外部数据直接放到原数据集中,以提高查询效率。缺点也比较明显,对关联数据做更新时会比较麻烦。
- SQL中在一个表中的每条数据的字段是固定的。而NoSQL中的一个集合(表)中的每条文档(数据)的key(字段)可以是互不相同的。
(3)MongoDB作为非关系型数据库相较于关系型数据库的优点:
- 易扩展:NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展
- 大数据量,高性能:NoSQL数据库都具有非常高的读写性能,尤其在大数据量下表现优秀。这得益于它的非关系性,数据库的结构简单
- 灵活的数据模型:NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库中,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个梦
(3)mongodb安装
安装:如何在 Ubuntu 上安装 MongoDB - wefeng - 博客园
2.mongodb的使用
(1)简单使用
1. 服务端的启动:
- 默认端口号:27017
- 默认配置文件的位置:/etc/mongodb.conf
- 默认日志的位置:/var/log/mongodb/mongodb.log
两种方式启动:
本地测试方式的启动(只具有本地数据的增删改查的功能)
验证数据库能否正常运行
生成方式启动(具有完整的全部功能)
部署启动2. mongodb数据库的命令:
- 查看当前的数据库:db(没有切换数据库的情况下默认使用test数据库)。查看所有的数据库:how dbs /show databases
- 切换数据库:use db_name
db_name为show dbs后返回的数据库名- 删除当前的数据库:db.dropDatabase()
3. mongodb集合的命令:
- 无需手动创建集合:向不存在的集合中第一次添加数据时,集合会自动被创建出来
- 手动创建集合:
db.createCollection(name,options)
db.createCollection("stu"")
db.createCollection("sub", { capped : true,size : 10})
参数capped:默认值为false表示不设置上限,值为true表示设置上限
参数size︰集合所占用的字节数。当capped值为true时,需要指定此参数,表示上限大 小,当文档达到上限时,会将之前的数据覆盖,单位为字节- 查看集合:show collections
- 蒯除集合:db.集合名称.drop0
- 检查集合是否设定上限: db.集合名.isCapped0
- 测试代码:
show dbsuse test show collections db db.stu.insert(i " name ' :"郭靖','age ':22}) show dbs show collections db.stu.find() db.stu.drop() show collections db.dropDatabase() show dbs exit4. mongodb中常见的数据类型:
- 常见类型:
Object ID: 文档ID/数据的ID,数据的主键(默认为索引)
String: 字符串,最常用,必须是有效的UTF-8
Boolean: 存储一个布尔值,true或false(小写)
Integer: 整数可以是32位或64位,这取决于服务器
Double: 浮点数
Arrays: 数组/列表
Object: mongodb中的一条数据/文档,即文档嵌套文档
Null: 存储null值
Timestamp: 时间戳,表示从1970-1-1到现在的总秒数
Date:存储当前日期或时间的UNIX时间格式- 注意点:
- 每个文档都有一个属性,为_id,保证每个文档的唯一性,mongodb默认使用_id作为主键
可以手动设置_id的值,如果没有提供,那么MongoDB为每个文档提供了一个 独特的_id,类型为objectlD- objectID是一个12字节的十六进制数,每个字节两位,一共是24位的字符串:
。前4个字节为当前时间戳
。接下来3个字节的机器ID
。接下来的2个字节中MongoDB的服务进程id。最后3个字节是简单的增量值
(2)mongodb的增删改查
1. mongodb插入数据:
- 命令:db.集合名称.insert(document)
db.stu.insert((name : ' gj ', gender:1))
db.stu.insert({_id:"201701e1",name :" gj' , gender:1})
- 插文档时,如果不指定_id参数,MongoDB会为文档自动分配一个唯一的Objectld
2.mongodb的保存
- 命令:db.集合名称.save(document)
db.stu.save({_id: '20170101', name : ' gj', gender:2})
db.stu.save({name : 'gi‘ , gender:2})
db.stu.find()
- 如果文档的_id已经存在则修改,如果_id不存在则添加(插入)
3.mongodb的查询
3.1 简单查询
- 方法find():查询
db.集合名称.find({条件文档})- 方法findOne():查询,只返回第一个
db.集合名称.find0ne({条件文档})- 方法pretty0:将结果格式化;不能和findOne()一起使用! 美化!!!!
db.集合名称.find({条件文档}).pretty()
3.2 比较运算符
- 等于:默认是等于判断,没有运算符。
- 小于: $lt (less than)
- 小于等于:$lte(less than equal)。
- 大于: $gt(greater than)
- 大于等于: $gte
- 不等于: $ne
查询年龄大于18的所有学生
db.stu.find({age:{$gte: 18}})
3.3 逻辑运算符:逻辑运算符主要指与、或逻辑.
- and:在json中写多个条件即可
查询年龄大于或等于18,并且性别为true的学生
db.stu.find({age :{$gte:18},gender:true})
- or:使用$or,值为数组,数组中每个元素为json
查询年龄大于18,或性别为false的学生
db.stu.find({$or:[iage:{$gt:18}}, {gender:false)]})
查询年龄大于18或性别为男生,并且姓名是郭靖
db.stu.find({$or:[{age:{$gte:18}},{gender:true}], name : 'gj'})
3.4 范围运算符
- 使用$in , $nin判断数据是否在某个数组内
查询年龄为18、28的学生
db.stu.find({age:{$in: [18,28]}})
3.5 使用正则表达式
- 使用$regex编写正则表达式
查询name以'黄'开头的数据
db.stu.find({name:{$regex:"^黄"}})
3.6 自定义查询:
mongodb shell 是一个js的执行环境 使用$where 写一个函数,返回满足条件的数据
查询年龄大于30的学生
db.stu.find( {
$where:function() {
return this.age>30;}
})
3.7 skip和limit(查询结果的操作)
- 方法limit():用于读取指定数量的文档
db.集合名称.find( ).limit(NUMBER)
查询2条学生信息
db.stu.find().limit(2)
- 方法skip0:用于跳过指定数量的文档
db.集合名称.find( ).skip(NUMBER)
db.stu.find().skip(2)
- 同时使用-------> 可以实现翻页操作
db.stu.find().limit(4).skip(0) # 四条数据
db.stu.find().skip(4).limit(4) # 接着四条数据
3.8 投影
在查询到的返回结果中,只选择必要的字段
命令: db.集合名称.find({}, {字段名称:1,---})
参数为字段与值,值为1表示显示,值为0不显 特别注意∶
- 对于_id列默认是显示的,如果不显示需要明确设置为0
- 对于其他不显示的字段不能设置为0
db. stu.find({}, {_id :0, name: 1, gender: 1})
3.9 排序
方法sort(),用于对查询结果按照指定的字段进行排序
- 命令: db.集合名称.find().sort({字段:1,...})
参数1为升序排列,参数-1为降序排列
根据性别降序,再根据年龄升序(复合排序)
db.stu.find().sort({gender : -1, age:1})
3.10 统计个数(和去重)
方法count)用于统计结果集中文档条数
- 命令: db.集合名称.find({条件}).count()
- 命令: db.集合名称.count({条件})
db.stu.find({gender:true}).count()
db. stu.count({age:{$gt:20}, gender:true})
- 命令: db.集合名称.distinct(字段,{查询条件})
db.stu.distinct("hometown") # 对整个数据去重
db.stu.distinct("hometown", {age:18}) # 对查询结果去重!!()
4. mongodb的更新
db.集合名称.update({query}, {update}, {multi: boolean})
- 参数query:查询条件
- 参数update:更新操作符
- 参数multi:可选,默认是false,表示只更新找到的第一条数据,值为true表示把满足条件的数据全部更新
db.stu.update({name : 'hr'}, {name: 'mnc'}) # 全文档进行覆盖更新
此时该条数据只有一个内容即:{name: "mnc"}, 还有id
db.stu.update({name : 'hr' }, {$set:{name: 'hys'}) # 指定键值更新操作
db.stu.update({}, {$set:{gender:0}}, {multi: true}) # 该数据库中的数据全部更新
db.stu.update({name: "qdd"}, {$set: {age: 18}, {upsert: true}} # 找到则该,没有就插入
注意: "multi update only works with $ operators"
- multi参数必须和$set一起使用!!
5. mongodb的删除
db.集合名称.remove({query}, {justOne: boolean})
-参数query:可选,删除的文档的条件
-参数justone:可选,如果设为true或1,则只删除一条,默认false,表示删除全部小结
- mongo shell中的增:
db.集合名.insert({数据})
db.集合名.save({包含_id的完整数据})#根据指定的_id进行保存,存在则更新,不存在 则插入- mongo shell中的删:
db.集合名.remove({条件}, {justOne: true/false})- mongo shell中的改:
db.集合名.update({条件}, {$set:{完整数据/部分字段}}, {multi: true/false})- mongo shell中的查:
db.集合名.find({条件}, {字段投影})
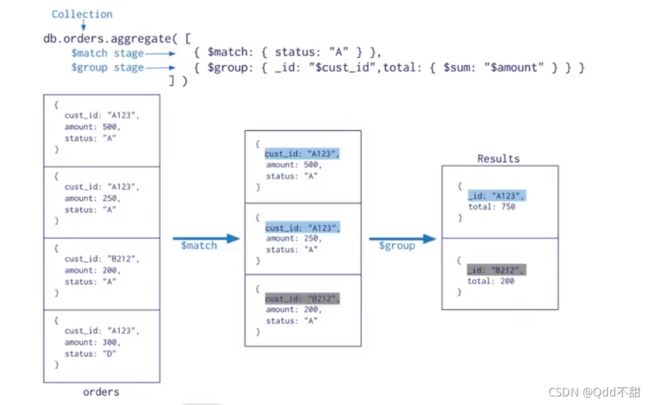
(3)mongodb的聚合操作
1. mongodb的聚合是什么
聚合(aggregate)是基于数据处理的聚合管道,每个文档通过一个由多个阶段(stage)组 成的管道,可以对每个阶段的管道进行分组、过滤等功能,然后经过一系列的处理, 输出相应的结果。
语法: db.集合名称.aggregate({管道:{表达式}})
2. mongodb的常用管道和表达式
2.1 常用的管道命令
在mongodb中,文档处理完毕后,通过管道进行下一次处理常用管道命令如下
- $group: 将集合中的文档分组,可用于统计结果(!!!!!!!最重要)
- $match: 过滤数据,只输出符合条件的文档
- $project: 修改输入文档的结构,如重命名、增加、删除字段、创建计算结果
- $sort: 将输入文档排序后输出
- $linit: 限制聚合管道返回的文档数
- $skip: 跳过指定数量的文档,并返回余下的文档
2.2 常用表达式
表达式:处理输文档并输出语法:表达式:"$列名·常用表达式:
- $sun : 计算总和, $sum:1表示以一倍计数(可以用于数据计数)
- $avg : 计算平均值
- $min : 获取最小值
- $max︰获取最大值
- $push : 在结果文档中插入值到一个数组中
3 管道命令之 $group !!!!!!!!!!!!!!!!!!!!非常重要
3.1 按照某个字段进行分组
$group是所有聚合命令中用的最多的一个命令,用来将集合中的文档分组,可用于统计结果使用示例如下
db.stu.aggregate( {$group: { # $gender表示取含有gender字段的数据 _id:"$gender", # 这个_id表示的不是分组之前的键,而是分组结果中的键 counter:{$sum: 1} } } )其中注意点;
- db.db_name. aggregate 是语法,所有的管道命令都需要写在其中
- _id表示分组的依据,按照哪个字段进行分组,需要使用$gender表示选择这个字段进行分组
- $sum:1 表示把每条数据作为1进行统计,统计的是该分组下面数据的条数
3.2 group by null
当我们需要统计整个文档的时候,$group的另一种用途就是把整个文档分为一组进行统 计使用实例如下:db. stu.aEgregate( {$group: { _id:null, counter:{$sum: l} # counter不是固定的,是你自己可以随便取得 } } )其中注意点; 一条数据又称为文档
- _id: null 表示不指定分组的字段,即统计整个文档,此时获取的 counter表示整个文档的个数
3.3 数据透视
正常情况在统计的不同性别的数据的时候,需要知道所有的name,需要逐条观察,如 果通过某种方式把所有的name放到一起,那么此时就可以理解为数据透视
使用示例如下;
- .统计不同性别的学生
db.stu.aggregate( {$group: { id:null, name:{$push:"$name"} # push 放 } } )- 使用$$ROOT可以将整个文档放入数组中
db.stu.aggregate( {$group: { _id:null, name:{$push: "$$ROOT"} } } )4. 其它管道命令
4.1 $match
$match用于进行数据的过滤,是在能够在聚合操作中使用的命令,和 find 区别在于 smatch操作可以把结果交给下一个管道处理,而find不行
使用示例如下:
- 查询年龄大于20的学生
db.stu.aggregate( {$match:{age:{$gt:20}} )
- 查询年龄大于20的男女学生的人数
db.stu.aggregate( {$match:{age:{$gt:20}), {$group:{_id:"$gender", counter:{$sum:1}}} )4.2 $projiect ----->类似投影
$project用于修改文档的输入输出结构,例如重命名,增加,删除字段
使用示例如下:
- 查询学生的年龄、姓名,仅输出年龄姓名
db.stu.aggregate( {$project: {_id: 0, name:1, age:1}} )
- 查询男女生人生,输出人数
db.stu.aggregate( {$project: {_id:"$gender", counter:{$sum:1}}}, {$project: {_id:0, counter:1} )4.3 $limit和$skip
- $limit限制返回数据的条数
- $skip跳过指定的文档数,并返回剩下的文档数
- 同时使用时先使用skip在使用limit
使用示例如下:
- 查询2条学生信息
db.stu.aggregate( {$limit:2} )
- 查询从第三条开始的学生信息
db.stu.aggregate( {$skip:3} )
- 统计男女生人数,按照人数升序,返回第二条数据
db.stu.aggregate( {$group:{_id: "$gender", counter:{$sum:1}}}, {$sort:{counter: -1}}, {$skip:1}, {$limit:1} )
(4)mongodb-索引
1. 创建mongodb索引的作用:
- 加快查询数据
- 进行数据去重
2. 创建简单的索引方法
- 语法:db.集合名.ensureIndex({属性: 1}},1表示升序, -1表示降序
3. 创建索引前后查询速度对比:
插入数据:
for(i=0; i<100000; i++){ db.stu.insert( {name: 'text' + i, num:i} ) }创建索引前:
db.stu.find({name:'text10000'}).explian('exectionStats') # 显示查询操作的详细信息创建索引:
db.stu.ensureIndex({name:1})创建索引后:
db.stu.find({name:'test10000'}).explain('exectionStats')前后速度对比:
4. 索引的查看
默认情况下_id是集合的索引查看方式: db.集合名.getIndexes()
5. 删除索引
- db.集合名.dropIndex({索引名称:1})
- db.集合名.dropIndex()
6. 创建唯一索引
在默认情况下mongdb的索引域的值是可以相同的,创建唯一索引之后,数据库会在插入数据的时候检查创建索引域的值是否存在,如果存在则不会插入该条数据,但是创建索引仅仅能够提高查询速度,同时降低数据库的插入速度。
6.1 添加唯一索引的语法:
- db.集合名.ensureIndex({'字段名': 1}, {'unique': true)
利用唯一索引去重:根据唯一索引指定的值,如果相同,则无法插入该数据
7 建立复合索引在进行数据去重的时候,可能用一个域来保证数据的唯一性,这个时候可以考虑建立复合索引来实现。例如︰抓全贴吧信息,如果把帖子的名字作为唯一索引对数据进行去重是不可取的,因为可能有很多帖子名字相同
建立复合索引的语法:
- db.collection_name.ensureIndex({字段1:1, 字段2:1})
8. 建立索引注意点:
- 根据需要选择是否需要建立唯一索引
- 索引字段是升序还是降序在单个索引的情况下不影响查询效率,但是带复合索引的条件下会有影响
- 数据量巨大并且数据库的读出操作非常频繁的时候才需要创建索引,如果写入操作非常频繁,创建索引会影响写入速度
例如:在进行查询的时候如果字段1需要升序的方式排序输出,字段2需要降序的方式排序输出,那么此时复合索引的建立需要把字段1设置为1,字段2设置为-1

3. mongodb的权限管理
刚安装完毕的mondodb默认不使用权限认证方式启动,与MySQL不同,mongodb在安装的时候并没有设置权限,然而公网运行系统需要设置权限以保证数据安全,所以我们要学习mongodb的权限管理
(1)mongodb的权限管理方案
MongoDB是没有默认管理员账号,所以要先添加管理员账号,并且mongodb服务器需要在运行的时候开启验证模式
- 用户只能在用户所在数据库登录(创建用户的数据库),包括管理员账号。
- 管理员可以管理所有数据库,但是不能直接管理其他数据库,要先认证后才可以。
(2)mongodb-超级管理员账号
1. 创建超级用户
进入mongo shell
- sudo mongodb
使用admin数据库(超级管理员账号必须创建在该数据库上)
- use admin
创建超级用户
- db.createUser({"user": "python", "pwd": "xxxx", "roles": ["root"]})
创建成功后会显示如下信息:
- Successfully added user: { "user": "python", "roles" : ["root"] }
2. 以权限认证的方式启动mongodb数据库
- sudo mongod --auth
此时再使用数据库各命令的时候会报权限错误,需要认证才能执行相应操作
(3)mongodb-普通用户
1. 在使用的数据库上创建普通用户
选择数据库
- use test1
创建用户:
# 创建普通用户user1,该用户在test1上的权限是只读 db.createUser("user" :"user1","pwd" : "pwd1", roles:["read"]) # 创建普通用户user1,该用户在test1上的权限是读写 db.createUser("user" : "user1", "pwd" : "pwd1",roles : ["readWrite"])2. 在admin用户数据库上创建普通用户
- use admin
- db.createUser("user" :"user2","pwd" : "pwd2", roles:[{"role": "read", "db": "dbname1"}, {"role": "readWrite", "db": "dbname2"}])
在admin上创建python1用户,python1用户的权限有两个,一个再dbname1上的只读,另一个是在dbname2上的读写
(4)查看创建的用户与删除用户
1. 查看用户
- show users
2. 删除用户:前提是在超级用户状态下
- db.dropUser("python")
4. mongodb与python的交互
(1)mongodb和python的交互模块
- pymongo 安装方式 pip install pymongo
(2)使用pymongo
1. 无需权限认证的方式创建连接对象以及集合操作对象
from pymongo import MongoClient # 创建数据库链接对象 client = MongoClient('192.168.50.129', 27017) # 如果是本地连接host,port参数可以省略 # 选择一个数据库 collection = client['python_data'] # 选择一个集合 collection = collection['python_col']2. 需要权限认证的方式创建连接对象以及集合操作对象
from pymongo import MongoClient from urllib.parse import quote_plus user = 'python' password = '123456' host = '192.168.50.129' port = 27017 url = "mongodb://%s:%s@%s"%(quote_plus(user), quote_plus(password), host) # quote_plus函数,对url进行编码 # url = mongodb://python_data:[email protected] client = MongoClient(url, port=port) collection = client.db.python_data.python_col # ----------------------------------另外一种 client = MongoClient('192.168.50.129', 27017) db = client['admin'] db.authenticate('用户', '密码') # 账号密码 col = client['python_data']['python_col'] # 前一个为数据库,后一个为集合
3. insert()添加数据insert可以批量的插入数据列表,也可以插入一台哦数据
3.1 添加一条数据
返回插入数据的idret = collection.insert({"name": "test10000", "age": 21}) print(ret)3.2 添加多条数据
返回Object对象构成的列表item_list = [{"name": "test1001{}".format(i)} for i in range(10)] rets = collection.insert(item_list) print(rets) for ret in rets: print(ret)4. find_one()查找一条数据
接收一个字典形式的条件,返回字典形式的整条数据如果条件为空,则返回第一条ret = collection.find_one({"name" : "test10011"}) print(ret) #包含mongodb的ObjectId对象的字典 _ = ret.pop('_id') #清除mongodb的objectd对象的k , v print(ret)5. find()查看全部数据
返回所有满足条件的结果,如果条件为空,则返回全部结果是一个Cursor游标对象,是一个可迭代对象,可以类似读文件的指针,但是只能够进行一次读取
rets = collection.find({"name": "test10005"}) for ret in rets: print(ret) for ret in rets: #此时rets中没有 print(ret)6. updata()更新数据(全文档覆盖或指定键值,更新一条或多条)
- 语法: collection.update({条件}, {"$set":{指定的kv或完整的一条数据}}, multi=False/True,upsert=False/True
- multi参数:默认为False,表示更新一条; multi=True则更新多条; multi参数必须和$set一起使用
- upsert参数:默认为False; upsert=True则先查询是否存在,存在则更新;不存在就插入
- $set表示指定字段进行更新
6.1 更新一条数据;全文档覆盖;存在就更新,不存在就插入
data = ( "msg":"这是一条完整的数据1" , "name":'哈哈'} collection.update({"haha" : "heihei"},{"$set": data},upsert=True)6.2 更新多条数据;全文档覆盖;存在就更新,不存在就插入
data = { "msg" : "这是一条完整的数据2" , "name" :'哈哈'} #该完整数据是先查询后获取的collection.update({}, {'$set':data}, multi=True, upsert=True)6.3 更新一条数据;指定键值;存在就更新,不存在就插入
data = {"msg":"指定只更新msg___1"} collection.update({},{"$set" :data}, upsert=True)6.4更新多条数据;指定键值;存在就更新,不存在就插入入
data = {"msg":"指定只更新msg_2"} collection.update({}, {"$set" :data}, multi=True,upsert=True)7. delete_one()删除一条数据
- collection.delete_one({ "name" : "test10001"})
7.1 delete_many()删除全部数据
- collection.delete_many({"name": "test10810"})
8 pymongo模块其他api
- 查看pymongo官方文档或源代码 http://api.mongodb.com/python/current/
二、scrapy-爬虫框架
scrapy官方文档:
- 中文版:Scrapy 2.5 documentation — Scrapy 2.5.0 文档 (osgeo.cn)
- 源文档:Scrapy 2.5 documentation — Scrapy 2.5.0 documentation
1.学前应知:
(1) scrap的概念和流程:
1. 概念:
Scrapy是一个python编写的开源网络爬虫框架,它是一个被设计用于爬取网络数据,提取结构性数据的框架-----> 少量的代码就能够快速的抓取
2. 工作流程
其流程描述如下:
- 爬虫中起始的url构造成request对象-->爬虫中间件-->引擎-->调度器
- 调度器把request-->引擎-->下载中间件--->下载器
- 下载器发送请求,获取response响应---->下载中间件---->引擎--->爬虫中间件--->爬虫
- 爬虫提取url地址,组装成request对象---->爬虫中间件--->引擎--->调度器,重复步骤2
- 爬虫提取数据--->引擎--->管道处理和保存数据

(2) scrapy的三个内置对象:
- requests请求对象:由url、method、post_data、headers等构成
- response响应对象:由url、body、status、headers等构成
- item数据对象:本质是一个字典
(3)scrapy中的模块的具体作用:

- 爬虫中间件和下载中间件只是运行逻辑的位置不同,作用是重复的:如替换UA等
(4)安装与项目开发流程介绍:
1. 安装:
- pip/pip3 install scrapy
2. 开发流程:
1. 创建项目:
- scrapy startproject mySpider
2. 生成一个爬虫:
- scrapy genspider itcast itcast.cn
3. 提取数据:
- 根据网站结构在spider中实现数据采集相关内容
4. 保存数据:
- 使用pipeline进行后续处理和保存
2. 项目流程(重点!!!)
(1)创建项目:以pycharm为例
创建scrapy项目的命令:在pycharm底部的终端中输入该命令
- scrapy startproject <项目名字> ---->eg: scrapy startprojet myspider
创建成功有:

(2)创建爬虫
通过命令创建出爬虫文件,爬虫文件为主要的代码作业文件,通常一个网站的爬取动作都会在爬虫文件中进行编写。
命令:---->在项目路径下执行:、
- scrapy genspider <爬虫的名字> <允许爬取的域名>
爬虫的名字:作为爬虫运行时的参数
允许爬取的域名: 为对于爬虫设置的爬取范围,设置之后用于过滤要爬取的url,如果爬取的url与允许的域不通则被过滤掉。
eg:
- cd myspider # 要转到项目目录下才行
- scrapy genspider w3school www.w3school.com.cn
结果如下:
运行爬虫:
- scrapy crawl w3school -->终端上

(3)完善爬取
1. 爬取传智播客的老师
import scrapy class ItcastSpider(scrapy.Spider): name = 'itcast' # 2.检查域名 allowed_domains = ['itcast.cn'] # 1.通常需要更改一下初始url start_urls = ['http://www.itcast.cn/channel/teacher.shtml#ajavaee'] # 3.在parse方法中实现爬取逻辑 def parse(self, response): # 获取所有教师节点 node_list = response.xpath('/html/body/div[14]/div/div[2]/div/div[2]/div[1]/ul/li/div') # 遍历所有教师节点 for node in node_list: temp = {} # xpath方法返回的是列表, extract()用于从选择器对象中提取数据 temp['name'] = node.xpath('./h3/text()').extract_first() temp['title'] = node.xpath('./h4/text()')[0].extract() temp['data'] = node.xpath('./p/text()')[0].extract() print(temp) # xpath的结果为列表,我们需要第一个值,我倾向于用extract_first(),为啥嘞: # 因为如果列表为空,那么用这个方法可以避免报错!! yield temp # 这里不用return,虽然可以创建一个空列表放数据,但是一旦return后,函数就终止了, # 如果我们还有操作,这就得不偿失!! pass注意:
- scrapy.Spider爬虫类中必须有名为parse的解析
- 如果网站结构层次比较复杂,也可以自定义其他解析函数
- 在解析函数中提取的url地址如果要发送请求,则必须属于allowed_domains范围内,但是start_urls中的url地址不受这个限制,在后续将学习如何在解析函数中构造发送请求
- 启动爬虫的时候注意启动的位置,是在项目路径下启动
- parse()函数中使用yield返回数据,注意︰解析函数中的yield能够传递的对象只能是: Baseltem,Request, dict, None
2. 定位元素以及提取数据、属性值的方法
解析并获取scrapy爬虫中的数据:利用xpath规则字符串进行定位和提取
- response.xpath方法的返回结果是一个类似list的类型,其中包含的是selector对象,操作和列表一样但是有一些额外的方法
- 额外方法extract():返回一个包有字符串的列表
- 额外方法extract_first()︰返回列表中的第一个字符串,列表为空没有返回None
3. response响应对象的常用属性!!!!!!!
- response.url: 当前响应的url地址
- response.request.url: 当前响应对应的请求的url地址
- response.headers: 响应头
- response.requests.headers: 当前响应的请求头
- response.body: 响应体,也就是html代码,byte类型
- response.status: 响应状态码
(4)保存数据
利用管道pipeline来处理(保存)数据
1. 在pipeline.py文件中定义对数据的操作
1.定义一个管道类
2.重写管道类的process_item方法
3. process_item方法处理完item之后必须返回给引擎import json class MyspiderPipeline(): #爬虫文件中提取数据的方法每yield一次item,就会运行一次 #该方法为固定名称函数 def process_item(self, item, spider): print(item) return item2. 在setting.py配置启用管道----->在65行左右!!
ITEM_PIPELINES = { 'myspider.pipelines.MyspiderPipeline': 300, }配置项中键为使用的管道类,管道类使用.进行分割,第一个为项目目录,第二个为文件,第三个为定义的管道类。
配置项中值为管道(可以有多个管道)的使用顺序,设置的数值约小越优先执行,该值一般设置为1000以内。
(5)爬虫运行:
我们运行爬虫项目,都是在终端中进行的:注意要在项目目录下进行!!!!
- scrapy crawl itcast --nolog # 加上--nolog就会剔除掉日志信息,但是不会报错误信息
(6)数据建模:
通常在itens.py中进行数据建模
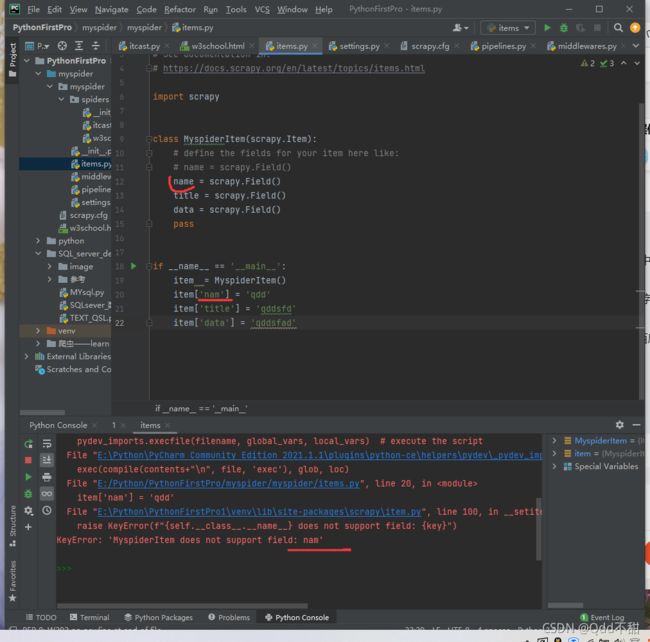
1. 为什么建模:
- 定义item即提前规划好哪些字段需要抓,防止手误,因为定义好之后,在运行过程中,系统会自动检查
- 配合注释一起可以清晰的知道要抓取哪些字段,没有定义的字段不能抓取,在目标字段少的时候可以使用字典代替
- 使用scrapy的一些特定组件需要ltem做支持,如scrapy的ImagesPipeline管道类,百度搜索了解更多
2. 如何使用建模:
就运行该文件!!!!
这就是 检错!!!!!会提示你,字段写错了
注意:
- 在进行建模后,item是对象,对象,对象!!!!!
3. 如何使用建模:
模板类定义以后需要在爬虫中导入并且实例化,之后的使用方法和使用字典相同job.py:
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html # useful for handling different item types with a single interface import json from itemadapter import ItemAdapter from myspider.items import MyspiderItem # 导入Item,注意路径!!! # 在导入之前,要将第一个myspider设置为source root!!! class MyspiderPipeline: def __init__(self): self.file = open('itast.json', 'w') def process_item(self, item, spider): # 将itcast对象强转为dict!!!! item = dict(item) # 将字典数据序列化, ensure_ascii=False-->中文 json_data = json.dumps(item, ensure_ascii=False) + '\n' # 将数据写入文件 self.file.write(json_data) # 默认使用完管道后将数据返回给引擎! return item def __del__(self): self.file.close() # 记得要关闭文件!!!!!注意;
- from myspider.items import Myepiderltem这一行代码中注意item的正确导入路径,忽略pycharm标记的错误
- python中的导入路径要诀: 从哪里开始运行,就从哪里开始导入
4. 开发流程总结
- 创建项目
scrapy startproject 项目名- 明确目标
在items.py文件中进行建模- 创建爬虫
3.1创建爬虫: scrapy genspider 爬虫名 允许的域
3.2完成爬虫:
修改start_urls
检查修改allowed_domains
编写解析方法- 保存数锯
在pipelines.py文件中定义对数据处理的管
在settings.py文件中注册启用管道
(7)翻页请求的思路:
要提取如下图的所有页面上的数据该怎么办

回顾requests模块是如何实现翻页请求的:
- 找到下一页的URL地址
- 调用requests.get(url)
scrapy 实现翻页的思路:
- 找到下一页的url地址
- 构造url地址的请求对象,并传递给引擎
3. 请求对象:
(1)构造requests对象,并发送请求
- 确定url
- 构造请求,scrapy.Request(url, callback)
callback: 指定解析函数名称,表示该请求返回的响应使用哪一个函数进行解析 - 把请求交给引擎:
yield scrapy.Requsets(url, callback)
(2)scrapy.Requests的更多的参数
- scrapy.Requests(url[, callback, mdthod='GET', headers, body, cookies, meta, dont_filter=False])
参数解释:
- 中括号里的参数为可选参数
- callback: 表示当前的url的响应交给哪个函数去处理
- meta: 实现数据在不同的解析函数中传递,meta默认带有部分数据,比如下载延迟,请求深度等(用于解析方法之间的数据传递,常用在一条数据分散在多个不同结构的页面中的情况)
- dont_filter: 默认为False,会过滤请求的url地址,即请求过的url地址不会继续被请求,对需要重复请求的url地址可以把它设置为Ture,比如贴吧的翻页请求,页面的数据总是在变化;start_urls中的地址会被反复请求,否则程序不会启动
- method: 指定POST或GET请求
- headers: 接收—个字典,其中不包括cookies
- cookies:接收一个字典,专门故置cookies
- body: 接收json字符串,为POST的数据,发送payload_post请求时使用
补:meta参数的使用
meta的作用: meta可以实现数据在不同的解析函数中的传递
在爬虫文件的parse方法中,提取详情页增加之前callback指定的parse_detail函数:
def parse(self,response):
...
yield scrapy.Request(detail_url,callback=self.parse_detail,meta=("item" :item})
...
def parse_detail(self, response) :
#获取之前传入的item
item = response.meta["item"]import scrapy
from wanyi.items import WanyiItem
import re
class JobSpider(scrapy.Spider):
name = 'job'
allowed_domains = ['163.com']
start_urls = ['https://hr.163.com/position/list.do']
# cookis参数的使用,重写start_requests函数,这个函数在scrapy.Spider中
def start_requests(self):
url = self.start_urls[0]
temp = '_ntes_nnid=1abfbc77f799fbae9d902316cb752b4c,1615031424593; _ntes_nuid=1abfbc77f799fbae9d902316cb752b4c; HR163=13fb983d6110c01684acb73a808b3af70c018ae2; NTEShrSI=08713F9EF4A912F8DC491B54678DDE9E.hzabj-new-rms3.server.163.org-8011; mp_versions_hubble_jsSDK=DATracker.globals.1.6.12.9; userName=; accountType='
cookies = {data.split('=')[0]: data.split('=')[-1] for data in temp.split('; ')}
# print('--------------', cookies)
yield scrapy.Request(
url=url,
callback=self.parse,
cookies=cookies
)
# 在parse中实现爬取逻辑
def parse(self, response):
# 获取所有职业节点
node_list = response.xpath('//*[@class="position-tb"]/tbody/tr')
# with open('wanyi.html', 'wb') as f:
# f.write(response.body)
# 遍历所有职业节点,这里要间隔着运行,display:none属性的tr是详细内容
for node in node_list[0::2]:
item = WanyiItem()
item['title'] = node.xpath('./td[1]/a/text()').extract_first()
item['department'] = node.xpath('./td[2]/text()').extract_first()
item['category'] = node.xpath('./td[3]/text()').extract_first()
item['type'] = node.xpath('./td[4]/text()').extract_first()
item['address'] = node.xpath('./td[5]/text()').extract_first()
item['num'] = node.xpath('./td[6]/text()').extract_first().strip()
item['time'] = node.xpath('./td[7]/text()').extract_first()
item['link'] = 'https://hr.163.com/' + node.xpath('./td[1]/a/@href').extract_first()
# 构建详情页请求
yield scrapy.Request(
url=item['link'],
callback=self.parse_datail,
meta={'item': item}
)
# 翻页
# href="?currentPage=254"(有下一页时) ; javascript:void(0)(终止时)
# 其实在这里,我们只需要更改curentPage的值就是对应多少页的url
pre_url = response.xpath('/html/body/div[2]/div[2]/div[2]/div/a[9]/@href').extract_first()
# 判断是否终止:
if pre_url != 'javascript:void(0)':
next_url = response.urljoin(pre_url)
# 返回引擎:
yield scrapy.Request(
url=next_url,
callback=self.parse
)
def parse_datail(self, response):
item = response.meta['item']
# 这里用正则表达式剔除所有非中文的字符!!!!
describe = str(response.xpath('/html/body/div[2]/div[2]/div[1]/div/div/'
'div[2]/div[1]/div').extract())
require = str(response.xpath('/html/body/div[2]/div[2]/div[1]/div/div/'
'div[2]/div[2]/div').extract())
describe = re.sub('''[A-Za-z\<\>\[\]\=\-\'\"]''', '', describe).strip()
require = re.sub('''[A-Za-z\<\>\[\]\=\-\'\"]''', '', require).strip()
# 这里该补充的值补充完整!然后返回给引擎!
item['describe'] = describe
item['require'] = require
yield item
特别注意:
- meta参数是一个字典
- meta字典中有一个固定的键proxy ,表示代理ip,关于代理ip的使用将在scrapy的下载中间件的学习中进行介绍
4. scrapy模拟登录
(1)回顾之前的模拟登陆的方法
1.1 requests模块是如何实现模拟登陆的?
- 直接携带cookies请求页面
- 找url地址,发送post请求存储cookie
1.2 selenium是如何模拟登陆的?
- 找到对应的input标签,输入文本点击登陆
1.3 scrapy的模拟登陆
- 直接携带cookies
- 找url地址,发送post请求存储cookie
(2)scrapy携带cookies直接获取需要登陆后的页面
应用场景:
- cookie过期时间很长,常见于一些不规范的网站
- 能在cookie过期之前把所有的数据拿到
- 配合其他程序使用,比如其使用selenium把登陆之后的cookie获取到保存到本地,scrapy发送请求之前先读取本地cookie
实现:重构scrapy的starte_rquests方法:
- scrapy中start_url是通过start_requests来进行处理的,其实现代码如下
# cookis参数的使用,重写start_requests函数,这个函数在scrapy.Spider中
def start_requests(self):
url = self.start_urls[0]
temp = '_ntes_nnid=1abfbc77f799fbae9d902316cb752b4c,1615031424593; _ntes_nuid=1abfbc77f799fbae9d902316cb752b4c; HR163=13fb983d6110c01684acb73a808b3af70c018ae2; NTEShrSI=08713F9EF4A912F8DC491B54678DDE9E.hzabj-new-rms3.server.163.org-8011; mp_versions_hubble_jsSDK=DATracker.globals.1.6.12.9; userName=; accountType='
cookies = {data.split('=')[0]: data.split('=')[-1] for data in temp.split('; ')}
# print('--------------', cookies)
yield scrapy.Request(
url=url,
callback=self.parse,
cookies=cookies
)注意:
- scrapy中cookie不能够放在headers中,在构造请求的时候有专门的cookies参数,能够接受字典形式的coookle
- 在setting中设置ROBOTS协议、USER_AGENT
(3)案例--网易招聘爬虫:
地址:https://hr.163.com/position/list.do
方法5. scrapy.Requests发送post请求:
- 可以通过scrapy.Request()指定method、body参数来发送post请求;但是通常使用scrapy.FormRequest()来发送post请求
1. 发送post请求
- 注意:scrapy.FormRequest0)能够发送表单和ajax请求,
- 参考阅读: https://www.jb51.net/article/146769.htm
2. 思路分析
- 找到post的url地址:点击登录按钮进行抓包,然后定位url地址为https://github.com/session
- 找到请求体的规律:分析post请求的请求体,其中包含的参数均在前一次的响应中
- 否登录成功:通过请求个人主页,观察是否包含用户名
3. 代码实现如下:
import scrapy class Git1Spider(scrapy.Spider): name = 'git1' allowed_domains = ['github.com'] start_urls = ['http://github.com/login'] def parse(self, response): # 从登录页面中解析出post表单数据, token = response.xpath('//*[@id="login"]/div[4]/form/input[1]/@value').extract_first() timestamp = response.xpath('//*[@id="login"]/div[4]/form/div/input[10]/@value') .extract_first() timestamp_secret = response.xpath('//*[@id="login"]/div[4]/form/div/input[11]/@value').extract_first() post_data = { 'commit': 'Sign in', 'authenticity_token': token, 'login': 用户名, 'password': 密码, 'trusted_device': '', 'webauthn-support': 'supported', 'webauthn-iuvpaa-support': 'unsupported', 'return_to': 'https://github.com/login', 'allow_signup': '', 'client_id': '', 'integration': '', 'required_field_be94': '', 'timestamp': timestamp, 'timestamp_secret': timestamp_secret } print(post_data) # 针对登录url发生post请求 yield scrapy.FormRequest( url='https://github.com/session', callback=self.after_login, formdata=post_data ) # 我们虽然post提交成功了,但是它并不会直接将GitHub登录后的页面发给我们,所以我们还要发送一个get请求 def after_login(self, response): yield scrapy.Request( url='https://github.com/exile-morganna', callback=self.check ) # 此时我们才登录完成,我们打印一下title验证是否登录成功!!! def check(self, response): # 正确输出应该是exile-morganna print(response.xpath('/html/head/title/text()').extract_first())
6. scrapy管道的使用:
(1)pipeline中常用的方法:
- process_item(self, item,spide,:
管道类中必须有的函数。
实现对item数据的处理。
必须return item - open_spider(self,spider):在爬虫开启的时候仅执行一次
- close_spider(self, spider):在爬虫关闭的时候仅执行一次
(2)管道文件的修改:
完善wanyi爬虫,代码如下:
这里是在wanyi项目基础上再创建一个job_simple爬虫

代码:
job.py:
import scrapy from wanyi.items import WanyiItem import re class JobSpider(scrapy.Spider): name = 'job' allowed_domains = ['163.com'] start_urls = ['https://hr.163.com/position/list.do'] # cookis参数的使用,重写start_requests函数,这个函数在scrapy.Spider中 def start_requests(self): url = self.start_urls[0] temp = '_ntes_nnid=1abfbc77f799fbae9d902316cb752b4c,1615031424593; _ntes_nuid=1abfbc77f799fbae9d902316cb752b4c; HR163=13fb983d6110c01684acb73a808b3af70c018ae2; NTEShrSI=08713F9EF4A912F8DC491B54678DDE9E.hzabj-new-rms3.server.163.org-8011; mp_versions_hubble_jsSDK=DATracker.globals.1.6.12.9; userName=; accountType=' cookies = {data.split('=')[0]: data.split('=')[-1] for data in temp.split('; ')} # print('--------------', cookies) yield scrapy.Request( url=url, callback=self.parse, cookies=cookies ) # 在parse中实现爬取逻辑 def parse(self, response): # 获取所有职业节点 node_list = response.xpath('//*[@class="position-tb"]/tbody/tr') # with open('wanyi.html', 'wb') as f: # f.write(response.body) # 遍历所有职业节点,这里要间隔着运行,display:none属性的tr是详细内容 for node in node_list[0::2]: item = WanyiItem() item['title'] = node.xpath('./td[1]/a/text()').extract_first() item['department'] = node.xpath('./td[2]/text()').extract_first() item['category'] = node.xpath('./td[3]/text()').extract_first() item['type'] = node.xpath('./td[4]/text()').extract_first() item['address'] = node.xpath('./td[5]/text()').extract_first() item['num'] = node.xpath('./td[6]/text()').extract_first().strip() item['time'] = node.xpath('./td[7]/text()').extract_first() item['link'] = 'https://hr.163.com/' + node.xpath('./td[1]/a/@href').extract_first() # 构建详情页请求 yield scrapy.Request( url=item['link'], callback=self.parse_datail, meta={'item': item} ) # 翻页 # href="?currentPage=254"(有下一页时) ; javascript:void(0)(终止时) # 其实在这里,我们只需要更改curentPage的值就是对应多少页的url pre_url = response.xpath('/html/body/div[2]/div[2]/div[2]/div/a[9]/@href').extract_first() # 判断是否终止: if pre_url != 'javascript:void(0)': next_url = response.urljoin(pre_url) # 返回引擎: yield scrapy.Request( url=next_url, callback=self.parse ) def parse_datail(self, response): item = response.meta['item'] # 这里用正则表达式剔除所有非中文的字符!!!! describe = str(response.xpath('/html/body/div[2]/div[2]/div[1]/div/div/' 'div[2]/div[1]/div').extract()) require = str(response.xpath('/html/body/div[2]/div[2]/div[1]/div/div/' 'div[2]/div[2]/div').extract()) describe = re.sub('''[A-Za-z\<\>\[\]\=\-\'\"]''', '', describe).strip() require = re.sub('''[A-Za-z\<\>\[\]\=\-\'\"]''', '', require).strip() # 这里该补充的值补充完整!然后返回给引擎! item['describe'] = describe item['require'] = require yield itemjob_simple.py:
就是对上面的改一下,不在进行职位信息详情的补充!!
import scrapy from wanyi.items import WanyiSimpleItem class JobSimpleSpider(scrapy.Spider): name = 'job_simple' allowed_domains = ['163.com'] start_urls = ['https://hr.163.com/position/list.do'] # cookis参数的使用,重写start_requests函数,这个函数在scrapy.Spider中 def start_requests(self): url = self.start_urls[0] temp = '_ntes_nnid=1abfbc77f799fbae9d902316cb752b4c,1615031424593; _ntes_nuid=1abfbc77f799fbae9d902316cb752b4c; HR163=13fb983d6110c01684acb73a808b3af70c018ae2; NTEShrSI=08713F9EF4A912F8DC491B54678DDE9E.hzabj-new-rms3.server.163.org-8011; mp_versions_hubble_jsSDK=DATracker.globals.1.6.12.9; userName=; accountType=' cookies = {data.split('=')[0]: data.split('=')[-1] for data in temp.split('; ')} # print('--------------', cookies) yield scrapy.Request( url=url, callback=self.parse, cookies=cookies ) # 在parse中实现爬取逻辑 def parse(self, response): # 获取所有职业节点 node_list = response.xpath('//*[@class="position-tb"]/tbody/tr') # with open('wanyi.html', 'wb') as f: # f.write(response.body) # 遍历所有职业节点,这里要间隔着运行,display:none属性的tr是详细内容 for node in node_list[0::2]: item = WanyiSimpleItem() item['title'] = node.xpath('./td[1]/a/text()').extract_first() item['department'] = node.xpath('./td[2]/text()').extract_first() item['category'] = node.xpath('./td[3]/text()').extract_first() item['type'] = node.xpath('./td[4]/text()').extract_first() item['address'] = node.xpath('./td[5]/text()').extract_first() item['num'] = node.xpath('./td[6]/text()').extract_first().strip() item['time'] = node.xpath('./td[7]/text()').extract_first() item['link'] = 'https://hr.163.com/' + node.xpath('./td[1]/a/@href').extract_first() # 翻页 # href="?currentPage=254"(有下一页时) ; javascript:void(0)(终止时) # 其实在这里,我们只需要更改curentPage的值就是对应多少页的url pre_url = response.xpath('/html/body/div[2]/div[2]/div[2]/div/a[9]/@href').extract_first() # 判断是否终止: if pre_url != 'javascript:void(0)': next_url = response.urljoin(pre_url) # 返回引擎: yield scrapy.Request( url=next_url, callback=self.parse )pipeline.py:
- 这里的两个管道WanyiSimplePipeline和WanyiPipeline: 都进行了是否是对应爬虫的判断,这样避免数据进入到非对应管道中造成数据混乱!!
# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html # useful for handling different item types with a single interface from pymongo import MongoClient import json # 要启用管道,要先去setting里面将65行的注释去掉 class WanyiPipeline(object): # 启用管道时,说明此时的引擎返回的item是包含完整一条数据的 def open_spider(self, spider): if spider.name == 'job': self.file = open('网易求职详细.json', 'a') def process_item(self, item, spider): if spider.name == 'job': # 要将item转化为dict item = dict(item) # 将Python的字典结构导出到json使用json.dumps() ,将json读成Python的字典结构,使用json.loads(), ensure_ascii=False显示中文的数据 json_data = json.dumps(item, ensure_ascii=False) + '\n' self.file.write(json_data) return item def close_spider(self, spider): if spider.name == 'job': self.file.close() class WanyiSimplePipeline(object): # 启用管道时,说明此时的引擎返回的item是包含完整一条数据的 def open_spider(self, spider): if spider.name == 'job_simple': self.file = open('网易求职_simple.json', 'a') def process_item(self, item, spider): if spider.name == 'job_simple': # 要将item转化为dict item = dict(item) # 将Python的字典结构导出到json使用json.dumps() ,将json读成Python的字典结构,使用json.loads(), ensure_ascii=False显示中文的数据 json_data = json.dumps(item, ensure_ascii=False) + '\n' self.file.write(json_data) return item def close_spider(self, spider): if spider.name == 'job_simple': self.file.close() # 这里没有对爬虫进行判断,意味着将两爬虫的数据都写入到该数据库中 class MongoPipeline(object): def open_spider(self, spider): # 创建数据库连接对象 self.client = MongoClient('192.168.50.129', 27017) # 选择一个数据库 self.db = self.client['python_data'] # 选择一个集合 self.col = self.db['python_wanyi'] # 将数据写入数据库 def process_item(self, item, spider): # 注意将数据转化为dict data = dict(item) self.col.insert(data) return item def close_spider(self, spider): self.client.close()setting.py:
- 就改了这几处!!

(3)开启管道:
在settings.py设置开启pipeline
ITEM_PIPELINES = {
'wanyi.pipelines.WanyiPipeline': 300,
'wanyi.pipelines.WanyiSimplePipeline': 301,
'wanyi.pipelines.MongoPipeline': 302,
}
# 权重值越小。越优先执行!别忘了开启mongodb数据库sudo service mongodb start并在mongodb数据库中查看mongo思考:在settings中能够开启多个管道,为什么需要开启多个?
- 不同的pipeline可以处理不同爬虫的数据,通过spider.name属性来区分
- 不同的pipeline能够对一个或多个爬虫进行不同的数据处理的操作,比如一个进行数据清洗,一个进行数据的保存
- 同一个管道类也可以处理不同爬虫的数据,通过spider.name属性来区分
(4)pipeline使用注意点
- 使用之前需要在settings中开启
- pipeline在setting中键表示位置(即pipeline在项目中的位置可以自定义),值表示距离引擎的远近,越近数据会越先经过: 权重值小的优先执行
- 有多个pipeline的时候,process_item的方法必须return item,否则后一个pipeline取到的数据为None值
- pipeline中process_item的方法必须有,否则item没有办法接受和处理
- process_item方法接受item和spider,其中spider表示当前传递item过来的spider
- open_spider(spider): 能够在爬虫开启的时候执行一次
- close_spider(spider):能够在爬虫关闭的时候执行一次
- 上述俩个方法经常用于爬虫和数据库的交互,在爬虫开启的时候建立和数据库的连接,在爬虫关闭的时候断开和数据库的连接
小结:
- 管道能够实现数据的清洗和保存,能够定义多个管道实现不同的功能,其中有个三个方法 *process_item(self, item,spider):实现对item数据的处理
*open_spider(sellf, spider):在爬虫开启的时候仅执行一次
*close_spider(self, spider):在爬虫关闭的时候仅执行一次
*start_urls中的url地址是交给start_request处理的,如有必要,可以重写start_request函数 *直接携带cookie登陆:cookie只能传递给cookies参数接收
*scrapy.Request0发送post请求
7.另外一种爬虫类--crawlspider
继承自 Spider 爬虫类,自动根据提取链接并且发送给引擎
它的应用面更窄,但是性能却更好!!
(1)创建crawlspider 爬虫
- scrapy genspider -t crawl name domians
- 和创建一般爬虫类似,加了 -t crawl
代码:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class ItcastSpider(CrawlSpider):
name = 'itcast'
allowed_domains = ['itcast.com']
start_urls = ['http://itcast.com/']
# 链接提取规则
rules = (
# LinkExtractor用于设置链接提取规则,一般使用allow参数,接收正则表达式
# follow参数决定是否在链接提取器提取的链接对应的响应中继续应用链接提取器提取链接(套娃)
# 使用Rule类生成链接提取规则对象
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
return item
注意:
- cralspider经常应用于数据在一个页面上进行采集的情况,如果数据在多个页面上采集,这个时候通常使用spider
8. scrapy中间件的使用:
(1)scrapy中间件的分类和使用:
1.1 scrapy中间件的分类
根据scrapy运行流程中所在位置不同分为:
- 下载中间件
- 爬虫中间件
1.2 scrapy中间的作用: 预处理request和response对象
- 对header以及cookie进行更换和处理
- 使用代理ip等
- 队请求进行定制化操作,
但在scrapy默认的情况下两种中间件都在middllewares.py一个文件中
爬虫中间件使用方法和下载中间件相同,且功能重复,通常使用下载中间件,爬虫中间件基本不用
(2)下载中间件的使用方法:
1. 在middleware.py中定义中间件类:
2. 在Downloader Middlewares类中重写处理请求或响应的方法:
process_request(self, request, spider):---通常写的更多
- 当每个request通过下载中间件时,该方法被调用。
- 返回None值: 没有return也是返回None,该request对象传递给下载器,或通过引擎传递给其他权重低的process_request方法
- 返回Response对象: 不再请求,把response返回给引擎
- 返回Request对象︰把request对象通过引擎交给调度器,此时将不通过其他权重低的process_request方法
process _response(self, request, response, spider) :
- 当下载器完成http请求,传递响应给引擎的时候调用
- 返回Resposne:通过引擎交给爬虫处理或交给权重更低的其他下载中间件的process_response方法
- 返回Request对象:通过引擎交给调取器继续请求,此时将不通过其他权重低的process_request方法
3. 在settings.py中配置开启中间件,权重值越小越优先执行(同管道的注册使用)
(3)定义实现随机User-Agent的下载中间件---豆瓣实例
1. 在middlewares.py中完善代码:
如下:
import random from Douban.setting import USER_AGENT_LIST # 定义一个中间类 class RandomUserAgent: def process_requset(self, request, spider): ua = random.choice(USER_AGENT_LIST) request.headers['User=-Agent'] = ua2. 在setting.py中设置User-Agent列表并开启自定义的下载中间件,设置方法同管道设置类似


(4)代理ip的使用:
1. 思路分析:
- 代理添加的位置:request.meta中增加 proxy 字段
- 获取一个代理ip,赋值给request.meta['proxy']
*代理池中随机选择代理ip
*代理ip的webapi发送请求获取一个代理ip2. 具体实现
- 在middlewares.py中添加类:
import random from Douban.setting import USER_AGENT_LIST from Douban.setting import PROXY_LIST import base64 # 定义一个中间类 class RandomUserAgent: def process_requset(self, request, spider): ua = random.choice(USER_AGENT_LIST) request.headers['User=-Agent'] = ua class RandomProxy: def process_request(self, request, spider): proxy = random.choice(PROXY_LIST) # 验证是否需要账号密码(独享ip) if 'user_passwd' in proxy: # 对账号密码进行编码 b64_up = base64.b64erjode(proxy['user_passwd'].encode()) # 设置认证 request.headers['Proxy-Authorization'] = 'Basic ' + b64_up.decode() # 注意Basic后有一个空格 # 设置代理 request.meta['proxy'] = proxy['ip_port'] else: # 共享ip # 设置代理: request.meta['proxy'] = proxy['ip_port']
- 在setting.py中设置:


(5)动态加载selenium:
1. 什么时候需要用到动态加载:
当我们需要的数据在elements中的,但是我们的response里面并没有改数据时,说明该数据是浏览器得到response后渲染生成的,此时我们就需要下载中间件
2. 代码:一般都是固定的:
import time
from selenium import webdriver
from scrapy.http import HtmlResponse
from scrapy import signals
class SeleniumMiddleware:
def process_request(self, request, spider):
url = request.url
if 'davdata' in url: # 这里是判断get那条url时,需要对response的数据进行渲染!!
driver = webdriver.Chrome()
driver.get(url)
# 为了防止渲染为完成就进行数据的提取,让程序睡眠一下:
time.sleep(3) # 具体数值看网速!
data = driver.page_source # 得到渲染后的源码!!
# 创建响应对象
res = HtmlResponse(url=url, body=data, encoding='utf-8', request=request)
# 这里返回只能是三种数据None、request、response
# 所以不能用yield,yield返回的是生成器
return res注意:
- 我们写的中间件属于那种中间件,是下载中间件还是爬虫中间件!!!
- 写完中间件后要去setting.py中启用!!!